
基于信任委托的区块链分层共识优化
2020-10-15 08:32段靓,吕鑫,b,刘凡,b
计算机工程 2020年10期
段 靓,吕 鑫,b,刘 凡,b
(河海大学 a.计算机与信息学院; b.海岸灾害及防护教育部重点实验室,南京 210098)
0 概述
区块链作为一种去中心化的分布式系统,链上的数据需要在全网节点间进行一致性分发和冗余存储,以此保证数据无法被篡改或伪造[1]。这一特性是区块链技术的优势,但也是区块链应用的瓶颈。区块链系统需要消耗大量的计算、存储和网络资源实现全网节点间的数据和业务协同,这使得区块链系统在业务处理上的性能远低于传统中心化的系统[2],而且网络规模越大,这种差异就越明显。
公有链的共识算法主要是从PoW(Proof of Work)和PoS(Proof of Stake)这2种算法上派生演化的,而联盟链共识算法则大多基于经典分布式一致性算法CFT(Crash Fault Tolerance)和BFT(Byzantine Fault Tolerance)[3-4]。无论是公有链还是联盟链,采用分片技术和并行技术都可以解决区块链平台扩展性问题。分片技术包括计算分片、通信分片和存储分片,例如公有链采用的多链、跨链等混合共识机制[5],联盟链采用的分组、分层共识机制等[6]。
本文提出一种基于信任委托的分层共识优化机制。该机制将共识网络划分成不同的子区域,子区域内的节点根据可信程度选举出代理人委托其参与全局共识。
1 共识算法
本文重点研究联盟链的共识算法,这是因为公有链目前最广泛的应用场景还是开放环境中的加密货币,而在政府和企业级应用场景中,节点都是经过身份认证的,因此多采用联盟链架构[7]。
联盟链中最通用的共识协议就是实用拜占庭容错(Practical Byzantine Fault Tolerance,PBFT),其本质是一种基于投票的共识机制[8]。当节点数增大时,共识交互消息会成几何倍数增长。如果节点分布在互联网上,网络延时会导致共识协议时间迅速增加,严重影响共识服务的吞吐量。为解决这一问题,业界主要从优化共识协议和改进共识架构两方面开展研究[9]。
1)优化共识协议。文献[10]提供一种基于聚合签名的优化方法dBFT,将m条消息签名聚合为1条,空间复杂度降为原先的1/m,但计算复杂度提升为O(3m)。文献[11]提出一种基于环签名的PBFT区块链共识算法改进方案,节点在环签名时自行组成环,使PBFT算法能够支持节点的动态加入与退出,从而提高超时导致的共识效率低下问题。文献[12]提出一种基于投票机制的优化算法VPBFT。通过引入投票证明将共识节点分成投票人、管理人、候选人和普通用户,候选人由投票人选举产生。生产节点根据任期内是否生成有效的数据块来获得相应的分数,分数高的节点将允许进入下一轮投票。该方法消耗的带宽是PBFT的2/3。文献[13]提出一种基于Gossip协议的PBFT算法。该算法将PBFT的消息广播改为利用Gossip协议,节点自行选择邻近节点进行信息交换。通过主动探测故障节点,使共识网络可以容错一半的节点,达到XFT容错能力。文献[14]提出一种不依赖计算能力的共识算法C-BFT。在主从多链模型中,使用时间阈值来约束各链之间的共识协作,动态调整节点间的通信延迟,确保主链节点在时间阈值内写入数据。另有一些算法采用基于DAG的分布式账本改进性能,通过节点中非同步的平行共识来加快数据传输。文献[15]提出一种基于Lachesis协议的PBFT算法ONLAY,使用分层和层次化的DAG图对数据进行异步排序以保障共识完成的时间。基于该算法的Fantom平台能达到300K TPS的吞吐量。
2)改进共识架构。无论是采用横向分片还是纵向分层扩展,其本质上都是将节点划分为各自独立的空间。文献[16]针对联盟链提出一种多中心动态共识机制,设计了一种主从多链结构,全局区块链链接多个主体区块链。每个主体(即中心)包含若干区块链节点,维护本主体的交易区块链(即从链),所有主体再共同维护全局区块链(即主链)。当构建全局区块时,每一轮都要由一个全局主节点从全网选出下一轮的全局节点,采用并行方式构建Merkle树。该方法采用验证群组来解决数据全局一致性的问题。文献[17]提出一种基于“组”的层次结构,将所有节点划分为若干组,每组有一个主节点。层次共识分为局部和全局2个阶段。首先,客户节点将请求广播给所有节点,每一个分组都要在组内进行一次请求的局部共识;然后,各个分组的主节点再进行一次全局共识,至此,整个请求才算完成。文献[18]提出一种可伸缩动态多代理层次化的PBFT算法SDMA-PBFA,可以将共识过程中的通信消息复杂度从O(n2)降至O(n·k·logkn)[18]。其基本思想是将节点划分为若干组,每个组选出一个节点作为代理人。客户节点请求先分发给所有代理人,代理人再在分组内部完成共识过程,最后由各个代理人通知客户节点请求完成。文献[19]同样采用节点分组的方式,每个分组有一个领导人,PRE-PREPARE、PREPARE和COMMIT 3个阶段都需要本组节点和其他组领导人节点参与。文献[20]采用树形拓扑构建共识网络,引入信誉模型降低错误节点在共识过程中的影响,但共识消息仍要通过子网的父节点分发到子网内进行三阶段共识。
尽管上述研究通过采用分片技术和代理人节点能够降低共识消息复杂度,提升共识性能,但却没有很好地解决以下问题:即如何对成员可靠性进行检测和评估,确保选出可信的委员会成员,以保障共识网络拓扑的稳定;如果委员会成员是高可信的,分片共识协议能否进一步简化,以提升共识网络的吞吐量,如果委员会成员行为异常,共识协议能否采取主动干预机制,以减轻共识请求时间的波动。
针对上述问题,本文提出一种基于信任委托的分层共识优化机制,在保证整体共识过程满足PBFT协议有效性、一致性和完整性要求的同时,降低每个阶段参与共识的节点数量,提升共识网络的吞吐量。
2 研究思路
本文的设计思想包含信任、层次化和委托3个核心概念。下文分别定义这3个概念的内涵。
1)信任。在社会治理领域,联盟链是更适合政府和企业构建行业应用的区块链方案。这是因为加入联盟链的节点需要经过审核和授权,节点的行为状态相对稳定,可以建立信任关系[21]。这里的“信任关系”不是主观设定的关系,而是根据节点在生成区块过程中的行为进行客观地评价。运行速度快、能和大多数节点形成一致共识的节点,其信任度就高;经常响应超时、共识消息发生错误的节点,其信任度就低。将节点依据信任度划分成不同类型的节点后,就可以为不同节点分配共识过程中不同的任务。
2)层次化。在各行各业的分布式业务系统中,业务节点的交互和数据都存在局部现象。这是因为社会网络作为一种复杂网络,宏观上有“小世界”,中观上有“群聚特性”,微观上有“中心性”“聚类性”等特征。联盟链在实际场景中,节点也同样具有小世界现象。例如大型机构设立分支机构,省局下设地市和区县分局,中心节点和边缘节点协同处理业务请求。基于此思想,可以将区块链平台在同一平面内的节点进行层次化,划分成若干个相互独立的子区域。节点的信任度只要根据节点与子区域内节点交互的行为进行评价,即只需得到子区域内的节点认可。
3)委托。委托是在完成节点层次化和建立的节点信任度之后进行的。每个子区域有信任度的节点能被其他节点委托参与共识,经常故障或状态异常的不可信节点不得参与共识。信任度高的节点可以作为子区域的代表,被委托参与各个子区域之间的协调共识。
本文的层次化不同于基于分片技术的共识算法。分片通常是指针对链上数据进行划分,构建不同的子链,而本文是针对节点的交互范围对节点进行划分,降低共识过程的网络复杂度。此外,基于信任度的划分,使得共识算法可以充分考虑节点的时延、抖动、吞吐量、失败率等性能指标,从而确保共识服务质量。
3 系统整体流程
本文提出的共识机制是一个基于“监控-评价-反馈”的流程,包含状态监控、信任度评价、委托代理人和分层共识4个部分,如图1所示。其中,节点状态监控是基础,信任度评价是核心,委托代理人是手段,分层共识是目标,4个阶段相互关联,循环往复。

图1 监控-评价-反馈系统流程Fig.1 Procedure of monitor-evaluate-feedback system
状态监控包括节点状态监控和共识过程监控。前者主要检测节点的网络和服务状态,例如服务是否在线、节点是否宕机等;后者则监控节点共识过程中的行为,例如完成消息的时间、共识的结果等。
信任度评价根据状态监控的数据计算节点信任度的各个影响因子,进而对当次共识过程中节点的表现进行评价。信任度更新则是结合节点过往信任度,合理稳健地更新节点的信任度,保障节点信任状态的稳定。
委托代理人则依据各个节点的信任度,选举出不同级别的代理人参与分层共识。在分层共识的过程中,共识算法还会依据节点的信任状态动态选择可靠的共识节点,识别故障或恶意节点,并提前干预,从而改善共识算法的性能,提升系统共识效率。
4 信任度评价
4.1 信任度定义

对共识节点可信度的评价主要基于节点的3种行为,即正常、故障和恶意行为。节点的不同行为会导致信任度发生相应变化。在上一轮评估信任度的基础上,正常行为会增加信任度,故障行为会减少信任度,一旦发现恶意行为,信任度直接归0。
根据信任度的大小进一步将节点分成4种类型。使用3个阈值Ctrust、Cnormal和Cabnormal分别表示可信节点、普通节点和故障节点的信任度下限,也就是各类型节点的信任度阈值,其值满足Ctrust>Cnormal>Cabnormal。Ctrust默认值为0.8,Cnormal默认值为0.5,Cabnormal默认值为0.2。系统初始化时节点状态均为普通节点,如果某节点长期稳定运行,性能优越,则随着其可信度增高,节点将会升级为可信节点;如果某节点运行不稳定,可信度会逐步降低,节点降级为故障节点;如果节点故障长时间得不到修复,可信度降至Cabnormal之下,或者被检测存在恶意行为,则将被立刻标记为恶意节点,并拒绝其参与共识过程。
4.2 信任度因子
信任度的计算基于对节点行为的评估,节点行为可以从不同角度描述。例如有的节点活跃度高,频繁参与共识,有的节点运行不稳定,经常超时等等。这些不同的表现可通过节点活跃情况、总体运行状况、事务影响程度、节点行为等因素来体现。这些因素可以统称为信任度因子。将这些相关因子以不同权重加入信用度的计算中,就可以通过信用度评价共识过程中节点的行为状态。
定义1(节点活跃度) 指节点在一定时间T内参与共识的频度,反映了节点在系统中的活跃程度。节点活跃度ρ(n)表示为:
(1)

定义2(节点共识完成率) 指节点完成其所参与共识的频度,反映了节点在共识网络中的运行状况。节点共识完成率γ表示为:
(2)
其中,s表示成功完成的共识次数,n为总共参与共识的次数,γ值随s与n比值增大而增大,γ越大表示节点越稳定。
定义3(节点历史影响度) 指节点历史信任度对当前信任度的影响程度。节点历史影响度ω(Δt)表示为:
(3)
定义4(事务重要级别因子) 用于标识请求事务的重要程度。设交易重要性参数为m,则事务影响函数F(m)可表示为:
(4)
其中,M0为交易重要性参数的阈值,本文取3,F(m)的值随m值增大而增大,F(m)越大表示事务重要程度越高。
定义5(行为评价值) 对节点参与共识过程的行为进行综合评价,行为评价值E表示为:
(5)
4.3 信任度的评价与更新
在每次共识过程完成后,系统会对各节点在本次过程中的表现进行评价。子区域i中节点j的信任度评价Sij表示为:
(6)
其中,Cinit为节点信任度初值,ρ(n)为节点活跃度,γ为共识完成率,ω(Δt)为历史影响度,F(m)为事务重要级别因子,E为行为评价值。该模型可以准确地反映节点在本次共识过程中的表现。如果节点活跃度高且共识的完成情况好,或者完成级别较高的事务获得较好的评价,都会使节点获得较高的信任度评价。反之,如果节点活跃度较低,无法完成共识过程,则会导致节点获得较低的信任度评价。
在完成对节点行为的评价后,需要以一定的策略更新节点的信任度,从而更新节点的信任类型。
设节点在开始共识前的信任度为Tij,本次共识过程完成后,节点信任度的评价值为Sij,则节点信任度按式(7)的规则更新:
(7)
其中,θ为信任度更新调节因子,若节点本次信任度评价高于往次,可适当调高信任度,反之则调低信任度。
如果节点因故障发生离线,信用度Cij会逐步衰减,即每次共识评价值Sij值为Cinit,直至Cij∈[0.9·Cinit,1.1·Cinit]或节点重新恢复服务。如果节点有恶意行为,信任度会变为0,后续该节点将被禁止参与共识。
信任度更新调节因子θ按式(8)的规则更新:
(8)
当本次信用度评价与前次评价值相差较大时,较小的信用度所占权重较大。这是因为当信用度评价值突然变大时,很有可能是节点在利用重要级别事务恶意提升自己的信任度,而该因子调节方式可以抑制信用度异常变化行为。
5 基于信任度的委托选举
当节点完成信任度评估并确认信任类型后,就可以依据信任度进行委托选举。
5.1 代理人选举过程
PBFT协议本质上是一种基于投票的共识机制,下面参照选举制度为例来阐述节点委托的概念。图2是一个三层的树状共识网络,其中节点包含4种类型:1)三级代理人节点,由信任类型为普通的节点组成,如果把每个子区域看做一个州,其类似于州一级的议员;2)二级代理人节点,从其直接子节点(即图2中三级代理人节点)中的信任类型为可信的节点中选出,可以代表其所有子节点,类似于国会议员;3)一级代理人节点,从全网二级代理人节点中选出,具有最高的共识权重,类似于大选中获胜的总统;4)非共识节点,通常是故障或恶意节点,不参与共识过程,由于选举是自下而上的,当低一级代理人升级为高一级代理人之后,其空缺的位置将根据节点信任度排名自动递补。
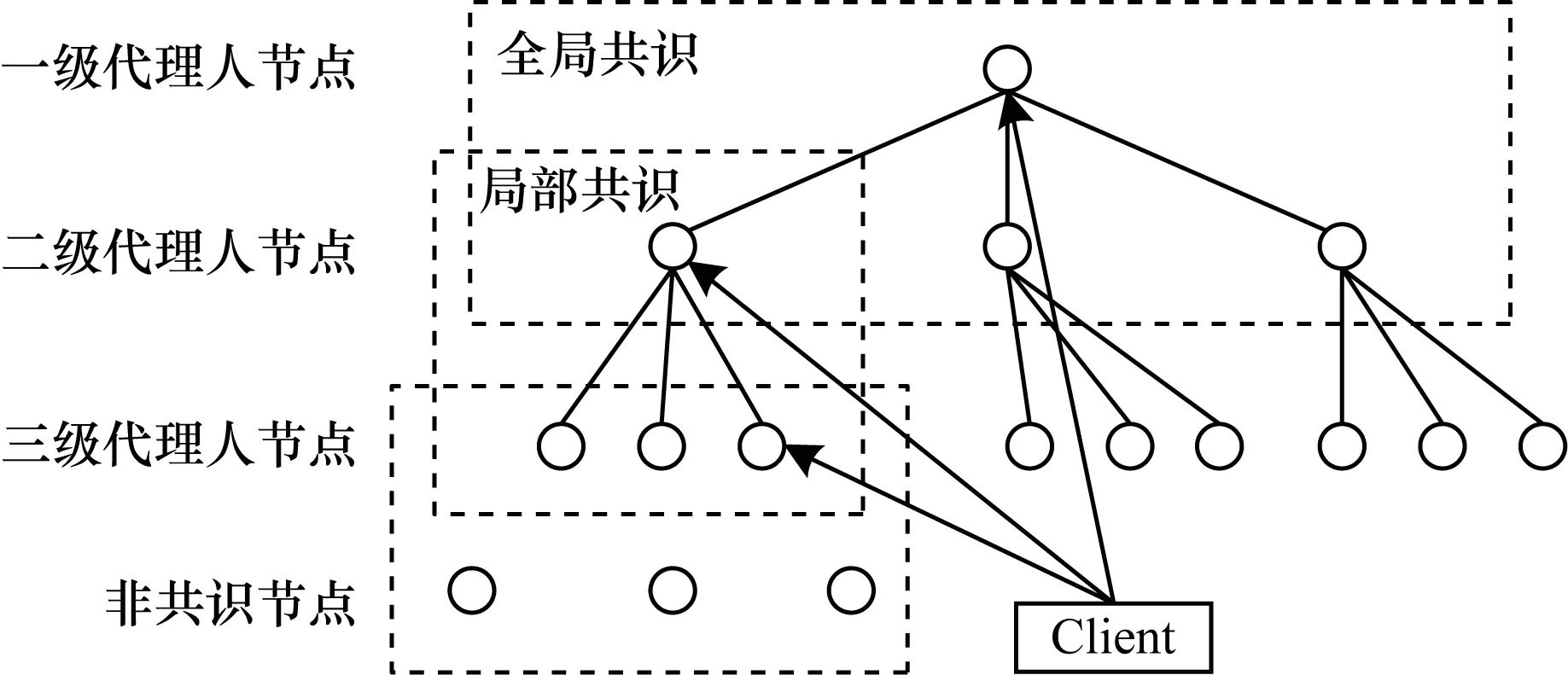
图2 分层共识网络架构Fig.2 Hierarchical consensus network architecture
在系统初始化阶段,根据应用需求、网络环境等条件预先规划树状网络结构,并根据节点的处理能力设置初始时各级代理人节点。在节点完成组网后,各级别节点分工合作,实现对全网节点请求事务的共识过程。类似于各级议员和总统分工合作实现对国家事务的治理。
为降低全网共识过程的通信复杂度,将共识分为局部和全局两级共识过程。首先是各个子区域内的节点进行局部共识,子区域的二级代理人节点负责定时生成区块,二级和三级代理人节点会先对区块进行一次局部共识过程,类似州议员投票形成一个州议案。全网所有的二级代理人和一级代理人再对区块进行一次全局共识过程,对区块进行最终确认。其他子区域的二级代理人节点将区块异步地分发给各自区域内的三级代理人节点,更新其节点的账本数据库。类似国会议员和总统对州议会的提案进行投票,形成全国性的法案,并将法案分发给其他各州执行。
与其他基于分组的PBFT共识机制不同之处在于,由于采用了基于节点信任度的授权,参与全局共识的节点是可信节点,可以代表其所在区域的所有节点进行共识投票,这样极大地降低了共识的通信复杂度。
平台将根据各级节点在共识过程中的表现(如完成共识的时间)确定节点的信任度。当某个代理人节点的信任度低于特定的阈值或因故障不能正常提供服务时,平台将重新选举新的代理人。当重新选举时,如果是二级代理人节点,则仅需要本区域内的节点完成一次选举;如果是一级代理人节点,则需要全网节点重新进行选举。
5.2 模型形式化定义
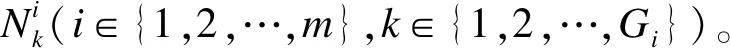


定义9(代理人节点状态) 代理人节点分为:1)正常状态,即节点可以在规定时间内完成共识过程;2)故障状态,即节点因为服务器宕机或网络中断导致的故障状态,该故障状态如果能在指定时间内恢复正常状态,则可以不重新选举代理人节点;3)异常状态,即节点被检测出恶意破坏和攻击PBFT共识过程,此时,该节点被排除出共识网络,系统重新选择代理人节点替代其职能。
定义10(法定选举票数) 共识网络完成共识过程需要的全网节点的最少票数。一个共识节点只有一张选票,但二级代理人节点在全局共识时可以拥有子区域内的所有选票,类似大选中的赢者通吃策略。
定义11(票数权重) 一级和二级代理人节点在进行全局共识过程中代表其子节点票数的权重。如某个二级代理人节点下有10个三级代理人节点。当权重为100%时,其全局共识算作10张选票。当权重为50%时,其全局权重算作5张选票。票权随着节点信用度的变化而改变。
定义12(区块) 区块链上的区块由一组请求事务及其哈希值组成,表示为B=([tx1,tx2,…,txk],h)。区块在全局有唯一的序号s。
定义13(局部共识) 每个子集合内的节点执行PBFT协议,完成共识过程,得到一个局部合法的区块。
定义14(全局共识) 代表各个子集的二级代理人节点和一级代理人节点执行PBFT协议,对局部共识进行二次共识过程,得到最终全局合法的区块。
6 分层共识过程
本文提出的基于信任授权的分层共识协议TDH-PBFT,其核心思想是通过对共识节点进行划分后,利用不同子区域的局部共识和委托代理人的全局共识降低传统PBFT协议连接的节点数量,从而降低完成共识的时间,提高系统的吞吐量。
6.1 代理人选举
在联盟链共识网络中,各级代理人节点可以由管理方预先设定,也可以随机从节点中选择。当节点运行一段时间,更新节点信任度之后,即可以依据信任度定期选举各级代理人节点。
代理人选举算法如算法1所示。
算法1TDH-PBFT代理人选举算法
输入对等数量n,对等节点N[n],组数m,节点组数G[m][n],三级代理人节点数TD_number[m],投票人权重FD_weight,SD_weight[m]
全局变量:FD,SD[m],TD[m][n],FD_credit,SD_credit[m],TD_credit[m][n]
1.procedure TDHPBFT_ELECTION()
2.for I ← 0,m do
3.TD[i][n]←delegatorElection(G[i][n],TD_number[i]+1)
4.end for
5.SD[m] ← delegatorElection(TD[m][n],1)
6.FD,k ← delegatorElection(SD[m],1)
7.SD[k] ← delegatorElection(TD[k][n],1)
8.TD[k][n] ← delegatorElection(G[k][n],1)
9.end procedure
H-PBFT初始化算法首先从各个子集中选取三级代理人节点。这里选择的数量要比指定的三级代理人数量多一个,因为被选出的三级代理人节点将再执行一次delegatorElection,推举出二级代理人节点。同样,二级代理人节点将选举出拥有最高共识权重的一级代理人节点。假设被选中的一级代理人来自第k个集合,此时,由于k集合二级代理人晋升导致其岗位空缺。该集合将先从三级代理人中补选一个二级代理人,再从普通节点中增补一个三级代理人。
不同信任状态的节点拥有不同的权限。可信节点权限最大,通常是一级、二级代理人节点,或者有机会作为候选人被选为一级、二级代理人节点。普通节点作为三级代理人节点正常参与局部共识过程。故障节点虽然状态不稳定,但仍然可以参与共识。但是一旦共识消息响应超过时限,二级代理人节点可以在满足允许的容错节点数量前提下,主动放弃等待其返回的消息。恶意节点不参与共识,应及时通知系统管理员进行故障修复。
6.2 分层共识算法
TDH-PBFT分层共识协议分为本地共识和全局共识2个阶段执行:
阶段1(子集内部的本地共识阶段) 子集内的二级代理人节点发起本地共识。由于子集内有不少于4个节点参与共识,即节点数大于3f+1,因此可以抵御f个恶意节点的拜占庭攻击。共识过程分为PROPOSE、WRITE和ACCEPT 3步。二级代理人节点首先向其他节点广播PROPOSE消息。其他节点验证PROPOSE消息后就进入WRITE阶段,广播WRITE消息。当各节点接收到2f+1个WRITE消息后,节点进入ACCEPT阶段,广播ACCEPT消息。当各节点接收到2f+1个ACCEPT消息后,表示大部分节点对二级代理人节点发起的请求达成了共识。此时,阶段1的本地共识完成。
阶段2(子集间的全局共识阶段) 在本地共识阶段完成后,接收到足够数量消息的二级代理人节点,将作为成员参加全局共识过程。首先向一级代理人节点和各个子集的二级代理人节点广播PROPOSE消息。这里各子集二级代理人不需要再将消息转发到子集内部进行本地共识,而是作为各自子集的全权代表对消息进行投票,具体代表的票数通过投票权数控制。例如,某个子集内有4个节点,投票权重为100%,二级代理人节点拥有4张票权,若投票权重为50%,则拥有2张票权。按照此规则,各节点开始广播WRITE消息。当各节点接收到2f+1个WRITE消息后,节点进入ACCEPT阶段,并广播ACCEPT消息。当各节点接收到2f+1个ACCEPT消息后,表示大部分节点对二级代理人发来的请求达成了共识。此时,阶段2的全局共识完成,一级和二级代理人将区块写入账本。各子集的二级代理人通知子集内部其他节点,各节点更新本地区块链账本,实现共识网络数据的最终一致性。
分层共识协议消息示意图如图3所示。

图3 分层共识协议消息示意图Fig.3 Schematic diagram of hierarchical consensus protocol messages
分层共识算法如算法2所示。
算法2TDH-PBFT分层共识算法
1.Initialisation
2.s ← 0
3.B ← ⊥
4.D ← ⊥
5.accepted ← {⊥}
6.
7.Local propose phase
8.send LOCAL_PROPOSE
9.
10.Upon LOCAL_PROPOSE
11.s ← sp
12.B ← Bp
13.begin Local write phase
14.
15.Local write phase
16.D ← digest(B)
17.send LOCAL_WRITE
18.wait for majority of LOCAL_WRITE
19.send LOCAL_ACCEPT
20.
21.Upon LOCAL_ACCEPT
22.if Dp= D then
23.accepted ← accepted {delegator}
24.if accepted contains majority of delegators then
25.begin Global propose phase
26.
27.Global propose phase
28.send GLOBAL_PROPOSE
29.
30.Upon GLOBAL_PROPOSE
31.s ← sp
32.B ← Bp
33.begin Global write phase
34.
35.Global write phase
36.D ← digest(B)
37.send GLOBAL_WRITE
38.wait for majority of GLOBAL_WRITE
39.send GLOBAL_ACCEPT
40.
41.Upon GLOBAL_ACCEPT
42.if Dp=D then
43.accepted ← accepted {delegator}
44.if accepted contains majority of delegators then
45.decided on B
6.3 投票权数调整
在经典PBFT算法中,一个节点只拥有一张票权。建立可变票权机制可以进一步优化共识算法,增强共识算法的容错能力。
节点的投票权数是根据节点的信任状态决定的。可信节点通常具有更高的票权,用Vtrust表示为:
(9)
其中,Nabnormal为故障节点数量,Ntrust为可信节点数量,N为参与共识的节点总数。从式(9)可以看出,故障节点数增加或可信节点数减少都会提升可信节点的投票权数。
普通节点投票权用Vnormal表示为:
(10)
其中,Nnormal为普通节点数量,其权重同样受到故障节点和普通节点数量的影响。如果当前系统内没有可信节点,可以进一步提升普通节点的票权,如式(11)所示:
(11)
故障节点投票权用Vabnormal表示为:
(12)
故障节点投票权数主要取决于故障节点占共识总节点数的大小。故障节点越多,其票权就越低。恶意节点没有投票权,则不参与共识过程。
6.4 基于信任度的共识优化
利用节点的信任度,可以在共识开始前和WRITE、ACCEPT消息完成后进一步优化共识过程。
如图4所示,当共识过程开始时,二级代理人节点先将各节点按信用度高低排序。排除恶意节点,将可信节点、正常节点和异常节点作为本次共识的节点。
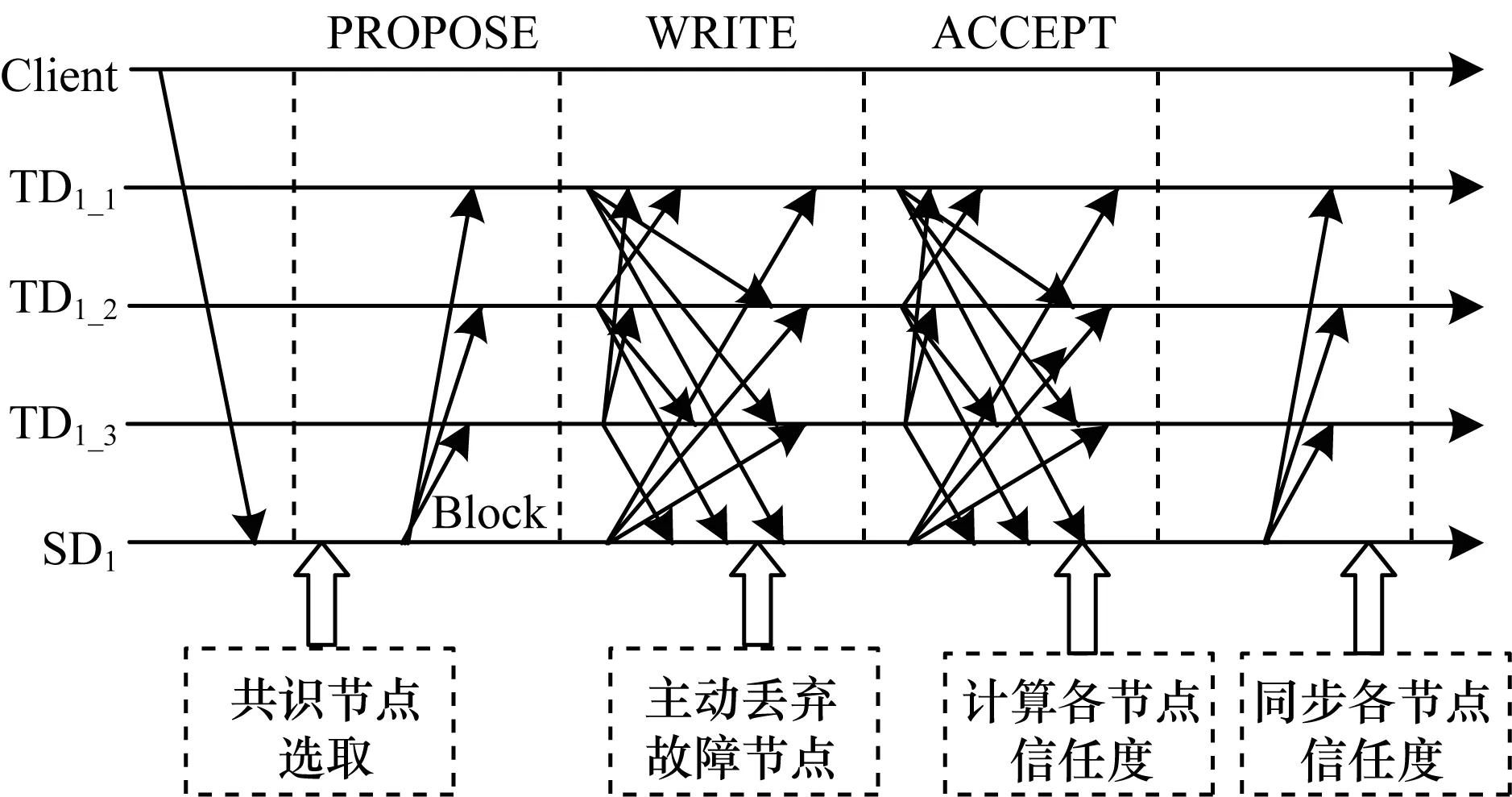
图4 基于信任度的共识过程优化示意图Fig.4 Schematic diagram of consensus process optimization based on trust degree
在WRITE阶段,三级代理人节点将WRITE消息广播给其他共识节点,当二级代理人节点收到2f+1个确认消息后,进入ACCEPT阶段。如果此时有节点的消息没有正常返回,或者有恶意消息,在保证2/3共识节点数量的前提下,该节点将被移除,不再参与后续共识。二级代理人节点通过ACCEPT消息的附加属性将移除的节点通知其他三级代理人节点。
在ACCEPT阶段,三级代理人节点将WRITE消息广播给其他共识节点,当二级代理人节点收到2f+1个确认消息后共识达成。二级代理人记录各节点在共识过程中的行为和状态,计算并更新节点信用值和节点信用状态,再将各节点最新信任度表广播给各个三级代理人节点。
6.5 分层共识一致性证明
下文证明采用TDH-PBFT协议实现分布式一致性,并且满足分层共识网络的活性和安全属性。
证明由于TDH-PBFT协议包含了局部共识和全局共识2个阶段,下面将通过分析2个阶段中协议的执行过程来证明TDH-PBFT可以实现分布式一致性。
综上所述,TDH-PBFT共识过程是2个连续的PBFT过程,且区块序号在2次协议执行中保持不变。由于PBFT协议已被证明实现了分布式一致性,因此TDH-PBFT在全局共识协议中实现了一致性,满足区块链网络的有效性、一致性、完整性和全序关系等属性。
引理1TDH-PBFT协议满足分层共识网络有效性Validity。
1)如果二级代理人SDi未被错误怀疑,则所有参与全局共识的节点都会对区块B达成共识,即所有无故障的二级代理人节点都会获得B,并将该区块分发给各自区域内的节点进行提交。如果某个二级代理人发生故障,它会先根据全局故障恢复机制得到处理,并最终获取区块B。因此,请求tx将最终在共识过程中被提交。
引理2TDH-PBFT协议满足分层共识网络一致性Agreement。
证明如果某个子区域i内的节点N提交一个请求tx,根据分布式共识服务的“连续序号”和“不重复请求”属性,则有:1)该节点所在区域的二级代理人节点SDi必然提交了包含tx且序号为s的区块B;2)区块B必然已经完成了一次全局共识;3)各级节点必然已经获取了所有小于序号s的区块;4)没有任何小于序号s的区块会包含tx。由此可得,在分层共识网络中,如果正常状态的代理人节点接收到序号为s的区块B和序号为s′的区块B′,若s=s′,则B=B′。
引理3TDH-PBFT协议满足分层共识网络完整性Integrity。
证明假设某二级代理人节点SDi发送了序号为s+1的区块Bs+1,根据分布式共识服务的“连续序号”和“不重复请求”属性,则必然有某二级代理人节点SDj已经提交了序号为s的区块Bs,且该区块已经完成全局共识,并被各节点提交至账本。二级代理人节点SDi在发起请求s+1前,使用哈希函数对本地账本数据库存储的前一个区块s进行签名,将得到的哈希值H(B)和最新的tx事务一起打包。这样新的区块Bs+1必然满足哈希链完整性。
引理4TDH-PBFT协议满足分层共识网络全序关系Total order。
证明假设来自子区域i和j的2个客户节点ci和cj分别发起了事务请求txi和txj。子区域i和j各自的二级代理人SDi和SDj将对txi和txj打包成区块Bi和Bj。下面分两种情况来说明该引理成立。
1)如果ci和cj位于同一个子区域,则SD将按照请求提交的时间对txi和txj进行排序。接下来txi和txj可能都被按序打包进序号为s的区块B中,当区块完成全局共识分发至各节点后,txi必将先于txj被提交至账本。txi和txj还有可能分别打包进序号为s的区块Bs以及序号为s+1的区块Bs+1。由分布式共识服务的“连续序号”属性可知,Bs将先于Bs+1完成全局共识并被提交,则txi也将先于txj被提交至账本。
2)如果ci和cj位于不同的子区域,则有txi和txj分别被SDi和SDj打包至区块Bi和Bj中。
(1)由于客户节点ci在执行请求事务时,必须选择至少包含FD、SDi和TDki在内的3个代理人节点。3个节点返回的事务执行结果必须相同,即保证账本数据库在全局和局部完全一致,客户节点才会将请求发送给SDi,从而开始2次共识过程。
(2)一级代理人节点FD拥有的全局事务视图,是协调各个子区域请求事务顺序的关键。
SDi在将事务tx打包成区块B时,将询问FD其区域允许打包事务的开始和结束区间。当区间内没有键值修改冲突时,例如txi先于txj修改了键为k的值,SDi将按照预定的区块大小或默认时间间隔进行打包。这样,Bi先于Bj被提交参与共识,可确保Bi中的事务txi先于txj被提交至账本;否则,假设txj先于txi修改了键为k的值,SDi将打包至SDj修改k的前一次修改事务到区块Bi,SDj将从修改k的事务开始打包Bj。此时,当Bi和Bj完成全局共识后,Bj中的事务txj先于txi被提交至账本。
综上可得,TDH-PBFT协议满足分层共识网络的全序关系要求。
7 实验评估
为深入了解TDH-PBFT模型的运行机制,使用SimPy模拟器对其运行流程进行建模。SimPy是基于进程的离散事件模拟器,它包含实体(Process)、事件(Event)和资源(Resource)3个主要概念。在TDH-PBFT中,实体主要是各级代理人节点,事件包括局部和全局共识的PROPOSE、WRITE、ACCEPT等。为了便于对比参照,还使用SimPy实现了标准的PBFT算法以及单纯采用分组的H-PBFT算法。H-PBFT算法中,各分组的头结点用于转发其他分组的消息,而并非像TDH-PBFT算法,代表组内节点直接参与共识。
首先比较3种共识算法在系统节点数为17、49、97这3种情况下的性能,主要考察吞吐量和延时2个指标,PBFT的性能数据是实验的基准线。从图5和图6可以看出,PBFT算法性能随着节点数的增多而下降。吞吐量从3 164 TPS迅速下降至1 233 TPS,下降了61%。事务请求平均延时从750 ms增大到1 103 ms。基于分组的H-PBFT共识算法性能有所改善,这得益于分组降低了全网共识消息。TDH-PBFT的吞吐量是三者中最优的,随着共识节点数从17增大到97,吞吐量仅下降了14.7%。节点数为97时的事务请求平均延时为762 ms,接近PBFT算法在节点数为17时的延时。该实验展现了TDH-PBFT共识算法具有良好的伸缩性能,可以有效缓解当共识网络节点数增大时,消息数量爆炸导致的性能下降。

图5 不同共识算法下系统吞吐量的对比Fig.5 Comparison of system throughput under different consensus algorithm

图6 不同共识算法下系统延时的对比Fig.6 Comparison of system delay under different consensus algorithm
然后比较区块大小对系统性能的影响。分别选取0.5 MB、1 MB、2 MB和4 MB 4种取值,这也是实际系统部署时常选取的4种取值。从图7可以看出,当区块大小从0.5 MB增大到2 MB时,系统吞吐量从6 023 TPS增加到7 989 TPS,增加了33%。但单个事务请求的平均延时从608 ms增大到753 ms。这是因为增大区块大小可以减少共识次数,提升系统的整体处理能力,但对于个别请求,等待打包的时间增加了其请求时长。当区块大小从2 MB增大到4 MB时,系统吞吐量增加了2%,系统延时也进一步增大。可以看出,此时增加区块大小对系统性能提升的作用已不显著,2 MB是TDH-PBFT算法首选的区块大小值。
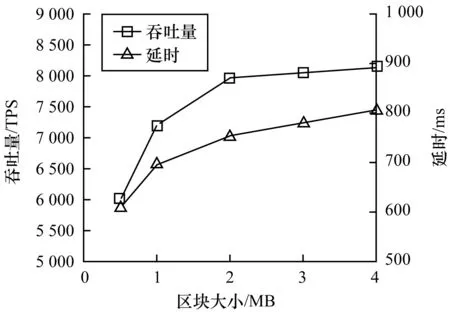
图7 区块大小对系统吞吐量和延时的影响Fig.7 Influence of block size on system throughput and latency
最后比较共识节点部署在不同类型网络下的系统性能差异。选取17个节点的共识网络,第1类场景模拟所有节点全部都在局域网环境内,节点之间使用百兆网络互连。第2类场景模拟节点混合部署,即一级和二级代理人之间的全局共识网络使用10兆网络互连,二级和三级代理人之间的局部共识网络使用百兆网络互连。第3类场景模拟所有节点全部都在互联网环境内,节点之间使用10兆网络互连。从图8可以看出,3种算法在有节点处于互联网环境时,随着共识时间变长,吞吐量均会下降。但无论在哪种网络类型下,TDH-PBFT的吞吐量都是最优的。即使在完全互联网环境中,TDH-PBFT的性能也优于H-PBFT在完全局域网环境的性能。分层共识算法减少了共识消息的数量,使网络带宽对共识算法性能的影响降到最低。

图8 网络对系统吞吐量的影响Fig.8 Influence of network on system throughput
8 结束语
为优化大规模联盟链网络的共识过程,本文提出一种基于信任委托的分层共识优化机制。根据节点运行状态建立信任度,选举出可信的代理人节点进行局部和全局2次共识过程,从而降低消息广播的数量,提升共识网络吞吐率。实验结果表明,该模型能够满足联盟链平台的性能扩展性需求,当全网节点数增大时,系统依然可以保持较好的性能。在TDH-PBFT共识算法中,二级与三级节点配比、权重票数和全局共识阈值等参数均对系统性能产生显著影响,后续将对参数的作用做进一步研究。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
专利代理(2019年3期)2019-12-30
专利代理(2019年4期)2019-12-27
专利代理(2019年1期)2019-04-13
金桥(2018年4期)2018-09-26
环球时报(2018-01-23)2018-01-23
专利代理(2016年1期)2016-05-17
汽车维护与修理(2015年5期)2015-02-28
中国卫生(2014年5期)2014-11-10
