
具有随机缺陷率产品的多点转运库存优化模型
2020-10-12 12:12戢守峰宋乃绪
计算机集成制造系统 2020年9期
万 鹏,戢守峰,宋乃绪
(1.东北大学 工商管理学院,辽宁 沈阳 110004;2.青岛理工大学 管理工程学院,山东 青岛 266520)
0 引言
现实生活中,由于受到设计、生产技术或者包装、运输等各种原因的影响,制造商交付给分销商的产品并不能保证是完美无缺的,这加剧了产品市场供给的不确定性。而由于市场需求的不确定性,在通过多个零售商对产品进行销售时,又经常发生局部缺货和局部超储的情况,为应对这种情况,一些零售商通常采用横向转运策略来予以解决。当市场需求的不确定性和由于质量缺陷造成的产品供给不确定性共同作用时,其产生的影响成为供应链横向转运库存决策领域值得探讨的重要问题。
目前,国内外学者已经关注到了产品的质量缺陷对供应链横向转运库存决策的影响。LEE等[1]最早开始了质量有缺陷产品的库存系统优化方面的研究,并给出了最优订购策略。Mahata等[2]采用梯形和三角两种模糊数建立了考虑质量缺陷和短缺延期交付的库存模型。Hsu等[3]开发了一个存在质量缺陷产品和检验差错的经济订购批量模型,确定了最优订购批量、最大短缺水平和最佳再订购点。
Paul等[4]在不允许缺货假设下,考虑了质量缺陷产品在价格折扣情形下的补货问题,研究了产品缺陷率对订购策略的影响。Sarkar等[5]在可变提前期下,研究了质量缺陷产品和延期交付下的库存模型,获得了允许缺货情况下的最优方案。Lu等[6]建立了一个缺陷产品的库存模型,考虑随机缺陷率下的最优订购周期和订购数量。Shekarian等[7]在不允许出现短缺的假设条件下,开发了一个考虑缺陷产品有不同的持有成本的经济订购批量模型,在模糊情景下,使用Karush-Kuhn-Tucker(KKT)条件确定最佳批量。Alamri等[8]在不允许缺货假设下,提出一个受限于质量缺陷产品检验的经济订购批量模型,研究了需求变动和筛选率对最优订购数量的影响。Lin等[9]在不允许缺货假设下,不仅在质量缺陷产品的库存模型中考虑了筛选率的影响,还考虑了数量折扣对最佳订购数量的影响。Zhou等[10]更进一步,不仅考虑质量缺陷和筛选检验,还考虑贸易信贷对经济订购批量的影响,建立了以总利润最大化为目标的库存模型。Datta等[11]提出一个融合了质量改进投资机会的质量缺陷产品的库存模型,在市场需求与销售价格相关假设下,以利润最大化确定最佳质量改进投资、销售价格和库存数量。这些研究都围绕质量缺陷产品的最优订购问题进行,没有考虑多级供应链的情形。Rad等[12]在两级供应链情形下开发了质量缺陷产品的最优生产和分销库存模型,并假设销售价格和广告会影响市场需求,分别在独立决策和联合优化决策下确定了最优定价、广告和批量。Taleizadeh等[13]在不允许缺货的假设下,开发了一个三级供应链的库存模型,研究了质量缺陷产品回购情形下的定价和订购决策问题。Pal等[14]同样建立了一个质量缺陷产品的三级供应链模型,假设制造商为供应链核心企业,并在检验差错和需求与价格和库存相关的情况下,研究了短缺和延期交货对库存系统的影响。
由以上文献可以看出,在不同的情境下,产品的质量缺陷对库存订购和补货都造成了很大的影响,从而影响了供应链的绩效。通常的研究假设也都是构建在单个制造商和单个零售商组成的供应链库存模型基础上,而对由单个制造商和多个零售商组成的质量缺陷产品的供应链库存系统的研究还不够丰富。
在单个制造商和多个零售商构成的供应链库存系统中,分布在不同地理区域的零售商也会由于市场需求的不确定,造成空间上的供给与需求不平衡,即在销售过程中有的零售商出现库存剩余而有的零售商出现库存短缺。已有文献表明,库存横向转运策略可以有效解决这一问题。Sherbrooke[15]最早对多层级库存系统的物资转运问题进行了研究。Axsäter[16]考虑了由多个仓库组成的供应链库存系统,利用设计的横向转运规则实现最小化期望成本的目标。Kutanoglu等[17]依照距离因素对实施转运的零售商划分了优先级,在服务水平约束下建立了成本最小化模型,并设计了基于隐枚举法的求解方法。Olsson等[18]在预先制定的转运规则下对订货策略和常规补货策略进行了优化,研究表明使用横向转运有益于改善服务水平和降低库存系统的总成本。LEE等[19]在两级供应链下,提出了考虑服务水平的横向转运策略,并通过模型确定了转运数量,有效减少了系统总成本。Li等[20]的研究也表明,采用横向转运进行的库存共享提升了客户的服务水平。Axsäter等[21]在存在多个零售商的供应链库存系统中,构建了允许横向转运的库存模型,在一定的服务水平约束下进行成本评估和优化再订购点。汪传旭等[22]在满足需求点全部需求的假设下,研究了不确定环境下的多需求点横向转运库存策略问题,建立了以总成本最小为目标函数,以各需求点服务水平为约束条件,以各需求点的库存水平和转运点为决策变量的优化决策模型。在此基础上,汪传旭等[23]又引入产品替代策略,在以零售商自有库存满足市场需求的服务水平约束下,构建了总利润和顾客等待时间最小的双目标模型,并使用改进粒子群算法对模型进行求解。许民利等[24]在多级多库存点允许横向转运的背景下,基于消费者等待时间限制,建立了成本最小化的库存优化模型,并采用遗传算法进行求解。Tai等[25]考虑了两级库存系统的马尔科夫模型,通过允许横向转运来获得较高的服务水平,实现最小化库存系统的总期望运营成本。Johansson等[26]在缺货允许延期交付的假设下,研究了一个具有非线性延期交付成本的两级库存系统,允许零售商在同级进行横向转运,确定了在一定的客户服务水平下的最优决策。戢守峰等[27]在三级分销网络下,构建了考虑库存共享和服务水平限制的横向转运模型,并设计了贪婪算法进行求解,对比了One-for-One库存策略和(Q,R,H)库存策略下的系统成本。
综上所述,一方面,在研究允许横向转运的库存策略的文献中,学者们通常假设产品没有缺陷,仅关注需求不确定造成的供需不平衡;另一方面,在研究存在质量缺陷产品的文献中,学者们多着眼于最优生产批量和订货批量的决策上,并主要研究单个制造商和单个零售商之间的生产和订购问题,极少研究单个制造商和多个零售商情况下由于市场需求不确定对库存决策的影响问题。鉴于此,本文将两者结合起来,考虑一个由单个制造商和多个零售商组成的供应链系统,在满足一定服务水平约束的前提下,研究随机缺陷率产品的多点横向转运库存策略问题。
1 问题描述与条件假设
1.1 问题描述
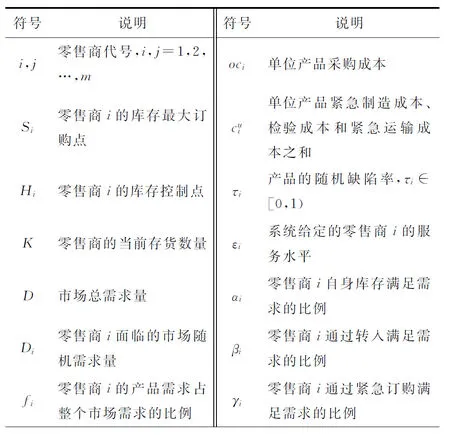
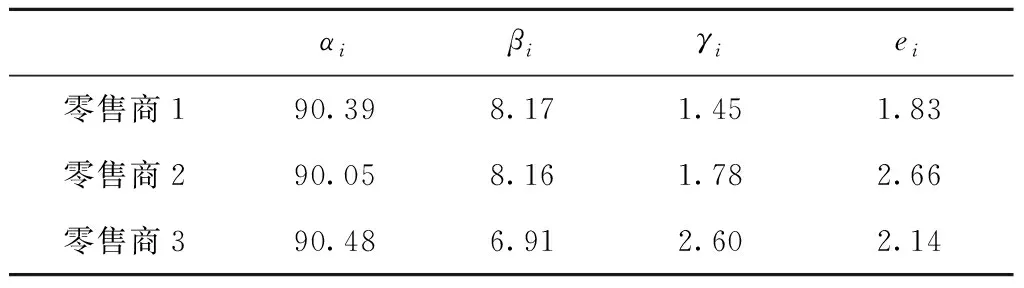
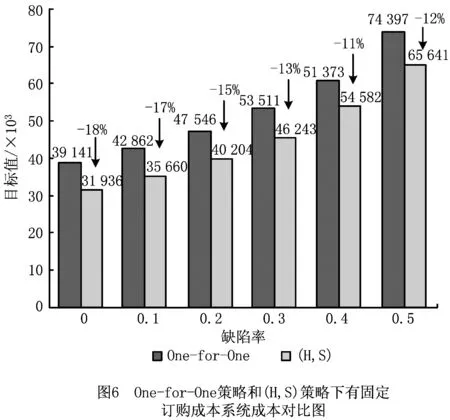
本文研究的供应链系统由1个制造商和m个零售商组成,所分销产品存在一定概率的缺陷。系统中制造商处于主导地位,允许零售商之间进行横向转运。各零售商采用(H,S)库存控制策略,S为零售商的最大订货点,H为零售商的库存控制点,当零售商当前库存K>H时,其可以响应其他零售商的横向转运请求,而当K 为便于模型研究,做出如下假设,模型参数如表1所示。 (1)本文以单一产品为研究对象,假设不允许市场缺货。 (2)制造商在供应链中居于主导地位,在不同区域的各零售商i之间需求相互独立,并通过制造商建立的供应联盟进行库存信息共享,到达零售商i消费者服从λi的泊松分布。 (3)每批产品中的缺陷率为随机变量,零售商知道缺陷率服从一定的分布,且τi∈[0,1)。 (4)零售商需要对到货产品进行全部检验,产品检验和顾客需求是同时发生的,但是检验速度远大于需求速度。 (5)零售商的常规补货时间远大于横向转运的时间,因而当某客户达到时,零售商首先利用自有库存来满足客户需求,当自有库存不能满足时,则由临近的其他零售商通过横向转运满足,如果所有零售商都不能满足,则由零售商向上级制造商进行紧急订购来满足。 (6)零售商采用先到先服务的原则。 (7)由于支付了更高的采购费用,零售商通过紧急订购的产品无缺陷。 表1 参数符号说明 续表1 (1)服务水平约束 服务水平有不同的表达,如需求满足率和等待时间限制等。本文以零售商由自身库存直接满足消费者需求的概率αi作为零售商的服务水平,目标服务水平约束为εi,则有 αi≥εi。 (1) (2)优先级约束 为保证零售商正常的采购和销售,避免出现套利,零售商满足需求所采取方式,其优先级为直接满足>转运满足>紧急订购,因此 (2) 零售商采用连续盘点的(H,S)库存策略,H是库存控制点。设零售商的当前库存为K,若K (3) 由式(3)可以推导出 (4) Hi+1≤K≤Si。 (5) 联立式(4)和式(5)可得 (6) 则零售商i库存为0的概率为 (7) 当零售商i的库存不为0时,其均可依靠自身库存直接满足消费者需求,得到 (8) 则可计算出零售商i库存低于库存控制点的概率为 (9) 当零售商i的库存为0,且其他零售商的库存不全都在各自库存控制点以下时,则其他零售商就可以对零售商i进行横向转运,得到: (10) 当零售商i的库存为0,且其他零售商的库存全部都在各自库存控制点以下时,则需要由制造商紧急补货来满足消费者需求,紧急订购满足需求的比例γi为: (11) (12) (13) 将ωir归一化处理得: (14) 为了与所提出的(H,S)策略进行比较,本文参考文献[23]也建立One-for-One策略下的转运库存模型。与2.2节中符号定义和过程相同,建立One-for-One策略下的马尔科夫稳态方程: (15) 由式(15)可以推导出 (16) (17) 联立式(16)和式(17)可得 (18) 则One-for-One策略下零售商i库存为0的概率为 (19) 由此,在One-for-One策略下可以根据迭代方法计算出αi、βi、γi、ei的表达式。 为保证一定的基于需求满足率的服务水平,减少缺货成本和紧急订购的成本,零售商会持有较多库存,但这将增加产品存储成本和采购成本。此外,由于制造商产品存在一定的质量缺陷,使得不同服务水平下的零售商库存控制策略更难以制定。为此,本文考虑系统的存储成本、订购成本、运输成本、检验成本以及缺陷产品损失成本4类成本,构建系统成本最小化的库存模型。 (1)合格产品采购成本C1 (20) (2)合格产品存储成本C2 (21) (3)合格产品运输成本C3 运输成本包括常规运输成本、紧急运输成本和转运运输成本3类。 1)常规运输成本C31。 无论是由零售商自有库存直接满足的需求,还是通过横向转运满足的需求,其产品都是通过常规订货而来,因此这两类满足方式的产品运输方式均为常规运输,成本为 (22) 2)转运运输成本C32。 (23) 3)紧急补货成本C33。 (24) 因此,C3=C31+C32+C33。 (4)检验成本C4 由于制造商产品存在一定缺陷,产品到达零售商处时,零售商会对所有产品进行检测,单位产品检验成本为ce,检验数量为Di(1-γi)/(1-τi),则总检验成本 (25) (5)缺陷品损失成本C5 缺陷品损失成本包括采购成本中缺陷品所占的支出成本C51、运输成本中缺陷品所占的支出成本C52和检验出缺陷品后的缺陷品处理成本C53。 (26) (27) (28) 因此,C5=C51+C52+C53。 综上所述,总成本最小化模型为 minTC=C1+C2+C3+C4+C5。 (29) 因为缺陷率为随机变量,所以期望总成本可表示为 minETC=E(C1)+E(C2)+E(C3)+E(C4)+E(C5) s.t αi≥εi>0, αi+βi+γi=1。 (30) 本文所构建的模型是非线性的,且需要重复迭代,难以直接求得精确解,由于遗传算法在求解非线性规划问题时表现出了良好的收敛性和鲁棒性,采用一种改进自适应遗传算法进行求解。算法流程如图2所示。 具体步骤如下: 步骤1染色体编码。 遗传算法需要将待处理的问题转换成由一定结构组成的染色体,然后模拟生物遗传的方式寻得最优解。染色体编码的方法有整数编码、二进制编码和浮点编码等类型,本文采用整数编码。 本文模型的决策变量H和S成为染色体的两个片段。染色体中基因的数量为零售商数量的两倍,假设零售商数量为5,如图3所示。图中:1~5格表示零售商i的最大库存水平S,分别为100、110、120、130、140;6~10格表示零售商i的库存控制点H,分别为10、11、12、13、14。 步骤2初始化种群。 初始种群的质量在很大程度上制约了遗传算法的寻优能力,因此生成优秀的初始群体是寻找最优结果的重要前提。为此,根据模型的特点,可以在[αDi,βDi]范围内生成染色体第一片段基因的值,即Si的值,其中0<α<1,β>1,首先赋予较大数值,然后根据寻优结果逐次实验减小,最后得到较为合适的值。 根据模型建立的条件,染色体第二片段的基因数值一定要小于对应的第一片段的基因数值,因此理论上第二片段基因的取值范围为[0,Si],但由于不同染色体第一片段中相同基因位的数值有所差别,经过交叉操作之后,可能出现后代染色体中第二片段某基因位数值大于对应的第一片段基因位数值的情况,因此,该类染色体就不再具有遗传意义。对于上述有问题的后代染色体可以进行两种操作:①对其进行改造,对问题基因进行合理范围内的变异,使之合理;②对其进行淘汰,不再参与迭代。随着遗传代数的增加,问题染色体可能会越来越多,对其改造会大大延长算法执行时间,而淘汰则会破坏种群的多样性,从而降低算法的寻优能力。为此,本文采用从根本上避免此类问题的方法,即让第二片段基因所能取的最大值小于第一片段所能取的最小值,则取值范围变成[1,(1-α)Di]。 步骤3 计算适应度。 遗传算法的适应度越大越有利于生存,因此遗传到下一代的概率越大。因为文中的模型是成本最小模型,所以取倒数作为该染色体的适应度,则染色体r的适应度为1/TCr。 步骤4 选择。 为解决“遗传退化”和“搜索迟钝”问题,采用轮盘赌和最佳保留策略相结合的方法,即当通过轮盘赌方式产生的子代染色体不如父代染色体优秀时,用最优的父代染色体替换子代中的最差染色体,使优秀基因得以继续遗传。 步骤5 交叉和变异。 交叉是遗传算法的核心步骤,两个优秀个体通过交换某一段的基因产生新染色体,这是遗传算法搜索最优解的关键步骤。变异有助于跳出局部最优以寻求全局最优解。小的交叉和变异概率有利于保留优秀个体并加快算法的收敛速度,但是容易陷入局部最优;大的交叉和变异概率则有利于突破局限从而寻找全局最优解,但会使得算法收敛变慢,也使得最优解更容易遭受破坏,当交叉和变异概率太大时,算法就退化成了随机搜索过程。因此,为了提高算法对局部最优的突破能力和全局最优的保存能力,使交叉概率和变异概率随染色体适应度进行自适应调整是一种有效的改进策略。首先设Zmax为当前种群中最大的适应度,Zavg为平均适应度,Δ=Zmax-Zavg。Δ越大说明当前种群个体越离散,种群多样性好,需要较小的变异概率加速收敛;Δ越小说明当前种群个体越集中,多样性减小,为避免陷入局部最优,需要以较大变异概率产生新个体增加种群多样性。本文采用如下调整公式: (31) mpct=pcmax·2-θΔ/Zmax; (32) (33) mpmt=pmmax·e-θΔ/Zmax。 (34) 式中:Zmax为当前种群的最大适应度;Zavg为当前种群的平均适应度;Δ为当前种群最大适应度与平均适应度之差;pct为当前种群交叉概率;pcmax为最大交叉概率;mpct为中间计算变量;pmt为当前种群变异概率;pmmax为最大变异概率;mpmt为个中间计算变量,θ为敏感系数。 步骤6终止算法。 当算法迭代到最大代数时,终止并输出结果。 概率为0.2,最大迭代次数为2 000,α=5,β=5,θ=10,在Intel i5系列2.5 GHz处理器,4 G内存,WIN7 64位操作系统的计算机中,使用MATLAB进行求解。 在(H,S)库存控制策略下,满足90%的服务水平、缺陷率为0.05时,最小成本为33 376,最优决策变量值为S=[33,46,38],H=[9,7,2],表示零售商1的最优库存水平为33,库存控制点为9,即当前库存量小于等于9时不再响应其他零售商的横向转运请求,并向制造商发出补货订单补充库存至33。同理,零售商2的最优库存水平为46,库存控制点为7;零售商3的最优库存水平为38,库存控制点为2。3个零售商的α、β、γ、e的值如表2所示。 表2 α、β、γ、e的值 以不允许横向转运的库存模型作为比较基准,与允许横向转运的库存模型进行对比,设置εi=0.80,0.85,0.90三个不同的服务水平,得到不同服务水平下两种方案的数据表现,结果如表3和表4所示。 表3 不同服务水平下允许横向转运库存方案结果 表4 不同服务水平下不允许横向转运库存方案结果 由表3、表4可知,在相同服务水平约束下,允许横向转运的库存方案均比不允许横向转运的库存方案总成本更低,且具有更低的最大库存水平。随着服务水平的提升,各零售商的最大库存水平和库存控制点亦不断增加,表明随着对利用自身库存直接满足需求的要求越来越高,各零售商需要订购更多数量的产品,设置更高水平的库存控制点;反之,在直接使用自身库存满足需求的要求较低时,各零售商可以有更低的库存控制点,以便于零售商之间通过横向转运满足市场需求。 表3和表4还表明,不同服务水平下允许横向转运的库存方案有不同的最优库存水平,而不允许横向转运的库存方案只有一个最优库存水平且有着很高的直接满足率,这是由于在只有常规订购和紧急订购两种补货方式时,为降低紧急订购成本,零售商只能选择高库存策略实现用自身库存满足市场需求的服务水平要求。 由表5可知,随着使用自有库存满足市场需求的服务水平越来越高,系统总成本不断增加,其中采购成本会大幅增加,转运成本和紧急补货成本逐渐减少,检验成本和缺陷品损失成本亦不断小幅增加。说明随着直接满足市场需求的服务水平要求越来越高,由于缺陷品的影响,零售商需要采购的数量也越来越多,从而需要通过其他渠道满足市场需求的数量不断降低,所需成本亦降低。 表5 不同服务水平下允许横向转运库存方案成本构成情况 通过分析不同服务水平下允许横向转运库存方案的结果可知,服务水平越高,零售商的最优库存水平和库存控制点水平越高,系统最优总成本也随之增加,而由横向转运满足需求的概率β、紧急订购概率γ以及转出量e均会降低。这是由于零售商的最优库存水平S和库存控制点水平H都较高时,也使得缺货风险降低,从而引起了自身由横向转运满足需求的概率β和邻近零售商转出量e的减少。此外,高库存控制点也提高了自身转出的限制,亦会引起自己转出量的减小。以上分析说明,使用自有库存满足需求的服务水平较低时,允许横向转运的库存方案更具成本优势。 在ε=0.9的条件下,改变缺陷率的分布范围,计算不同期望缺陷率对应的各零售商的最大库存水平S和库存控制点H,以及相应的最优总成本,如图4和图5所示。 由图4可知,零售商的最优库存量和库存控制点亦会随着缺陷率的增大而增加,但最优库存量增长速度较快,库存控制点增幅较小。这是由于缺陷率越大,零售商要得到一定数量的合格产品需要购进的产品数量就越多,最优库存量亦会快速增加。 由图5可知,随着产品缺陷率的增加,系统总成本亦快速增加,表明产品缺陷率对系统总成本有重要影响,提高产品质量是降低系统总成本的重要手段。随着缺陷率的增加,用于产品的采购成本、运输成本和相应的缺陷品处理成本都不断增加。由于商品价值较大,造成缺陷产品采购成本损失C51更加明显。由于对采购产品进行了缺陷检测,在服务水平保持不变的情况下,随着缺陷率的增加,转运的合格品的绝对数量较小,转运成本C32逐渐降低,说明产品缺陷率的高低对转运数量的影响不显著,零售商在高缺陷率下,更趋向于增加订购数量,通过自身库存满足市场需求,而不是通过转运和紧急订购来满足。 由图6可知,在按照固定订货成本为50进行计算后,One-for-One策略会因订货次数的增加而产生高昂的固定订货成本,则One-for-One库存控制策略的系统最优总成本明显高于(H,S)库存控制策略,随着缺陷率的增加,成本差额也不断扩大。由此可见,在有质量缺陷的产品库存控制方面,(H,S)库存控制策略优于One-for-One策略。 为分析算法的有效性,分别采用基本遗传算法和改进自适应遗传算法进行验证求解。为提高求解效率,本文对算法的种群规模进行了优化。 (1)种群规模的确定 在最大迭代次数为2 000代的情况下,种群规模选择为10,20,30和40。使用算例中的数据,对每个种群规模进行仿真计算,计算花费时间分别为27 s,35 s,48 s和62 s,并得到图7。由图7可知,进化代数为2 000代、种群规模为20时,能够较快地收敛,且收敛值最低,因此选择种群规模为20。 (2)算法对比 结合确定的种群规模,分别设置基本遗传算法和改进自适应遗传算法的初始参数,如表6所示。算法运行配置环境为:Intel i5系列2.5 GHz处理器,4 G内存,WIN7 64位操作系统。 表6 算法初始参数对比表 由表7计算结果可知,本文所采用的改进自适应遗传算法在目标值和收敛代数上都优于基本遗传算法,算法的平均运行时间也比基本遗传算法用时更短。因此,本文采用的改进自适应遗传算法是有效的,能够用于此类问题的求解。 表7 各算法结果对比表 本文以使用自有库存直接满足市场需求的比率为服务水平约束,允许零售商之间进行横向转运,构建了一个两层级的随机缺陷率产品的分销网络库存优化模型,分销网络由一个制造商,m个零售商及n个消费者构成。本文的主要贡献和结论如下: (1)本文在(H,S)库存控制策略下,研究了允许横向转运的随机缺陷率产品的库存优化问题。在相同的服务水平和缺陷率下,指出(H,S)库存控制策略优于One-for-One库存控制策略。 (2)本文对不同服务水平下允许横向转运的库存方案和不允许横向转运的库存方案进行了对比,结果表明,在不同服务水平约束下允许横向转运的库存方案在系统总成本和库存水平方面均优于不允许横向转运的库存方案,证明了模型的有效性和优越性。 (3)通过对服务水平和产品缺陷率的敏感性分析可知,系统最优总成本会随着服务水平和缺陷率的增大而增大;系统最优库存水平和库存控制点水平也会随着服务水平和缺陷率的增大而增大。受此影响,直接满足率α会随着服务水平的增大而增大,随着缺陷率的增大而减小;横向转运满足概率β会随着服务水平的增大而减小,随着缺陷率的增大先增大后减小;紧急订购概率γ会随着服务水平的增大而减小,随着缺陷率的增大而增大;转出量则和转运满足概率β有着相同的变化趋势。 (4)在两级分销网络中,零售商分销有随机缺陷率的产品时,采用横向转运策略能够获得较大的成本优势,且采用(H,S)库存控制策略优于One-for-One策略。 本文假设分销供应链系统属于分销单一品种的集中决策,未来研究可在分散决策和多种产品分销供应链间展开。另外,本文假设零售商是同质的,具有相同的服务水平约束,因此,探讨异质零售商在不同服务水平约束下的横向转运问题也是未来的研究课题。
1.2 假设条件

2 模型建立
2.1 服务水平的刻画
2.2 (H,S)策略下αi、βi、γi和ei的度量


2.3 One-for-One策略下αi、βi、γi和ei的度量
2.4 目标函数
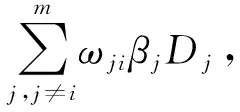


3 改进自适应遗传算法设计


4 数值仿真与分析

4.1 服务水平敏感性分析



4.2 缺陷率敏感性分析


4.3 算法对比



5 结束语
猜你喜欢
中国典型病例大全(2022年7期)2022-04-22四川劳动保障(2021年8期)2021-12-02石油化工管理干部学院学报(2021年5期)2021-08-06全球定位系统(2021年1期)2021-03-26活力(2019年19期)2020-01-06中国粮食经济(2018年11期)2018-12-27科学与财富(2018年10期)2018-06-09北京航空航天大学学报(2017年4期)2017-11-23中国工程咨询(2017年12期)2017-01-31右江医学(2015年2期)2015-07-18
