
一种用于网络用户行为聚类的标签自动生成方法
2020-10-15 08:32毕猛,邵中,徐剑
计算机工程 2020年10期
毕 猛,邵 中,徐 剑
(1.沈阳工业大学 软件学院,沈阳 110023; 2.东北大学 软件学院,沈阳 110169)
0 概述
随着云计算、物联网、移动计算等技术的快速发展,微博、微信及网络直播等自媒体社交公众平台不断涌现,网络用户正在实现从信息消费者向信息缔造者的转变,然而网络是社会现实的镜像,网络用户行为不仅会影响虚拟网络,而且会直接反作用于真实社会,影响人们的日常生活[1-3]。对于庞大的网络用户群,其所表现出的行为各具特点,若要向这些用户群提供高效、安全、个性化的网络服务,则需要对网络用户行为进行分析并建立有效的分析模型。网络用户行为分析综合运用统计学、人工智能、大数据、心理学、社会学以及其他与网络用户行为分析密切相关的理论和方法,对网络用户的构成、特点及其行为活动所表现出的内在规律进行分析,进而对网络用户的行为进行预测、管理和控制,达到为政府、企业及个体用户服务的目的[4-6]。
聚类算法是数据挖掘的一个重要研究领域,其能够以较高的效率获得全局范围内的数据分布特征,已在网络用户行为分析中得到广泛应用[7-9],但是目前典型的聚类算法(如K-means算法等)更多关注聚类效果,并且在网络用户行为分析过程中存在用户行为数据规模需在聚类前确定,用户行为数据聚类后生成的簇无明确语义的问题。
对于以K-means为代表的聚类算法,需要事先确定用户行为数据的规模(即簇的个数)才能进行聚类[10],但在实际应用中,用户行为数据规模很难确定,并且聚类后所产生的簇个数通常为未知,甚至在数据快速增长时簇的个数也可能会发生变化。因此,此类聚类算法在面对海量网络用户行为数据时通常聚类效果较差。另外,由于聚类一般不需要有标签的数据,因此生成的簇也没有标签,即没有明确的语义,也无法获知每一个簇所代表的类别[11]。然而,在实际应用中如果无法逐一遍历每个簇内的数据,则不能确定簇所代表的类别。目前,除了文本聚类算法利用文字出现频率作为标签外,多数聚类算法无法为簇生成有效的标签。而对于海量网络用户行为数据而言,如果生成的簇无标签,则需要用户为每个簇人工赋予标签来达到用户行为分析的目的,但是该任务的工作量非常庞大,而且人工语义标签的生成效率也很低。
针对上述问题,本文结合潜在因子模型(Latent Factor Model,LFM)[12]和矩阵分解等方法,提出一种用于网络用户行为聚类的簇标签自动生成方法。该方法包括用户行为数据缺失值处理、网络用户行为聚类过程中的簇标签自动生成以及簇标签评价等具体过程,并利用AP[13]和DP-means[14]等聚类算法及实际用户行为数据进行实验验证。
1 相关工作
目前,已有众多学者利用聚类算法对用户行为进行研究。文献[15]利用K-means算法并结合关联规则对银行客户进行聚类以生成簇标签。文献[16]通过分层聚类与卡方检验对文件进行聚类并生成标签。文献[17]将层次聚类算法与文本关键词抽取算法相结合生成微博用户的标签,该标签不包含同义标签,可以从多方面体现出网络用户的兴趣。文献[18]对K-means算法进行改进,解决了其依赖初始聚类中心的问题,在此基础上设计一种面向网络用户行为的喜好标签聚类系统。文献[19]采用文本聚类算法对网络用户的文本内容进行聚类生成标签,并将数据处理为矩阵形式,同时利用匈牙利算法提高生成标签的准确性。文献[20]基于支持向量聚类算法提出一种快速且稳定的簇标签生成方法来提高聚类过程的准确性,解决了因支持向量聚类算法时间复杂度高导致生成标签准确率降低的问题。
虽然上述方法可以在聚类的同时生成簇标签,但是其都是针对具体应用场景提出的解决方案,缺乏通用性。为此,本文提出一种用于网络用户行为聚类的簇标签自动生成方法,以解决目前多数聚类算法需要事先确定用户行为数据规模以及生成的簇缺乏明确语义的问题。
2 设计思想
本文依据用户行为数据的属性特征,对用户行为进行聚类,并且在聚类过程中增加行为特征作为参与元素,同时利用这些行为特征信息产生簇标签,提出一种用于网络用户行为聚类的簇标签自动生成方法,具体流程如图1所示。
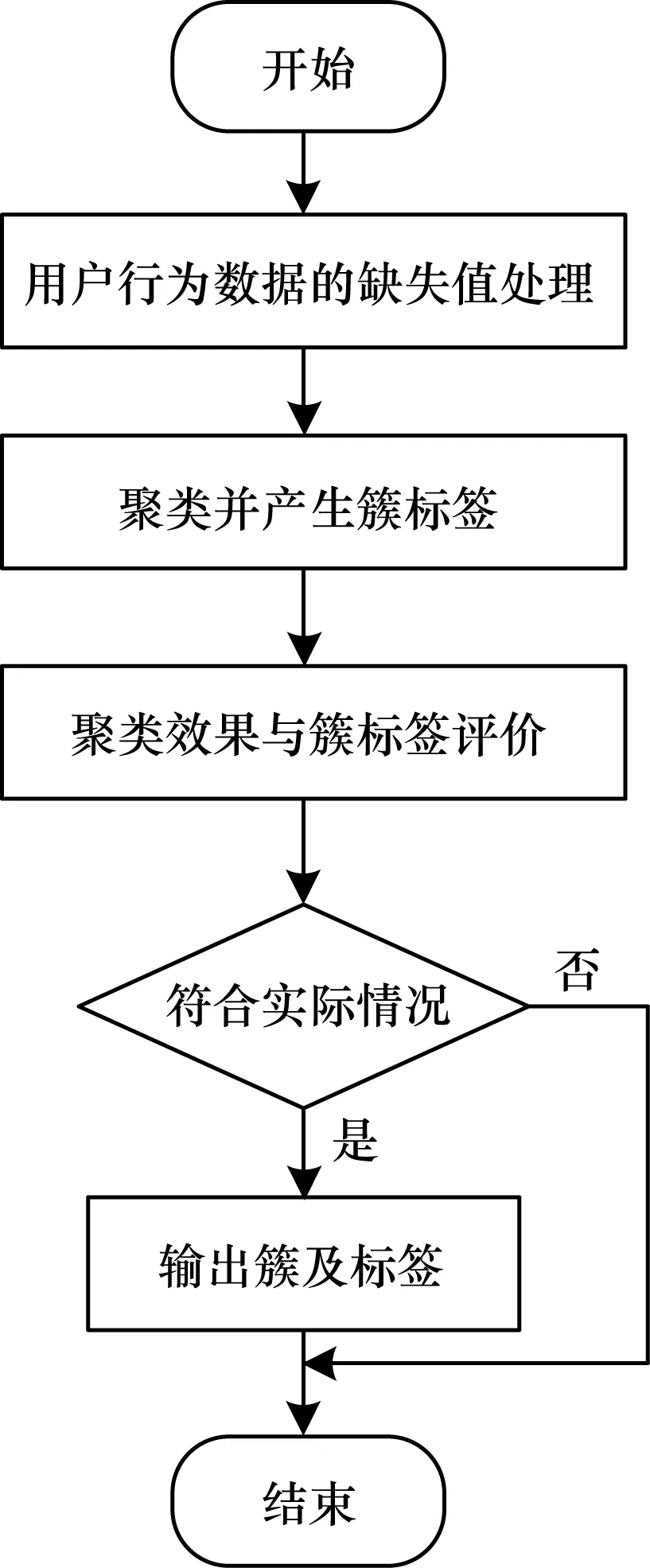
图1 用于网络用户行为聚类的簇标签自动生成流程Fig.1 Procedure of automatic cluster label generation method for clustering of network user behavior
用于网络用户行为聚类的簇标签自动生成方法的具体步骤如下:
步骤1用户行为数据的缺失值处理。在当前网络环境下,收集用户行为及其特征。以用户在网络上收听歌曲为例,如果用户通过网络收听说唱类音乐,则说明该用户行为具有时尚、潮流等特征,然而搜集的特征数据存在缺失值情况,例如用户对某首歌曲的收听次数通常与喜欢程度成正比,但是未听过该歌曲并不代表不喜欢该歌曲,由于搜集的数据通常只包含用户听过的少部分歌曲,而没有听过的歌曲对原始数据集而言就是缺失值,因此需要对存在缺失值的数据做预处理,从而找到缺失值。
步骤2在用户行为聚类过程中产生簇标签。将用户行为与行为特征相结合后可对聚类后的簇添加标签,使其具有较明确的语义,例如对于购买最新款iPhone手机的某一类人群可添加时尚、潮流等标签。
步骤3聚类效果及簇标签评价。评价聚类效果并对生成的簇标签进行检验,同时判断是否符合实际的用户聚类情况。
步骤4输出符合要求的簇及其对应的标签。
3 用于网络用户行为聚类的簇标签自动生成
3.1 符号描述
在用户行为聚类过程中使用的相关符号及其定义如表1所示。

表1 符号及其定义Table 1 Symbols and their definitions
3.2 簇标签自动生成过程
3.2.1 用户行为数据的缺失值处理
由于网络中收集的用户行为数据会存在缺失值,因此本文采用潜在因子模型(Latent Factor Model,LFM)对原始用户行为数据进行预处理。LFM是一种矩阵分解算法,将原始高维数据分解为潜在因子矩阵,从而实现稀疏矩阵分解和数据降维。
给定一个大小为m×n的稀疏矩阵d,m表示用户数目,n表示行为数目,k表示潜在因子个数,通过LFM可以得到一个大小为m×k的矩阵p和一个大小为k×n的矩阵q,如式(1)所示:
dmn=pmk×qkn
(1)
LFM计算的核心思想为在迭代过程中,通过优化数据集的矩阵分解误差值来找到合适的p与q,如式(2)所示:
emn=dmn-qnk×pmk
(2)
其中,emn表示矩阵分解误差值,k值若小于原始高维数据的维度,则可实现降维效果。由于通过调整k值可以分解出不同的矩阵,因此k值会影响矩阵分解的误差结果。
根据收集到的原始数据构建用户-行为矩阵D,如式(3)所示:
(3)
其中,dij表示用户i与行为j的关系,包括行为执行次数、行为执行程度等,若用户已执行该行为,则不为空,若用户未执行该行为,则为缺失值。由于通过原始数据构建的矩阵D为稀疏矩阵,其包含缺失值且维度较高,因此会增加聚类难度及降低聚类效果。
构建用户行为-标签矩阵G,如式(4)所示:
(4)
其中,矩阵G为包含缺失值的稀疏矩阵,行表示用户,列表示用户行为特征,共有m个用户和n种行为。
由于D为稀疏矩阵,且利用LFM通过潜在因子对矩阵D进行矩阵分解可以得到低维矩阵p、q,因此将p、qT相乘可以补全矩阵D,如式(5)所示:
D≈p×qT
(5)
对于矩阵q,通过式(6)计算得到潜在因子-标签矩阵H,并以此作为簇标签自动生成算法的输入。由于p为用户-潜在因子矩阵,且潜在因子个数小于D的原始维数,因此矩阵分解能够实现降维的效果。
H≈qT×G
(6)
3.2.2 簇标签自动生成算法
簇标签自动生成算法的具体过程如下:
步骤1将用户-行为矩阵D分解为p、q两个矩阵,再根据q×G构建用户行为潜在因子-标签矩阵H。
步骤2使用聚类算法对矩阵p进行聚类,取每个簇的平均值,得到每个簇的簇中心及用户聚类矩阵C。
步骤3将用户聚类矩阵C和潜在因子-标签矩阵H相乘得到用户标签矩阵T,对矩阵T内的数值进行排序选出前t项作为用户标签。
算法1簇标签自动生成算法
输入用户-行为矩阵D、用户行为-标签矩阵G
输出簇-标签矩阵Q
1.(p,q) ← matrix factorization(D)
H ←q×G
2.C ← clustering algorithm(p)
for i ← 1 to size(C) do
Si← {px∈Ci|x=1,2,…,N}
Centeri← mean(Si)
end
Q ← Centeri×H
3.Seq=Sort(Q)//对矩阵Q进行排序,得到每个簇的
//标签序列
Labeln=Find(Seq)//查找前n个标签
在簇标签自动生成过程中利用矩阵分解算法找到潜在因子,补充矩阵D中缺失值的特征,将D分解得到矩阵p、qT。使p、qT相乘得到补全缺失值的矩阵D′,但由于该矩阵维度过高,此时聚类效果不理想,因此对p进行聚类,将qT与G相乘得到潜在因子-标签矩阵H,如式(7)所示:
(7)
在p聚类后,通过两种方式为聚类后的簇自动生成标签:
1)对簇内的数据取平均值得到每个簇的簇中心,如式(8)和式(9)所示:
Si={x∈centeri|px}
(8)
Ci=means(Si)
(9)
其中,Ci为每一列中的较大值,表示该簇具有较强的维度特性,即对应的潜在因子容易被发现,因此只要将该簇对应的潜在因子-标签关系矩阵相乘,即可得到簇-标签矩阵Q,计算公式如式(10)所示:
(10)
Q中的每一列均表示一个簇的标签,例如赋予第一个簇n个标签,可从q11,q12,…,q1t中取出最大的n个值作为该簇的标签,或是给定一个阈值,若超过该阈值,则视为该簇的标签。
2)找出所有数据的对应标签,由于p表示用户与潜在因子的关系,且H表示潜在因子与标签的关系,因此p×H可视为用户与标签的关系,利用该矩阵统计簇内的标签数量,并将出现次数最频繁的前n个标签作为此簇的标签。
3.2.3 簇标签评价算法
在用户行为聚类过程中每个簇都会生成多个标签,因此需要给出标签评价方法评估标签与簇之间的适合程度。假设x属于ptest中的一个数据样本,且x被分配到簇c中,TP表示x和c共同拥有的标签数量,FP表示x没有而c拥有的标签数量,FN表示x拥有而c却没有的标签数量,TN表示x和c都没有的标签数量。
F1 score是簇标签得分,其计算公式如式(11)所示:
(11)
其中,Precision表示准确率,Recall表示召回率,其计算公式如式(12)和式(13)所示:
(12)
(13)
将矩阵p分为ptest和ptrain两部分,选取80%作为训练数据集进行聚类并给出标签,20%作为测试数据集。簇标签评分的具体过程如下:
步骤1根据ptrain聚类结果,利用相同的聚类算法将ptest分配到ptrain已有的簇内,同时根据ptest×H得到测试集中用户所代表的标签。
步骤2根据式(12)和式(13)计算准确率与召回率。
步骤3根据式(11)计算簇标签得分F1 score。
算法2簇标签评分算法
输入ptrain和ptest的聚类结果C及其标签矩阵T,潜在因子-标签矩阵H
输出簇标签得分F1 score
1.S←ptest×H
assign ptestinto C
2.TP←0,FP←0,FN←0
for i←1 to N do:
for j∈clusterido:
TP←count(TP+Sj∩Ti)
FP←count(FP+SjTi)
FN←count(FN+TiSj)
end
end
4 实验结果与分析
4.1 实验数据
本文实验利用Last.fm数据集、Movielens数据集及CiteULike数据集进行测试。
Last.fm数据集包含用户、歌手以及歌手类型的资料,包括每个用户收听每个歌手音乐的次数以及用户已标记的歌手类型,并且不同用户可能对同一个歌手标记不同类型。该数据集中具有1 892个用户、17 632个歌手及11 946种歌手类型,采用用户与歌手关系的数据集构建矩阵D,歌手与歌手类型关系的数据集构建矩阵G。
CiteULike数据集包含作者引用论文与每篇论文对应的关键字。将作者引用论文表示为1,未引用视为缺失值,采用作者与作者引用论文数据集构建矩阵D,而论文与论文所对应关键字的关系数据集构建矩阵G。该数据集中具有5 551个作者、16 980篇论文以及46 391个关键字。
Movielens数据集包含用户对不同电影的评分数据,包括自2000年起6 040个用户对3 900部电影产生了1 000 209条评分数据。将用户已评分电影表示为1,未评分视为缺失值。采用用户与电影评分的关系数据集构建矩阵D,每部电影所代表的类型构建矩阵G。
4.2 结果分析
4.2.1 矩阵分解误差评估
如果矩阵分解误差较大,则会对聚类和自动标签生成产生影响。因此,首先对本文矩阵分解方法进行评估。以Last.fm数据集为例,采用LFM对原始稀疏矩阵进行矩阵分解,潜在因子k取值为4、8、12、16、20、24、28、32、36,潜在因子与矩阵分解误差的关系如图2所示。可以看出,随着潜在因子数量的增加,矩阵分解误差呈现下降趋势,初始阶段下降速度较快之后放缓,在潜在因子数量达到32后,放缓趋势较为明显。因此,潜在因子数量选择32较理想。
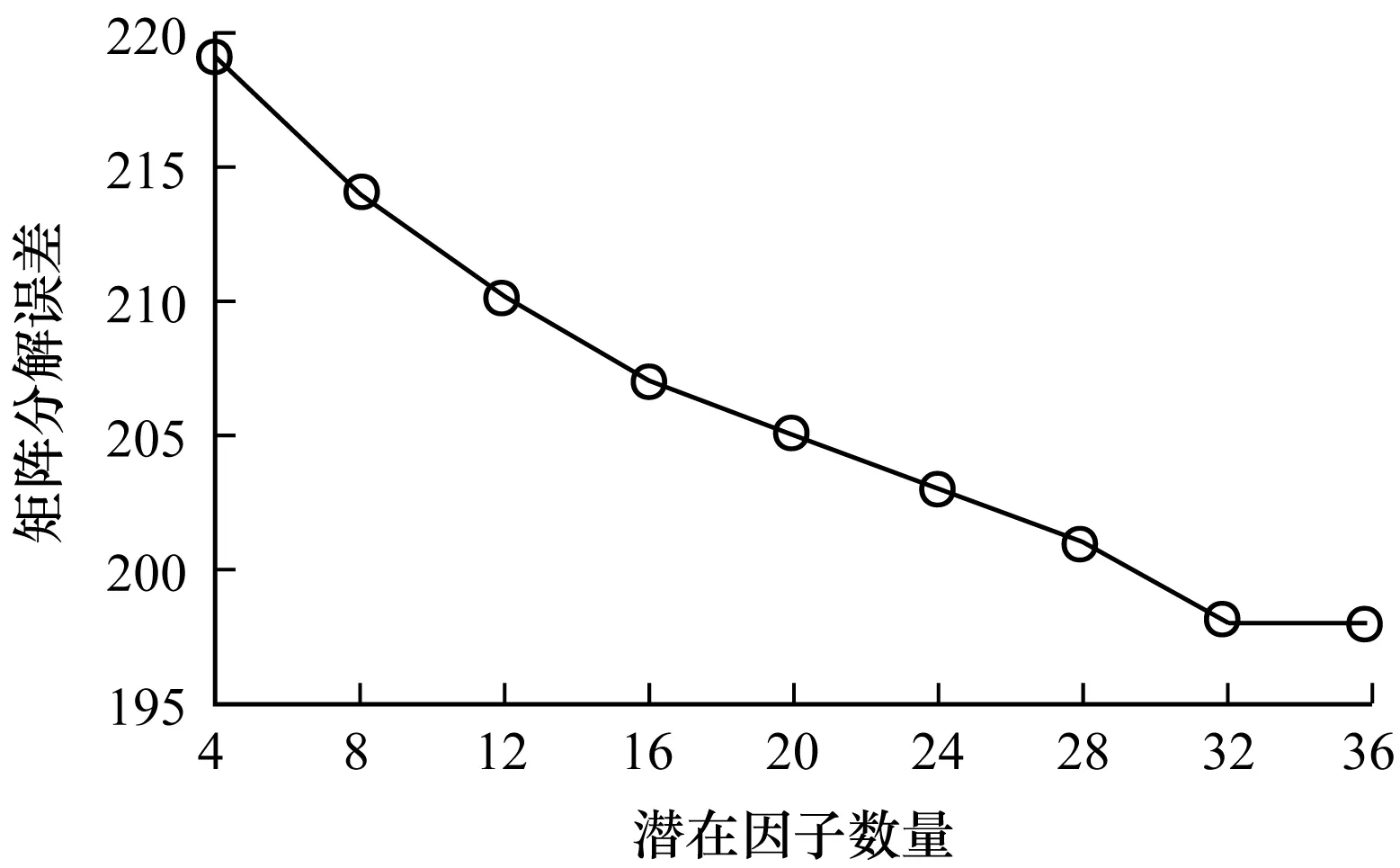
图2 潜在因子与矩阵分解误差的关系Fig.2 The relationship between latent factor and matrix factorization error
4.2.2 聚类效果评估
本文选取潜在因子为32、矩阵分解误差为164,分别利用AP[13]、DP-means[14]、K-means[15]、K-means++[16]以及层次聚类[17]算法进行聚类,并使用Silhouettes方法对聚类效果进行评估,实验结果如图3所示。Silhouettes用于评价聚类效果的轮廓系数,轮廓系数的取值范围为[1,1],若大于0则表示聚类结果可用,若越接近1则说明聚类效果越好。在5种聚类算法中,K-means++、DP-means以及AP算法无需事先确定用户行为数据规模,轮廓系数均大于需要实现确定用户行为数据规模的K-means与层次聚类算法,聚类效果更好。由于处理的数据集不同,各算法聚类效果存在差异,例如在Last.fm数据集中,AP算法的轮廓系数为0.354,但在CiteULike数据集中轮廓系数为0.427。虽然整体轮廓系数均未超过0.6,但本文方法的主要目的是完成聚类过程的标签自动生成,因此该结果是可以接受的。
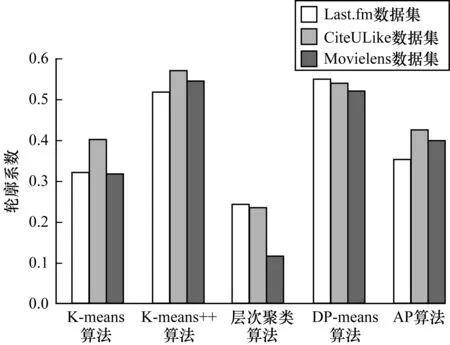
图3 5种算法的聚类效果对比Fig.3 Comparison of clustering effects of five algorithms
4.2.3 簇标签评分评估
本文将同一个歌手被标记的所有类型进行求和,被标记次数较多的类型作为该歌手偏向类型的标签。采用歌手与歌手类型关系的user_taggedartists.dat数据集构建矩阵G。同时将用户收听歌手音乐的次数通过数据标准化转化为1分~5分的喜欢程度,若未听过则不评分并将其作为缺失值,采用用户与歌手关系的user_artists.dat数据集构建矩阵D。在聚类完成后进行矩阵运算得到簇-标签矩阵Q并对Q进行排序,得到每个簇的前n个标签,而标签评分通过F1 score进行表示,其值越接近1表示聚类效果越好。实验在CiteULike数据集上使用AP算法进行测试,由于采用的标签数量不同,因此计算得到的F1 score也不同,如图4所示。
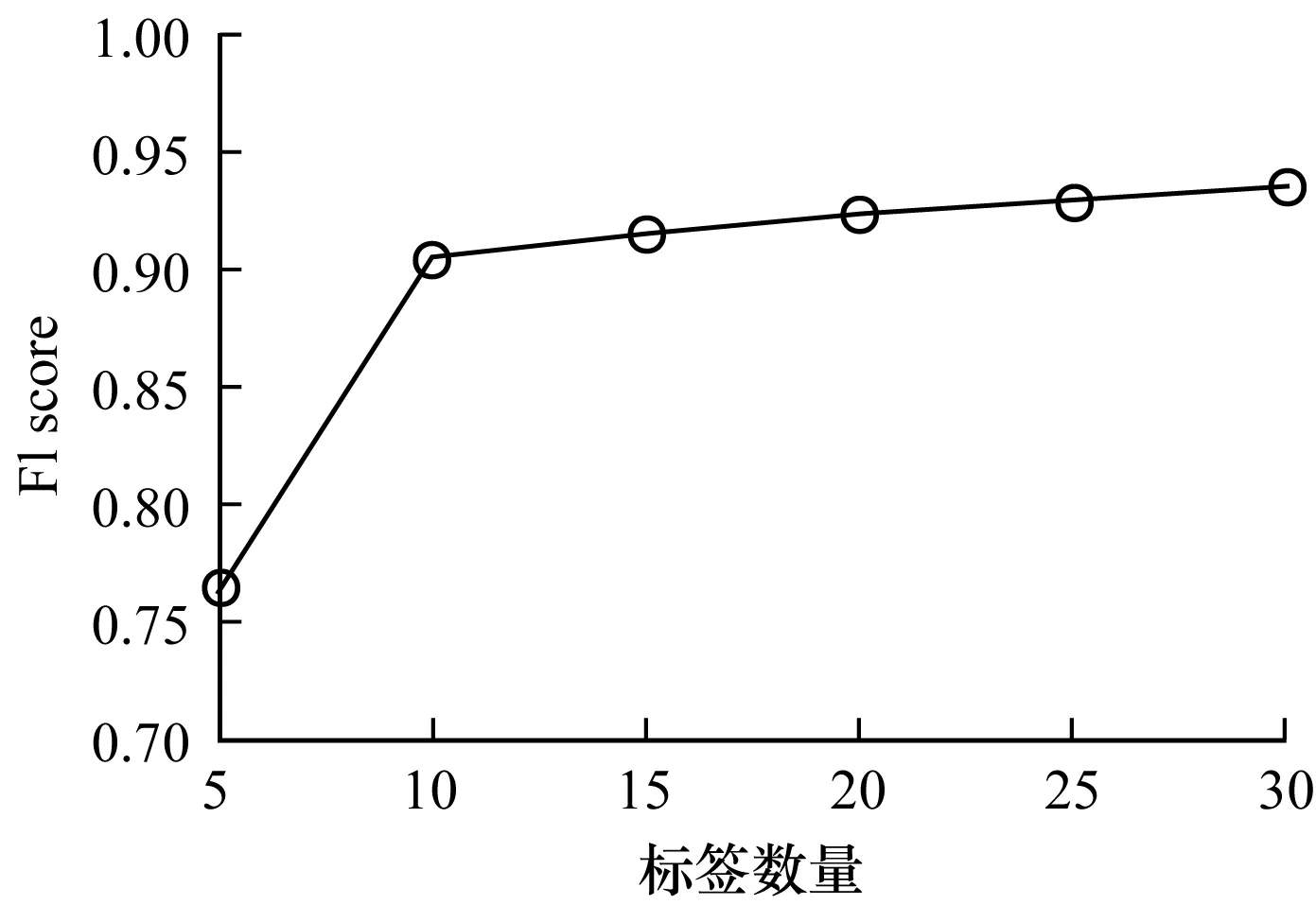
图4 标签数量对F1 score的影响Fig.4 The impact of the number of tags on F1 score
在图4中,当标签数量为5时,通常会取得较常见的标签,但簇标签评分较低,簇的语义较模糊,随着标签数量的增多,簇标签评分越来越高,会取得区别能力较高的标签,使簇的语义更明确。当标签数量为10~30时,F1 score增加效果不明显,因此本文取标签数量为10。
通过综合轮廓系数(聚类评分)和F1 score(标签评分)两项聚类性能指标(如表2所示),证明本文方法可在保证一定聚类效果的前提下生成语义更明确的簇标签,且标签评分均大于0.4。经对比分析可以看出,不同数据集下各聚类算法的聚类评分及标签评分不同,无须事先确定用户行为规模的K-means++、DP-means以及AP算法的两项指标均大于K-means和层次聚类算法。
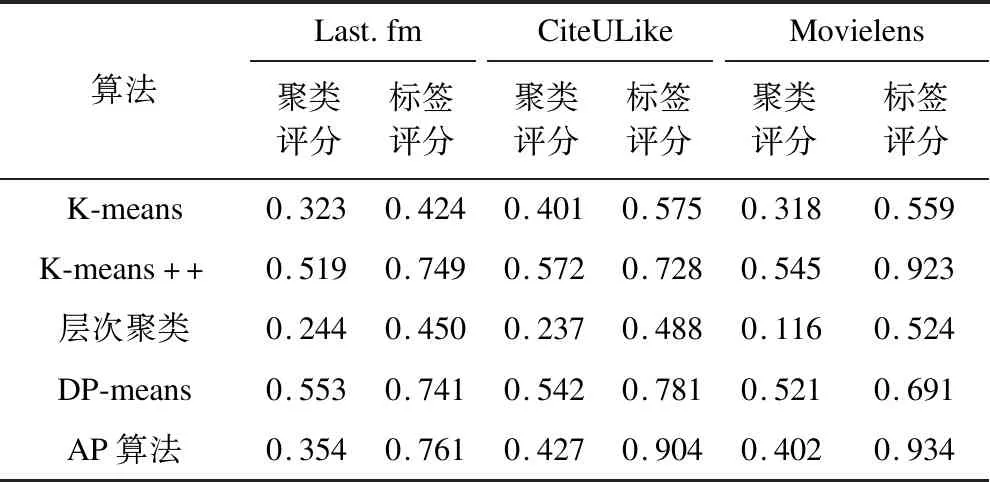
表2 3个数据集中的算法聚类性能比较Table 2 Comparison of algorithm clustering performance in three datasets
为证明本文方法的聚类效果符合用户实际情况,利用Last.fm数据集通过AP算法对本文方法的聚类结果及簇标签进行分析,结果如表3所示。通过聚类后共形成4个簇,每簇取前10个标签作为簇标签,可以看出簇1的用户喜好偏向独立摇滚乐,簇2的用户喜好偏向80年代经典摇滚乐,簇3的用户喜好偏向流行电子音乐,簇4的用户喜好偏向前卫摇滚乐。通过人工检查这些数据,发现聚类结果与实际情况相符合,进一步证明了本文方法的有效性。
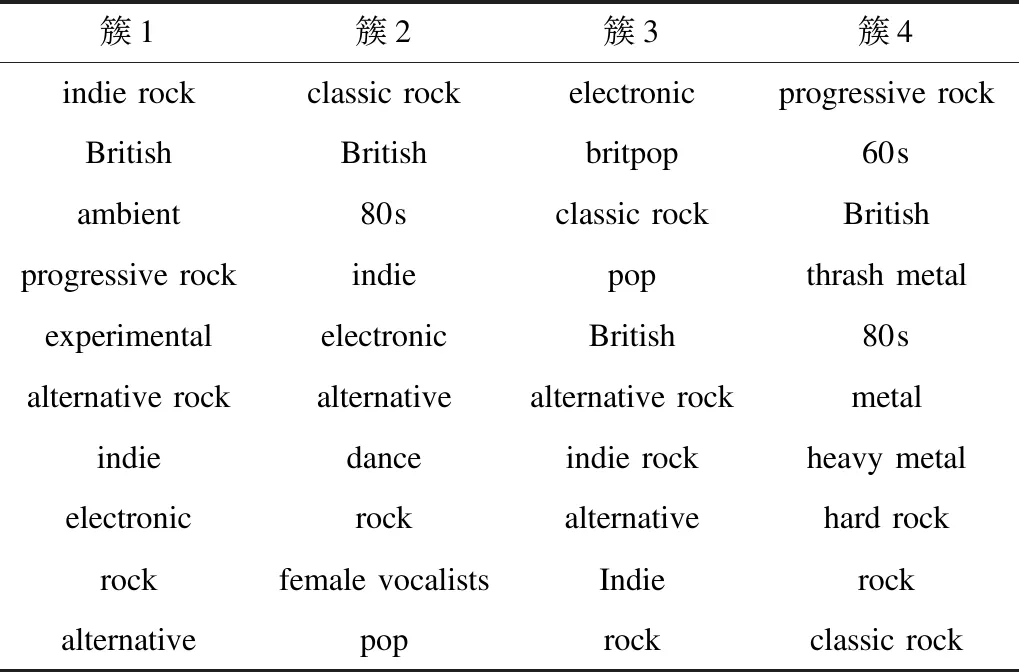
表3 Last.fm数据集中簇所对应的标签Table 3 The labels corresponding to the clusters in Last.fm dataset
4.2.4 缺失值补充效果评估
在进行聚类前,为提高生成标签的准确性,需要对用户行为数据进行补充缺失值处理。同时,原始数据维度较大,若对原始数据直接进行聚类,则聚类效率较低。以Last.fm数据集为例,原始数据经去重复用户处理后,矩阵D大小为1 877×376,LFM矩阵分解后的矩阵p大小为1 877×32,从数据维度上可以看出对经补充缺失值处理后的矩阵p聚类效率优于对原始矩阵直接进行聚类。实验在Movielens数据集上利用K-means、K-means++、层次聚类、DP-means及AP算法分别在有无补充缺失值的条件下进行聚类,实验结果如图5所示。
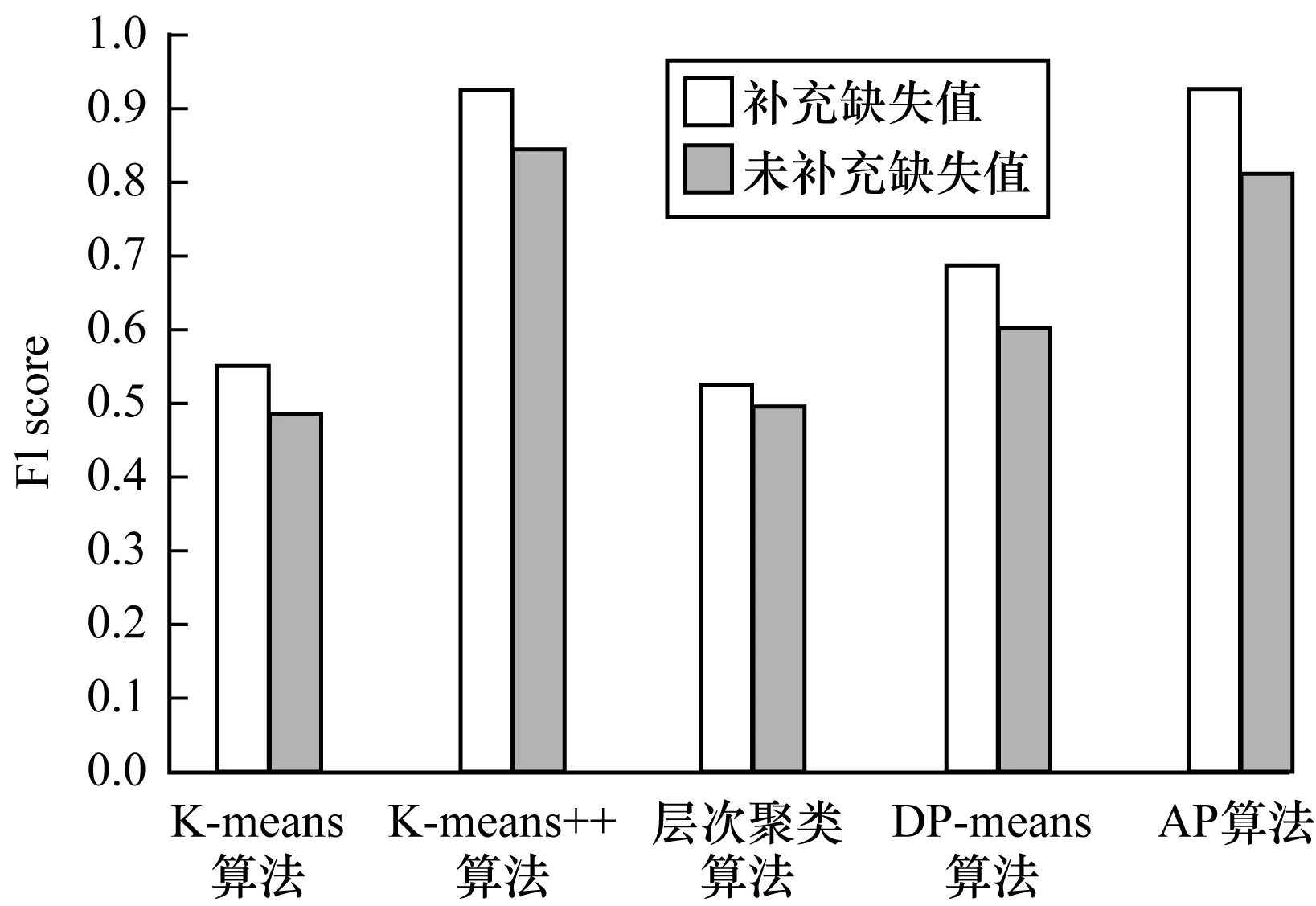
图5 缺失值对F1 score的影响Fig.5 The impact of missing values on F1 score
从图5可以看出,经补充缺失值后F1 score提高了4%~15%,从而提升生成标签的准确性。通过一系列实验结果分析可知,本文方法可在保证聚类效果的前提下,在聚类过程中自动生成语义更明确的簇标签。
5 结束语
现有聚类算法在对网络用户行为进行分析时需要预先确定用户行为数据规模,并且生成的簇也缺少语义特征。为此,本文对网络用户行为数据特征进行聚类分析,并应用LFM、矩阵分解等方法,提出一种用于网络用户行为聚类的簇标签自动生成方法。实验结果表明,本文方法无需事先确定用户行为数据规模,在聚类过程中可以同时产生簇标签,且所生成的簇标签符合用户行为的实际语义。但由于本文方法对用户行为数据有一定的格式要求,因此后续将对此进行改进,扩展其应用范围并提升通用性。
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
雷达学报(2017年6期)2017-03-26
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
Coco薇(2015年11期)2015-11-09
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
