
基于双层特征的彝语数据情感自动标注方法
2020-10-18 12:57张彩庆张云飞张德海李小珍
计算机应用 2020年10期
何 俊,张彩庆,张云飞,张德海,李小珍
(1.昆明学院信息工程学院,昆明 650214;2.云南大学外国语学院,昆明 650206;3.云南大学软件学院,昆明 650206)
(*通信作者电子邮箱369885901@qq.com)
0 引言
人工智能的蓬勃发展,特别是以深度神经网络(Deep Neural Network,DNN)为代表的深度学习方法获得突破性的进展,极大地促进了语音智能化的研究进程。然而,由于深度学习模型必须用大量准确的标注数据进行训练才能获得好的效果,近年来以人工为主的数据标注已经成为一个庞大的产业[1-2],但人工标注费时耗力、错误率高、质量参差不齐,因此自动或半自动数据标注的研究已然迫在眉睫。而情感是智能的一部分,是一种特殊的智能[3]。当前语音情感识别已成为人机交互领域的研究热点。由于公开的小语种情感标注数据非常少[4],特别是彝语情感标注数据属于稀缺资源,严重阻碍了彝语智能化发展进程。为了获得彝语语音情感标注数据,本文以扶贫日志中大量的彝语语音记录和文本数据为基础,结合彝语的特点,分别在声学层(Acoustics)和语言层(Language)提取识别特征,融合特征后用分类器进行训练,以获得大量自动标注数据,为彝语情感研究提供带标注数据资源,推进彝语智能化研究进程。
本文的主要工作包括:
1)针对彝语情感词缀丰富的特点,提出一种双层情感特征提取、融合和对齐方法;
2)设计彝语情感特征融合、对齐和自动标注算法;
3)通过该方法可获得大量彝语情感自动标注数据,为其他小语种数据标注研究提供方法参考。
1 相关工作
近年来,研究者们对数据标注进行了大量研究和探索,众包模式和许多商业平台应运而生[5-6],并催生出一个劳动密集型的数据标注产业。文献[7]中提出一种“兴趣+收获+报酬”数据标注模式,系统研究了社会标注模式的内在机理,所提出的标注策略在语音数据标注领域值得借鉴。然而,数据自动标注成为研究热点后,人们希望通过自动或半自动标注数据来取代人力,并在图像自动标注研究中取得较大成功[8-9]。但计算机生成的标注和人工标注仍存在较大差距,图像自动标注还有很多问题亟须解决[10]。在小语种数据标注方面,研究者们利用学习和分类模型实现半自动标注,并取得了一些成果。如:文献[11]中用隐马尔可夫模型(Hidden Markov Model,HMM)对没有时间标注的藏语训练语音基元进行自动标注,取得了比较接近人的效果,但没有扩展到整个语音数据标注。文献[12]中利用强化学习方法标注壮语的词性,并与神经网络结合来缓解模型对训练语料库的依赖。文献[13]中利用神经网络模型对韵律边界进行标注,融合了静音时长和文本特征融合,可提高标注的效率,该方法对本文研究有一定的启发。目前,语音情感识别研究工作在情感描述模型的引入、情感语音库的构建、情感特征分析等方面已取得长足发展。文献[14]中提出的FEELTRACE 情感标注系统为语音情感数据的标注提供了标准化工具;文献[15]中的面向语音情感特征提取开放式工具包openSMILE,实现了包括能量、基频、时长、Mel 倒谱系数等在内的常用语音情感特征的批量自动提取;文献[16]中提出的大型多媒体情感数据库SEMAINE为语音情感识别的研究和发展提供了公开的、丰富的、高质量的自然情感语料。这些研究成果为本研究工作提供了基础。
综上所述,国内外研究者对数据自动及半自动标注、图像自动标注等方面进行了大量研究,并取得一些成果。尽管目前在语音情感识别方面已进行多年研究,但在小语种情感数据标注方面的研究还处于起步阶段,而彝语数据自动标注的研究尚不多见。
2 双层特征提取
2.1 彝语情感标注
目前绝大多数语言情感标注研究工作的特征提取都集中在声学层,主要从韵律、频谱和音质等方面,以帧为单位进行提取。而彝语由东部、南部、西部、北部、东南部和中部六大分支方言组成,各分支方言语音存在较大差异。此外,彝语在发展过程中不断与汉语融合、演化,产生了大量汉语借来词,使文字和发音变得更加复杂。这些因素给彝语数据情感标注带来极大的障碍。但彝语除了在声学层具有丰富的情感外,在语言文字上也有丰富的情感词缀,这些词缀对情感识别和标注有很大的帮助。如表1所示。
因此,本文在传统语音情感特征单层提取方法的基础上,加入文字情感特征,提出双层特征彝语情感自动标注方法。本文方法的实现过程包括:彝语语料的声学特征和语言特征提取、特征融合及对齐、情感分类和训练、自动标注等步骤,彝语情感自动标注流程和框架如图1所示。
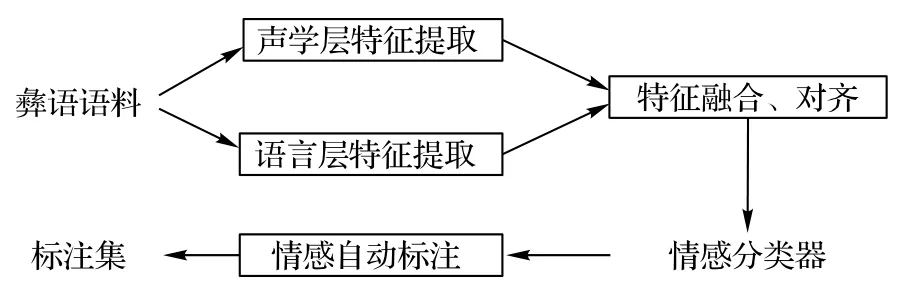
图1 彝语情感自动标注流程Fig.1 Flowchart of automatic emotion annotation of Yi language
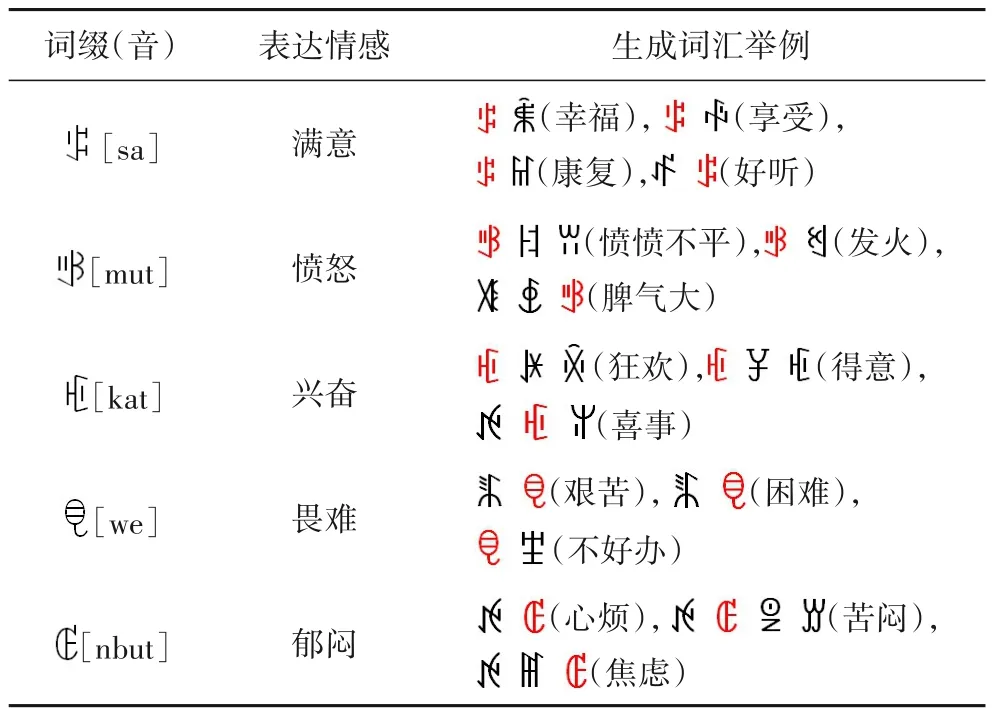
表1 彝文情感词缀示例Tab.1 Examples of emotional affixes in Yi language
2.2 声学层特征提取
情感特征提取的效果会直接影响情感自动标注的正确率。本文采取通用方法,从彝语语音中提取基频、共振峰和梅尔倒频谱系数三类特征。
1)基频特征。通过对语音的基音频率检测将不同语音区分出来。采用相关函数法[17]进行计算,如式(1)所示。
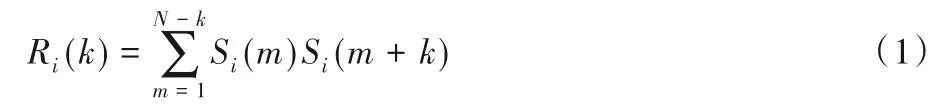
其中:Ri(k)表示第i帧自相关函数;Si(m)表示一帧语音信号的第m个采样值;N表示帧长;k表示时间的延迟量。函数与语音信号的周期一致,通过寻找自相关函数波峰的延迟即可找到语音信号的周期,从而进行基频标注。
2)共振峰特征。共振峰包含在语音频谱之中,频谱包含的最大值即为共振峰。采用线性预测法进行计算[18],如式(2)所示。
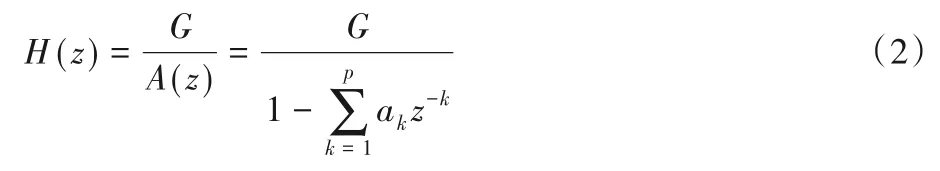
其中:G表示增益;p表示阶数;ak表示模型的系数。该方法能够在由预测系数构成的多项式中精确地估计共振峰参数,可以得到一组优良的语音信号模型参数。
3)梅尔倒频谱系数特征[19]。语音信号经过梅尔滤波器处理后可以得到近似人耳的频谱信号,通过信号提取得到频谱特征。计算方法如式(3)所示。

其中:f为采样频率;Q和D为语音的频率参数,需要根据彝语特点训练得到,Q通常在2 000 Hz左右,D在800 Hz左右,参数可通过模型训练得到。
2.3 语言层特征提取
按下列方法提取语言层特征:
1)n-gram 分词。利用n-gram 模型对彝文句子进行分词,分别提取unigram、bigram、trigram 特征,表示为集合Fu、Fb和Ft。
2)情感词缀特征提取。在分词基础上,按表1 示例的情感词缀特征进行分类,即按照含有情感词缀对词汇进行分类,记为集合Fc。结合分词特征结果集合,可以得到情感词汇集合,如式(4)所示。

3)词汇情感分类。将彝语情感分为7 种类型:中性(nertral)、生气(anger)、害怕(fear)、高兴(joy)、悲伤(sadness)、厌恶(disgust)、无聊(boredom)。在集合F中分别进行7 种情感标注,得到彝文情感词汇标注集。
2.4 双层特征融合和对齐
因为声学层和语言层特征分别在帧层面和词汇层面提取特征,完全在不同的问题空间中,要实现自动标注必须通过特征融合和对齐处理,之后才能采用分类器进行训练。下面介绍分层特征融合和对齐方法。
为了实现特征融合,可将帧层面的高维特征映射到词汇层面的低维特征,即从微观特征映射为宏观特征。设X=,X∈RD为帧特征的D维空间;,Y∈Rd为词汇特征的d维空间。其中:d<<D,则定义F:X→Y为帧特征空间到词汇特征空间的映射。由于帧和词汇都是可识别的,因此该映射是一个线性变换。
由于语音是由声道的连续运动而产生的,是一组前后相关性很强的序列。而语言特征则受到词法、字典以及语言模型的约束,二者均为强相关序列。可以利用各自的相关性和加入<Blank>单元实现对齐,如图2所示。

图2 双层特征对齐示意图Fig.2 Schematic diagram of double-layer feature alignment
参考生成式序列模型(Generative Sequence Model,GSM)思路,融合生成双层特征,如式(5)所示。
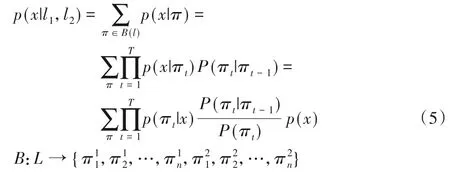
其中:l1和l2分别是声学特征序列和语言特征序列;π是融合后的特征状态序列,πt是第t个状态;P(πt|πt-1)是转移概率,P(πt)是先验概率;B是融合特征序列集合。

式(6)说明B决定了特征序列融合的集合,通过在l2的每两个词汇之间插入可选的<Blank>单元实现特征对齐。融合后的特征放入同一个特征空间,并作为同一个特征序列交给分类器处理。
3 特征融合分类器及算法
3.1 分类器选择
分类器一定程度上可能会影响自动标注的效果。为探索不同分类器对彝语数据情感标注正确率的影响情况,采用多种分类进行对比研究,寻求最佳方法。目前已有不少模型分类器被语音情感识别研究者们所尝试,使用最广泛的有隐马尔可夫模型(Hidden Markov Model,HMM)[11]、卷积神经网络(Convolutional Neural Network,CNN)[20]、支持向量机(Support Vector Machine,SVM)[21]、k最邻近(k-Nearest Neighbor,k-NN)[22]、长短期记忆(Long Short-Term Memory,LSTM)[23]等模型和算法。结合这些分类器在语音识别领域的性能表现情况,本文选择HMM、CNN 和SVM 三种代表性模型进行对比实验。
HMM 模型以句子为自动标注基本单位,每个HMM 将融合后的词汇特征序列为模型的观察状态,7 种情感类型为模型的隐含状态。利用训练数据集完成初始状态、转移矩阵等参数训练后,得出每一个彝语句子情感状态的预测结果,根据模型预测结果进行情感自动标注。CNN模型同样以句子为单位进行分类,第1层使用一维的卷积层,卷积核数设为16,第2层采用32 个卷积核,窗口长度确定为10,卷积步长设定为1,下采样因子为2。为防止过拟合,在训练中更新参数时按0.3的概率随机断开输入神经元。每个样本循环20 轮进行训练。不断调整优化参数,根据分类结果进行自动标注。SVM 模型的训练思路与传统的语音识别分类处理方法类似,先设置参数C和γ的值为0.2,然后再根据模型的表现,每次乘以0.1作为一个步长,搜索最优参数,直至模型训练完成,按照每一个句子的情感识别结果进行标注。先完成三种模型的分类训练,比较自动标注的效果,然后选择效果较优的方法完成后续实验。
3.2 特征融合算法
算法1 先分别提取声学层和语言层的情感特征再生成特征序列,然后根据需要插入<Blank>单元,最后将对齐后的特征序列进行合并。假设彝语语料按词汇为单位计算的长度为n,每个词汇的平均帧数为m,则最坏情况下的时间复杂度为O(n2×m)。若每次都是首次完成对齐,则时间复杂度O(n×m),因此可以采用适当调大模型的对齐阈值来减少时间开销。


3.3 自动标注算法
算法2 以句子为单位进行标注,根据分类器识别或预测结果逐一进行情感标注。若一个句子中出现大于一种的情感特征,如:同时出现“生气”“害怕”两种特征,则分类器会根据概率选择可能性最大的一种情感特征进行标注。

4 实验与结果分析
4.1 实验数据集
标注自动化程度与训练数据质量、模型性能、质量检测和纠错方法等都有密切的关系,其中模型性能与建模是否充分结合语种特点有较大关系。云南省少数民族精准扶贫日志数据库中记录了大量访谈语音和记录数据,其中一些彝族聚集区的语音是彝语数据,这些数据包含音源基本信息(姓名、性别、年龄、地址、时间等)。从数据中抽取原始语音数据并整理对应的彝语文字,筛选部分不含其他语种、噪声少、停顿少的优质语料作为实验数据。得到的彝语语音数据共840 min,其中男性460 min,女性380 min,对应的彝文有12 545 个句子,不含13岁以下儿童和70岁以上老人,音频格式以WAV为主,彝文格式为TXT 文件。实验数据集如表2 所示。发音和词汇区别都以北部方言为参照对象[24],区分方法参考《中文语音识别系统通用技术规范》(GB/T 21023—2007),且忽略个体发音区别因素。情感词缀占比是指该方言样本数据中带情感词缀的句子数占句子总数的百分比;发音区别占比是指该方言样本数据中发音有区别的句子数占句子总数的百分比;词汇区别占比定义类似[25]。
此外,手工标注部分数据采用Praat 工具完成,但标注过程难免会引入少量错误,为了降低实验难度,本研究忽略该误差,假设人工标注结果完全正确,并作为自动标注正确与否的参照标准。同时,由于分支方言间词汇区别不大,忽略该因素。

表2 彝语实验数据集统计数据Tab.2 Statistical data of Yi language experimental dataset
4.2 实验结果
首先,分别采用HMM、CNN 和SVM 三种分类器对样本数据的7种情感进行自动标注,实验结果如表3所示。
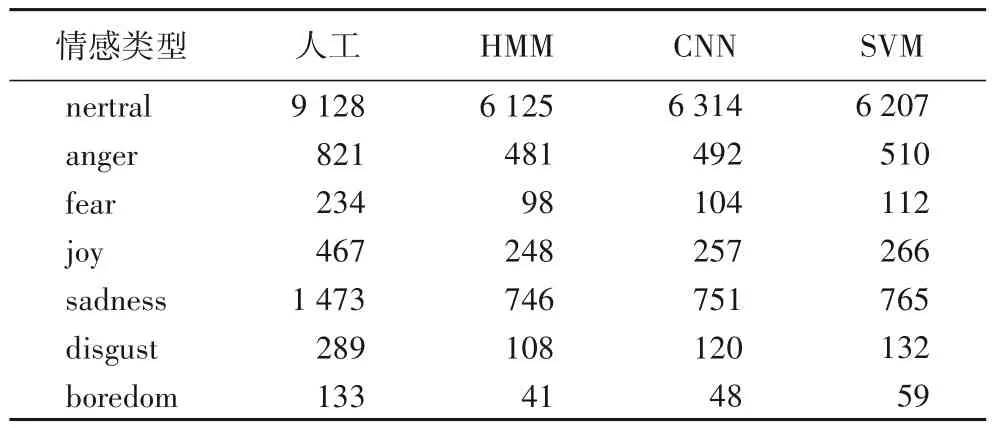
表3 三种分类器自动标注和人工标注正确句子数量比较Tab.3 Number comparison of correct sentences by automatic and manual annotation with three classifiers
表3 给出人工(Artificial)对12 545 个句子的标注结果和HMM、CNN、SVM 三种分类器自动标注的正确句子数量,标注结果按nertral、anger、fear、joy、sadness、disgust、boredom 等7 种情感类型进行句子数量的统计。为了便于比较,三种分类器自动标注结果只给出与人工标注一致的数量,即假设标注为正确的句子数量。
其次,以SVM 为分类器,分别对仅使用声学层特征、仅使用语言层特征和双层特征融合三类情况进行自动标注实验,实验结果如表4所示。
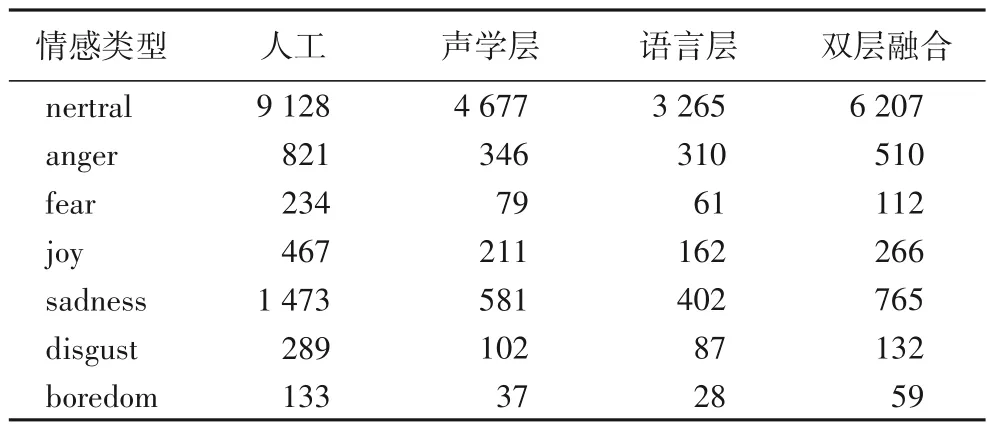
表4 四种标注方法正确句子数量比较Tab.4 Number comparison of correct sentences of four annotation methods
表4 给出上述四类标注方法的7 种情感类型的句子标注结果,分别是:人工标注(Artificial)、仅采用声学层特征的自动标注(Acoustics)、仅采用语言层特征的自动标注(Language)和双层特征融合情况下的自动标注(Fusion)四种结果。与表3 相同,三种自动标注方法(后三列)只给出与人工标注一致的数量,即假设标注为正确的句子数量。
本文将正确的自动标注句子数量与人工标注句子数量的比值定义为自动标注正确率,如式(7)所示。

其中:ALA表示自动标注正确率;ANCS表示自动标注正确句子数量;NMMS表示人工标注句子数量。
表5 是在表4 基础上对自动标注正确率进行统计的结果。
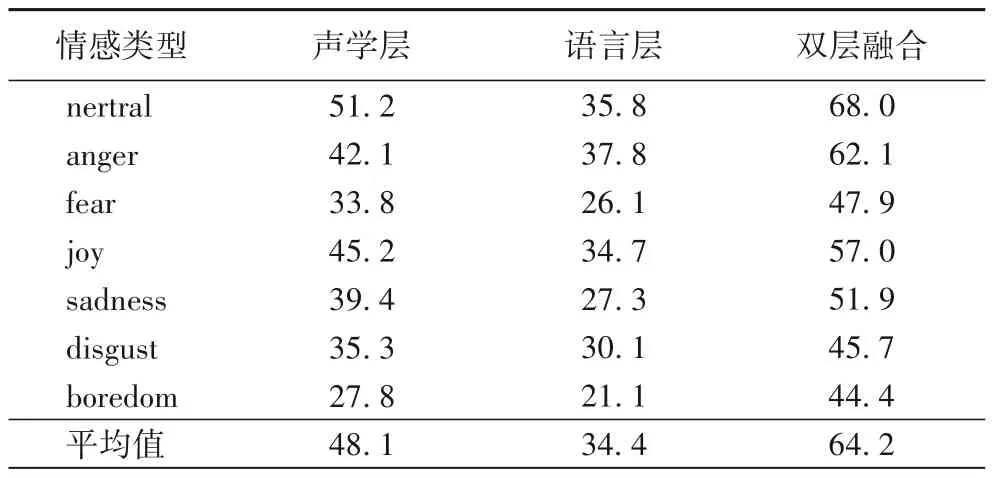
表5 自动标注正确率统计 单位:%Tab.5 Statistics of automatic annotation accuracy unit:%
4.3 实验分析
1)三种分类器自动标注和人工标注对比分析,结果如图3所示。结合表3统计结果可知,三种分类器自动标注的平均正确率为63.5%,其中HMM 为62.6%、CNN 为63.7%、SVM为64.2%,说明不同分类器对自动标注的正确率影响不大,而SVM 略优于其他两种分类器。另外,自动标注对不同情感类型的标注正确率有较大差异,下面将进一步对比。
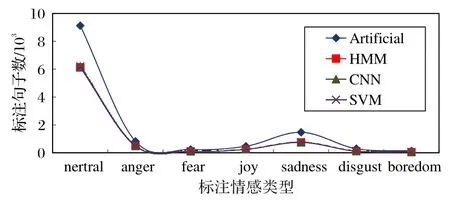
图3 自动标注与人工标注对比Fig.3 Comparison of automatic and manual annotation
2)自动标注数量和正确率对比分析如图4~5 所示。从图4 可以看出,四种方法标注的正确句子数量存在较大差异,其中:人工标注全部样本12 545个句子,Acoustics正确标注句子6 033 个,Language 正确标注句子4 315 个,Fusion 正确标注句子8 051个,说明双层特征融合方法的正确标注句子数量比仅提取一层特征方法有明显增加。
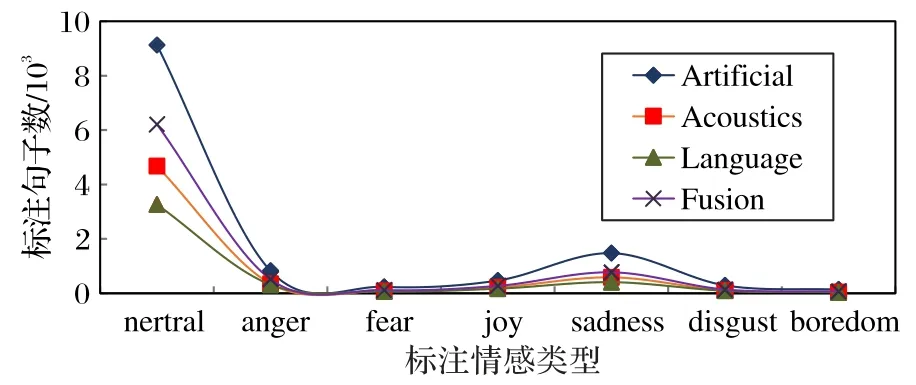
图4 四种标注方法的正确标注数量对比Fig.4 Number comparison of correct annotations of four annotation methods
结合表4 实验结果可以看出,Acoustics 的ALA为48.1%,Language 的ALA为34.4%,正确率并不高。Fusion 的ALA为64.2%,说明双层特征融合方法使自动标注的正确率明显提高。此外,从图5 可以看出7 种情感类型的ALA存在较大差异。
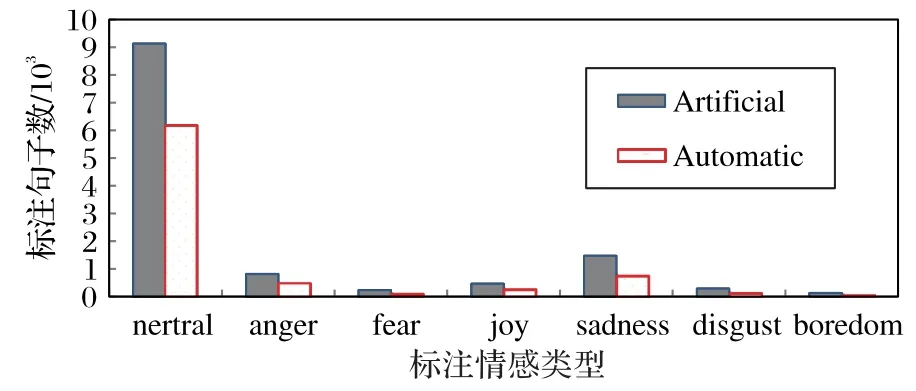
图5 自动标注与人工标注的正确率对比Fig.5 Accuracy comparison between automatic and artificial annotation
3)7个情感类型的自动标注结果对比如图6所示。从图6可以看出,除了nertral 情感类型标注正确率(67.6%)比较高以外,anger、joy 情感的标注正确率(60.2%、55%)明显高于boredom 和disgust 等情感类型,其中boredom 的标注正确率仅37.1%,说明不同情感类型的识别和自动标注效果差异较大,对生气、高兴等相对“外在”的情感类型自动标注正确率较高,而对无聊、厌恶等相对“含蓄”的情感类型更不容易识别和自动标注,是后续人工补充核查的重点。
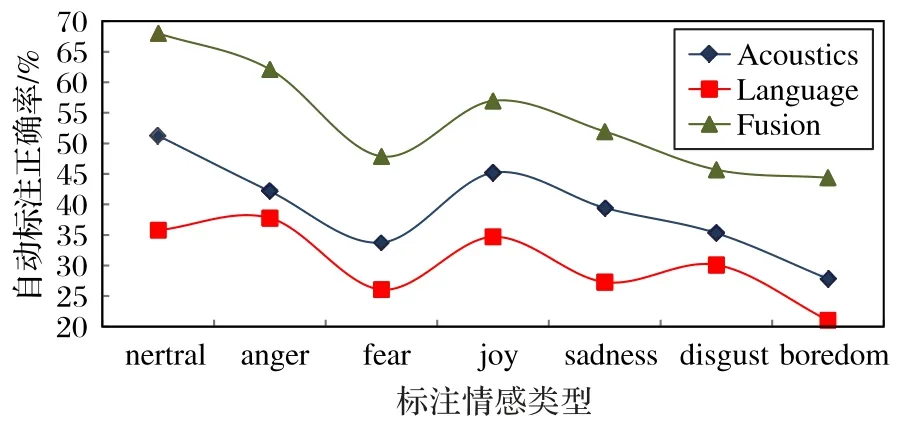
图6 双层融合标注与单层标注的正确率对比Fig.6 Accuracy comparison between double-layer fusion and single-layer annotation
综上所述,通过对比实验和分析可以得出结论:双层特征融合方法使自动标注正确率明显提高,从仅声学层的48.1%和仅语言层的34.4%提高到双层融合的64.2%。验证了本文所提出方法的有效性。三种分类器自动标注结果差异较小,而不同情感类型的自动标注效果差异较大,该结果可为后续人工核查提供参考依据。
5 结语
本文针对彝语的特点,提出分别从声学层和语言层提取情感特征并进行特征融合和对齐,再用分类器进行情感识别后完成自动标注的方法。从扶贫日志数据中筛选彝语语音和整理出对应的彝文作为样本数据,完成数据自动标注实验,并以人工标注的结果为参照进行对比分析。实验结果表明,本文提出的双层特征融合方法使自动标注正确率明显提高,验证了该方法的科学性和有效性。下一步可深入研究不同情感类型自动标注正确率提升方法。
猜你喜欢
医学食疗与健康(2022年3期)2022-04-23
电子产品世界(2022年4期)2022-04-21
健康体检与管理(2021年6期)2021-11-17
计算机系统应用(2021年2期)2021-02-23
计算机应用与软件(2020年1期)2020-01-14
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年9期)2019-05-30
计算机测量与控制(2019年4期)2019-05-08
电子制作(2019年24期)2019-02-23
小说界(2018年5期)2018-11-26
