
基于YOLOv2-Tiny的环视实时车位线识别算法
2020-09-30 02:03何俏君郭继舜关倩仪
汽车电器 2020年9期
何俏君,郭继舜,关倩仪,钟 斌,付 颖,谷 俊
(广州汽车集团股份有限公司 汽车工程研究院,广东 广州 511434)
随着近年来人工智能技术的蓬勃发展,关于智能驾驶技术的研究在汽车行业快速兴起。其中,自动泊车辅助系统(Automatic Parking Assist,APA)受到众多新兴人工智能领域企业以及传统汽车制造企业的广泛关注并展开了相关技术研究。车位识别作为自动泊车系统中的感知环节,其准确性和快速性对后续车辆泊车路径规划与控制至关重要。
目前已有的空闲车位识别技术可以分为基于超声波雷达探测,基于视觉的空闲车位识别以及超声波与视觉相融合3种基本模式。得益于360°环视成像技术的成熟发展,本文提出一种基于环视图像的全视觉空闲车位线识别方法。在其他学者既已提出的众多研究车位线自动识别方法中,可划分为依据线检测与依据角点检测定位车位两种基本思路。
文献[1,2]中结合环视图像边缘提取与Hough变换检测直线实现车位线定位,除了Hough变换外,文献[3]使用Line Segment Detector(LSD)检测识别车位线。基于直线检测的车位定位对部分仅画出角点附近车位线的车位适用性不高,且直线检测对图像噪声点较为敏感,环境复杂的情况下对检测准确度影响较大。基于角点检测的思路,Suhr等人[4]提出分层树模型以自下而上、自上而下两种模式搜索定位车位角点完成车位线识别,但难以满足实时性要求。Lin[5]等提出训练分类器检测角点并结合先验逻辑约束重构车位,但仅能用于检测角点为直角的车位线。而文献[6]中提出基于深度学习的车位检测方法,分别用目标检测网络检测角点,并训练另一个网络匹配角点对模式,结合模板匹配确定车位摆向。该方法利用了深度学习强大的非线性拟合能力,但对运算所需硬件设备要求较高且角点中心定位准确程度对车位摆向影响较大。
以自动泊车系统所要求的运算资源成本低且实时性要求高为出发点,本文提出一种基于轻量化深度学习目标检测网络YOLOv2-Tiny的角点检测方法,结合车位线骨架信息提取,对网络定位角点不精确的问题进行校正,并进一步将概率霍夫变换直线检测应用于角点区域骨架上,减少全局噪声对直线检测精度的影响,最终确定重构的车位线,算法流程图如图1所示。
1 鱼眼矫正拼接环视图像
鱼眼摄像头成像角度广,可收集近距离内较多视场信息,但鱼眼相机拍摄图像时存在严重畸变,故需预先对鱼眼摄像头进行标定校正。
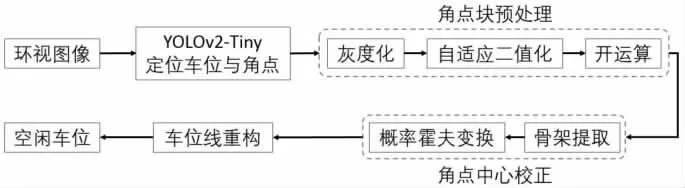
图1 本文车位线识别算法流程图
1.1 鱼眼摄像机模型中的坐标系统
世界坐标系 (world coordinate system):用户定义的三维世界的坐标系,为了描述目标物体在真实世界里的位置而被引入。
相机坐标系 (camera coordinate system):在相机上建立的坐标系,为了从相机的角度描述物体位置而定义,作为沟通世界坐标系和图像/像素坐标系的中间一环。
像素坐标系 (pixel coordinate system):描述物体成像后的像点在数字图像上的坐标,是从相机内真正读取到的信息所在的坐标系。
图像坐标系 (image coordinate system):描述成像过程中物体从相机坐标系到图像坐标系的投影透射关系,可进一步得到像素坐标系下的坐标。
标定过程分为两部分。
第1部分为世界坐标系转换为相机坐标系,这一步是三维点到三维点的转换,转换关系为:
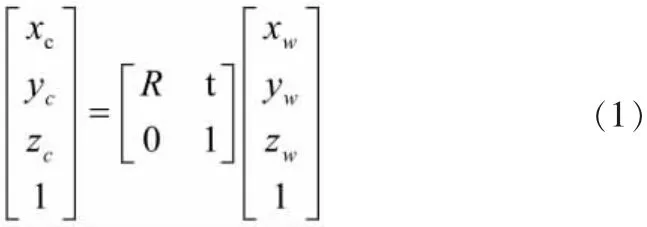
式中:R——3×3的旋转矩阵;t——3×1的平移矢量;(xc,yc,zc,1)T——相机坐标系的齐次坐标; (xw,yw,zw,1)T——世界坐标系的齐次坐标。
第2部分是相机坐标系转换为像素坐标系,是三维点转为二维点的过程。但因像素坐标系不利于坐标转换,需先建立图像坐标系,由像素坐标系转换为图像坐标系:
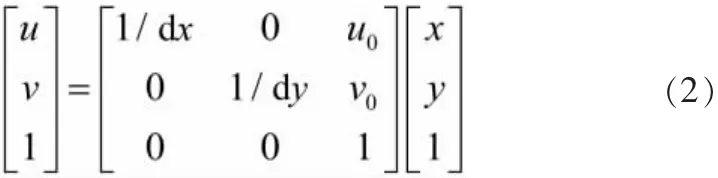
式中:1/dx,1/dy——分别为沿x轴与y轴方向单位物理尺寸上的像素个数;(u,v)——图像中心点的像素坐标。
由相机针孔成像原理可知,相机坐标系转换为图像坐标系即为透视投影过程。转换关系如下:
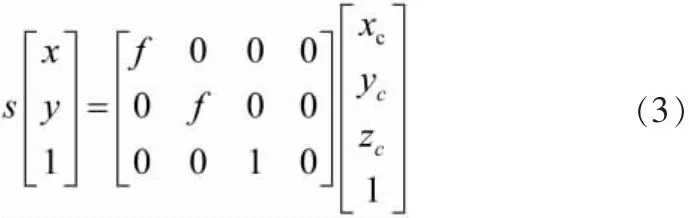
式中:s——比例因子 (s不为0);f——有效焦距 (光心到图像平面的距离); (x,y,z,1)T——空间点P在相机坐标系OXYZ中的齐次坐标; (x,y,1)T——像素点p在图像坐标系OXY中的齐次坐标。
通过将世界坐标系上的坐标值投影到对应的像素坐标系上的像素点,在此过程中可求解出相机的内外参数。转换关系可表示为:
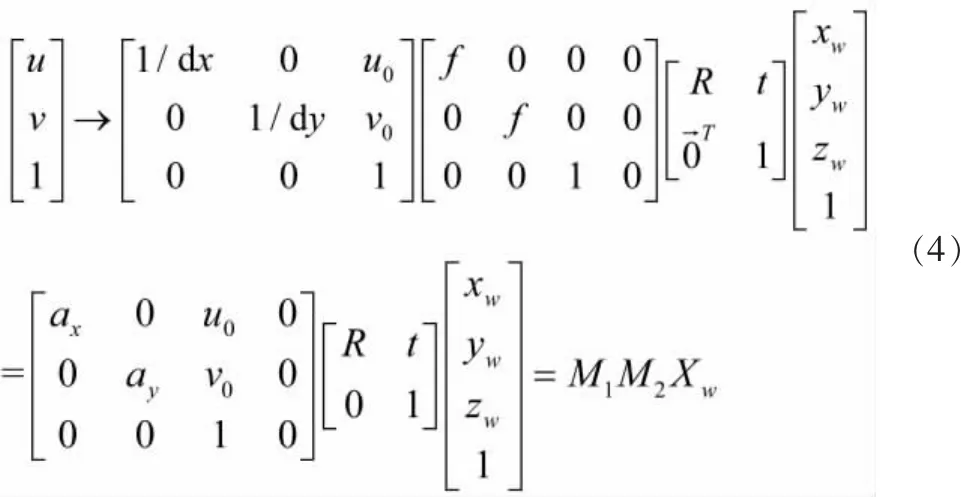
式中,R——3行3列矩阵,称为旋转矩阵;t——三维列向量,称为平移向量;M1——相机内部参数矩阵;M2——相机外部参数矩阵。
1.2 鱼眼摄像机标定技术
为了矫正鱼眼相机产生的畸变,需先标定相机求出内外参数。相机标定技术主要分为两种:相机的自标定法和摄影标定法。张正友棋盘格标定法是介于二者之间,接受度较高的方法,既克服了摄影标定法需要的高精度三维标定物的缺点,又解决了自标定法鲁棒性差的难题。
张氏标定法[7]是一种基于平面棋盘格的标定法,通过图像平面与标定物棋盘格平面的坐标系映射关系确定单应性矩阵,利用约束条件求解相机的内参数矩阵并由其估算出相应的外参数矩阵,从而达到标定相机并矫正的目的。具体流程如下。
1)打印一张棋盘格,贴在一个平面上以作为标定物。
2)通过调整标定物或摄像机的方向,为标定物拍摄一些不同方向的照片。
3)从照片中提取棋盘格角点。
4)估算理想无畸变的情况下,5个内参和6个外参。
5)应用最小二乘法估算实际存在径向畸变下的畸变系数。
6)极大似然法对畸变系数进行优化估计,提升估计精度。
1.3 环视图像拼接
多个鱼眼摄像头收集到图像数据后需要将其拼接成一幅完整画面。本文使用尺度不变特征转换 (SIFT,Scale-invariant Feature Transform)方法匹配2幅图像相同的特征点,通过随机一致性采样 (RANSAC,Random Sample Consensus)筛选正确的特征匹配并输出透视矩阵,利用透视变换完成图像的拼接,循环这个流程迭代所有图像就可以完成多张图像的全景图拼接。
SIFT特征提取分为检测特征点,确定特征点的尺度方向,生成特征向量,最后进行匹配。首先扫描图片所有尺度下的所有位置,计算2个相邻的高斯尺度空间差值得到高斯差分空间,高斯差分空间的众多极值点即为特征点;利用直方图统计方法,求出邻域内所有像素点的梯度方向以及幅值,直方图的峰值所代表的方向即为特征点的主方向;通过求得特征点的邻域梯度信息来计算特征向量;采用最近邻方法计算特征向量的欧氏距离从而匹配特征点。
随机一致性采样算法 (RANSAC)是随机采用部分特征匹配坐标计算得到一个透视矩阵,利用此透视矩阵测试所有的匹配点,若匹配结果良好则输出该透视矩阵,否则换用其他特征匹配坐标。该方法的作用是剔除掉不正确的特征匹配结果,获得正确的透视矩阵。
透视变换就是将图像投影到一个新的视平面上。在全景图拼接时,很多图像会由于拍摄角度等问题出现一些方向上的不同步,需要旋转图像到相同视角再拼接。而控制旋转变换的方式即是通过透视矩阵与原图像的矩阵形式进行相乘得到新的图像矩阵方可进行拼接。原视频与拼接后的图像对比如图2所示。

图2 原视频与拼接后的图像对比
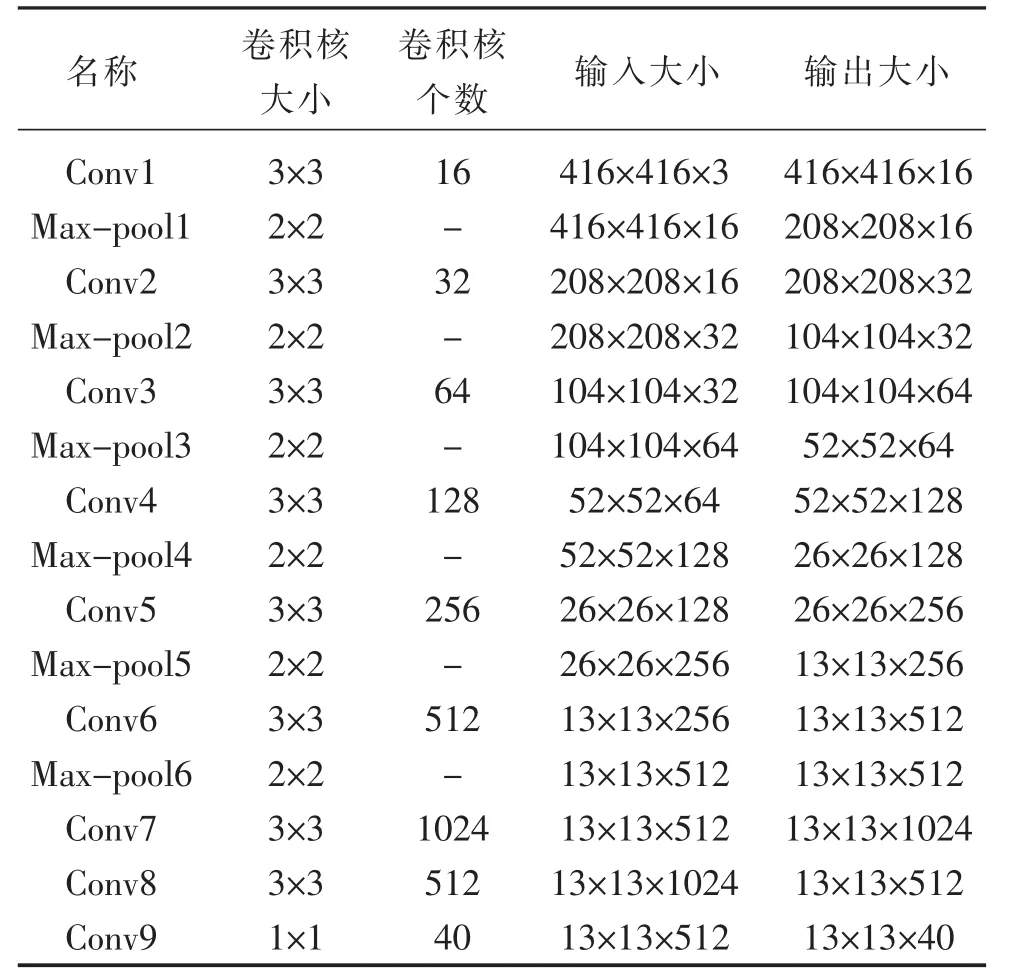
表1 YOLOv2-Tiny结构组成
2 基于YOLOv2-Tiny的空闲车位与角点检测
2.1 YOLOv2-Tiny目标识别
基于darknet框架的YOLO目标检测模型最早于2016年由Redmon等提出,YOLO通过网格化分割方式回归目标边界框同时预测类别,相较于当时表现出色的Faster-RCNN目标检测模型,YOLO检测效率大幅提升,对实时性要求高的目标检测任务适用性更好。随后YOLO模型进一步发展至YOLOv2,其特征提取基于darknet-19实现,通过在网络中加入了批归一化,多尺度特征提取,引入固定框 (anchor boxes)取代全连接层进行边界框回归等改进从而优化YOLO分类与定位效果,并进一步提升检测效率。
然而,尽管基于深度网络的YOLOv2模型对运算资源硬件要求较SSD、Faster-RCNN等目标检测模型有所降低,仍难以满足其在车载嵌入式ECU得以广泛应用所期待的低成本与高效率二者相平衡的要求。因此,针对全自动泊车系统中基于视觉的空闲车位检测任务的应用场景,使用轻量化的YOLOv2-Tiny模型适应车载嵌入式ECU算力低且检测任务实时性要求高的特点。YOLOv2-Tiny的网络结构共包含9个卷积层,6个池化层,具体每层卷积核大小和数量如表1所示。
2.2 空闲车位区域与车位线角点识别
本文基于YOLOv2-Tiny模型对空闲车位区域以及角点进行识别,其中角点类型分为T型角点 (图3a)与L型角点两种(图3b),共3种目标类型。

图3 两种角点类型
2.3 网络训练
实验中网络训练部分基于Darknet框架在Ubuntu 16.04 LTS系统,中央处理器为主频2.10GHz的Intel Xeon E5-2683 v4,GPU为TITAN X配置下实现。采用文献[6]中提供的不同天气状况,不同室内外环境,不同光照方向与光照强度下采集的公开数据集进行训练与测试。数据集包含共10000张环视车位图像,其中8000张作为训练样本,其余作为测试样本。YOLOv2-Tiny网络训练超参数设置如下:批次大小为16,迭代次数为10000,学习率为0.001。
2.4 识别精度与效果
利用训练好的网络权重在Ubuntu 16.04 LTS系统,中央处理器为主频2.80GHz的Intel Core i7-7700HQ,GPU为NVIDIA Quadro M1200配置下实现对2000张测试样本图进行测试,得到空闲车位区域与两种角点识别准确率如表2所示。从表中可以看出,训练后的YOLOv2网络对空闲车位检测效果十分理想,两种类型角点的检测精度较高,其轻量化结构使其检测效率大大提高,能满足自动泊车系统的实时性要求。
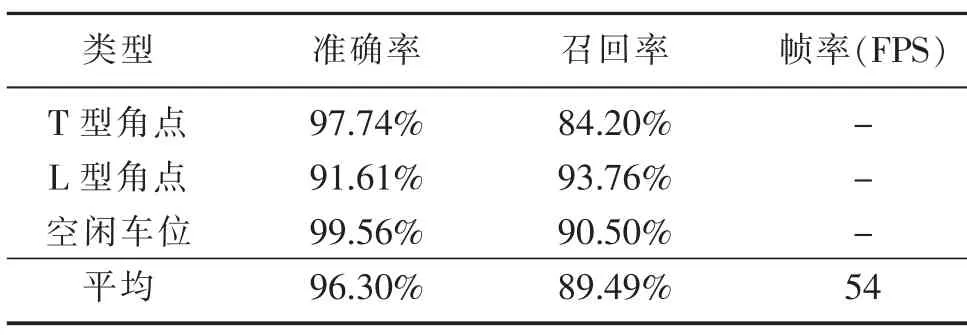
表2 YOLOv2-Tiny识别精度
训练好的网络对测试图片检测结果如图4所示,从图4可看出网络能正确定位空闲车位区域,并识别出角点类型与位置,根据角点块中心与车位区域间的相对位置可筛选出每个车位区域内的角点,后续根据角点位置重构实际车位线。

图4 空闲车位与角点识别效果
3 基于角点块骨架提取的角点中心校正
第2章中训练好的YOLOv2-Tiny网络能基本定位角点块区域,理想状态下角点块区域中心像素点坐标为实际角点坐标,但由于YOLOv2-Tiny较于其他深度网络轻量化的特性,其对角点中心的定位精度有所降低。环视图像中具有一定宽度的车位线在图像上往往对应覆盖多个像素点范围,准确意义上的角点中心为2条线各自覆盖的像素点区域中心轴相交的交点。图像骨架提取指的正是相连通的像素点区域细化至单位像素宽度的过程,对于线状轮廓而言,经过骨架提取后可得到单位宽度的中轴线,2条中轴线的交点即为实际角点中心。
3.1 角点校正预处理
对图像进行骨架提取前需要对原始角点区域图像进行灰度化和自适应阈值二值化。各步骤处理角点图像效果如图5所示。

图5 各步骤处理角点图像效果
3.2 角点骨架提取
本文使用Zhang[8]提出的经典快速并行图像细化算法对识别出的车位角点块进行骨架提取,该算法迭代逐次消除角点框内直线的边缘像素点,将每个像素点的相邻像素点分布编号为如图6所示顺序,每轮消除满足以下 1)~3)3个条件的像素点,直到没有新的像素点被消除停止迭代。
快速并行细化算法删除点条件如下所述。
1)与中心像素点相邻的8个像素点之和满足式 (5)。
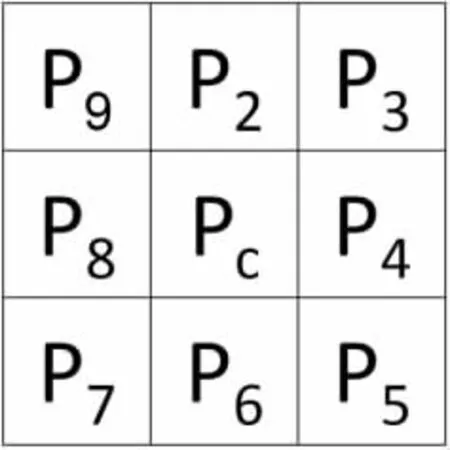
图6 相邻像素点编号序列

2)顺时针遍历P2~P9,像素点从0变成1的总次数等于1,即满足式 (6)。
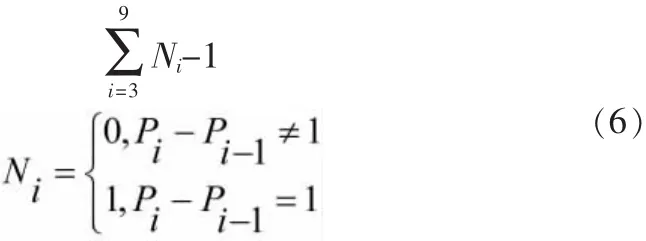
3)奇数轮迭代满足:
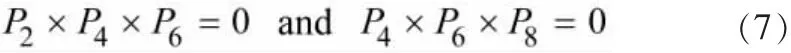
偶数轮迭代满足:
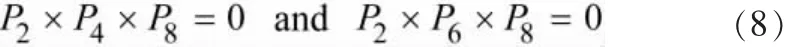
使用快速并行细化算法对角点提取骨架后的结果如图5e所示。
3.3 概率霍夫变换检测直线得到交点坐标
标准霍夫变换建立了二维空间(x,y)与参数空间(ρ,θ)间的投影变换,二维空间中的直线对应参数空间中的某个点(ρ0,θ0),因此二维空间直线上的所有点变换后都对应经过该点 (ρ0,θ0),由此可将直线检测转化为参数空间的高频点检测,霍夫变换中两个空间的关系满足式 (9):

标准霍夫变换可用于直线检测,在此基础上,概率霍夫变换把图像边缘点投影至参数空间并累积至满足设定阈值后终止,较标准霍夫变换效率更高,可有效检测线段,对本文识别任务更为适用。利用概率霍夫变换可以得到角点骨架线段,并进一步通过线段起始点和终点相对位置确定不完整显示车位的摆向。
基于细化后的角点骨架,利用概率霍夫变换检测线段的结果如图5f所示。通过筛选可以得到通过2条有效线段的2个端点 (xs,ys), (xd,yd),根据2个端点相对位置可以确定2条车位线的斜率k1,k2(式 (10)) 以及式 (11) 所示直线表达式,进一步联立两个表达式可以求得式 (12)所示交点c=(xc,yc),即校正后的角点中心坐标。图7为经过角点校正后识别出的环视图像车位角点标记。
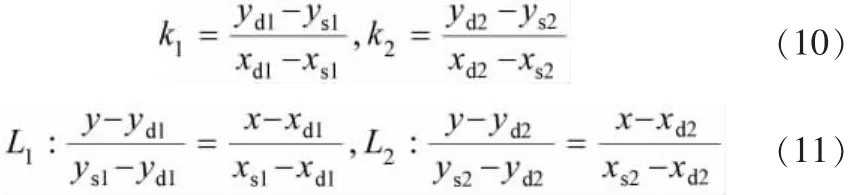


图7 角点中心校正前后对比
4 车位线重构
由3.3节中计算的校正后角点位置和斜率可分不同情况对实际车位线进行重构,对于不完整显示的车位需要识别出2个有效角点方可进行实际车位重构,具体可划分为如下3种情况。
1)识别出的角点个数等于4。根据4个角点中心位置,两两计算其连线的斜率,与每个角点对应2条车位线的斜率k1,k2相比较,将在误差允许范围内连线斜率与k1,k2二者之一相等的2个角点相连,4点相连可得实际车位。
2)识别出的角点个数等于3。根据车位线对边平行的特性可以计算出第4个车位角点坐标,得到4点坐标后对应情况1)实现车位线重构。
3)识别出的角点个数等于2。此时为车位不完整显示于环视图像中的情况,识别出的2个角点为同侧角点,计算2个角点中心连线的斜率km与检测得到的各自对应的车位线斜率k1,k2相比较,相差较大者分别为2个角点另一端不完整车位线的斜率ks。以单条车位线为例,沿其斜率方向延伸可以与环视图像边界交于两点p1,p2,以角点中心c为起点,与图像边界角点为终点可以得到2个向量,。该角点骨架经过概率霍夫变换后可以得到的对应斜率kn的线段2个端点sn,dn,以离角点中心c较接近的端点为起始点s,较远点为终点d,可得到车位摆向向量,分别对计算与的内积,满足式 (13)的向量c为同向,对应点p*为有效交点。

车位线重构效果如图8所示,蓝色线段为重构的车位线。
5 结束语

图8 车位线重构效果图
针对自动泊车系统中实时检测空闲车位这一实际任务,本文提出了一种使用轻量网络YOLOv2-Tiny进行角点检测的算法,并基于角点检测结果结合骨架提取与概率霍夫变换进行角点中心校正。角点校正一方面可以弥补使用轻量化网络带来的角点定位偏差问题,另一方面基于角点块区域检测直线可以减轻全局环境噪声对直线检测精度的影响,且可检测角度多变的不同类型车位。通过实验结果证明本文所提出的车位线识别算法效果良好,且轻量化网络检测效率高,可满足自动泊车系统实时性要求。
猜你喜欢
汽车电器(2021年8期)2021-08-24
汽车电器(2021年7期)2021-08-04
现代电子技术(2021年1期)2021-01-17
汽车维修与保养(2020年11期)2020-06-09
小读者之友(2019年9期)2019-09-10
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
东坡赤壁诗词(2018年6期)2018-12-22
现代电子技术(2018年18期)2018-09-12
电脑知识与技术(2018年35期)2018-02-27
