
机器人目标抓取区域实时检测方法
2020-10-10 01:00:34卢智亮刘瑞雪
计算机工程与应用 2020年19期
卢智亮,林 伟,曾 碧,刘瑞雪
广东工业大学 计算机学院,广州510006
1 引言
在家庭和工业场景下,抓取物体是机器人进行人机协作任务的关键步骤。人类可以准确且稳定地执行抓取形状不规则以及任意姿态的物体。然而对于机器人而言,准确地抓取各式各样、任意姿态的物体依旧是一种挑战。机器人若要抓取目标物体,需要预先检测该物体的抓取区域,不适当的抓取区域将导致机器人无法稳定地抓取物体。因此,如何实时且准确地检测目标抓取区域,是机器人领域中一个重要研究方向。
近年来,国内外学者对机器人抓取区域检测的研究已有不错的成果。Lenz 等[1]率先采用深度学习的方法提取RGB-D 多模态特征,基于滑动窗口检测框架同时使用支持向量机(Support Vector Machine,SVM)作为分类器,预测输入图像中的一小块图像是否存在合适的抓取位置。与Jiang等[2]使用传统机器学习方法相比,该方法不需要人为针对特定物体设计视觉特征,而是以自主学习的方式提取抓取区域的特征。在Cornell 数据集[3]上,上述方法达到73.9%的准确率。然而采用滑动窗口的方法会导致搜索抓取区域耗费时间长且计算量大。杜学丹等[4]在检测抓取位置前,先使用Faster R-CNN二阶目标检测算法[5]预测被抓物体的大致区域,缩小搜索范围以减少搜索时间,但该方法并未从本质上减少检测时间且计算量仍旧偏大,无法达到实时检测的要求。
Redmon等[6]不再基于滑动窗口框架搜索抓取框,而是利用AlexNet 网络[7]强大的特征提取能力,直接在整个图像上回归抓取框参数。将输入的图像划分成N×N个网格单元,每个网格单元预测一个抓取配置参数及适合抓取的概率,取其中概率最高的作为预测结果。在相同数据集上达到88.0%的准确率,平均检测时间为76 ms。Kumra等[8]也采用全局抓取预测的方法,使用网络结构更复杂的ResNet-50[9]提取多模态特征,准确率相应提高1.21%。以上两种方法借助性能强大的特征提取网络力求尽可能提高检测速度和检测准确率,但是直接回归抓取框参数容易导致预测的抓取框趋向于物体的中心,对于如盘子等抓取部位为物体边缘的情况,预测的效果并不理想。
Chu 等[10]提出旋转抓取框的方法,将方向预测视为抓取角度分类问题,借鉴Faster R-CNN二阶目标检测算法的思想,首先判断由GPN(Grasp Proposal Network)推荐的多个抓取候选区域能否用于抓取目标物体,然后判断剩余的抓取候选区域角度所属类别。该方法使用三种基础面积以及三种不同长宽比的锚框(Anchor)搜索抓取候选区域,达到96%的准确率,平均检测时间为120 ms。该方法虽然大幅度减少文献[1]和[4]中算法的检测时间,但依旧无法满足动态环境或动态物体下实时抓取检测的要求,并且仅利用特征提取网络中最后一层的特征图进行预测,倾向于检测较大的抓取框,对小抓取框检测性能不足,检测精确性有待提高。
综上国内外学者的抓取检测算法已达到不错的效果,但是仍然存在以下两个问题:第一,高准确率下检测抓取框时间过长,不满足机器人抓取检测的实时性要求;第二,容易忽略目标物中可用于抓取的小部位信息,检测出来的抓取框偏大、精确度不足。
针对以上问题,本文提出一种基于嵌入通道注意力结构SENet[11]的一阶抓取检测网络(Squeeze and Excitation Networks-RetinaNet used for Grasp,SE-Retina-Grasp)模型的机器人抓取区域实时检测方法。该方法采用快速的一阶目标检测模型RetinaNet[12]作为基本结构,在其特征提取网络中嵌入通道注意力模块SENet以提升重要特征通道的权重,确保检测精度;而且为了解决原RetinaNet模型特征融合中仅关注相邻层特征信息的问题,结合平衡特征金字塔[13](Balance Feature Pyramid,BFP)思想,充分融合高低层的特征信息,加强检测小抓取框的能力。
2 抓取框在图像空间的表达方式
给定包含目标物的图像I,检测该目标物的最优抓取框G,需要先明确抓取框在图像空间的表达方式。本文针对末端执行器为平行夹爪的情况,采用文献[1]提出的抓取框表达方法表示机器人抓取的具体位置,如图1所示,公式表示为:

其中,(x,y)为抓取框的中心点;h、w分别表示机器人平行夹爪的高度、平行夹爪张开的距离大小;θ为沿w方向与图像x轴正方向之间的夹角。过大的抓取框容易导致抓取中心点的偏移和预测的w远大于夹爪实际可张开的大小,抓取框的精确性直接影响机器人能否稳定地抓取目标物。
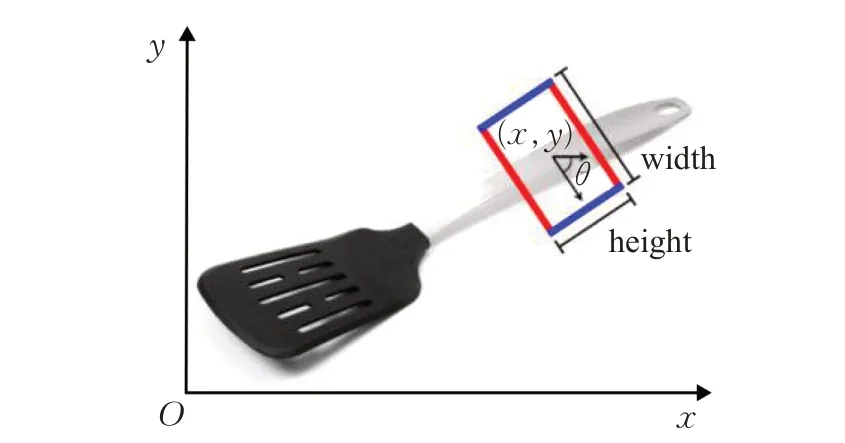
图1 抓取框在图像空间的表达方式
3 SE-RetinaGrasp模型
机器人目标抓取区域实时检测算法流程框图如图2 所示。首先,获取包含目标物的RGB 场景图像;其次对该图像进行数据预处理操作后,作为抓取检测网络模型的输入;最后模型生成可用于抓取目标物的抓取框,机械臂利用抓取框的位置姿态信息,完成抓取目标物的任务。

图2 机器人目标抓取区域实时检测算法流程
本文提出的SE-RetinaGrasp 模型如图3 所示。图(a)表示特征提取网络,在深度残差网络ResNet-50中嵌入SENet模块,对抓取检测任务起积极作用的特征通道加强权重;图(b)表示平衡金字塔结构,进一步融合特征金字塔结构FPN(Feature Pyramid Networks)[14]中高低层的特征信息;图(c)表示两个FCN(Fully Convolutional Networks)[15]子网络,分别用于抓取框的定位以及抓取角度的分类。

图3 SE-RetinaGrasp模型结构
3.1 RetinaNet一阶目标检测模型
一阶目标检测模型RetinaNet是由文献[12]提出,用以验证提出的Focal Loss 函数对解决训练过程中正负样本类别失衡问题的效果。考虑到目标物仅占输入图像中的一部分,为解决一阶目标检测模型中密集采样候选机制导致的正负样本失衡的问题,本文采用Focal Loss 函数作为分类损失函数、光滑L1 函数处理抓取框参数的回归问题。
其中,Focal Loss函数是一种改进的交叉熵(Cross-Entropy,CE)损失函数,通过在原有的交叉熵损失函数中乘上使易检测目标对模型训练贡献削弱的指数式,成功减少目标检测损失值容易被大批量负样本左右的现象。Focal Loss函数定义如下:
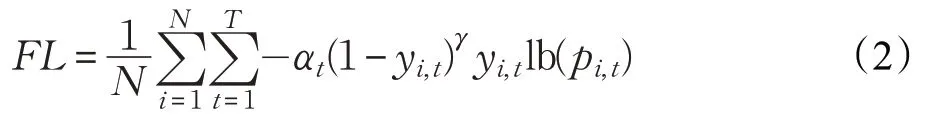
假设有N个样本,总共有T种分类,y为真实标签,pi,t为第i个样本被预测为第t类目标的概率大小;平衡参数α用以调整正负样本对总分类损失的贡献;(1-yi,t)γ为Focal Loss函数添加的指数式系数,用以降低易分类样本的权重,将更多注意力放在难分类样本的训练上。其中,α、γ为超参数,不参与模型的训练过程。
RetinaNet 检测模型主要由ResNet-50 提取特征网络、特征金字塔FPN 结构以及两个FCN 子网络组成。RetinaNet检测模型,如图4所示。

图4 RetinaNet检测模型结构
C1、C2、C3、C4、C5 分别为ResNet50网络中采用不同个数残差块(Residual)提取的不同分辨率大小特征图。根据低层特征语义信息弱,目标位置清晰;高层特征语义信息强,目标位置模糊的特点,FPN 结构通过自底向上连接、自顶向下连接以及横向连接,对不同层的特征信息进行融合。与原FPN结构不同的是:
(1)RetinaNet 模型仅利用C3、C4、C5 特征图,避免在高分辨率C2 特征图中生成Anchor,减少模型检测时间。
(2)对C5 特征图进行卷积核为3×3,步长为2 的卷积运算得到P6 网络结构;对P6 使用Relu 激活函数增加非线性后再进行相同的卷积运算得到P7 结构,通过在P6、P7 生成较大面积的候选区域增强模型检测大物体的性能。
与目标检测任务不同的是,抓取检测任务是检测可用于抓取目标物的区域位置,并非检测目标物自身的位置。针对目标物抓取区域面积较小的特点,为使RetinaNet模型更好地应用于抓取检测任务中,本文仅在P3、P4、P5 三个层次生成抓取候选区域,采用{82,162,322}基础大小的候选窗口,加入三种不同的尺度和{1∶2,1∶1,2∶1}三种不同的长宽比,搜索各种尺寸大小的抓取候选框。
3.2 SENet结构
从文献[10]的实验发现,将特征提取网络Vgg16[16]替换为ResNet-50仅提高0.5%的准确率,证明当网络达到一定深度时,继续加深网络层数并不能对准确率有较大的提升。本文从考虑特征通道之间的关系出发,在特征提取网络ResNet-50中的每一个残差块后嵌入SENet模块,增强抓取检测任务中关键通道的注意力,以提升检测准确度。SENet结构,如图5所示。

图5 SENet结构
SENet模块主要采用挤压(Squeeze)、激励(Excitation)以及特征重标定(Scale)三个操作完成特征通道自适应校准。
首先使用全局平均池化压缩每一个特征图,将C个特征图转换成1×1×C的实数数列,使每一个实数具有全局感受野。然后本文通过两个卷积层完成降维与升维的操作,第一个卷积层将特征维度降低到原来的C r后通过Relu激活函数增加非线性;第二个卷积层恢复原来的特征维度,经过Sigmoid函数得到归一化的权重,最后通过乘法逐通道加权到原来的特征通道上,对原始特征进行重标定。挤压、激励以及特征重标定公式如下所示:

3.3 平衡特征金字塔
针对原RetinaNet模型中FPN结构仅融合相邻层次的特征信息,导致高低层特征信息利用不平衡的现象。为进一步加强检测小抓取框的效果,充分利用不同分辨率下的特征信息,本文受文献[13]中平衡特征金字塔结构的启发,对原RetinaNet 模型中的特征金字塔结构进行改进。平衡特征金字塔结构如图6 所示。提取P3、P4、P5 三个层次的特征图,对P3、P5 分别采用最大池化操作、上采样操作,使P3、P5 的特征图分辨率与P4特征图保持一致,三者对应元素相加取平均,得到平衡特征图P′,公式如下:

其中,Pl表示第l层特征;本文中lmin、lmax代表最低层数、最高层,分别为3、5;N代表累加的层数量。对平衡特征图P′进行卷积核为3×3,步长为1 的卷积运算得到进一步提炼的特征图Pr,使特征信息更具有判别性。最后调整提炼后的特征图Pr分辨率大小分别与P3、P4、P5 层次的特征图分辨率大小一致,与原层次的特征对应元素相加,分别得到增强原层次特征表征能力的P3′、P4′、P5′,特征图,从而增强模型捕捉细节信息的能力,有助于检测小抓取框。
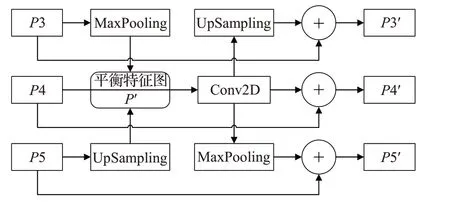
图6 平衡特征金字塔结构
4 实验
4.1 实验环境
本文的实验机器是一台配置型号为Intel®Core™i7-8750H 的CPU 和NVIDIA GeForce GTX 1070 的GPU的个人计算机,内存以及显存大小分别为32 GB、8 GB。该机在Ubuntu 16.04 上运行,基于深度学习框架keras使用Python 语言编写,借助CUDA(Compute Unified Device Architecture)加速运算。
4.2 实验数据集
本文采用Cornell数据集作为训练数据,图7为数据集中的部分图片。该数据集总共有885张图片,其中包含了244种不同种类的物体,每一种物体均有不同的摆放位置及姿态。数据集对每一张图片中的目标物体的抓取位置进行标记,共标记5 110 个可用于抓取目标物的矩形框和2 909个不可用于抓取的矩形框。本文实验将抓取数据集依照以下两种方式进行划分,得到708张图片作为训练样本、177张图片作为测试样本。

图7 Cornell数据集
方式1 按图片随机划分。将数据集图片随机划分至训练集和验证集中,以验证模型对已见过的、不同摆放位置的物体的泛化能力。
方式2 按物体种类随机划分。使训练集中并不含有测试集中的物体种类,以验证模型对未曾见过的新物体的泛化能力。
4.3 数据预处理
尽管Cornell 数据集包含的物体种类丰富,但数据量较小,为了使训练样本尽可能地涵盖各种可能出现的情况,本文对训练样本进行扩充:
首先对原始图像在x轴、y轴各做50 个像素点内的随机平移;然后对平移后的图片进行中心剪裁得到321×321 大小的图像;处理后的图像再进行0°~360°范围内的随机旋转;为了方便与其他算法进行比较,本文将原始图像分辨率大小为480×640 调整为227×227 作为网络模型的输入;
最后如文献[10]一样将抓取角度进行类别划分,考虑到抓取角度的对称性,本文将180°均分成19个区域,加上背景分类,本文实验共有20 种类别。标签中的角度值相应分配至最近的区域,将原本带有方向性的矩形框置为没有角度倾斜的矩形框,模型训练时拟合这些垂直于图像x轴的矩形框,并预测这些矩形框属于哪种角度类别。
4.4 模型训练的实现
考虑到RetinaNet模型内部层数较多且结构相对复杂,对于目前数据集数据规模较小的情况容易导致过拟合。为此本文采用迁移学习的方法进行抓取检测模型训练,将在微软COCO 数据集训练好的ResNet-50 模型参数作为初始值,在此基础上进行微调,网络中其余的参数采用标准高斯分布进行初始化。以图像RGB作为模型输入,学习率初始化为0.000 1,学习率衰减因子为5,设置每批训练图片数为2,epoch初始化为20,采用随机梯度下降法(SGD)对模型进行训练。
4.5 评估指标
通常有两种评估方法来衡量模型预测抓取姿态的效果:一种是点度量方法,另一种是矩形度量方法。
点度量评估方法主要以模型预测的抓取框中心点与标注真值框的中心点之间的距离作为衡量标准,当两点之间的距离小于预定的阈值,则认为预测结果可用于抓取目标物体并取最小值作为最佳抓取框。然而以往算法中没有公开点度量评估方法所使用的阈值,并且该方法没有将抓取角度纳入评估范畴中,所以更多的算法采用矩形度量作为评估方法。
矩形度量方法采用抓取矩形来衡量模型预测的效果,当预测的矩形框同时满足以下两个条件时,则认为该矩形框可用于抓取物体:
(1)预测的抓取角度与标注真值框的抓取角度之差小于30°。
(2)Jaccard 相似系数大于0.25,其中Jaccard 相似系数计算公式如下:

其中,gp为预测抓取矩形区域,gt为标注真值框的抓取矩形区域。本文采用矩形度量的评估方法,取预选抓取框中评判值最大的作为模型预测结果。
4.6 实验结果与分析
本文使用Cornell 数据集对提出的算法进行测试,测试结果如图8 和图9 所示:图8 展示模型预测的部分正确抓取框;图9展示模型预测结果中错误抓取框。

图8 模型预测的部分正确抓取框

图9 模型预测结果中错误抓取框
为进一步验证本文算法的有效性,本文进行以下两部分实验:
(1)原RetinaNet模型和SE-RetinaGrasp模型检测效果对比
将数据集按图片随机划分的方式切分训练集和测试集,利用原RetinaNet模型和SE-RetinaGrasp模型对测试集进行抓取检测,实验结果如表1所示。

表1 原RetinaNet模型、SE-RetinaGrasp模型结果对比
从表1中可以看出,嵌入SENet结构的RetinaNet模型较原RetinaNet模型准确率提高了1.13%,参数量较原RetinaNet模型增加8%,而平均检测时间几乎没有增加;基于SE-RetinaNet 模型的基础上引入平衡金字塔的思想,准确率进一步提升0.4%,参数量较SE-RetinaNet 模型仅增加1%,总体平均检测时间较原RetinaNet模型增加了1 ms。
实验分析可知,嵌入SENet结构有助于挖掘抓取检测任务中重要的特征通道,增强特征图的感受野;而引入平衡特征金字塔的思想进一步融合不同层次的特征信息,加强原来各层次中特征的表达能力,有助于检测物体中各种大小的抓取框。由于主要采用上采样以及最大池化操作,模型参数数量基本不变,并有效提高了检测准确率。本文算法与原RetinaNet检测效果如图10所示。

图10 原RetinaNet模型、SE-RetinaGrasp模型效果对比
由图10 可发现,对于同一种物体,原RetinaNet 检测的抓取框趋向于两端且仍有抓取框偏大的现象,而SE-RetinaGrasp 模型的抓取框更趋向于物体的中间位置且抓取框更为精准,提高了机器人抓取目标物体的稳定性。
(2)本文算法和其他算法检测效果对比
将本文算法与以往提出的算法进行对比,并比较不同方式划分数据集下检测准确率以及检测时间。对比结果如表2所示。
实验结果显示,本文算法可在保持高准确率的前提下,以实时速度检测抓取框,比文献[10]算法的检测速度快了将近6倍。
按方式1划分数据集,本文算法准确率均高于其他检测算法;按方式2 划分数据集,准确率稍低于文献[10]。本文算法的执行效率均高于其他经典抓取检测算法,尽管本文模型在生成候选抓取框时耗费了一定的时间,但本文算法的网络模型为全卷积网络且无文献[10]算法中区域生成网络该一步骤,有效地减少检测时间。

表2 本文算法与其他算法结果对比
为进一步体现本文算法性能,表3 展示了在不同Jaccard阈值下检测精度结果。结果表明,在更严格的评价标准中,本文算法仍保持较高的检测准确率,有助于机器人精确地抓取目标物。

表3 不同Jaccard阈值下的检测精度 %
本文通过复现文献[10]的抓取检测算法,与本文算法进行对比,具体效果如图11所示。

图11 本文算法与其他算法效果对比
由图11 的对比效果可发现,对于检测同一种物体不同摆放姿态下的抓取位置,文献[10]检测的抓取框偏大,精确度不足;本文算法预测的抓取框更加精细,主要原因在于本文算法充分利用不同层次的特征信息,并在不同层的特征图上检测抓取框,与文献[10]在提取特征网络的最后一层特征图上进行检测相比,本文算法能更好地捕抓目标物的细节信息,加强小抓取框的检测效果。
5 结束语
为了使机器人实时且准确地抓取目标物体,本文提出并验证了一种基于SE-RetinaGrasp 的神经网络模型。该模型以一阶目标检测算法RetinaNet 为基础,一方面,通过通道注意力SENet 结构,建立特征通道之间的相互依赖关系,提升对抓取检测任务起积极作用的特征并抑制用处不大的特征,从而提高检测准确率;另一方面,利用平衡金字塔的思想,在不增加太多参数的前提下,进一步融合不同层次的特征信息,加强模型对细节信息的捕抓能力。在Cornell 数据集上的实验证明,相比于传统抓取检测模型,SE-RetinaGrasp 模型保持高检测准确率的同时,实时性高,并且一定程度上提高了抓取框的精细程度。
然而,Cornell数据集针对的图像仅包含单一目标物体,对于现实生活中多物体堆叠的情况尚未能很好的解决,因此,如何能在多物体堆叠的场景下,实时准确地抓取相应物体是下一步的研究内容。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
中国交通信息化(2018年5期)2018-08-21 03:37:40
少儿科学周刊·少年版(2015年4期)2015-07-07 21:13:44
少儿科学周刊·少年版(2015年4期)2015-07-07 21:09:31
少儿科学周刊·少年版(2015年4期)2015-07-07 21:08:08
少儿科学周刊·儿童版(2015年4期)2015-06-17 03:37:19
