
基于Prometheus+ Grafana实现企业园区信息化PaaS平台监控
2020-10-09 09:09陈秋燕
数字通信世界 2020年9期
黄 静,陈秋燕
(1.中国移动通信集团广东有限公司,广东 广州 510640;2.浪潮世科(山东)信息技术有限公司,山东 济南 250000)
1 Prometheus与Grafana介绍
1.1 定义
Prometheus是一种开源的系统监视和警报工具,基本原理是通过HTTP协议周期性抓取被监控组件的状态,只要提供HTTP接口就可以接入监控系统,不需要任何SDK或者其他的集成过程[1]。
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知[2]。
1.2 优点
Prometheus作为Google发起的linux基金会的第二大开源项目有如下优点[3]:
(1)提供多维度数据模型(基于时间序列的k/v键值对)。(2)灵活的查询及聚合语句(PromQL)。(3)支持服务器节点的本地存储,并且可以对接第三方时序数据库和OpenTSDB等。(4)支持通过静态文件配置和动态发现机制发现监控对象,自动完成数据采集。(5)易于维护,可以通过二进制文件直接启动,并且提供了容器化部署镜像。(6)支持数据的分区采样和联邦部署,支持大规模集群监控。
支持多种模式的图形和仪表板。
Grafana作为开源的可视化工具有如下优点:
(1)可视化:快速和灵活的客户端图形具有多种选项。面板插件为许多不同的方式可视化指标和日志。(2)混合数据源:在同一个图中混合不同的数据源,可根据每个查询指定数据源。适用于自定义数据源。(3)告警:可视化地为最重要的指标定义告警规则。Grafana将持续评估它们,并发送通知。(4)动态仪表盘:使用模板变量创建动态和可重用的仪表板,根据所选的模板变量动态创建面板。(5)注释:注释来自不同数据源图表。将鼠标悬停在事件上可以显示完整的事件元数据和标记。(6)过滤器:过滤器允许您动态创建新的键/值过滤器,这些过滤器将自动应用于使用该数据源的所有查询。
1.3 现状
Prometheus+Grafana是Kubernetes集群常用的一套比较成熟的预警监控方案,在Kubernetes官方社区或腾讯云社区也有很多相关的案例。 Prometheus支持数据的分区采样和联邦部署,支持大规模集群监控。 Grafana可以根据各个业务线需要监控的需求定义各种各样的图表,操作简单并提供预警功能。基于Kubernetes集群搭建的PaaS平台选择Prometheus+Grafana来实现平台的监控预警功能,使企业园区信息化系统更加稳定、高效运行。
2 Prometheus+Grafana监控系统的设计架构
监控的实现过程是,将平台和业务系统中所涉及的硬件资源、软件资源、系统信息等纳入统一的运维监控平台中,并通过消除管理软件的差别,数据采集手段的差别,对各种不同的数据来源实现统一管理、统一规范、统一处理、统一展现,最终实现运维规范化、自动化、智能化的大运维管理。
运行监控和故障告警是一个监控系统的两个主要功能模块。根据以上原理,PaaS平台监控的实现架构设计如下图所示,划分两大模块,分别是数据收集提取模块和监控告警模块。具体的,从低到高又分为6层,分别是数据收集层、数据提取层、数据展示层、告警规则配置层,告警发生层、告警显示层。
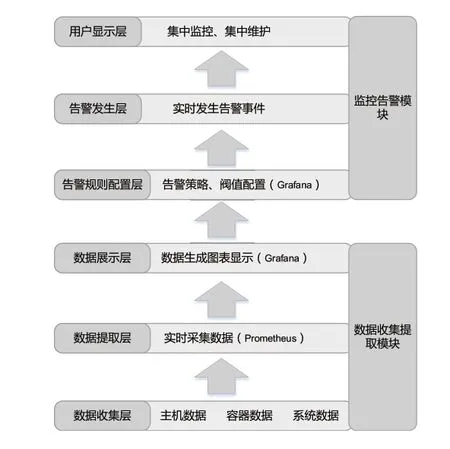
3 Prometheus+Grafana监控系统的模块功能及实现
3.1 数据收集层
主要收集主机数据、系统数据、容器数据等,然后将收集到的数据进行规范化,并进行存储。
①根据实际业务及资源情况需求,搭建好Kubernetes集群,把集群作为监控目标。
②在集群内安装exporter和cadvisor,实现对集群性能数据的获取。如cpu、内存、磁盘、网络等资源数据信息。
③通过exporter采集不同维度的监控指标,并通过Prometheus支持的数据格式暴露出来,Prometheus定期pull数据并用Grafana展示。
④通过cadvisor采集容器、Pod相关的性能指标数据,并通过暴露的metrics接口用prometheus抓取。
⑤通过prometheus-node-exporter采集主机的性能指标数据,并通过暴露的metrics接口用prometheus抓取。
3.2 数据提取层
主要是通过部署时编写好的yaml文件内的告警规则语言,将数据收集层获取到的数据进行规格化和过滤处理,提取需要的数据到监控告警模块, Prometheus把收集到的数据通过exporter保存统一格式的数据存储到Prometheus自带的时序数据库,用于grafana调用。
(1)Prometheus搭建安装具体实现操作如下六个步骤:
①把Prometheus镜像打包好并且放到集群镜像仓库中,用于后面Prometheus的安装。
②在搭建好的Kubernetes集群中创建名字为monitoring的命名空间,主要用于存放Prometheus运行的容器。
③给monitoring分配集群的读取权限,用于Prometheus可以通过Kubernetes的API获取集群的资源相关信息。
④在monitoring创建ConfigMap用来存储Prometheus容器的一些配置以及Kubernetes集群中动态发现pod和运行中的服务的配置。
⑤创建Deployment模式的Prometheus,通过yaml文件安装Prometheus。
⑥连接Prometheus,通过yaml文件把Prometheus内部端口映射成外部端口,用于Kubernetes集群自动连接到Prometheus,即Prometheus部署成功。
(2)Prometheus工作流程
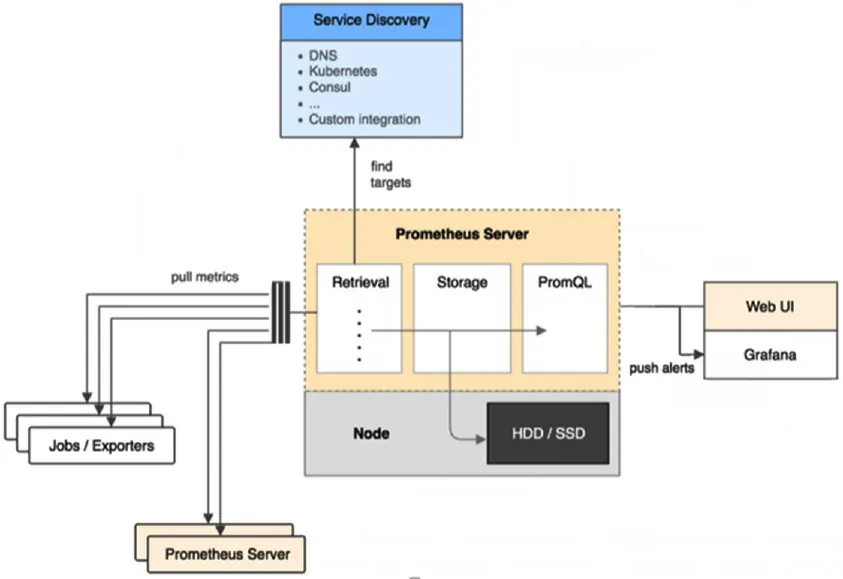
如图所示,工作流程为:Prometheus server 定期从配置好的exporters 中拉 metrics;Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Grafana推送警报;Grafana根据配置文件,对接收到的警报进行处理,发出告警;在图形界面中,可视化采集数据。
3.3 数据展示层
数据展示层是一个web展示界面,主要是将数据收集层获取到的数据进行统一展示,展示的方式可以是曲线图、柱状图、饼状态等,通过将数据图形化,可以帮助运维人员了解一段时间内主机或网络的运行状态和运行趋势,并作为运维人员排查问题或解决问题的依据。实现数据展示层主要通过Grafana工具,具体操作步骤如下[4]:
把Grafana镜像打包好并且放到集群镜像仓库中,用于后面Grafana的安装。
①通过yaml文件安装Grafana。
②连接Grafana,通过yaml文件把Grafana内部端口映射成外部端口,用于Kubernetes集群自动连接到
Grafana。
③使用管理员账号登录Grafana,并且配置Prometheus的数据源。
④编辑好需要图表类型的JSON文件,导入到Grafana,用于调用各个图表的样式,显示各个数据类型的图表。
⑤连接Grafana,即可看到相关默认模式的监控数据,即Grafana部署成功。
3.4 告警规则配置层
告警规则配置层主要是根据第三层获取到的数据进行告警规则设置、告警阀值设置、告警联系人设置和告警方式设置等。该功能主要通过grafana进行配置,具体操作如下:
①连接登录Grafana
②打开设置面板,选择预警接收类型,如邮箱、短信
③设置预警值的范围
④预警配置成功,当资源到达设置的预警范围,即能发送预警通知。
3.5 告警事件发生层
告警事件发生层主要是将告警事件进行实时记录以及通知用户。
3.6 用户显示层
用户显示层是一个web展示界面,主要是将监控统计结果、告警故障结果进行统一展示。
4 监控效果
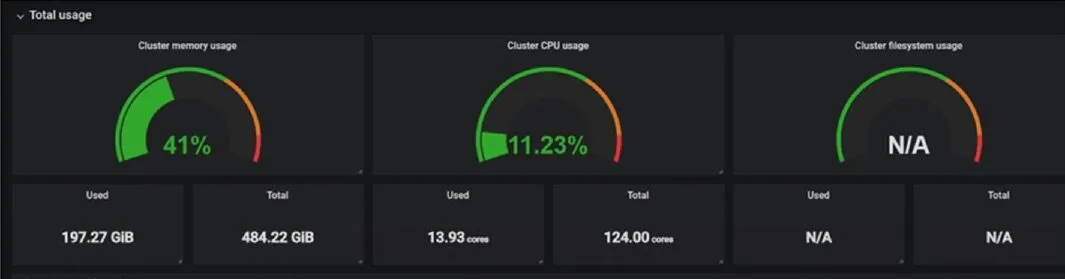
4.1 计算机节点监控情况
(1)集群内存、CPU概况
(2)集群网络情况

4.2 集群应用pod资源情况
(1)集群pod资源概况
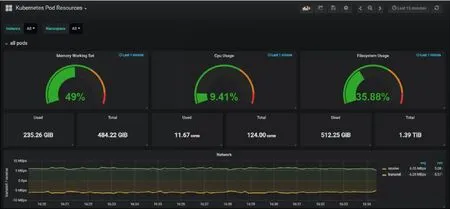
(2)cpu/内存实时监控显示图
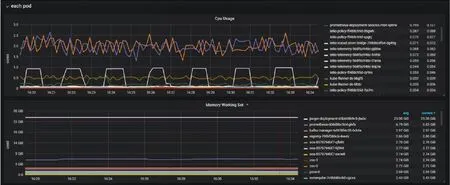
(3)网络/文件系统实时监控显示图
5 结束语
使用开源工具Prometheus与Grafana结合实现PaaS平台进行监控部署的方法,可以提高运维人的维护能力,实现监控手段的自维。
猜你喜欢
当代党员(2020年20期)2020-11-06
创新作文(1-2年级)(2019年3期)2019-09-03
软件和集成电路(2019年7期)2019-08-30
小型微型计算机系统(2019年3期)2019-03-13
小康(2018年23期)2018-08-23
计算机与生活(2018年3期)2018-03-12
办公自动化(2016年18期)2016-08-20
办公自动化(2016年18期)2016-08-20
电脑爱好者(2015年20期)2015-09-10
小康(2015年4期)2015-03-31
