
RFID对象包含关系几何向量编码优化策略
2020-10-20 10:05:58廖国琼段雨薇杨乐川
小型微型计算机系统 2020年10期
廖国琼,段雨薇,杨乐川
1(江西财经大学 信息管理学院,南昌 330032) 2(江西省高校数据与知识工程重点实验室,南昌 330032)
1 引 言
随着5G网络的推出,竞争激烈的市场再次将“万物互联”的优势展示在了人们眼前,利用物联网智能化管理供应链(Supply Chain),是提高市场监管效率的有效手段之一.在众多物联网设备中,无线射频识别技术(Radio Frequency Identification,RFID)因其成本低、体积小,可增加物品的追溯性,从而较早被提出[1,2].该系统由电子标签、阅读器、天线组成,其中电子标签具有唯一性、可实现多目标非接触自动快速识别,且RFID具有大规模部署潜力,因此可为实现物品在供应链环境中追溯提供良好的硬件支持[3-5].
供应链是对客户订单有兴趣的一组流程和实体[6].按照ISO规定标准,追溯是指通过记录物品的识别代码以实现追踪对象的空间变化[7].文献[8]按追溯粒度大小将追溯分为单品级追溯与批次级追溯;按追溯功能将追溯分为位置追溯、包含关系追溯.
在供应链整个生命周期内构建完整的包含关系追溯系统,应设计合理的追溯模型、编码机制及追溯策略等[9].本文主要研究支持包含关系追溯的编码机制,追溯需求主要为向下追溯、向上追溯、平行追溯和包含历史追溯,而在设计编码时,应考虑供应链应用环境的以下特征:
标签海量性.存在大量粘贴RFID标签的物品在供应链中流通.
标记对象数量已知性.物品流通前需要用RFID标签进行标记,因此供应链中标记对象数量已知.
包含关系多层级性.流通对象可分为物品对象、容器对象,因此形成多层级包含关系.
单体改变性.物品在流通过程中,可能会发生包装拆分和包装重组等操作,单件物品可能从某容器拆分到新的容器对象之中,改变原有的包含关系.
整体改变性.当某容器从其上层容器中拆分到新的容器中时,该容器中的全部对象整体跟随移动到新容器中.
包含关系的本质是层次关系,单体改变性和整体改变性是供应链中常见的包装拆装情况,而目前已有的层次编码策略较少考虑以上特征.因此本文在基于这些特征,深入研究RFID标签对象编码策略,以增强包含关系的可追溯性.
2 相关研究
追溯查询供应链中物品的包含关系,需要对所有流通在供应链中的RFID对象进行编码.包含关系可表示为树形结构,目前涉及层次关系的编码有素数编码、区间编码、前缀编码、向量编码及几何向量编码等.素数编码采用自顶向下的方式依次为编码树的每一层结点赋予一个素数[10,11],当某上层容器中的物品全部拆分到下层新容器中时需要重新分配素数且由于标签的海量性容易出现素数溢出情况,而且追溯查询时同余值的计算较为复杂,导致该方法的查询效率低,不适用于大型供应链场景.区间编码对树先序遍历,再对同一棵树后续遍历,使得每一个结点都可由一对整数表示,构成一个区间.文献[12]采用区间编码以实现对RFID对象的追溯,整数形式的编码使得查询效率高,但是由于供应链环境的单体改变性,当某容器中对象拆分到新容器时,需要重新遍历树来获取新的编码,因此该编码方式主要用于包含关系变化不频繁的场合.前缀编码的编码规则为父结点的编码是子结点的前缀,利用符号连接[13].该方法较区间编码而言更新代价小,但由于供应链环境下的标签海量性,查询时字符串的匹配时间长,导致查询效率低,也不适用于大型供应链场景.
文献[14]中针对XML文档提出向量编码,利用一对向量代替区间编码的区间值来给对象编码.向量编码的向量计算依赖于区间编码,结点由一对向量表示,基于两个向量之间可以插入无限多个向量的思想,可避免在供应链环境下插入新物品时需重新编码的情况,以此降低了更新开销,但是出现某容器中物品整体拆分到新容器中时,还是需重新编码才能反映正确的包含关系,并且由于标签的海量性,每一个对象都由一对向量表示导致存储效率低,存储开销大.为克服向量编码的不足,文献[15]在其基础上提出了几何向量编码策略(后续详细介绍),可避免重新编码情况发生,但该策略中存在数据溢出与数据碰撞问题.因此,本文拟针对这两个问题对几何向量编码进行优化,进一步提高编码及追溯查询性能.
3 编码准备
本节主要介绍编码的基础工作,包括RFID对象的包含关系、信息存储形式等.
3.1 包含关系
我们称粘贴RFID标签的对象为标记对象(Tag Objects,T),可分为简单对象与容器对象.
图1是一个包含关系树示例,其中TC1,TC2为两个包装箱,IC1,IC2,IC3为包装盒,S1,S2,S3等为具体物品,树中的层次关系表示了它们之间的包含关系.其中虚线部分表示供应链下两种不同的包含关系变化,图1(a)中为向容器IC2中加入物品S3,S4,对应供应链环境的单体改变性;图1(b)为向容器TC2中添加容器IC3及其包含的两个物品S5,S6,对应整体改变性.

图1 包含关系示例Fig.1 Example of containment relationships
定义1.简单对象是指不能包含其他标记对象的对象,可由二元组S =
按照追溯粒度的不同,简单对象可为单个物品或一批产品.考虑到包含关系追溯的一般性,后文所提的物品均为简单对象.如图1中简单对象S1,S2,S3等都位于包含关系的最底(内)层,设定其层级数l= 0.
定义2.容器对象是指包含其它标记对象的对象,可由四元组C =
容器对象可分为顶层容器对象,如图1中的顶层包装盒TC1,TC2,不能被其他容器对象包含,和中间层容器对象,如图1中IC1,IC2,IC3等,可被上层容器包含.
3.2 数据记录
简单对象和容器对象形成了多层级包含关系,在物品在流通之前由用户定义,存入如表1所示的对象表中.由于简单对象不能包含其他对象,因此只记录其tid与l的值,且其层级l为0,而包含容器的l值由底向上逐层递增.
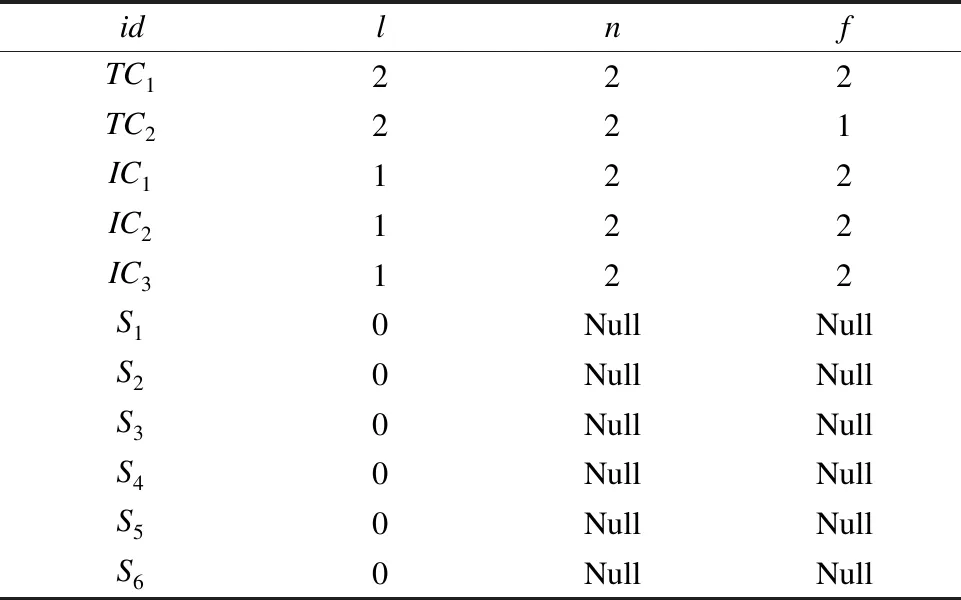
表1 对象表Table 1 Object table
定义3.每个标记对象都对应一条包含关系记录,可表示为一个四元组CR =
包含关系记录是在物品包装过程中动态生成的,存入如表2所示的包含关系表中.
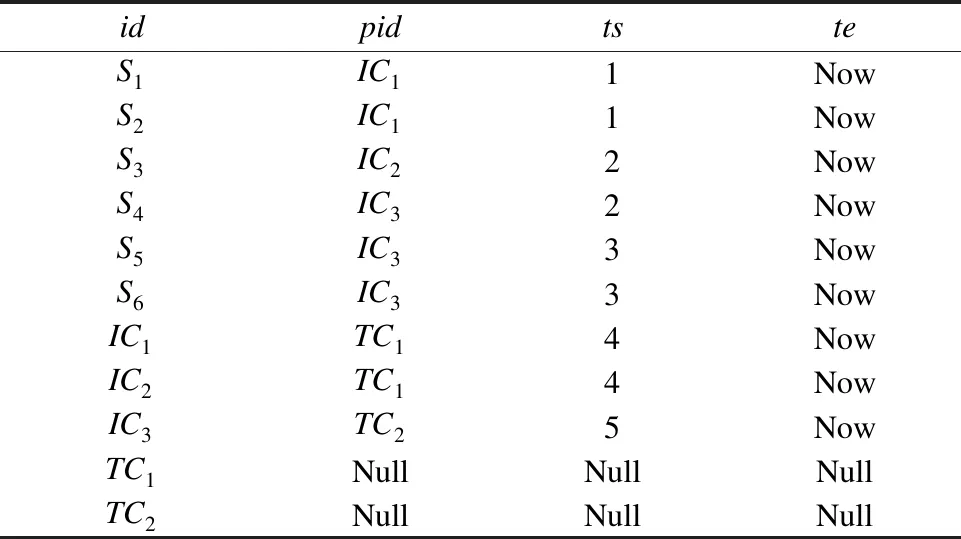
表2 包含关系表Table 2 Container table
3.3 建立关系树
为反映标记对象之间的包含关系和提高编码效率,我们可利用对象表和包含关系表,构建一棵满N叉树形式的包含关系树,其中结点表示标记对象,用于存储基本信息;边表示标记对象之间的包含关系,用于存储对象进入、离开直接容器的时间.由于简单对象数量、容器对象数量和容器对象容量等已知,故可对树进行统一编码.

图2 关系树示例Fig.2 Example of relational trees
以图1的包含关系为例,假设容器的最大容量为2,结合表1、表2建立的关系树如图2所示.其中,虚结点X为顶层容器对象的父结点.
对关系树进行初始化时,计算出所有结点的编码.可以看出,容器对象TC2的容量未满,仍给出了结点IC4与其包含的S7、S8的编码,但储存的信息为空值.当TC2有新对象加入时,只需增加时间信息,无需重新再编码,提高了更新效率.
4 几何向量编码优化策略
文献[14]提出的向量编码原理可用于供应链环境下的包含关系编码,但是不能直接利用其编码策略给标记对象编码.文献[15]在其基础上提出一种几何向量编码策略,解决了原向量编码存储空间开销大等问题.本节首先介绍几何向量编码基本原理、存在问题,然后提出优化策略.
4.1 几何向量编码及存在问题
几何向量编码策略[15]是基于两个向量间可以插入无限多个向量的思想,利用二维坐标轴第一象限中的向量进行编码.首先初始化虚结点为[1,0],[0,1],再根据容器对象的容量(n)来等分向量之间的夹角计算相应向量值.向量的插入规则为,假设容器对象A由向量a,b组成,以a向量末端为起点作与b平行的射线c,按照A的容量等分a,b之间的夹角与c的交点为插入向量的末端,由此生成下一层标记对象的向量.容器对象由一对向量表示,简单对象由一个向量表示,编码计算公式(1)如下:
(1)
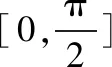
(2)
文献[15]证明了所有被近似处理后的向量间还保持原有的包含关系,但是原策略中对由公式(2)计算得到的向量值,直接采用向上取整的方式来得到最终编码.该策略虽然降低了编码的计算、存储开销,但存在数据溢出和数据碰撞的问题:
问题1.数据溢出问题.根据几何向量编码机制中向量的插入规则,当容器对象某一向量的倾斜角越大越靠近y轴,或倾斜角越小越靠近x轴时,会导致下一层插入对象的向量横、纵坐标值过大,造成数据溢出的情况.
问题2.数据碰撞问题.通过公式(2)计算向量得到xc和yc不为整数,文献[15]采用向上取整的方式对数据的小数位进行取舍.而直接取整会产生两个或两个以上对象由相同向量表示,因此会发生数据碰撞的情况.针对以上两个问题本文提出优化策略并证明其正确性.
4.2 优化策略
由公式(2)计算得到的向量,不直接采用向上取整的方式,而是提出新的数据优化策略,以解决问题1和2.现对二维坐标中第一象限的数据做以下处理:
1)扩大虚结点的初始值为[10l,0],[0,10l];
2)以坐标原点为圆心,画与包含层级l相同个数的同心圆,同心圆由内层到外层的半径比为1:10,第l层对象的向量取与第1个圆在第一象限的交点坐标,第l-1层取与第2个同心圆的交点,以此类推;
3)由步骤2)得到的结果不为整数,因此要对数据小数位进行取舍,保留与包含层级l相关的有效位数.
以图1包含关系中(S1,S2)⟹IC1⟹TC1为例,对其向量编码进行优化,如图3所示.
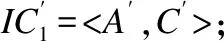
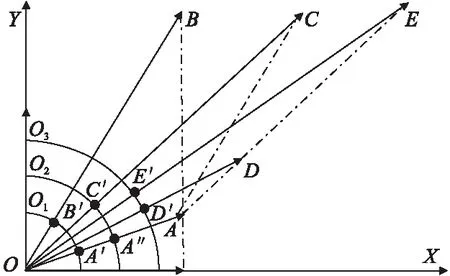
图3 向量优化示例Fig.3 Examples of optimize vector data
定理1.设A1[xa,ya]和A2[xb,yb]是某容器对象某一向量与同心圆O1,O2的两个交点坐标,ra,rb分别是半径等比例同心圆O1,O2的半径.当kra=rb(k为实数)时,则有kxa=xb,kya=yb.
证明:假设某过原点O的向量与同心圆O1,O2分别相交于A1,A2点,此时向量OA1,OA2与x轴的夹角为θ.因为同心圆O1,O2半径等比例,则有kra=rb.由于
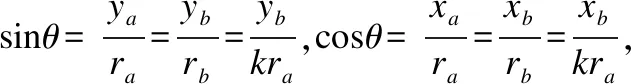
由此可证kxa=xb,kya=yb,成立.
以原点为圆心点,可以保证每层包含层级对应的圆为同心圆,由定理1可得,容器对象向量与每一层级圆的交点坐标为等比关系.由公式(2)计算后得到xc,yc再对其进行上述处理后得到计算公式(3):
(3)
利用同心圆优化向量坐标,可以保证同层级对象向量与同一圆相交,不同层级对象向量分别与对应层级圆相交,借此可以通过坐标大小来判断该向量所处的层级.容器P1的两个向量与同心圆组中O1相交,当往容器P1中增加下一层级的容器对象的时,容器对象P1的两个向量将会作为下一层级第一个容器的始向量,与最后一个容器对象的末向量,此时P1的两个向量会与同心圆组中的O2相交,容器对象P1的向量与同心圆O1,O2交点的坐标成比例,比例与同心圆半径比有关.
因此,利用公式(3)可以缩小向量末端横纵坐标值,以避免数据溢出的情况发生.
对于问题2,可根据供应链环境特征,确认包含关系的最大包含层级、容器对象的容量,根据实际调整虚结点X的初始值,当最大包含层级为l时,虚结点初始向量的始向量为<10l,0>,末向量为<0,10l>.同心圆半径取值有由内到外按照1∶10等例扩大.对由公式(3)得到的数据保留与包含关系层级有关的有效位数,使容器向量易于判断且可避免数据碰撞的情况发生.
尽管上述解决了数据溢出与数据碰撞的问题,但由于向量与同心圆取交点后做了近似处理,故需要证明所有向量进行优化后仍然满足原包含关系.

证明:由于
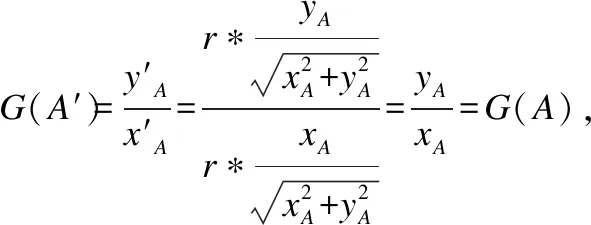
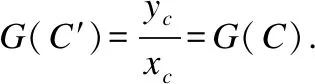
对于相交于同一个圆上的向量,经过数据优化得到的梯度满足于原来的梯度关系,因此当原包含关系满足G(A) (4) (5) (6) (7) C2计算同理.由于r>0,因此G(C1′) 定理1保证了坐标之间的等比关系.结合定理2、定理3可知在利用几何向量优化策略解决了问题1和2的同时,向量之间仍然保持原有包含关系,因此优化策略可行. 本节主要内容为先编码关系树中所有结点,再结合供应链环境下包含关系追溯需求和文献[15]中所述的包含关系变化,提出相应追溯查询算法. 根据前文编码原理、向量计算方式,可对关系树中的结点依次编码.从虚结点X开始深度优先遍历,由上至下逐层编码.编码过程即为向量计算和分配过程,将得到的向量对或向量作为标记对象的tid值.关系树中容器对象结点(非叶子结点)的向量计算和分配方式与简单对象结点(叶子结点)编码方式不完全相同. 1)虚结点X编码 给虚结点分配初始向量与最大包含层级数l相关:始向量Vs=[10l,0],末向量Ve=[0,10l]. 2)容器对象编码 在关系树中容器对象由树的中间结点表示,对其统一编码.首先根据父容器的容量按公式(2)计算分配n-1个等分向量,再利用公式(3)进行数据优化.根据实际包含对象数(f),依次为每个容器对象分配两个相邻向量,作为容器对象的tid.第一个容器对象的始向量横纵坐标为其父结点的始向量与该层级对应的同心圆交点坐标,且第m-1个容器对象的末向量与第m个相邻容器对象的始向量相同.容器对象编码的具体实现见算法1. 算法1.容器对象编码 输入:Vs,Ve,n,l 输出:Tid//所有容器的对象的编码 Begin 1.Tid→Vs,Ve;//数据初始化 2.r→0,tid=Tid,len=0; 3.for(i=1;i<=l-1;i++)://容器对象层级数为l-1 4.r=pow(10,i);//同心圆半径 5.for(j=0;j<=length(tid)-1;j++): 6. (xA,yA)→tid[j]; 7. (xB,yB)→tid[j+1]; 8.flag→ [0] ;//清空临时存储对象 9.for(m=1;m<=n-1;m++): 14.xc′,yc′→保留与层级有关的小数位数; 15. //存储所有容器对象向量 16.flag.append(xc′,yc′); 17.Tid.append(flag);//存储容器tid 18.len→len+length(tid);//获取上层容器数量 19.tid→Tid[len:-1];//获取该层容器对象tid End 3)简单对象编码 在关系树中简单对象由叶子节点表示,其向量计算与分配与容器对象基本相同,其不同之处为: ①将直接容器对象的向量夹角分成n+1等分后,计算n个向量; ②每个简单对象只分配一个等分向量. 基于以上编码规则,先利用公式(2)计算,再利用公式(3)进行优化,得到的向量作为简单对象的tid值.简单对象编码的具体实现见算法2. 算法2.简单对象编码 输入:Pid//l-1层容器对象的tid值 输出:Tid//所有简单对象的编码 Begin 1.for(j=0;j<=length(Pid)-1;j++): 2. (xA,yA)→Pid[j]; 3. (xB,yB)→Pid[j+1]; 4.for(m=1;m<=n-1;m++): 9.xc′,yc′→保留与层级有关的小数位数; 10.Tid.append(xc′,yc′);//存储所有简单对象向量 End 对RFID标记对象进行编码的主要目的是实现对流通物品的追溯查询. 定义4.假设标记对象A、B、C的包含关系为C⟹B⟹A.当A.l-B.l=1时,称A为B的直接包含容器对象(父容器);当A.l-C.l>1时,称A为C的间接包含容器对象(祖先容器). 定义5.如图1中的包含关系,称TC1、TC2为同容器对象,TC1、TC2与TC3为同层级对象. 根据以上定义,分别说明供应链环境下对包含关系追溯的主要需求: ·向上追溯.是指查询物品位于哪个容器内. 根据实际应用情况可细分为以下3种追溯情况: ·追溯祖先容器对象.先确定被查询对象的tid值,再通过包含关系表中对应的pid值来得到所有祖先容器,完成查询. ·追溯父容器对象.先追溯所有祖先容器,计算对应的l差值为“1”时,即为父容器,完成查询. 已知tid判断A是否为B的容器对象.根据编码规则,可直接利用tid进行判断.例如容器对象A的tid由Vs= ·向下追溯,是指追溯该容器中包含的对象. 可查找该容器对象包含的下一层级对象,或查找包含的全部对象.利用梯度关系可快速得出某一标记对象是否被该容器包含.向下追溯与向上追溯方法相类似,查询方法不多赘述. ·平行追溯,是指追溯物品与哪些物品位于同一容器内或处于同一层级. ·查询同容器对象.利用被查询对象的tid值先实现向上追溯查找父容器对象,再利用父容器的tid值来实现向下追溯,得到同容器中的全部对象. ·查询同层级对象.由于编码策略的优势,不同层级的对象向量中的横纵坐标值保留与层级数有关的有效位数,因此可以根据tid值中横纵坐标的小数位数来得出同层级对象的tid值. ·包含关系历史追溯,是指物品在供应链流通时,随时间发生包含关系变化后,追溯到它曾经存放过的容器. 供应环境下主要的包含关系变化有两种[15].第一种为往容器中添加未编码的新对象,由于给关系树编码时,已给出了编码,只需判断容器是否可以接收新对象,接收后直接赋予对象对应编码,而不影响已有对象编码;第二种为发生包含关系拆分重组的情况,从某一容器中迁出进入新的容器,为避免迁入对象所包含子孙对象重新编码,保持其子孙对象的编码不变,重新编码迁入对象即可. 当发生包含关系变化时,需要更新包含关系记录.包含关系历史追溯依据包含关系记录表中所有相关的包含关系记录,先利用向上追溯的方法查找查询对象的全部直接容器对象,然后按包含时间的先后排序,即可得到其包含关系的变化历史. 实验数据由模拟程序生成,首先模拟供应链环境下,贴有RFID标签物品的包装顺序,生成包含关系记录,再利用对应的对象表和包含关系表生成关系树,作为编码的基础.其中,最大包含层级数为4,初始化虚结点所处的层级为0,顶层容器对象个数为10. 实验对比分析的编码策略为文献[14]中提出的原始向量编码策略(Basic Vector Encoding,BVE),文献[15]中提出的近似几何向量编码(Approximate Geometry Vector Encoding,AGVE)与本文提出的几何向量优化策略(Geometry Vector Optimization Strategy,GVOS).实验主要对比以下4种性能指标:编码初始化时间、存储开销、编码更新时间、追溯查询效率. 顶层容器数量为10的情况下,分别比较每个容器在容量在不同情况下初始化时间,图4是三种编码机制的编码初始化时间比较结果. 从图4中可以看出来BVE的编码初始化开销时间最大,这是因为AGVE与GVOS都是在关系树的基础上直接计算和分配向量,而BVE则是先区间编码,再将区间编码转化为向量编码.AGVE的效率略高于GVOS这是因为GVOS在AGVE的基础上每个向量与同心圆取了交点,导致效率降低,但是GVOS解决了数据碰撞和数据溢出的问题,且由图5中可看出GVOS节省了大量的存储空间,因此效率差距在可接受范围内. 在顶层容器数量为10的情况下,分别比较每个容器在容量不同情况下编码数据存储开销.由图5可得出几何向量方法优于BVE方法,因为BVE编码时,无论是容器对象还是简单对象都由两个向量组成.而使用AGVE和GVOS编码时,简单对象仅由一个向量表示.因此在层级数相同的条件下,容器可以存放的简单对象数量越大,它们之间的存储开销差距也越大,由图5可以看出当标签达到百万级时BVE所需要的存储空间近乎是GVOS的3倍. 图4 编码初始化时间比较 图5 存储空间比较 图6 编码更新时间比较 分别比较两种更新方式(1)添加新容器对象时的更新效率;(2)已有容器对象插入的更新效率.在模拟程序中先构建一棵4层的关系树,第1,2层容器容量为10,第3层容器容量为100,最多可编码1百万个简单对象.再利用random函数随机生成插入层级,(1)类的对比结果如图6中实线部分所示.(2)类的对比结果如图6中虚线部分所示. (1)类更新方式,结果如图6实线所示,除BVE外其他2种编码机制效率相差甚微,原因是添加新对象时,几何向量方法是利用了向下追溯查找可插入容器的位置,再将编码关系树时计算得到的编码分配给新对象,而基本向量编码BVE则需要先寻找父结点及兄弟结点,再根据兄弟结点的编码值计算新编码,因此更新效率相对较差. 在(2)类更新中,由图6虚线结果可得,因为AGVE与GVOS只需利用向下追溯获取可插入位置,并给容器对象分配的当前位置编码(具体编码在初始化时已计算),因此AGVE与GVOS效率相差不大,而BVE不仅要对容器对象本身重新编码,还需对其包含的全部对象根据BVE编码规则重新编码,因此随着更新对象数量的增多,性能差距也越明显,当插入10000个对象时BVE耗时近乎是其他两个策略的4倍. 在供应链环境下主要有4种包含关系追溯,在模拟程序中构建一棵与6.3节相同的关系树,追溯查询性能对比结果如表3所示(查询结果单位:second). 6.4.1 向上追溯 对比追溯父容器对象的效率,按照5.2节中的查询方式进行查询,3种编码机制的对比结果如表3中向上追溯栏所示.由于GVOS的编码保留了与层级相关的有效位数,降低了查找容器对象的时间,提高了追溯查询效率.BVE的简单对象和容器对象都是由两个向量组成的,梯度对比时间复杂度高,因此追溯效率低. 6.4.2 向下追溯 获取随机生成的容器对象的编码,利用梯度关系追溯查询该容器包含的所有对象以实现向下追溯.效率对比结果如表3中向下追溯栏所示.由于GVOS机制的编码方式降低了梯度对比的时间复杂度,所以追溯查询效率高,而BVE的简单对象是由两个向量表示的,这样的数据结构增加了查询所需要的时间,当追溯数据越多时,效率差异越明显. 表3 追溯查询效率对比Table 3 Trace query efficiency comparisons 6.4.3 包含历史追溯 AGVE与GVOS可依据包含关系记录,先向上追溯查找被查询对象的全部直接容器对象,再按包含时间的先后排序,即可得到其包含关系的变化历史.实验对比结果如表3中历史追溯栏所示,由于包含关系发生变化时,BVE方法需要重新编码,无法直接判断出该容器是否发生变化,每一次查询都需查表,因此追溯查询效率低. 6.4.4 平行追溯 查询处于同一容器中的所有对象,先要对随机生成的被查询对象进行向上追溯,查找上层容器.在获取容器对象的编码后,再向下追溯,以此来实现平行追溯.效率对比结果表3中平行追溯栏所示.GVOS的效率最高,因为其向上向下的追溯效率高,而BVE简单对象由两个向量表示,因此BVE的效率最低,且当容器包含的简单对象越多时,效率差异越大. 为了提高在供应链环境下RFID对象包含关系的追溯效率,解决原几何向量编码策略中存在的问题,本文提出了优化策略.基于在从原点出发的两向量间可插入无数个向量的特性,提出了一种利用同心圆进行优化的几何向量编码优化策略. 该策略的基本思想是,利用坐标轴的第一象限,通过均分两个向量之间的夹角进行向量的计算和分配,再利用同心圆上对应的点成比例,且保持原梯度关系不变的思想来实现编码.与原几何向量编码方式相比,该方法降低了编码开销、提高了追溯效率,并解决了数据碰撞、数据溢出的问题. 通过实验对比分析,验证了所提出编码策略的可行性及有效性.下一步将基于所提出的编码策略,深入研究支持包含关系追溯的时态查询机制,进一步提高追溯查询效率.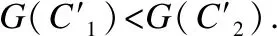
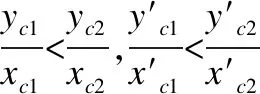
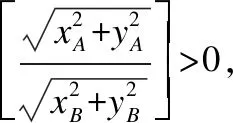
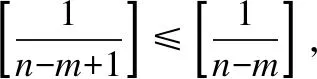
5 编码及应用
5.1 编码结点
5.2 追溯查询
6 实验结果对比分析
6.1 编码初始化时间
6.2 存储开销

6.3 编码更新时间
6.4 追溯查询性能
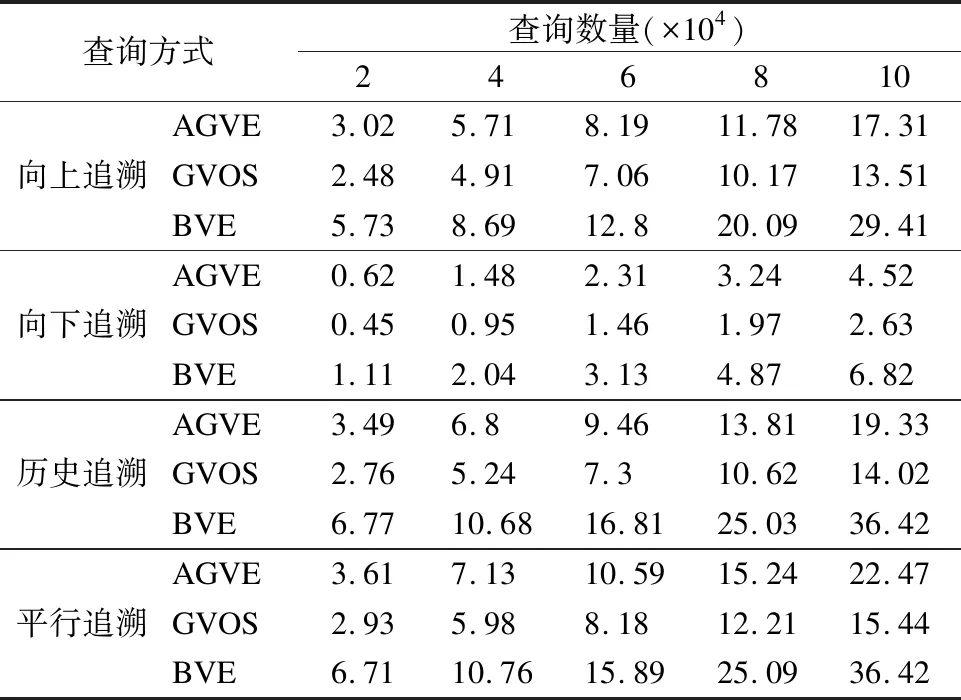
7 总结与展望
猜你喜欢
黄河之声(2022年1期)2022-03-16 02:41:22黄河之声(2021年21期)2021-03-22 03:27:08航天工业管理(2020年9期)2020-12-28 00:38:02华人时刊(2020年19期)2020-11-17 07:09:56军事运筹与系统工程(2020年1期)2020-09-11 06:41:00启蒙(3-7岁)(2020年7期)2020-07-08 03:13:28数学物理学报(2018年1期)2018-03-26 08:16:42系统工程与电子技术(2016年2期)2016-04-16 05:17:09电子设计工程(2014年12期)2014-02-27 11:58:23苏州市职业大学学报(2010年1期)2010-01-29 02:26:40
