
基于最大相关熵的分布式仿射投影算法
2020-10-20 09:13:04于和芳
微处理机 2020年5期
于和芳,郭 莹
(沈阳工业大学信息科学与工程学院, 沈阳110870)
1 引 言
分布式网络可应用于医疗应用、救灾管理、环境监测等诸多领域[1-4],将自适应滤波算法[5-6]应用到分布式网络中,可以更加准确地估计目标并增强分布式网络对环境变化的鲁棒性。研究人员提出了许多分布式的自适应滤波算法,例如分布式最小均方算法(Diffusion Least Mean Square, DLMS)[7]和分布式仿射投影算法(Diffusion Affine Projection Algorithm,DAPA)[8-10]。其中DLMS 算法结构简单,但对于有色输入信号,其收敛速度会急剧下降。DAPA 算法是在DLMS 算法的基础上将输入信号重组,可有效地改善输入为有色信号时算法的收敛性能。然而,传统的DLMS 算法和DAPA 都是基于L2 范数优化准则开发的,在非高斯干扰下性能会严重下降。
为解决这一问题,一系列抑制非高斯噪声的算法被提出。其中,文献[11]~[15]用可变的步长来代替传统DAPA 算法中的固定步长,凭借自适应步长选择算法在低稳态和快速收敛速度之间做出了较好的选择。由仿真实验可知,变步长分布式放射投影算法(Variable Step Size Diffusion Affine Projection Algorithm,VSS-DAPA)相比于传统的DAPA,收敛速度更快,但稳态更低。文献[16]和[17]提出了基于两种分布式策略的仿射投影符号算法(Diffusion Affine Projection Sign Algorithm, DAPSA),其中增强式策略估计了算法的抗脉冲干扰能力,增强了抗干扰能力,但是收敛速度较慢。最近,研究人员提出将最大相关熵准则(MCC)应用于自适应滤波领域,提出了基于MCC 准则的自适应滤波算法[18-20],构造了一个新的代价函数来抑制脉冲噪声。由于MCC 核函数的负指数项和核宽的作用,削弱了较大误差对相关熵的影响,因此MCC 算法中不会出现由偏差较大引起的数值不稳定问题,对脉冲噪声具有较强的鲁棒性。
基于上述研究,在此将最大相关熵准则与分布式仿射投影算法相结合,提出一种以高斯核函数为基础的最大相关熵算法。新算法大大降低了输入信号的相关性,并能很好地抑制非高斯噪声。
2 分布式仿射投影算法
在传统的集中式网络中,所有节点信息都需要传输到一个中心,然后由这个中心将数据处理结果共享并返回每个节点。这种协作需要一个强大的中央处理器,因此具有一定的局限性。改进后的分布式网络则没有融合中心,每个节点分散在一定的地理环境范围内。通过对各节点采集的数据进行局部处理,最终实现整个系统的信息处理。分布式网络根据协作策略不同分为:扩散式、一致式和增量式。扩散网络的信息交换过程与一致性相同,即每个节点可以与所有相邻的代理进行信息交换,但扩散策略优于后两种策略[21]。
仿射投影算法是利用数据重用的方法在传统LMS 算法上做出的改进算法。该算法将最近P 个输入向量组合在一起,以P 作为仿射投影阶数。在一个N 个节点的分布式网络中,第k 个节点的输入信号表示为uk(i),数据重用后,输入信号可写成如下矩阵形式:
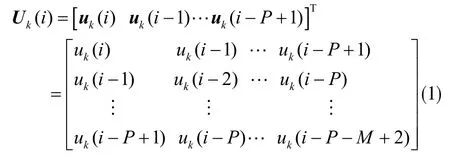
矩阵中的P 代表投影阶数,M 为滤波器长度,i 表示时刻,[·]T为矩阵的转置。
输出信号yk(i)和期望信号dk(i)分别写成矩阵形式表达式如下:

式中,w0为待估计的权值向量,M 为长度,vk(i)为信号中的加性干扰噪声。
传统的DAPA 算法是基于最小扰动原理(Principle of minimal disturbance)推导所得,一般是求解如下的受条件约束的最优化问题:

节点k 通过与其通信组内节点的中间权估计Φl(i),利用拉格朗日乘子法对式(4)和(5)进行推导,得基于ATC 式扩散策略[22]的DAPA 迭代算法的更新过程如下:
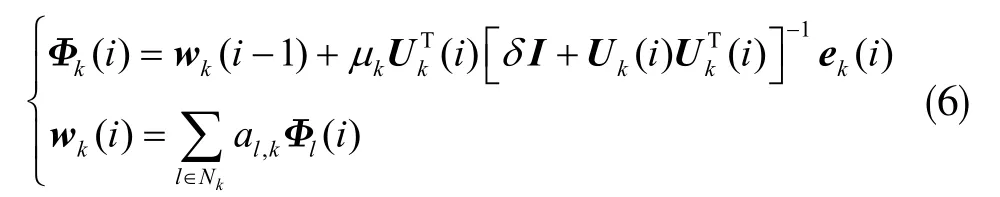
误差向量表示为:

其中l 为节点k 的邻居节点,al,k为联合系数,1。Nk表示与节点k 相连的所有节点的邻域,当l∉Nk时,al,k=0。δI 为避免逆矩阵不满秩的情况,δ 是一个极小的数,I 为M×M 的单位矩阵。μk为节点k 的步长参数。
上述DAPA 算法是基于L2 范数的自适应滤波算法,在高斯噪声下可以降低输入信号的相关性,但在非高斯噪声的干扰下会严重失调,为解决这一问题,在此提出一种基于最大相关熵的仿射投影算法。
3 基于最大相关熵的分布式仿射投影算法
3.1 最大相关熵准则
相关熵是两个随机序列X 和Y 之间的非线性相似性度量,定义为:
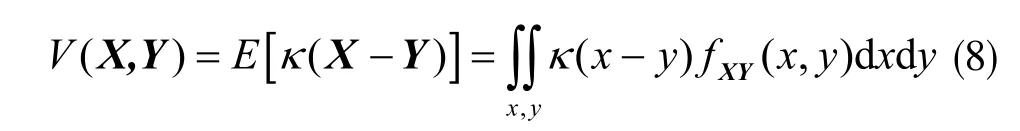
其中E(·)表示期望运算符,x、y 是序列X、Y 中的元素,fXY(x,y)是X、Y 的联合概率密度函数,κ(·)表示Mercer 核函数,其中最常用的Mercer 核函数是高斯核,定义为:

其中,σ>0 表示核宽。
期望信号d(i)来自线性模型:
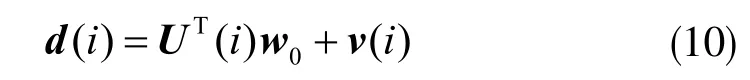
其中,w0为M×1 维待估计的未知参数向量,v(i)为背景噪声,误差信号为:
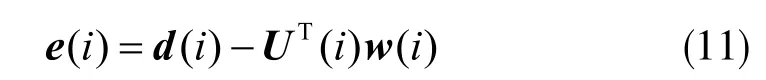
其中,w(i)是迭代到i 次时w0的估计。
在MCC 中,代价函数为:
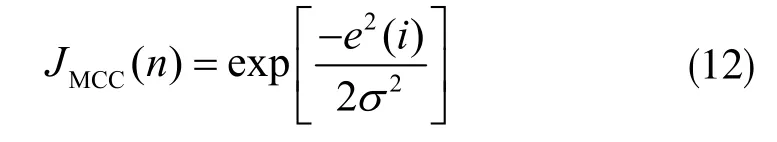
3.2 DMCCAPA 算法
由于MCC 算法不能用于分布估计,故而在此提出DMCC 算法。DMCC 有两种扩散策略,分别是先结合后自适应的CTA(Combine-Then-Adapt)模式和先自适应后结合的ATC(Adapt-Then-Combine)模式。ATC 可以比CTA 更快地遍历所有节点[23],此处选用ATC 策略展开讨论。
DMCC 使用与MCC 相同的代价函数来抑制网络中每个节点的脉冲噪声。在具有N 个节点的分布式网络中,待估计的未知向量为w0,k是M×1 维,节点k 在第i 次迭代时的局部测量值为{dk(i),Uk(i)},k=1,2,..., N,其中:

其中,vk(i)为背景噪声,vk(i)和Uk(i)是相互独立的。DMCC 是通过最大化节点k 的邻居Nk内的局部相关熵的线性组合来估计w0,k,DMCC 在节点k 处的代价函数为:
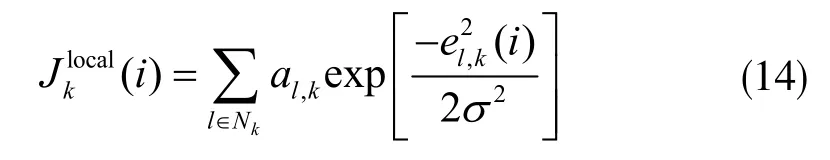

其中deg(k)表示节点k 的度(相邻节点到节点k 链接的数目,包括代理k 自身)。
对式(14)关于wk求导:

因此,基于梯度法估计节点k 处w0,k的DMCC 算法可以表示为:
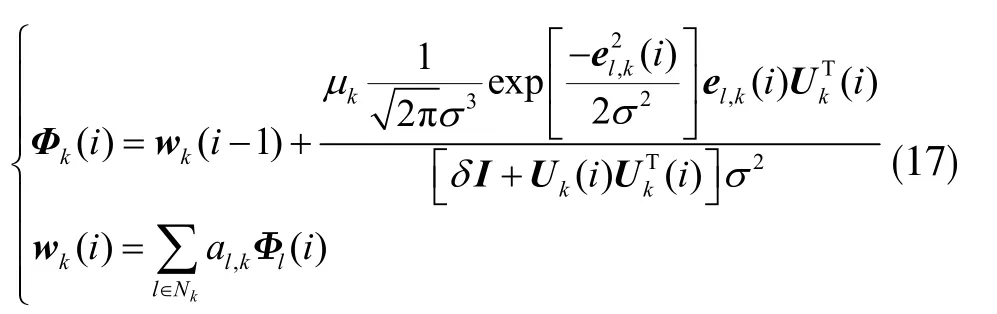
其中,Φk(i)为节点k 在i 时刻的中间估计值。
为了更好地理解本算法,将DMCCAPA 的算法规则归纳如下:
初始化: M=128,P=4,
对于每一次迭代i
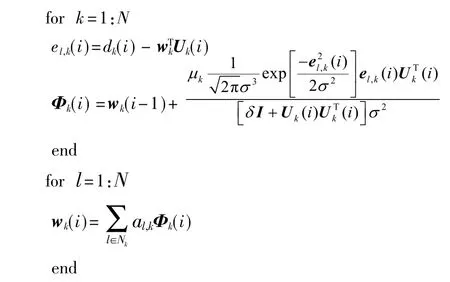
4 仿真实验
为了进一步证明算法的有效性,对新提出的算法及其他的分布式自适应滤波算法在不同的条件下进行了仿真实验。使各算法在同一收敛速度下对比各自的稳态误差:收敛速度相同时,得到稳态越小,滤波算法的自适应性越好,则表明在非高斯噪声下算法具有较强的鲁棒性。
4.1 噪声环境
实验采用的输入uk(i)为有色信号,它是均值为零的高斯分布的白信号通过一阶AR 系统得到的。一阶系统为。并在输出信号yk(i)=中加入测量噪声。仿真实验中噪声分别为均值为零的白噪声vk(i)和脉冲噪声vk(i),两种噪声模型分别如图1 和图2 所示。令其信噪比SNR=10×其中脉冲噪声采用伯努利分布,也称为(0,1)分布,写成一个伯努利函数与高斯函数相乘的形式:vk(i)=χk(i)γk(i),此处,χk(i)为伯努利分布,γk(i)为高斯分布。
4.2 性能指标及参数设置
实验中选用网络均方误差(Network Mean Square Deviation,NMSD)的收敛曲线来评价各算法的收敛性能[24],定义为:
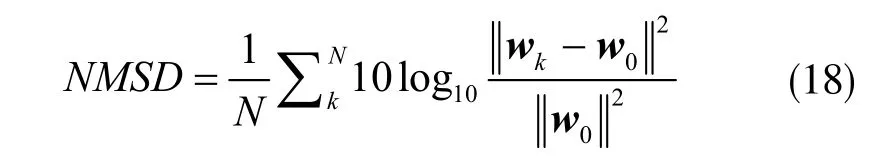
其中,NMSD 的值越大收敛性能越差;反之,该值越小表明自适应滤波系统越接近待估计系统。
为便于计算,由表1 给出实验中设置的参数。

表1 实验参数设置
4.3 仿真结果及分析
输入为有色信号,高斯噪声环境下,对DLMS 算法、DAPA 算法、DPSA 算法、DMCCLMS 算法以及新提出的DMCCAPA 算法的收敛性能进行对比分析。
当环境为高斯噪声时,设置信噪比SNR 为20dB,DLMS、DAPA、DPSA、DMCCLMS 及DMCCAPA算法的步长分别设置为0.2、0.15、0.08、0.002、0.001,其中DMCCLMS 和DMCCAPA 算法的核宽设为4。对比结果如图3 所示。可见,高斯噪声下输入为有色信号时,DLMS 和DMCCLMS 算法受有色信号的影响,算法收敛速度较慢。而DAPA、DAPSA 算法以及DMCCAPA 算法利用数据重用,降低了有色输入信号对算法的影响。注意到新提出的DMCCAPA 算法的收敛速度最快。
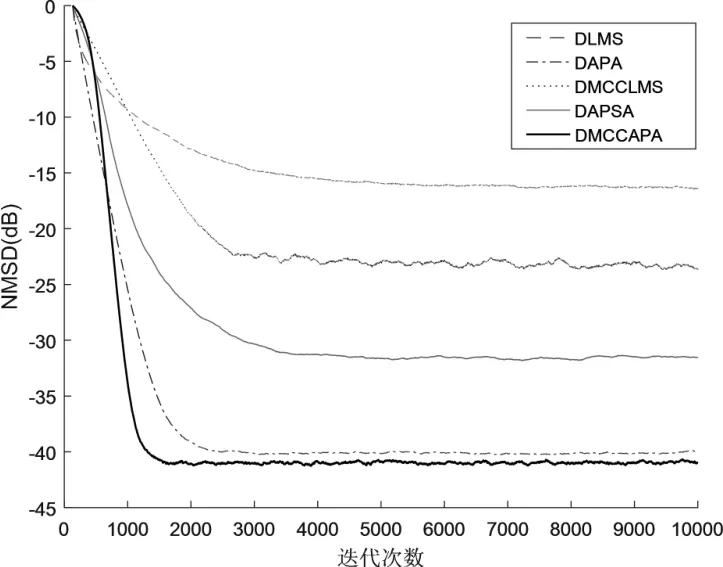
图3 高斯噪声下各算法仿真对比
非高斯噪声下进行的仿真结果如图4。分别设置DLMS、DAPA、DPSA、DMCCLMS 以及DMCCAPA算 法 的 步 长 参 数 为0.3、0.2、0.075、0.003、0.0015。DMCCLMS 和DMCCAPA 算法的核宽设为4。由图4可知,非高斯噪声环境下,DLMS 和DAPA 算法彻底失调。DAPSA 采用符号算法对误差信号进行量化,对非高斯噪声有一定的抗干扰能力,但量化后的误差函数取值大幅受限,使得算法的稳态误差较大。而新提DMCCAPA 算法求误差信号的最大相关熵,大大降低了非高斯噪声的干扰,且收敛较快。对比这些算法在相同的收敛速度下,新算法稳态误差最小,具有较强的鲁棒性。

图4 脉冲噪声下各算法仿真对比
5 结 束 语
基于对最大相关熵准则的讨论,以高斯核函数的DMCC 作为代价函数,提出一种基于DMCC 的仿射投影算法。在研究中借助了最大相关熵理论,作为一种基于信息熵理论的自适应滤波算法,在非高斯噪声下现实了较强的鲁棒性。与DAPA 算法相结合,在输入信号相关性较高的情况下,该算法能快速收敛。仿真结果表明,在非高斯噪声下,DMCCAPA 算法具有更好的性能,具有较快的收敛速度和较小的稳态误差。
猜你喜欢
数学小灵通(1-2年级)(2024年4期)2024-05-14 09:30:52
数学物理学报(2021年1期)2021-03-29 03:14:42
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25 01:40:34
小学生学习指导(低年级)(2019年6期)2019-07-22 03:33:10
学生天地·小学低年级版(2019年5期)2019-06-05 01:15:11
学生天地(2019年15期)2019-05-05 06:28:28
能源(2017年10期)2017-12-20 05:54:07
能源(2017年5期)2017-07-06 09:25:54
雷达与对抗(2015年3期)2015-12-09 02:38:50
四川师范大学学报(自然科学版)(2015年2期)2015-02-28 14:07:36
