
基于GIS地下水空间数据模型在乌兰盆地的应用
2020-10-20 02:22:56阿慧娟郭邦梅
河南科学 2020年9期
阿慧娟, 郭邦梅, 王 彪, 黄 焱
(1.青海省环境地质勘查局,西宁 810007; 2.青海省环境地质重点实验室,西宁 810002;3.青海省第三地质矿产勘查院,西宁 810008)
地理信息系统(GIS)中的一个关键问题就是如何在数字化环境下表现地理现象[1]. 数据模型通过定义对象、关系、操作及规则提供系统的基础概念,这确定了数据模型表示真实世界现象的方式以及在GIS环境中可以对其进行处理、分析、建模[2]. 空间信息以各种方式用于不同的学科,需要用特定学科的空间数据模型来近似表达和概化感兴趣的现象. 虽然GIS在地下水模拟模型处理上具备较强的数据存储、管理和输入输出功能,但在准确表达地理空间地下水系统的概念特征以及灵活对接数值模型方面还存在着很多的缺陷[3,4]. 如果不能将地下水学科的概念融入空间数据模型,就会导致应用失败以及表达折中[5]. 本文的研究重点是开发一个用于地下水研究的数据模型.
类似许多其他学科一样,地下水研究主要由三个部分组成:数据、概化、建模[6]. 研究地下水系统需要用到的各类数据,例如钻孔记录、抽水试验流量记录、地下水位观测值、包气带特性、降水以及河网信息. 由于地下水系统的复杂性,在用这些数据建立模拟模型之前,需要一个精心构思的概化过程来简化目标地下水系统. 概化过程依赖于对现有研究的回顾、对背景数据的分析以及模型开发者自己的专业判断. 此外,通过概化过程产生的概念视图具体指明了地下水系统中含水层的数量、每一层的类型、含水层的属性及水文地质边界条件.
一个单一的概念视图可以由不同的数值方法实现,比如:有限差分法[7]、有限元法[8]. 地下水数值模型只是定量刻画地下水系统的工具,模拟结果的合理性和可靠性除了模型方法本身之外,最主要的取决于水文地质概念模型的合理概化,如含水层结构、边界条件、补给与排泄条件等[9].
目前,研究人员已经开发出许多与地下水相关的数据模型,大多数数据模型都遵循了传统的空间数据模型的设计方法,就是将一系列定义了属性、关系和规则的地下水专题图层叠加在一起. 虽然现有的地下水数据模型非常适合存储和管理多种来源的地下水数据集,但是它们缺乏表达地下水系统概念视图的能力.因此需要开发新的空间数据模型类型,能反映对目标系统进行建模概化的过程,它可对现有数据模型进行扩展并主要用于存储管理现实世界的观测数据.
地下水数据模型是地下水系统的数学概化,在应用模型模拟时,模拟的精度是一个最关键的问题. 对客观实体的概化不可避免存在一定失真,使模型准确性和可靠性受到影响. 例如降雨入渗、灌溉渗漏等垂向补给量在补给地下水时存在时间上的滞后,河流与含水层的关系受两者相对位置和水位变动的影响等,准确概化这些现象具有一定的困难.
本文提出了一种新的地下水数据模型,可存储地下水系统的概念视图,并阐述了这种新的概化地下水数据模型,包括这种数据模型设计的基本原理、组成部分、数据关系以及其在关系型空间数据库上的实现.对乌兰盆地的研究表明,如何使用概化地下水数据模型来存储真实世界的地下水系统的概念视图以及与有限差分法、有限元法两种类型地下水模拟模型的交互. 该地下水数据模型具有潜在的应用能力.
1 概化地下水数据模型
1.1 地下水系统的概化
概化是指对地下水系统构想的简单视图. 按照理论,概念视图描述越接近真实世界的情况,地下水模型模拟的结果就越准确. 但由于野外条件的复杂性,在实际操作中往往需要简化[10]. 换言之,概念视图应该抓住关键点后,尽可能简单,只要它足以再现系统的行为就可以[11].
地下水系统的概化通常是以确定研究区域中具有相似水文地质属性的水文地质单元开始,然后根据它们的输水能力,再将这些水文地质单元分为含水层或者弱透水层. 因此最终的概念视图将地下水系统设想为一系列含水层和弱透水层,每一层都有自己的含水层特性和水体边界条件. 含水层特性描述了地下水流动所通过的地质介质的特征,如渗透系数、孔隙度及单位产水量;水体边界条件描述了含水层之间的水分通量和表面特性(如:钻孔抽水试验水位降深/恢复观测记录,地下水补给量). 图1举例说明了常见的含水层特性和水体边界条件类型[12].
1.2 Arc Hydro Groundwater数据模型概化的缺点
Arc Hydro Groundwater数据模型可用于表达地下水系统[13],其Arc Hydro Groundwater数据模型主要由三个部分组成:水文地质、模拟模块和时间序列[14]. 水文地质要素包括若干空间要素、Geo Rasters栅格目录和两个非空间信息表HydroGeologicUnit和VerticalMea⁃surements. 空间对象描述了二维的水文地质要素,如钻孔点和含水层边界,还描述了三维要素(如:地质断面和三维地质体);Georaster栅格目录存储了网格化水文地质属性如渗透率和导水系数;Verti⁃calMeasurements和HydroGeologicUnit 表描述了在垂直方向上钻孔各地层深度的相关属性. 时间序列部分则存储了时态信息,如水位和污染物浓度的变化. 模拟部分存储了地下水数值模拟模型中常用的对象,以利于数据从数据模型传递至数值模型中.这个部分包括有限差分模型的网格和有限元模型的网格节点(图2). 总的来说,Arc Hydro Groundwater数据模型主要设计为存储物理性水文地质要素及它们的观测结果,而不是存储地下水系统的概念视图. 举个例子,空间对象含水层和它直接相关的空间对象:钻孔抽水井以及它们间接相关的空间对象钻孔点(BorePoint)和钻孔线(Boreline)可以存储地质构造的垂直分布特征,这在地下水系统概化过程中起到识别相似水文地质单元和描绘含水层的重要基础作用. 然而,Arc Hydro Groundwater数据模型没有定义对象及它们之间的关系,所以不能存储概化的含水层和相关的含水层特性及水文边界条件.

图1 含水层特性和水体特性的表达Fig.1 Representation of aquifer properties and water properties

图2 Arc Hydro Groundwater数据模型(Strassberg 2007)[15]Fig.2 Arc Hydro Groundwater data model(Strassberg 2007)
1.3 概化地下水数据模型的设计与实现
一种面向对象的方法可以使用丰富的语义来描述现实世界现象的特征[16]. 图3给出了一个面向对象的地下水系统的概念视图表达. 它由一系列含水层组成,它们被归类为含水层或弱透水层. 每个含水层都与一些含水层属性和水体边界条件相关.
在真实世界里,含水层特性通常是不均匀的. 在概化过程中需要对含水层特性的分布进行适度的概括,如果认为是均质的,单一含水层的属性值是与含水层关联的. 如果认为是异质的,含水层各特性的属性值需要在一个含水层内的点、线或者区域间具体赋值.

图3 面向对象的地下水系统概念视图表示(E-R图)Fig.3 Object oriented representation of the groundwater system conceptual view
同样,水体边界条件也可以在不同点位(如:井),沿着线段(如:河段)或跨区域(如:地下水补给区)根据每个含水层与地表要素进行水量转换的方式被定义. 为了表达地下水数据模型的异质性,每个含水层都可以包含点位、线段和区域对象. 此外,在每个区域中可沿着线段或点位在不同位置具体给定属性,每条线段也可包含点位. 所有的这些空间实体都可以通过含水层属性和水体边界值相关联.
概化地下水数据模型已经在一个关系型的空间数据库框架内实现了,具体来说,是一个由ESRI开发的地理数据库[17],如图4所示. 这个数据模型定义了一系列非空间的表和空间对象. 类似ArcHydro数据模型一样,定义一个HydroID字段来唯一识别各种不同的空间对象和含水层上的记录[18]. 非空间表AquiferLayer包含了系统每层含水层的记录(透水层或者弱透水层),每一个记录都有一个唯一的HydroID 值;非空间表AquiferProperty还包含含水层属性值;非空间表WaterProperty包含了水文边界条件的数据. 定义了一个可以为空的字段BDData Time 来储存时间信息,在WaterProperty 表中保存的边界条件可能保持不变或者随着时间改变. 所以在地下水模型中能够存储水文地质所必需的观测信息,如钻孔抽水试验观测表,地下水补给量的变化等. 表AquiferProperty 和表WaterProperty 都是抽象类,它们是创建含水层属性和水体边界条件的具体类型子表的基础.
每一个含水层都可能与某些具体的含水层属性相关. 在每个含水层中,含水层属性(AquiferProperty)和水体边界(WaterProperty)值都可能与不同的空间对象有关,这些空间对象包括点(AquiferPoint和WaterPoint)、一条完整的线(AquiferLine、AquiferPloygonLine、WaterLine、WaterPolygonLine)、一个完整的区域(AquiferPolygon 和WaterPolygon). 此外,这些属性还可能与沿线具体的点(AquiferLinePoint,AquiferPolygonLinePoint,WaterLine Point,and WaterPolygonLinePoint)或者在一个区域内具体的点(AquiferPolygonPoint 和WaterPolygonPoint)有关. 最后,还有两个栅格目录来存放每个网格点位的含水层属性和水文边界值(AquifeRaster and Water⁃Raster). 一系列关系就被定义来执行上述关联(图2).

图4 在关系型空间数据库框架中概念化地下水数据模型的实施Fig.4 Implementation of the conceptualization groundwater data model within the relational spatial database framework(1-N represents one-to-many relationship)
2 案例研究
基于地下水系统的数据、知识以及对它的理解,初步形成了一个概念视图(图5). 图5说明了在地下水研究中如何使用概化的地下水数据模型. 地下水数据的来源是复杂多样的,有区域性的地下水数据集或者已经存在的地理数据库,这些数据最后都按照概化地下水数据模型将它们组织起来,然后储存在地理数据库中并转换成数值代码. 如果可以,通过为数值地下水方法开发图形用户界面(GUI)来促进转换为数值代码的过程化的地下水数据模型.
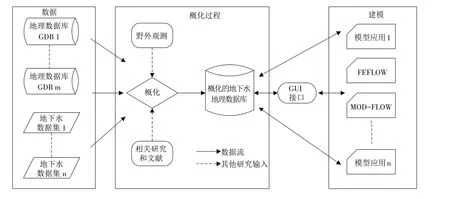
图5 在地下水研究中概化地下水数据模型的应用Fig.5 Use of the conceptualization groundwater data model in groundwater studies
作为一个案例研究,概化地下水数据模型用来模拟在乌兰盆地中地下水流场. 乌兰盆地地下水勘查是由中国地质调查局发起的柴达木盆地循环经济区重点地区地下水勘查(2010—2015年)中的子项目.
根据勘查成果以及研究目的,确立模拟区:南靠牦牛山,北至阿木内格山、青海南山和布赫特山,东临东大滩,西屏柴凯湖谷底天然分水岭;在垂向上,上部以地表为界,下部以基岩为界. 地理坐标介于东经98°00′~98°37′,北纬36°46′~37°03′,是一个东西宽长约50 km,南北宽约15 km的狭长盆地,面积共约755 km2(图6). 模拟区边界充分考虑了自然边界以及地下水循环模式,反映了盆地地下水流的特征.
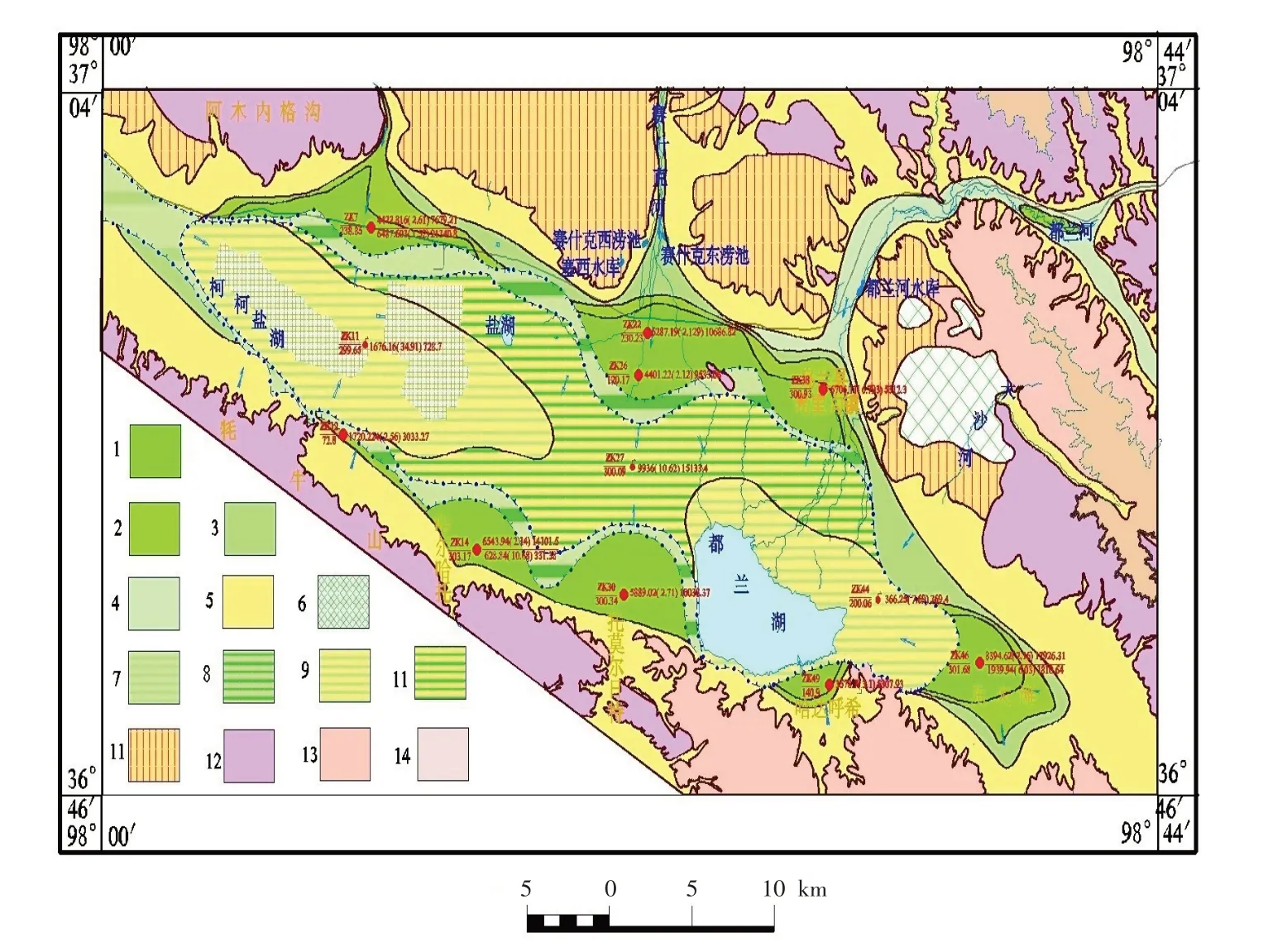
图6 乌兰盆地地下水系统概化水文地质概化图Fig.6 Hydrogeology conceptual views of Wulan Basin groundwater system
乌兰盆地属山间断陷盆地,其水文地质结构具有山前自流斜地特征,表现在第四系沉积岩相、岩性等特征上具有明显的分带性[10]. 山前冲洪积扇含水层一般为单一结构的卵砾石含水层,地下水形成单一结构潜水,在盆地中心的冲湖积平原,含水层过渡为砂与黏土互层的多层结构,形成多层结构的上层潜水及下层承压水[20].
此次研究的水文地质参数包括河流渗漏系数、渗透系数、给水度、单位储水率、降雨入渗系数、田间入渗系数以及渠系渗漏系数. 其中降雨入渗系数、田间入渗系数以及渠系渗漏系数通过查阅文献及资料获得,分别为0.13,0.15,0.5;渗透系数通过富水性分区及抽水试验获得,阈值范围在20~142 m/d之间,给水度参考渗透系数分区,通过地层岩性及资料获得,数值范围在0.03~0.1之间,单位储水率通过勘查资料推算获得,数值范围在0.08~0.1之间.
概化地下水数据模型是用来储存地下水系统的概念视图的,然后用于扩展两种常见类型的数值型地下水模拟模型:MODFLOW执行有限差分法,FEFLOW执行有限元方法[21]. 表1总结了这两个模拟模型所需要的参数. 它们的值都是根据勘查成果的基础上推算的.
该数据模型输入的数据在两个模拟模型中是相似的,除了几个需要指明不同的含水层属性和水体边界条件的步骤. 因为乌兰盆地地下水系统被概化成两个含水层(上层潜水,下层承压水),因此在AquiferLayer中就有两条含水层记录. 在建模区域内顶板高程、底板高程与渗透系数、给水度这几个含水层属性按预设分区分别赋值,在AquiferProperty 表中这几个属性值用对应的记录来表示. 这些记录的FeatureID 字段就相当于表AquiferLayer中的含水层HydroID字段(图7).

表1 乌兰盆地地下水系统的模型参数Tab.1 Model parameters for Wulan Basin groundwater system

图7 乌兰盆地地下水数据模型的实施Fig.7 Implementation of Wulan Basin groundwater data model
为了表示不均匀性,首先在表AquiferProperty 中为整个潜水含水层和承压水含水层定义一个初始的渗透系数. 然后以观测孔为水位实测值作为拟合对象,进行模型识别和验证. 乌兰盆地内地下水类型以第四系松散岩类孔隙水为主,概念模型所定义的边界有着不同的水力传导度的值,根据乌兰盆地水文地质图将它划定出来,然后以相应的含水层分区保存在空间对象AquiferPolygon中. 它们的渗透系数、给水度、单位储水率如上表所示,以另一条记录保存在AquiferProperty中,这条记录的FeatureID字段值就被指定为相应的含水层多边形要素的HydroID值.
在这两个地下水数值模型中,MODFLOW 和FEFLOW 需要一个地下水模型明确定义的外部边界,外部边界条件和相应的含水层数存储于空间对象WaterPolygon 中. 因此,在两种数值模型中,都在空间对象WaterPolygon中添加了记录,定义了地下水补给区的边界,在表WaterProperty的Discharge类型中就添加了一条补给率即入渗率(包括降水、河流、渠系).
最后这个区域的河网数据从地形图中提取出来,保存在WaterLine中. 在两种模型中,河流都被定义为依赖水头的水流边界条件,根据实测河流流量和渗漏量关系计算河流渗漏补给量,但是边界值却不同.MODFLOW需要用户指明沿着河段指定的格网的水头和渗漏率值. 由于格网的位置取决于模拟配置而导水率取决于格网的大小,它们都不是概念视图的一部分. 例如,ArcHydro地下水数据模型的模拟部分储存了网格的位置和网格节点. 因此在MODFLOW设计数据模型的时候,只有指明河段的水体边界条件类型的记录被添加在WaterProperty表中. FEFLOW需要用户指定沿着河段的网格节点的水头值以及它们的内转移率和外转移率. 由于网格节点的位置取决于模拟配置,因此水头值也不是概念视图的部分. 每条河段的内转移率和外转移率存储于表WaterProperty 的WaterBoundary InTransferRate 类型中,表WaterProperty 还包含了指明河段的水体边界条件类型的记录.
现有GUI 接口可以用来将乌兰盆地地下水系统的概念视图从概念化地下水数据模型转换成数值型代码. FEFLOW有自带的GUI接口,MODFLOW利用PMWIN. ESRI在ArcGIS环境下创建了Python脚本和模块自动提取地下水数据模型里的数据,并为不同的GUI接口提供输入文件. 图8显示了乌兰盆地地下水系统的模拟地下水位,除了一些地方的差异,两种模型模拟的地下水流场是相似的,地下水接受补给后,沿扇轴方向向盆地中心径流,至细土带前缘,地下径流受阻,地下水少量溢出,地下水最终消耗于浅埋大量蒸发以及都兰湖、柯柯盐湖、盐湖的湖面蒸发.

图8 用FEFLOW、MODFLOW模拟的地下水等水位线Fig.8 Simulated water line of groundwater by FEFLOW and MODFLOW
3 结论
水文地质系统的概化构成了地下水建模的基础. 尽管地下水模型在许多方面不同,但它们都是基于相同的地下水系统概念,如含水层、含水层属性和水体边界条件. 到目前为止,很少有人去设计地下水数据模型来储存这些建模概念. 本文通过开发一种新的概化地下水数据模型强调了这种需求,这个数据模型允许用户储存、更新和表达他们的目标地下水系统的概念视图. 目前,这个概化的地下水数据模型继承了传统的分层方法来概化三维地下水系统. 希望能够通过将三维地质要素和异质性融入地下水建模的过程,改进数据模型以便融入其他的三维要素. 对乌兰盆地地下水系统的研究实例说明了在地下水的研究中如何使用该数据模型以及该模型与多种地下水建模方法相交互的能力. 总的来说,概化地下水数据模型通过使地下水建模过程变得可扩展、可溯源和可互操作.
在空间数据模型设计中缺乏建模概念不是地下水研究的特有问题. 许多学科的数据模型都是基于专题图层的,而且都专注于存储真实世界的调查结果. 像本研究所提出的一样,其他学科的专家可以将存在于他们不同的建模方法之下的概念提取出来,然后基于这些概念设计概化数据模型. 概化的数据模型有助于识别兼容的对象,并建立关系,然后促进学科间模型的集成.
猜你喜欢
Acta Mathematica Scientia(English Series)(2022年3期)2022-06-25 02:12:58
青年歌声(2019年2期)2019-02-21 01:17:30
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:48
草原歌声(2018年1期)2018-05-07 06:40:04
电子测试(2017年12期)2017-12-18 06:35:36
草原歌声(2017年1期)2017-04-23 05:08:51
水利科技与经济(2017年2期)2017-04-22 02:34:24
心理学探新(2015年4期)2015-12-10 12:54:02
江苏农业科学(2014年6期)2014-08-12 08:48:54
测绘科学与工程(2013年1期)2013-03-11 15:07:24
