
ASN.1 的PER 分层运行库系统的设计和实现
2020-10-20 09:13:04高益
微处理机 2020年5期
高 益
(重庆航天职业技术学院电子工程系, 重庆400021)
1 引 言
ASN.1 编解码运行库软件在应用ASN.1 的系统中起着极为重要的作用,是整个系统中不可缺少的一部分,被用来处理针对不同的ASN.1 编解码规则提供不同的编解码函数[1]。例如:BER 编解码规则对应BER 编解码函数,PER 编解码规则对应PER 编解码函数,这些具体规则对应的编解码函数通过调用其相应的ASN.1 运行库完成其编解码过程[2]。可直接调用这些编解码函数完成复杂数据结构与传输码之间的转换,从而开发出实用ASN.1 的应用系统。基于此,本研究着眼于提高编解码运行库系统的灵活性和移植性,以降低使用难度为目标,设计实现一种智能化编解码系统。
2 PER 分层运行库系统模型组成和功能
PER 的编码原则就是用最简单的规则得到最简洁的编码[3],相应地PER 的编码规则也就更加复杂。除少数类型沿用了BER 的编码方法外,PER 各个数据类型的编码比BER 都精简得多,冗余信息极少。在此可设计一个底层的函数库,把这些共同的特征函数封装在一起,以此大大提高运行库的执行效率。基于不同ASN.1 编码规则的共同点,设计出一个ASN.1 分层运行库系统,其建模结构如图1 所示。

图1 ASN.1 分层运行库系统模型
图中各主要部分功能简介如下:
底层函数库层ASN.1 编解码函数的很多代码是各种类型所共用的,如果提供公共函数以供其它编解码函数调用,就可减少不必要的代码重复。
ASN.1 各种编解码规则库层在上述的公共函数库层之上,可根据ASN.1 各种编码规则编写不同类型的编解码函数库,例如:BER 编解码运行库、PER 编解码运行库、DER 编解码运行库等。以此可令ASN.1 数据值编码大为简化。如果为每个基本的ASN.1 数据类型编写编解码函数,则可以提供公共的函数库给各应用系统调用。
宏定义层把常用的代码段定义为宏,这样就便于定义与应用有关类型的编解码函数。提供一部分宏定义直接供其调用,包括处理内存分配、释放和长度计算的宏定义。
不同编解码规则都有相同的表述数据类型的方式,可分为:简单类型、复合类型和其它类型[4]。ASN.1 的PER 分层运行库系统模型也随之包括简单、复合与其它类型的编解码处理层。ASN.1 的PER 分层运行库系统的总体设计框架如图2 所示。
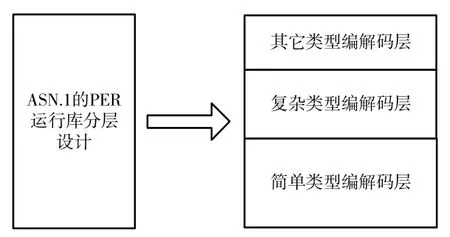
图2 ASN.1 的PER 分层运行库模型
图中各主要部分的功能为:
简单类型编解码层该层位于模型的最底层,是为ASN.1 语法描述中定义的所有基本数据类型提供的编解码函数,一个基本类型对应一套编解码流程和一对编解码函数。
复杂类型编解码层该层位居中间,与其对应的是ASN.1 智能PER 编解码系统的中间结构编解码处理层。如此的构成,可实现直接调用,无需在运行库中再次查找,省去了代码的重复压栈和出栈,提高编解码运行库的运行时间,同时也节约了代码运行所占的空间。
其它类型编解码层这一层位于运行库系统的最上层,对除了基本类型和构造类型外的其它ASN.1 类型,即对ASN. I 中的CHIOCE 和ANY 类型,进行编解码处理。
运行库函数不应随着相应协议的变化而变化,它实现的是编解码底层的支撑函数,符合标准C,具有较好的可移植性。
3 简单类型编解码处理层设计实现
简单类型编解码处理层的接口函数的实现应基于输入需要编码或者解码的数据、数据长度、输出编解码数据的需求[5]。先设计一个结构体RUNBuffer 用来存储消息缓冲区的编解码数据:
typedef struct {
char* data;
unsigned int byteIndex;
int size;
short int bitoffset;
unsigned char aligned;
}RUNBuffer;
RUNBuffer 结构体中变量data 是一个字符串指针,指向输入数据起始的地址;变量byteIndex 是一个无符号整形,表示当前编码结果字节的位置;变量size 是一个整型的值,表示当前缓冲区的大小;变量bitoffset 是一个短整型的值,表示当前地址偏移了多少位;变量aligned 是一个无符号的字符类型,表示当前数据是否为PER 的对齐方式。
在以下示例中,对ASN.1 基本类型的编解码算法进行设计,重点以整型为例,详细给出编码算法、整型编码模块实现流程图和函数编解码实现代码:
INTEGER 类型编解码算法:
步骤1:判断整数有无约束,如果没有约束,就按照无约束编码方式,用最少字节编码n 的值,内容字节的前面需要长度编码,表示n 的值占用了多少个字节。长度也用最少字节编码。编码成功,返回值为1,结束;如果有,则跳到步骤2。
步骤2:判断整数约束限度到唯一值,如果是,则编码失败,返回值-1,结束;如果不是,则跳到步骤3。
步骤3:判断整数约束的下限是否是无限的,如果是,则按无约束方式编码,编码成功,返回值1,结束;如果不是,则跳到步骤4;
步骤4:判断整数约束的下限是否是一个有限数,如果是,则上限是一个无限数,按照半约束整数方式编码,编码成功,返回值1,结束;如果不是,则跳到步骤5;
步骤5:判断整数约束的下限和上限是否都是有限数,如果不是,则编码失败,返回值-1,结束;如果是,则按照约束整数方式编码,编码成功,返回值1,结束。
INTEGER 类型编码流程图如图3。
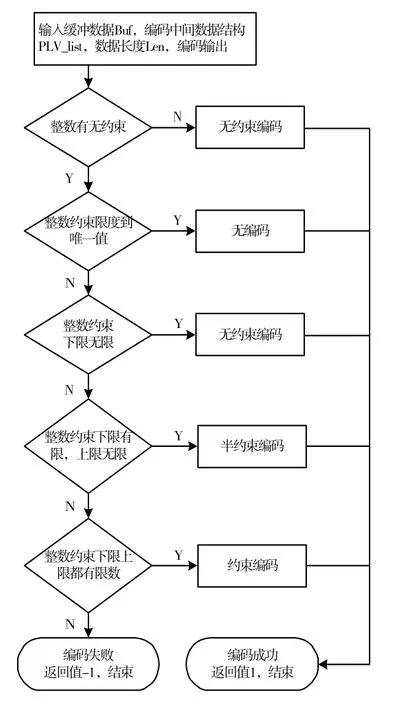
图3 整型编码模块实现流程图
4 复杂类型编解码处理层设计实现
4.1 算法约束规则
复杂类型即为ASN.1 中的构造类型,对此可按照表1 所示的规则处理[6]。

表1 复杂类型算法约束
表中所示的这四种类型编码算法,在Canonical PER 中和Basic PER 中,标记有DEFAULT 的成员,如果要编码的值是缺省值,则此成员的编码省略;而对于结构化的成员,即使它的取值是缺省值,是否被编码仍须由以下两点来判定:
①类型是可扩展的且取值没有出现扩展附加部分,则SEQUENCE 的值的编码结束;
②类型是可扩展的且取值有n 个扩展附加部分,则添加一个n 比特bitmap,对应比特取值1,表示该扩展附加部分出现。
当长度为n 的bitmap 增加一个长度指示后,编码方式为小的非负整数的编码。后面依次出现的扩展附加部分的编码方式如下:
扩展附加部分是单个成员,则以open 类型来编码,即包括长度字段和整数个字节的值字段;
扩展附加部分是由双重方括号内全部成员组成,则扩展附加部分的值以open 类型编码。区别在于:双重方括号内全部成员的值均作为一个sequence类型的取值来编码[7]。set 中的元素也可以是可选的,用关键字optional 来描述,若具有缺省值,用default来描述。
4.2 具体编码算法
算法首先要判定数据的类型,如果经判定数据类型为sequence,则计算其中出现的具有可选/必选属性的元素个数,用n 位来表示这n 个元素是否出现,若出现了,则用1 表示;若没有出现,则用0 表示。这n 位数的顺序就是元素在sequence 中出现的顺序。然后按元素的出现顺序和类型调用相应的编码函数,编码结束。
如果经判定数据类型为set,则计算其中出现的具有可选/必选属性的元素个数,用n 位来表示,若出现,则用1 表示;若没有,则用0 表示。这n 位数的顺序就是元素在set 中出现的顺序。按元素的定义顺序和类型调用相应的编码函数,编码结束。
SEQUENT OF 数据类型编码过程和SEQUENT相同。而SET OF 数据类型编码过程和SET 相同。
以下为SEQUENCE 类型的编码函数:
int SEQUENCE_encode_per(asn_per_constraints_t*constraints,
asn_codec_max*opt_codec_max,
void*sptr,asn_per_outp_t*po)
5 其它类型编解码处理层设计实现
除了上述类别外,ASN.1 中还有CHIOCE 和ANY 类别,其中ANY 表示任意类型,CHIOCE 表示一个或多个可选项的联合,如下所示[8]:
CallEventDetail::=CHOICE{
mobileOriginatedCall
mobileTerminatedCall
LocationService
}
对于CHOICE 类别,编码数据时一次只能选定一个元素。CHOICE 类型的解码函数为:
int CHOICE_decode_per(asn_codec_max* opt_codec_max,
asn_per_data *pd, asn_per_constraints *constraints,
void **buf)
6 结 束 语
ASN.1 的PER 分层运行库系统模型的提出,是考虑到目前运行系统存在的弊端,模型尝试解决传统ASN.1 运行系统的瓶颈问题,也给出了使用C 语言设计一个ASN.1 智能PER 分层运行库系统的实现过程。详细分析PER 编解码算法,从长度域编解码算法到基本类型编码算法,从基本编解码处理层的实现,到构造类型编解码处理层的实现,通过PER 可见子类型约束和宏的使用对代码进行了优化。设计实现的软件可以完成简单ASN.1 协议的编解码功能,对ASN.1 相关系统有较高的应用价值。为未来实现ASN.1 工具的其他功能打下了基础,在此基础上可结合其他应用语言的特性实现完整的ASN.1 运行库功能。
猜你喜欢
电子元器件与信息技术(2021年5期)2021-07-27 03:48:14
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
数码世界(2020年5期)2020-06-23 00:14:36
空间科学学报(2020年4期)2020-04-22 01:17:38
电子制作(2019年22期)2020-01-14 03:16:24
民用飞机设计与研究(2019年2期)2019-08-05 01:33:26
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
电子测试(2018年18期)2018-11-14 02:30:54
计算机工程(2014年6期)2014-02-28 01:27:54
