
机器学习中的特征工程方法
2020-10-21 04:14唐运军孙舒畅
汽车实用技术 2020年12期
唐运军 孙舒畅

摘 要:随着互联网的快速发展,机器学习技术得到了广泛的应用。面对海量的数据,特征工程就显得至关重要,可以说特征工程决定了机器学习模型的上线。文章介绍了对数值、文本、类别时间等不同类型数据的处理方法,总结了在面对高维数据时的特征选择方法并进行了比较,对机器学习的研究和工程应用具有指导意义。
关键词:机器学习;特征工程;特征选择
Abstract: With the rapid development of the Internet, machine learning technology has been widely used. In the face of massive data, feature engineering is very important. It can be said that feature engineering determines the on-line application of machine learning model. This paper introduces the processing methods for different types of data, such as numerical value, text, time of category, etc., and summarizes and compares the feature selection methods in the face of high-dimensional data, which has guiding significance for the research and engineering application of machine learning.
Keywords: Machine learning; Feature engineering; Feature selection
前言
在机器学习中使用数学模型来拟合数据并预测结果,而特征就是模型的输入。特征就是原始数据某个方面的数值表示。特征工程是指从原始数据中提取特征并将其转换为适合机器学习模型的格式。它是机器学习流程中一个极其关键的环节,因为正确的特征可以减轻构建模型的难度,从而使机器学习流程输出更高质量的结果。机器学习从业者有一个共识,那就是建立机器学习流程的绝大部分时间都耗费在特征工程和数据清洗上。
然而,尽管特征工程非常重要,专门讨论这个话题的著作却很少。张浩采用基于AdaBoost 算法的特征线性组合算法和基于提升树的非特征线性组合算法来实现结构化数据特征的自动生成,并采用基于高斯过程的贝叶斯优化方法来自动调整数据挖掘算法模型的参数[1]。白肇强以电商平台的用户行为数据作为切入点,介绍了特征工程的相关知识与概念,并在进行特征工程与实验验证的过程中提出了多项新的工程实现方案[2]。余大龙在ReliefF特征选择算法的基础上,融合了两种不同的数据降维算法和子模优化的性质,研究了基于特征选择的数据降维算法在文本和图像特征选取中的应用[3]。张娇鹏以粗糙集理论为背景,提出了一种面向动态数据集的高效特征选择算法和一种面向少量标记数据集的半监督特征选择算法[4]。张笑鹏针对高维数据下的有监督特征选择方法和无监督特征选择方法分别提出了改进的方法[5]。刘华文还提出了一种基于动态互信息的特征选择方法[6]。国外有人把特征选择问题与模拟退火算法、禁忌搜索算法、遗传算法等, 或者仅仅是一个随机重采样过程结合起来, 以概率推理和采样过程作为算法的基础,在算法运行中对每个特征赋予一定的权重; 然后根据用户所定义的或自适应的阈值来对特征重要性进行评价[7-8]。
究其原因,可能是正确的特征要视模型和数据的具体情况而定,而模型和数据千差万别,很难从各种项目中归纳出特征工程的实践原则。然而,特征工程并不只是针对具体项目的行为,它有一些基本原则,而且最好结合具体情境进行解释说明。
1 数据清洗
原始数据会因数据传输过程中的信号问题等原因存在错误数据、冗余数据和缺失数据,需要进行数据清洗,得到正确数据。错误数据是由测量时的错误造成的,如日期格式是“2018-09-19”和“20180920”两种混用,需要统一格式。冗余数据则是对同一信息的多次表述,比如,一周中的一天可以用分类变量来表示,它的值为“星期一”“星期二”……“星期日”,还可以表示为 0 和 6 之间的整数值,需要删去多余数据。如果某些数据点中不存在这种星期几的信息,那就出现了缺失数据,需要去掉所在行/列,取均值、中位数、众数和使用算法预测。
2 特征处理
2.1 数值特征
数值类型的数据具有实际测量意义,分为连续型(身高体重等)和离散型(计数等)。对于离散型的数据,我们可以二值化处理。例如如果消费者试驾过我们的车辆,那就认为对该车有兴趣。我们也经常使用分箱的方法处理年龄数据,人工设计年龄范围,例如:0-30岁为青年人,30-60岁为中年人,60岁以上为老年人,这样就可以把数据分为3类,如图1所示。
对于连续型的数据,可以采用对数变换、标准化、最大最小值、最大绝对值、基于L1或L2范数等缩放方法。经过对数变换之后,这样小数值扩大,大数值压缩,低计数值的集中趋势被减弱了,在x轴上的分布更均匀了。在梯度和矩阵为核心的算法中,譬如逻辑回归,支持向量机,神经网络,缩放可以加快求解速度;而在距离类模型,譬如K近邻,K-Means聚类中,缩放可以帮我们提升模型精度,避免某一个取值范围特别大的特征对距离计算造成影响。
2.2 类别特征
类别数据表示的量可以是人的性别、婚姻状况、家乡、学历等,其取值可是数值(如1代表男,0代表女),但是作为数值沒有任何数值意义。对于类别特征,最常见的是转化为独热编码(One-Hot Encoding),这是一种数据预处理技巧,它可以把类别数据变成长度相同的特征例如,人的学历分成小学、中学、大学,那么我们可以创建一个维度为3的特征,小学用(0,0,1)表示,中学用(1,0,0)表示,大学用(0,1,0)表示,如图2所示。
2.3 時间特征
时间型特征有的可以看做连续值(用车时间、停车间隔)处理,有的可以看做离散值(星期几、几月份)处理。另外还可以做时间序列分析:滞后特征(又称lag特征,当前时间点之前的信息)、滑动窗口统计特征(如回归问题中计算前n个值的均值,分类问题中前n个值中每个类别的分布)。
2.4 空间特征
对于坐标经纬度,可以散列成类别特征,行政区ID、街道ID、城市ID 可以直接当作类别特征处理。对于两地之间的距离计算可以采用欧式距离、球面距离、曼哈顿距离、真实距离。
2.5 文本特征
文本特征主要来自各大网站、社区论坛。首先进行文本清洗:去除HTML标记、转小写、去除噪声、统一编码等。最基础的文本表示模型是词袋模型。具体地说,就是将整段文本以词为单位切分开,然后每篇文章可以表示成一个长向量,向量的每一个维度代表一个单词。通常采用 TF-IDF 计算权重,如果某个词或短语在一篇文档中出现的频率很高,并且在其他文档中很少出现,则认为此词语权重很高。词袋模型是以单词为单位进行划分,但有时候进行单词级别划分并不是很好的做法,毕竟有的单词组合起来才是其要表达的含义,因此可以将连续出现的n个词(n <= N)组成的词组(N-gram)作为一个单独的特征放到向量表示中,构成了 N-gram 模型。目前主流的是词嵌入模型,词嵌入是一类将词向量化的模型的统称,核心思想是将每个词都映射成低维空间(通常 K=50-300维)上的一个稠密向量(Dense Vector)。常用的词嵌入模型是 Word2Vec,它是一种底层的神经网络模型,有两种网络结构,分别是 CBOW(Continues Bag of Words)和Skip-gram。
3 特征选择
对原始数据进行处理以后,有时数据的维度会非常大,但不是每个维度对当前的问题会有帮助,这时需要进行数据降维。特征提取与特征选择都能帮助减少特征的维度、数据冗余。从文字,图像,声音等其他非结构化数据中提取新信息作为特征。从所有的特征中,选择出有意义,对模型有帮助的特征,以避免必须将所有特征都导入模型去训练的情况。
虽然都是为了从原始特征中找出最有效的特征,但是它们之间的区别是特征提取强调通过特征转换的方式得到一组具有明显物理或统计意义的特征,这样就改变了原来的特征空间。而特征选择的方法是从原始特征数据集中选择出子集,是一种包含的关系,没有更改原始的特征空间。所以特征选择的过程经常能表示出每个特征的重要性对于模型构建的重要性,更具有解释性,应用优先级要高于特征提取。常见的特征选择方法分为以下三种,主要区别在于特征选择部分是否使用后续的学习器[9]。
3.1 过滤法
使用过滤方法进行特征选择不需要依赖任何机器学习算法,如图3所示。它是根据各种统计检验中的分数以及相关性的各项指标来选择特征,包括方差过滤,基于卡方,F检验和互信息的相关性过滤[10]。
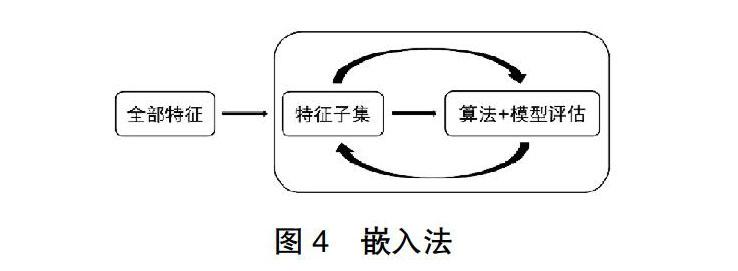
3.2 嵌入法
嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行,如图4所示。在使用嵌入法时,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征。这些权值系数往往代表了特征对于模型的某种贡献或某种重要性,然后就可以基于这种贡献的评估,找出对模型建立最有用的特征。
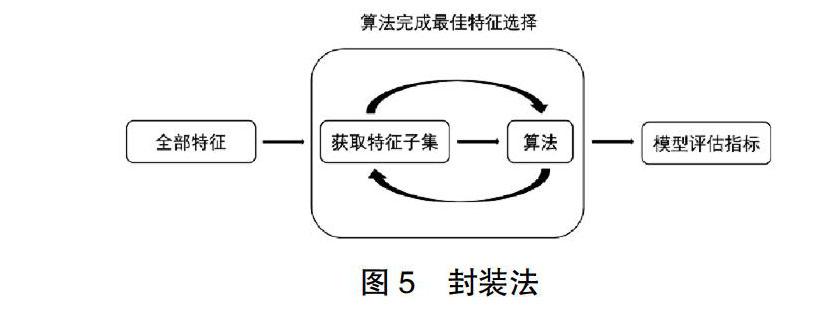
3.3 封装法
相比于过滤式特征选择不考虑后续学习器,封装法直接把最终将要使用的学习器的性能作为特征子集的评价原则,如图5所示。其目的就是为给定学习器选择最有利于其性能、量身定做的特征子集。优点是直接针对特定学习器进行优化,考虑到特征之间的关联性,因此通常包裹式特征选择比过滤式特征选择能训练得到一个更好性能的学习器。缺点是由于特征选择过程需要多次训练学习器,故计算开销要比过滤式特征选择要大得多。
4 结论
本文先是介绍了简单特征工程的作用,然后说明目前特征工程方面的研究现状:研究较少且只研究某一具体领域,没有形成通用处理方法。在数据清洗之后,从数值特征、类别特征、时间特征、空间特征和文本特5个方面介绍一些通用方法。最后对于数据维数和样本数过于庞大带来的“维数灾难”,可以从特征选择的过滤法、嵌入法和封装法3种方法来解决。
特征工程包含许多复杂的知识,为了控制本文的篇幅,做了一些取舍。本文没有讨论音频数据的傅里叶分析、随机特征、隐含狄利克雷分和矩阵分解等知识。下一步将结合机器学习的应用场景,对以上知识进行重点研究。
参考文献
[1] 张浩.自动化特征工程与参数调整算法研究[D].电子科技大学, 2018.
[2] 白肇强.基于用户行为的特征工程构建与应用研究[D].华南理工大学,2018.
[3] 余大龙.基于特征选择的数据降维算法研究[D].安徽大学, 2017.
[4] 张娇鹏.基于粗糙集的特征选择高效算法研究[D].山西大学, 2017.
[5] 张笑朋.面向高维大数据的特征选择方法研究[D].太原理工大学, 2018.
[6] 刘华文.基于信息熵的特征选择算法研究[D].长春:吉林大学, 2010.
[7] Tsymbal A, Seppo P, David W P. Ensemble features election with the simple Bayesian classification[J].Information Fusion,2003,4(2):87- 100.
[8] Wu B L,Tom A, David F, et al. Comparison of statistical methods for classification of ovarian cancer using mass spectrometry data[J]. Bioinformatics, 2003, 19(13): 1636-1643.
[9] Wang H, Han Z Z, Xie Q Y, et al. Finite-time chaos control via nonsingular terminal sliding mode control[J].Communications Nonlinear Science and Number Simulation,2009,14(6):2728-2733.
[10] Koller D, Sahami M. Toward optimal feature selection[C]. Proc of Int Conf on Machine Learning. Bari, 1996:284-292.
猜你喜欢
计算技术与自动化(2022年2期)2022-07-04
现代电子技术(2016年23期)2017-01-12
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
电脑知识与技术(2016年25期)2016-11-16
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
科教导刊·电子版(2016年10期)2016-06-02
