
层次化神经网络模型下的释义识别方法
2020-09-27 10:51:26袁自勇
哈尔滨工业大学学报 2020年10期
袁 蕾,高 曙,郭 淼,袁自勇
(武汉理工大学 计算机科学与技术学院,武汉 430000)
随着互联网的发展和个人移动终端的普及,互联网上产生的信息以爆炸方式增长.这些信息数量庞大、种类繁杂,且大部分是以短文本(或句子)的方式存在的,包括Twitter、微博的推文,电商网站的用户评价等.这些短文本数据具有稀疏性、实时性、不规范性等特点,导致人工处理这些海量的短文本信息极其困难.对用户生成的噪声文本进行释义识别是自然语言处理、信息检索、文本挖掘领域的重要任务,对查询排名、剽窃检测、问答、文档摘要等领域也起到了重要作用[1].最近,由于需要处理语言变异的问题,释义识别任务已经在自然语言处理领域中获得了极大的关注.
释义识别,又称复述检测,通常被形式化为二进制分类任务:对于给定的两个句子,确定它们是否具有相同的含义,具有相同含义的句子称为释义对,而具有不同含义的句子称为非释义对[2].
传统的释义识别方法主要关注文本的特征,包括字面特征、语法特征、语义特征等.但这些方法存在准确率不高和受到语料库限制导致适应性差等缺点.随着神经网络发展,专家学者们陆续提出了各种基于神经网络的释义识别模型.这些基于神经网络的释义识别模型大大提高了识别的准确率,但仍存在一些问题:易受到数据集限制,在大型数据集上表现良好的模型,常常在小型数据集上表现较差等.同时,现有神经网络释义识别模型大多采用“编码-匹配”模式,对句子对进行编码、匹配操作以后,结果被直接用于分类,没有充分利用匹配结果中的信息.针对这些问题,本文提出了一种面向释义识别的层次化神经网络模型,它采用了“编码-匹配-提取”模式,编码层使用基于注意力的上下文双向长短期记忆力网络(Attention Based Contextual Bi-directional Long Short-Term Memory Network, ABC-BiLSTM)作为编码器,获取前向和逆向两个长短期记忆力网络(Long Short-Term Memory Network, LSTM)所有隐藏层状态,并且通过注意力机制(Attention Mechanism)提取权重信息;匹配层利用多种矩阵运算获得匹配结果;特征提取层则利用Xception作为提取器,以便进一步从句子匹配结果中提取分类特征.
1 国内外研究现状
近年来,国内外相关学者在释义识别领域投入了大量的研究.识别两个句子是否是释义对,即是识别二者是否足够相似,包括字面上的相似和语义上的相似.现有的释义识别方法主要有基于特征的方法和基于神经网络的方法.
基于特征的方法主要关注文本的特征,包括n-gram重叠特征[3]、语法特征[4]、语言特征[5-6]、基于维基百科的语义网络[7]、知识图[8]等.该类方法通过提取文本对的特征,然后通过计算特征向量的相似度,判断两个文本是否是释义对.计算特征向量的相似度方法有余弦相似度、欧式距离以及词移距离等方法.
基于神经网络的方法有两种,一种是通过神经网络计算词向量,然后计算词向量的距离得到文本相似度,判断是否是释义对.如黄江平等使用神经网络训练词向量,并使用改进的EMD方法计算向量间的语义距离,获得文本释义关系[9].另一种是通过神经网络模型直接输出文本是否是释义对,本质上是一种分类算法.常用的神经网络模型有卷积神经网络(Convolutional Neural Network,CNN)、递归神经网络(Recurrent Neural Network, RNN)、注意力机制等.在这些模型的基础上,学者们提出了各种适用于释义识别的神经网络模型.包括Wang等提出的BiMPM,通过双向长短期记忆网络(Bi-directional Long Short-Term Memory Network, BiLSTM)编码句子,在两个方向上匹配来自多个角度的编码结果[10];Chen等的ESIM模型,使用两层BiLSTM和自注意力机制,将编码后结果通过平均池化层和最大池化层,输入决策层分类[11];Kim等设计的一种具有密集连接的互注意力循环神经网络DRCN,主要由单词表示层,注意力机制连接的RNN编码层和交互预测层组成[12]等.
综上,基于特征和基于神经网络的释义识别方法,或者受到语料库限制,或者缺乏特征提取机制,或者模型准确率对数据集大小较敏感,有待进一步提升。因此,本文设计了面向释义识别的层次化神经网络模型,通过增加特征提取层并在相关层提取更丰富的语义和分类信息,从而克服以上问题.
2 问题定义
对于给定长度为p的句子A=(a1,…,ap)和长度为q的句子B=(b1,…,bq),求分类结果y∈{0,1}.y=0表示两个句子含义不同(是释义对),y=1表示两个句子含义相同(非释义对).
3 面向释义识别的层次化神经网络
本文提出的面向释义识别的层次化神经网络(Hierarchical Paraphrase Identification Network, HPIN)模型是一种分层结构,由输入层、嵌入层、编码层、匹配层、特征提取层、输出层组成.图1显示了该模型的整体结构.与已有的释义识别神经网络模型不同,HPIN采用“编码-匹配-提取”模式,在“编码-匹配”模式基础上,添加了特征提取层,以便从匹配结果中提取更多分类信息.HPIN各层的概述如下.
1)输入层用于将句子转换为向量形式,即用不同的数字表示不同的单词.该层的输入是句子对,输出是向量对.
2)嵌入层使用密集分布向量表示输入句子的每个单词,向量之间的距离表示语义的相似程度.该层对预训练词向量(包含可训练和不可训练两种)、字符向量和附加特征向量进行连接,并作为最终词向量.嵌入层的输入是向量对,输出是词向量矩阵对.
3)编码层用于学习句子的上下文信息.编码层采用基于注意力机制的上下文双向长短期记忆力网络,能够获取前向和逆向两个LSTM中所有单元的隐藏状态.该层的输入是词向量矩阵对,输出是编码矩阵对.
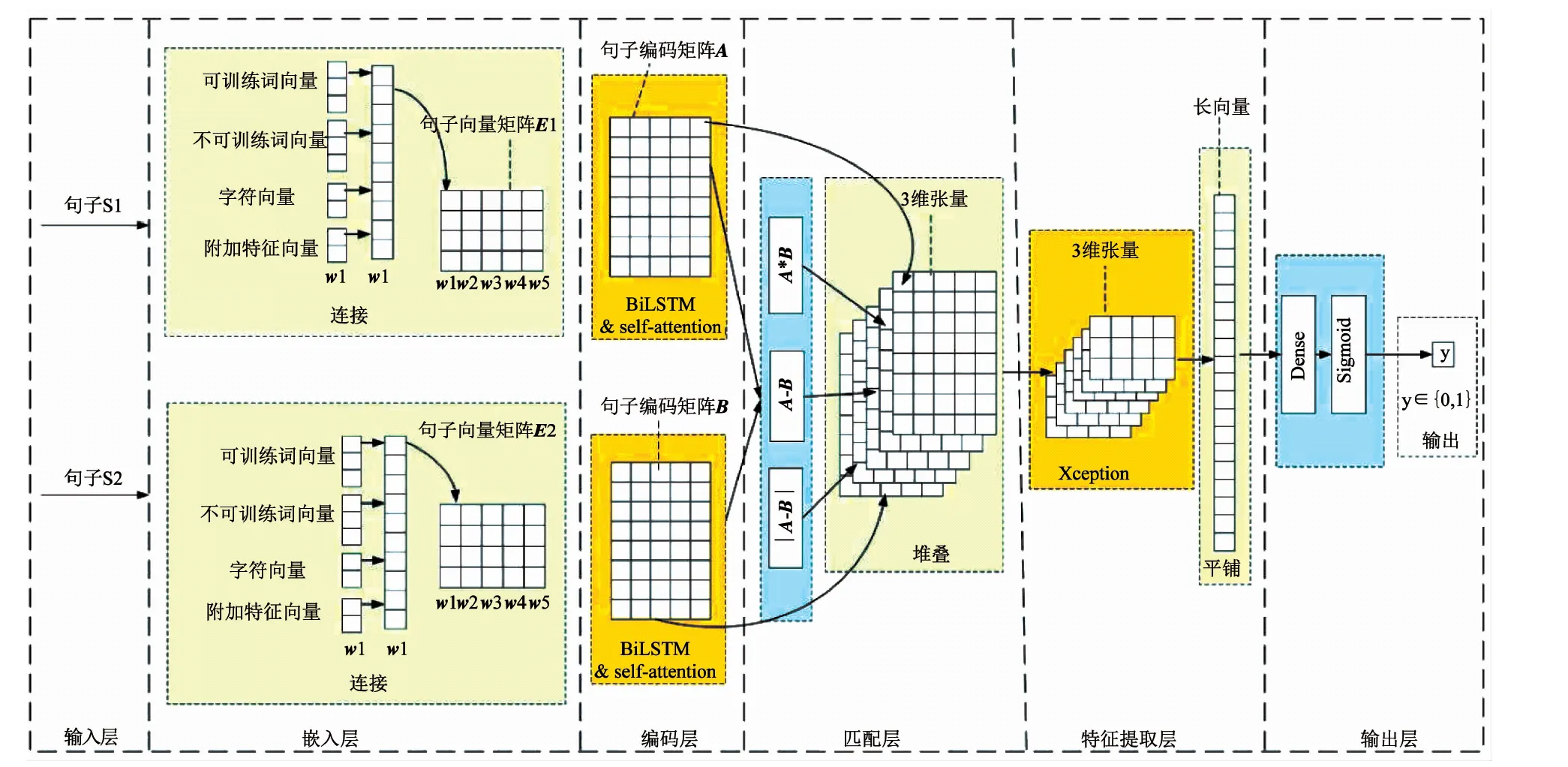
图1 面向释义识别的层次化神经网络模型
4)匹配层对编码结果进行多种矩阵运算,包括矩阵减法、矩阵相减再按位求绝对值、矩阵按位乘法,并且与编码矩阵对堆叠,生成三维张量.该层的输入是由编码层生成的编码矩阵对,输出是三维张量.
5)特征提取层用于提取匹配层输出的三维张量的语义特征.HPIN使用Xception作为编码器以便更有效地从匹配结果中提取分类信息.该层的输入是由匹配层生成的三维张量,并将Xception的输出平铺成一个长向量,作为特征提取层的输出.
6)输出层由密集层和sigmoid函数组成,用于判断句子对是否为释义对.该层的输入是特征提取层生成的长向量,输出是二进制值,1代表是释义对,0代表非释义对.
3.1 多特征融合的词向量表示
在嵌入层,每个单词被表示为一个密集分布的向量,整个句子因而被表示为词向量矩阵.使用可训练词向量、不可训练词向量、字符向量和附加特征向量的串联作为最终的词向量.
1)可训练词向量和不可训练词向量.使用840B通用语料预训练的GloVe作为词向量.可训练词向量指在训练过程中会被更新的词向量,不可训练词向量指在训练过程中不会被更新的词向量.在嵌入层,两种词向量都会被使用.
2)字符向量.使用一维卷积核过滤字符向量.单词的字符卷积特征在时间维度上最大池化获得向量.字符特征能够为一些词汇表外(Out-of-Vocabulary, OOV)的单词提供额外信息.
3)附加特征向量.通过“附加特征筛选实验及分析”选取合适的附加特征组合,从而得到附加特征向量.嵌入层使用的附加特征有Wordnet相似度和词性标注.
最终的词向量由可训练词向量、不可训练词向量、字符向量、附加特征向量连接而成,具体可表示为
E(P)=[t(P),u(P),c(P),f(P)].
(1)
式中:P为句子,E(P)为句子P的词向量矩阵,t(P)为可训练词向量,u(P)为不可训练词向量,c(P)为字符向量,f(P)为附加特征向量,[,]为连接操作.
字符向量可以包括OOV词汇,附加特征向量可以提供语义和语法特征,这些特征不被包括在预训练的词向量中.因此,模型使用以上四种向量的连接作为最终嵌入可以获得更多信息并带来更好的识别效果.
3.2 基于注意力机制的上下文双向长短期记忆网络编码器构建
编码层对句子的上下文信息进行编码,HPIN使用基于注意力机制的上下文双向长短期记忆网络作为编码器.双向长短期记忆网络包括两个方向相反的长短期记忆网络,能够学习句子的前向和逆向两个方向的上下文信息.上下文长短期记忆(Contextual Long Short-Term Memory Network, Contextual-LSTM)网络不是仅使用LSTM的最后一个单元的输出,而是使用所有单元的隐藏状态作为输出,获得LSTM上的所有单元的信息.
本文设计的ABC-BiLSTM结合了BiLSTM和Contextual-LSTM的优点,能够获取前向LSTM和逆向LSTM所有单元的隐藏状态,并且在此基础上加入注意力机制,为不同单元的隐藏状态对句子编码结果的影响提供权重信息,从而产生更好的编码性能.其工作原理如下.
对于长度为l的句子的词向量矩阵w=(w1,w2,…,wl),编码过程为:
(2)
(3)
(4)
C(w)=[h1,h2,…,hl].
(5)
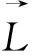
增加的注意力机制为:
(6)
(7)
A(w)=[a(h1),a(h2),…,a(hl)].
(8)
式中:wα∈R3d是可训练的参数,⊗为元素按位相乘操作,[,]为连接操作,A(w)为ABC-BiLSTM的输出,i,j∈[1,…,l].
由此可见,注意力机制的增加改变了Contextual-LSTM隐藏层节点状态hi对于编码结果中每一列影响的权重,由于注意力机制中的参数wα是可训练的参数,可通过选择合适的损失函数,训练wα,获得更好的编码结果.
3.3 基于多种矩阵运算的匹配操作
匹配层对来自编码层的句子编码矩阵对进行匹配.与以往单纯的将句子编码矩阵相乘或者相减作为匹配结果不同,HPIN对编码层输出的矩阵对进行多种矩阵计算,包括矩阵相减、矩阵相减后按位取绝对值、矩阵按位乘法,其目的是获取编码矩阵对之间的相关性,最后把句子编码矩阵对和3种匹配结果矩阵堆叠起来,形成的三维张量作为最终的匹配结果,如下
m={u,v,u-v,|u-v|,u⊗v}.
(9)
式中:u和v表示两个句子的编码结果矩阵,操作符|-|和⊗都是矩阵按位(element-wise)操作,-为矩阵减法,|-|为矩阵相减以后按位取绝对值,⊗为按位相乘,{,}为堆叠操作,即把二维张量堆叠为三维张量,m为匹配层的匹配结果.
3.4 Xception特征提取器构建
传统的“编码-匹配”模式难以从匹配结果中提取到足够的分类信息,因此本文设计了“编码-匹配-提取”架构,添加了特征提取层.在传统的“编码-匹配”模型中,由于缺少提取分类信息的结构,匹配层的匹配结果被直接输入到输出层用于分类,导致了分类准确率下降.在HPIN中,增加特征提取层,用于从匹配结果更好地提取分类信息.根据“特征提取器选择实验及分析”实验结果,最终选取Xception作为特征提取器.
Xception是Chollet于2017年提出的深度学习模型[13],最早用于图像分类.Xception是对Inception的改进,Chollet将Inception中的Inception单元替换为深度可分离卷积单元,得到了Xception.Xception是带有残差连接的深度可分离卷积单元的线性堆叠.简化的深度可分离卷积单元的结构见图2.
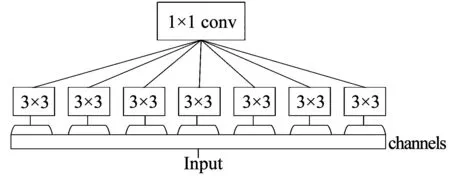
图2 深度可分离卷积单元
从图2中可以看出,输入通过多个3×3卷积核进行卷积,然后结果被连接起来,再进行1×1卷积.Xception由34个类似结构的深度可分离卷积单元组成.
在HPIN中,Xception接受来自匹配层的匹配结果(一个三维张量)作为输入,输入数据依次通过多个深度可分离卷积单元,在每个深度可分离卷积单元中,输入数据,先按照通道分组,对每个通道做一次3×3的卷积,然后再对卷积结果进行1×1的卷积.深度可分离卷积保证了得到的特征之间独立性,没有太多的相互依赖.残差连接把一些深度可分离卷积单元之间连接起来,从而避免了梯度爆炸问题.最后,整个Xception的输出被平铺成一个长向量,作为输出层的输入.
由于增加Xception作为特征提取器,利用其结构中多个深度可分离卷积单元以及残差连接,有效地提取了句子的分类信息,从而使得模型的分类准确率有了进一步提升.
4 实验设置
4.1 数据集
1)Quora问题对数据集.Quora问题对数据集来源于Quora.com,包含超过40万对真实数据.每个问题对都有二进制注释,1表示重复(释义对),0表示不重复(非释义对).
2)Twitter Paraphrase SemEval 2015数据集.最近不少释义识别研究都采用了Twitter Paraphrase SemEval 2015提供的数据集[14](以下简称PIT数据集).该数据集由带有噪音的短文本组成,共有18 762个文本对.
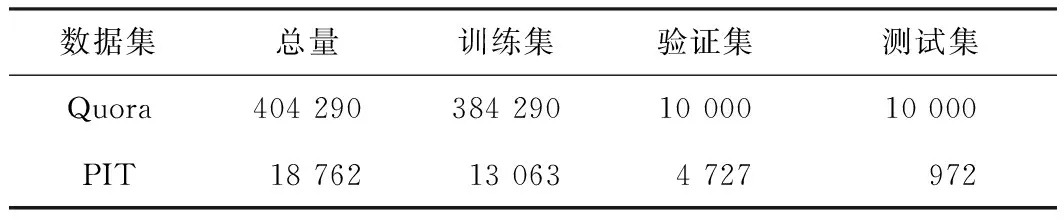
表1 数据集划分
在所有实验中,数据集划分为训练集、验证集和测试集,如表1所示.对于Quora数据集,随机抽取10 000个数据作为验证集,10 000个作为测试集,其余数据作为训练集.对于PIT数据集,使用数据集本身提供的数据划分.
4.2 评价指标
实验采用准确率和F1值作为评价指标.准确率是正确分类的释义对的百分比,F1值是精确度和召回率的组合.在使用Quora数据集的实验中使用准确率,在使用PIT数据集的实验中使用F1值,以更好地与其他人的工作进行对比(Quora数据集中更常用准确率,PIT数据集中更常用F1值).
4.3 通用设置
实验使用Keras框架实现提出的模型,使用初始学习率为0.001的RMSProp优化器优化可训练的参数.批量大小设置为128.使用300维840B语料训练的GloVe向量作为预训练词向量.设置句子标准长度为32,超出部分会被截去,不足部分用0补齐.对于所有实验,选择在验证集上表现最佳的模型,然后在测试集上对其进行评估.
5 实验结果和分析
5.1 附加特征筛选实验及分析
HPIN的嵌入层中使用了附加特征向量.本小节希望探索哪些附加组合可以更好地优化模型效果,并评估附加特征的优化效果在不同规模的数据集上的表现.
5.1.1 单附加特征筛选实验与分析
本实验目的是探讨哪些附加特征能优化模型效果.由于实验只用于评价单个附加特征对模型的影响,不作模型性能评估,所以仅使用Quora数据集.
在该实验中,将备选特征分别添加到模型中,评估该特征的加入对模型准确率的影响.将没有任何特征添加的模型视为该实验的基线.实验结果见表2,其中句子的长度、句子中单词的位置和n-gram重叠特征对提高模型准确率没有帮助,而BTM特征、词性标注和Wordnet相似度的加入提高了模型的准确率.
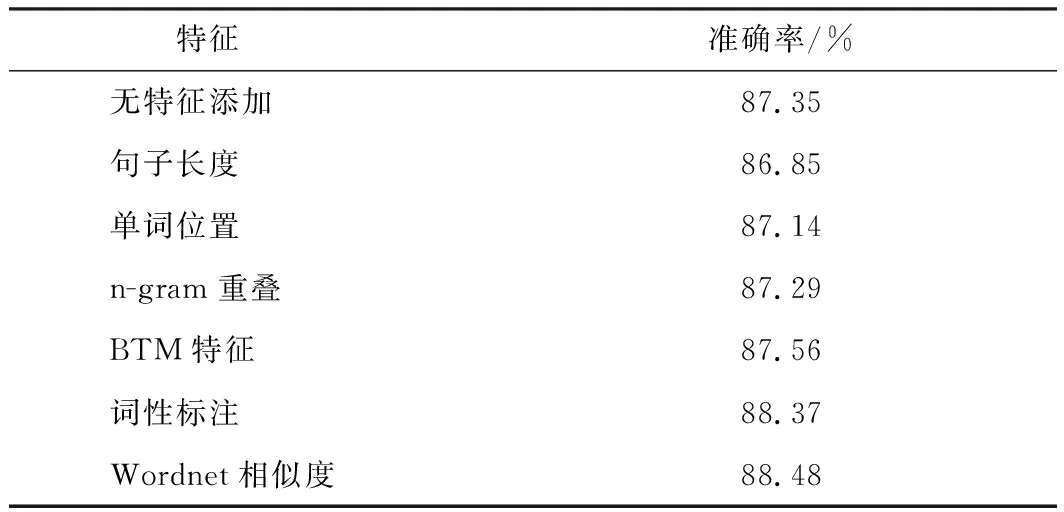
表2 单个特征对模型的影响
句子的长度、单词位置和n-gram重叠在被添加到词向量中时会产生负面效应.原因可能是这些特征包含的信息不足,而当它们被添加到词向量中时,同时也将噪声带入了词向量.
5.1.2 附加特征组合筛选实验及分析
本实验的目的是探索哪些附加组合可以更好地优化模型效果.由于实验只用于评价附加特征组合对模型的影响,不作模型性能评估,所以仅使用Quora数据集.
对“单附加特征评估实验与分析”中能优化模型效果的三个特征:BTM特征、词性标注和Wordnet相似度,进行组合并通过实验对这些组合的效果进行评估,结果如表3所示.可以发现“词性标注+Wordnet相似度”效果更好,因此模型最终选择词性标注和Wordnet相似度的组合生成附加特征向量.
由表3可知,BTM特征在单独添加到词向量中时会产生正面影响,而当它被添加到具有Wordnet相似度或词性标注的词向量中时,模型表现并不好.原因可能是BTM特征携带的信息与Wordnet相似度以及词性标注携带的信息存在重叠,当同时被加入模型中时,噪声比有价值的信息增加得更多.
5.1.3 附加特征在不同数据集上对模型优化效果评估
本组实验的目的是评估附加特征对于所提出模型HPIN的优化效果在不同规模数据集上的表现.主要记录4组结果:无附加特征添加的模型分别在Quora(大型数据集)和PIT(中小型数据集)上的准确率和有“词性标注+Wordnet相似度”作为附加特征添加的模型分别在Quora和PIT数据集上的准确率.实验结果如表4所示.

表3 附加特征组合对模型的影响
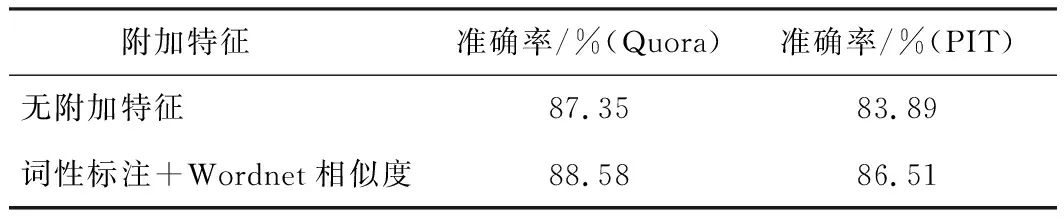
表4 附加特征对模型影响(Quora,PIT)
由表4可知,对于Quora数据集,附加特征的添加使得模型准确率提升了1.23%.而对于PIT数据集,附加特征的添加使得准确率提升了2.62%.显然,附加特征对于模型的优化效果在中小型数据集上表现得更明显.
5.2 特征提取器选择实验及分析
设计特征提取层是为了从匹配结果中更好地提取分类信息.本实验的目的是验证特征提取层的有效性以及寻找适合的特征提取器.由于该实验只评估不同特征提取器对模型准确率的影响,不作模型性能评估,所以仅使用Quora数据集.
在其他设置不变的情况下,只改变特征提取层的结构,以评估不同特征提取器对模型准确率的影响.其中,无特征提取层的模型作为实验的基线.参与对比实验的特征提取器结构有InceptionV3、DenseNet121、DenseNet169、DenseNet201、Xception、InceptionResnetV2和ResNet50.实验结果如表5所示,最佳结果在表格中用下划线标出.显然有特征提取层的模型比无特征提取层的模型准确率更高.这表明了特征提取层的设置是有效的.在各种特征提取器中,Xception和DenseNet121表现最好,达到了88.5%以上的准确率.而Xception比DenseNet121参数更少,训练得更快,所以最终选择了Xception作为模型的特征提取器.
在表5中,可以发现Xception的性能优于Inception、DenseNet和Resnet.Xception比InceptionV3更深却与InceptionV3的参数数量几乎相同,这体现了Xception能更有效地使用模型参数.Resnet50和DenseNet结构表现不佳的原因可能是当数据集较小时这些结构更容易过拟合.

表5 特征提取器效果评估
5.3 模型性能评估
本组实验对HPIN与其他释义识别模型在Quora数据集和PIT数据集(分别作为大型数据集和中小型数据集的代表)的释义识别结果进行评估对比.
5.3.1 Quora数据集上的模型性能评估
将HPIN与GenSen[15]、BiMPM[10]、SSE[17]、ESIM[11]、inferSent[18]和PWIM[20]在Quora数据集上释义识别的结果进行比较.与HPIN对比的模型数据来源于文献[10,15,21].结果如表6所示,最佳结果在表格中用下划线标出.HPIN在测试集上达到了88.58%的准确率,这比BiMPM的88.17%表现得更好.
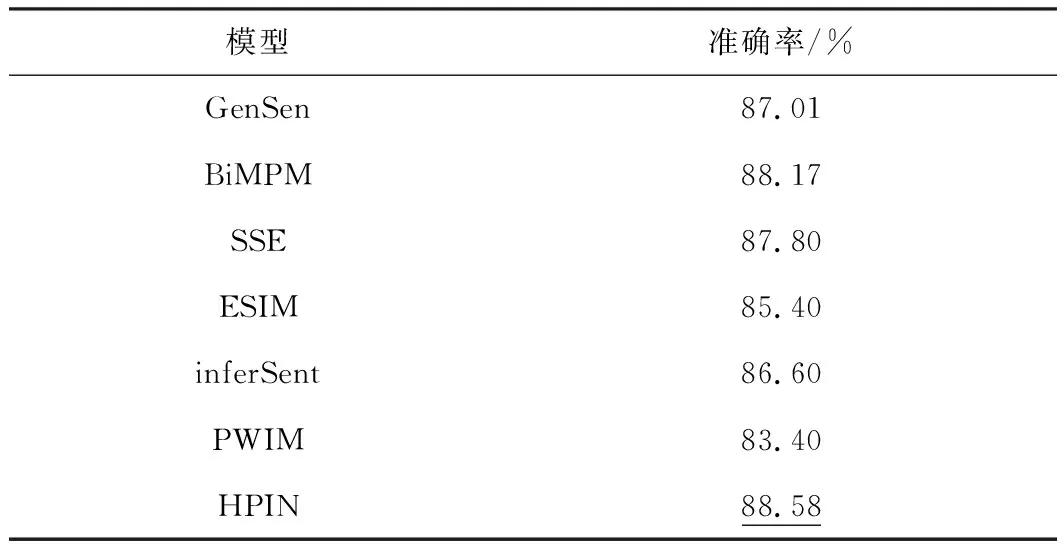
表6 Quora数据集上的模型评估
HPIN表现得比较好的原因可能有三点:首先是附加特征的使用,参与对比的其他模型没有使用附加特征,而HPIN采用多特征融合词向量,其蕴含的信息比普通的预训练词向量更加丰富;其次是增设了特征提取层,参与对比的其他模型没有特征提取步骤,HPIN使用Xception作为特征提取器,而“特征提取器选择实验及分析”表明,Xception作为特征提取器能够进一步提取分类信息,从而提升了模型识别的准确率;最后是HPIN在编码层使用了注意力机制,该机制能调节不同隐藏层状态对编码结果影响的权重,从而有助于准确率的提升,而其他几个模型没有使用注意力机制.
5.3.2 PIT数据集上的模型性能评估
将HPIN与Huang等的模型[16]、AugDeepParaphrase模型[1]、SSE[17]、ESIM[11]、inferSent[18]和PWIM[20]在PIT数据集上释义识别的结果进行比较.与HPIN对比的模型数据来源于文献[1,16,21].结果如表7所示,最佳结果在表格中用下划线标出.HPIN的F1值为0.749,仅比最佳模型AugDeepParaphrase低0.002.表明HPIN不仅在Quora这样的大型数据集上表现良好(见表6),在像PIT这样的中小型数据集上也有很好的表现.
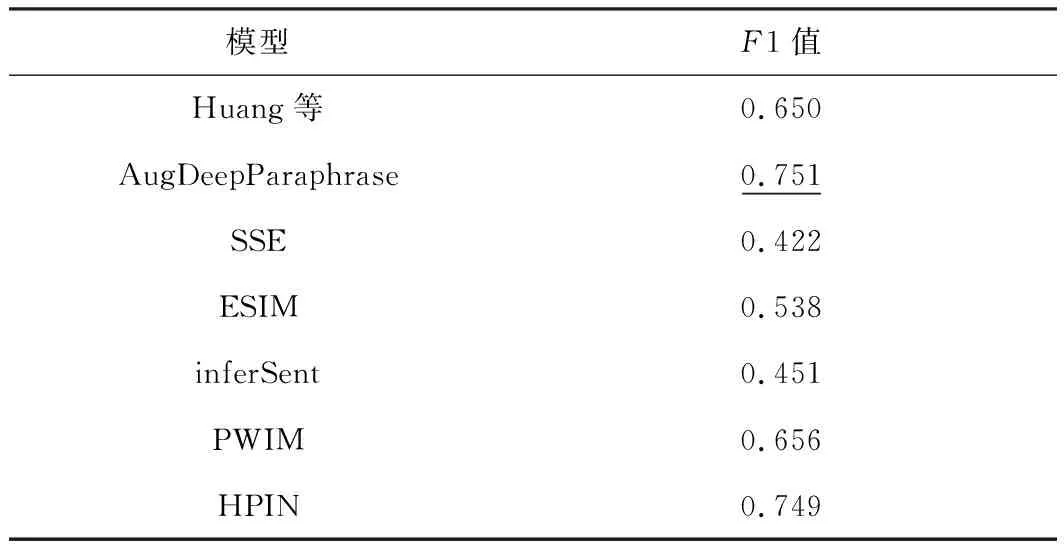
表7 PIT数据集上的模型评估
同时,分析表6和表7结果可知,模型SSE、ESIM、inferSent和PWIM在大型数据集Quora上表现良好(准确率与最优模型差距不大),但在中小型数据集PIT上则表现较差(表现远远差于最优模型),表明了这些模型对数据集大小较敏感;而HPIN在大型数据集Quora和中小型数据集PIT上都取得了良好的效果,表明HPIN具有一定程度的泛用性.其原因一是模型采用了多特征融合的词向量,特别是当数据集较小时,附加特征的贡献尤为明显(结论来自“附加特征在不同数据集上对模型优化效果评估”);另一个原因则是增设了特征提取层,充分提取了匹配结果中的分类信息,无论在大型数据集上还是在中小型数据集上都具有良好效果.
6 结 论
本文构建了一种新的释义识别模型HPIN.与大多数现有的释义识别模型采用的“编码-匹配”模式不同,采用“编码-匹配-提取”模式,增设了特征提取层,从匹配结果中提取更深层的分类信息.HPIN是一个分层模型,由6层组成:输入层、嵌入层、编码层、匹配层、特征提取层、输出层.嵌入层使用可训练的词向量、不可训练的词向量、字符向量和附加特征向量的连接,作为最终的词向量,较普通的预训练词向量携带更丰富的信息;编码层中采取基于注意力机制的上下文双向BiLSTM作为编码器,获取前向和逆向两个LSTM中所有隐藏层中的信息,有效地对词向量矩阵的上下文进行编码;在匹配层中,运用多种矩阵运算,从不同角度获取句子对的匹配信息;在特征提取层中,使用Xception结构,更有效地提取分类信息.本文在Quora(作为大型数据集代表)和PIT两个公开数据集上(作为中小型数据集的代表)评估该模型,均达到了竞争性的效果,从而表明所提出的HPIN模型不仅能有效提高释义识别的准确率,而且在不同规模的数据集上(Quora和PIT)都表现良好,因此也具有一定程度的泛用性.
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
电子制作(2019年22期)2020-01-14 03:16:24
数学物理学报(2019年6期)2020-01-13 06:08:16
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
电子制作(2018年19期)2018-11-14 02:37:08
数学物理学报(2017年5期)2017-11-23 07:51:31
自动化学报(2017年11期)2017-04-04 02:52:58
噪声与振动控制(2015年4期)2015-01-01 07:08:21
