
基于知识库和HSMM模型的云日志分析方法
2020-09-26 11:43张峥峰何成万张进
电脑知识与技术 2020年24期
关键词:知识库
张峥峰 何成万 张进

摘要:为了分析云基础环境下各个组件产生的日志数据,本文提出了一个基于知识库和HSMM(隐半马尔科夫模型)的云日志分析方法。首先,日志分析系统整合了Flume, Kafka, Spark Streaming;然后,消费模块实时获取云日志,云日志经过一系列处理后形成时间事件序列用于故障预测,正确的预测结果将通过接口写入知识库。此外,获取的云日志会写入elasticsearch中用于日志检索;最后,通过实验对系统的实用性指标进行了评估。该云日志分析系统可以聚集多源日志,方便日志检索,提高预测的准确度。
关键词:Spark Streaming;云日志;TF-IDF;知识库;OpenStack
中图分类号:TP311.5 文獻标识码:A
文章编号:1009-3044(2020)24-0007-04
Abstract: In order to analyze the log data generated by various components in the cloud-based environment, this paper proposes a cloud log analysis method based on the knowledge base and HSMM (Hidden Semi-Markov Model). First, the log analysis system integrates Flume, Kafka, and Spark Streaming; then, the consumer module obtains the cloud logs in real-time, and the time event sequence formed by the cloud logs after a series of processing is used for fault prediction. The correct prediction results will be written into the knowledge through the interface. Library. Also, the obtained cloud logs will be written into an elastic search for log retrieval; finally, the usage practices of the system was evaluated through experiments. The cloud log analysis system can aggregate multi-source logs, facilitate log retrieval, and improve the accuracy of prediction.
Key words: Spark Streaming; cloud log; TF-IDF; database of knowledge; OpenStack
1引言
伴随着云时代的到来,以OpenStack[1]搭建的云基础平台(IASS)越来越受到人们的重视。OpenStack搭建的云基础平台包含了仪表盘组件Horizon,计算组件nova,网络组件neutron,对象存储组件swift,块存储组件cinder,镜像组件glance,身份认证组件keystone,计费组件ceilometer,编排组件heat。云日志具有多源性特点:组件的独立性,即使是单机部署的OpenStack,不同组件运行后形成的日志文件也在不同的文件夹下面;业界熟知的阿里云,亚马逊云等都是一个分布式集群,集群中包含了控制节点,计算节点,网络节点和数据节点等,节点部署在集群的不同主机上,节点的分散性决定了日志多源性。
文献[2]提到了日志对于系统的运行维护和故障诊断都具有很大的帮助。直接阅读多源日志需要手动来回切换日志存储目录,不方便查询。故障预测作为故障检测的一种手段,让运维人员能够尽可能及早发现故障。日志的多源性会增加数据种类的多样性,增加系统监听负担,给故障预测的准确率和实时性都提出了挑战。
本文提出了一个基于知识库和HSMM模型的云日志分析方法。该方法具有集中分散多源日志、方便查询日志、能够在不修改源日志结构的前提下进行故障预测和提供解决方案等特点。
2相关工作
关于云环境下的日志分析,很多学者对此展开了深入的研究。Shetty[3]等人提出了一种基于机器学习和控制理论模型的数据挖掘技术,可以自适应地调整检测阈值,通过实时分析云日志来发现云环境中的异常事件,这是一种事后诊断的方法。Wang等人[4]设计并实现了一个云数据中心审计系统 CDCAS(Cloud Data Center Auditing System),用一个分布式自治代理模型来收集各种多源异构日志,基于特征的方法和相关性分析算法比较审计日志和预配置或预定义的事件模式,从而发现非法行为。由于是在非法行为已经发生了的情况下通过日志分析来发现系统异常的方法,是一种事后处理的方法。张之宣等[5]提出了一个基于HSMM模型的异常预测方法,能够对系统故障进行预测,但是预测的准确率不高,并且故障预测的结果是基于二分类的分类方法,其最终预测结果只有异常或者正常两类,所以异常的具体内容是无法得知的。王智远[2]等人提出了一种日志异常的检测方法,首先基于编辑距离进行日志聚类形成模板,然后对模板进行TF-IDF分词处理形成数值型特征向量,然后使用贝叶斯,逻辑回归等弱分类器构建得分特征向量,最后利用得分特征向量和随机森林得到强分类器用于异常检测。实验证明了该方法具有很好的分类效果。由于是基于事件已经发生后进行的分类处理,所以还是一种事后处理办法。
本文提出的是基于知识库和HSMM预测方法,简称KDB+HSMM(Knowledge DataBase+HSMM)。随着时间推移,知识库内容的丰富完善,相对原有的HSMM[5]预测方法而言,能够提高一点预测的准确度,得知异常发生的具体内容。
3系统设计与实现
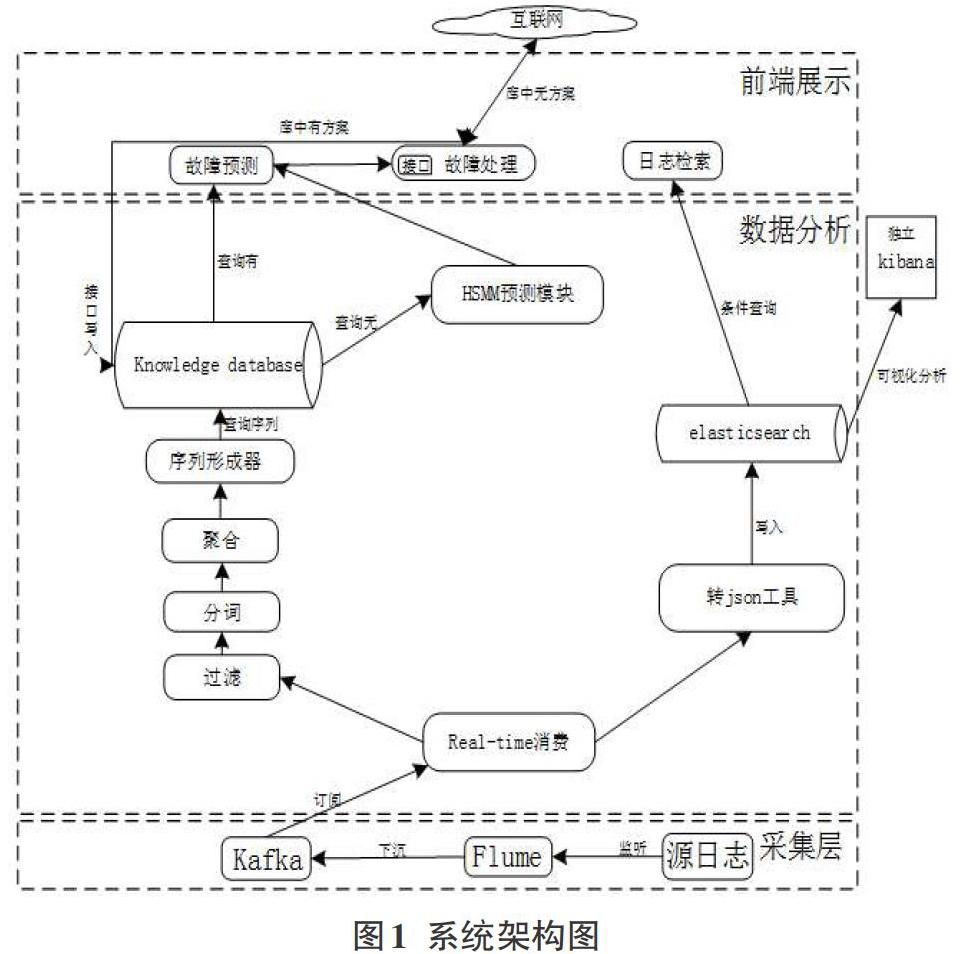
整个实时系统主要分为三大部分,数据采集部分,数据分析部分,数据前端展示部分,系统的整体架构如图1所示。
3.1数据采集
Flume是一个采集工具,主要功能是可以把各种数据源通过管道把数据下沉到目的地。通过配置数据来源和数据下沉的目的地,可以完成数据从产生的地方迁移到目的地。通过配置监听0penStack各个组件日志文件,从而将分散的多源日志集中收集起来,便于统一进行处理。
Kafka是基于消息發布订阅系统,由producer,broker,consumer构成,生产者向broker某个主题发布消息,消费者订阅该主题,可以从该主题上拉取数据。作为大数据处理的中间件,起数据处理缓冲作用。Kafka作为Flume和Spark Streaming之间桥梁,Flume下沉数据到Kafka主题上,Spark Streaming订阅主题实时消费数据。
Spark Streaming是伪实时处理框架,通过Spark Streaming提供编程模型,设置多少时间为一个批次,由于时间很短,近似看作是实时处理。Streamingcontext是Spark Streaming的程序入口。
valsparkConf = new SparkConf()
.setAppName(“cloudLogAnalysis”).setMaster[“local[*]”];
//配置[?t],作为数据的一个批次。
valssc = new StreamingContext(sparkConf,Seconds([?t]));
3.2 数据分析
3.2.1 故障预测
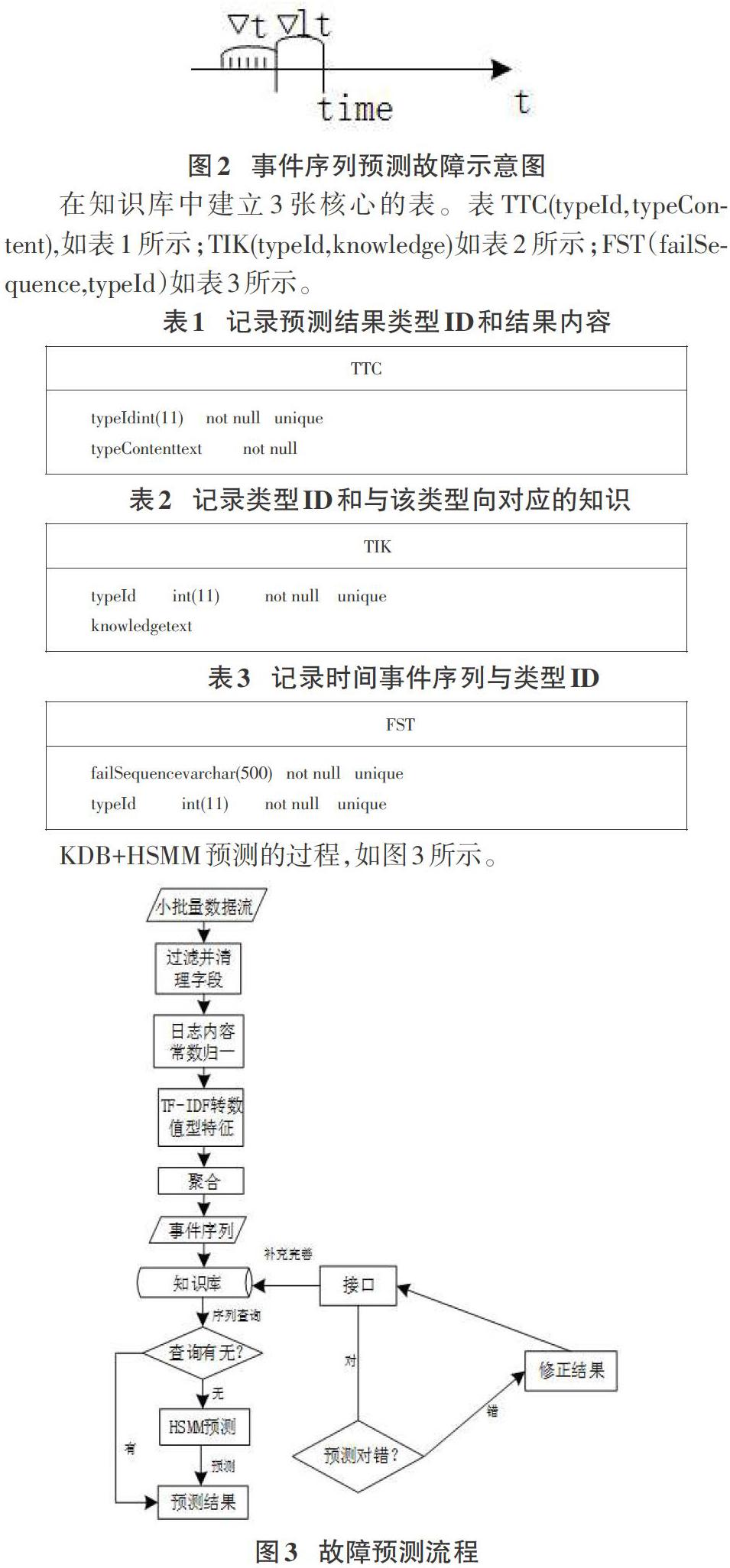
故障预测模块实现是基于知识库和HSMM预测方法。假设故障出现的时间点time,手动配置[?t],预测前置时间[?lt],在(time-[?lt-?t])到(time-[?lt])组成事件序列用来预测发生的time点的故障,如图2所示。
在知识库中建立3张核心的表。表TTC(typeId,typeContent),如表1所示;TIK(typeId,knowledge)如表2所示;FST(failSequence,typeId)如表3所示。
KDB+HSMM预测的过程,如图3所示。
1) OpenStack日志格式统一为<时间戳><日志等级><代码模块>
2)对日志内容进行常数归一处理,降低矩阵维度和减少无意义特征,提高效率和模型精确度。例如nova-compute.log中一条错误日志内容AMQP server on 192.168.143.128:5672 is unreachable: Too many heartbeats missed. Trying again in 1 seconds. Client port: None: ConnectionForced: Too many heartbeats missed,替换常数后形成的日志内容为AMQP server on * is unreachable: Too many heartbeats missed. Trying again in *seconds. Client port: None: ConnectionForced: Too many heartbeats missed,不同的常数增加了维度,统一用*号去代替,降低维度。
3)将经过2)常数归一处理后的文本信息转为数值型特征。本文采用是TF-IDF,对日志常数归一后的内容进行分词。TF-IDF[7](term frequency–inverse document frequency)是一种常见的文本挖掘技术。TF意思是词频(Term Frequency),表示词语在文档中出现的词频,IDF意思是逆文本频率指数(Inverse Document Frequency),是衡量词重要性指标。
4)经过3)分词后形成数值型特征进行分组聚类处理。日志中记录了很多相似的错误事件,可以进行聚类处理。日志文本信息丰富,形成的数值型特征矩阵维度高,聚类计算量大。而K-means聚类算法能够并行化处理,聚类速度快,spark机器学习库里面集成了该算法,方便进行内存迭代调优。K-means算法[8]初始化中心K是人为选取的,最优K值是当走HSMM模型预测路线的预测准确率收敛于某一个值。对事件聚类的过程如图4所示。
经过聚类处理后,可以知道每个事件到底属于哪一个类,然后根据每个事件所标记的时间,就可以展示出时间事件序列。用上图4中的a,b,c三个类进行举例子,假设标记的时间先后顺序为[m1,m2,m3,m5,m9,mk],那么经过聚类后所展示[m1,m2,m3,m5,m9,mk]时间事件序列如图5所示。
5)基于4)聚类的数据结合标记时间,形成时间事件序列。
6)故障预测。故障预测的本质是实时获取的事件序列是否包含有故障有关的序列,5)形成的时间事件序列作为预测的输入数据。知识库预测原理为FST中进行匹配查询(%failSequence%=R),如果查询有,会通过typeId关联到typeContent,返回预测结果的具体内容。HSMM预测原理为系统的一种类型的状态[si]对应一个 HSMM分类模型[λi],将实时获取的时间事件序列O代入[p(o/λi)],由计算概率最大的[λi]得到系统状态[si]。其预测示意图如图6所示。
3.2.2 知识库完善
如果组件运行出现了问题,首先是根据typeId从知识库表TIK里面去寻找对应的解决方案knowledge,如果到知识库库里面找不到解决方案,维护人员也不知道如何解决的情况下,点击故障解决模块中的网上搜寻按钮。系统会获取异常日志errorLogs,调用自动化测试工具selenium[9],将errorLogs作为关键词在网上检索解决方案,相对人为手动复制粘贴errorLogs到网上检索而言,方便快捷。当到网上顺利找到了对应的解决方案knowledge,维护人员将knowledge通过接口添加到TIK中,完善知识库,其过程如图7所示。
不同的浏览器选择不同的selenium驱动,搜索网站的网址,网站的搜索框Xpath,搜索按钮的Xpath(浏览器审查元素,然后复制元素Xpath获取),写入到配置文件中,让程序读取,如图7所示。维护人员没有配置的话,遵守约定优于配置的原则,默认是从百度上搜索解决方案。其实现的核心代码如下:
System.setProperty(浏览器selenium驱动地址);
WebDriver driver=new 浏览器驱动
driver.get(搜索网站网址);
WebElement input =driver.findElement(By.xpath(搜索框Xpath));
input.sendKeys(errorLogs);
WebElement button = driver.findElement(By.xpath(搜索按钮Xpath));
button.click();
3.2.3云日志检索
云日志很明显的一个特点是数据量大,如果用传统的关系型数据库存储可能存在查询响应慢和存储空间不足等问题。本系统采用的是elasticsearch[6]进行日志的存储,可以实现日志的快速检索功能。另外,如果还有其他需求的话,可以下载kibana(kibana版本号和elasticsearch的版本号要一致),配置kibana.yml中的elasticsearch url,可以对存储在elasticsearch中的日志进行可视化分析。Kibana和本文提到的分析系统是相互独立的,辅助分析云日志。
4实验结果及其比较
单机部署的OpenStack云基础环境,通过创建和删除云实例操作,循环反复50次后所产生的日志数据源进行实验。
用准确率(Precision),召回率(Recall),F-measure来衡量故障预测的结果。
张之宣提出的HSMM[5]和本文中KDB+HSMM就预测结果(知识库预测结果趋于稳定后)进行比较,结果如表4所示。
5 结语
通过整合Flume,Kafka,Spark Streaming大数据分析组件,搭建了一个实时云日志分析系统,可以集中多源日志,进行日志检索和异常预测,提供一套异常解决方案。日志检索模块,基于elasticsearch引擎实现,可以水平扩展,提升存储能力。异常预测模块是基于KDB+HSMM,较单独HSMM[6]而言,能够提高一点预测的准确度,显示即将发生异常的具体内容。不过,从实验结果中可以看出异常预测的准确度还是很低,另外HSMM预测路线的知识库丰富需要靠人工操作接口去补充,灵活性存在明显的不足,还需要进一步研究,提高预测的准确度和知识库丰富的灵活性。
参考文献:
[1] 王志健.基于Openstack平台的入侵检测系统的设计与开发[D].苏州:苏州大学,2017.
[2] 王智远,任崇广,陈榕,等.基于日志模板的异常检测技术[J].智能计算机与应用,2018,8(5):17-20,24.
[3] Shetty S . Auditing and Analysis of Network Traffic in Cloud Environment[C]// IEEE Ninth Word Congress Services. IEEE, 2013:235-258.
[4] Wang X Y,Zhang J,Wang M B,et al.CDCAS:a novel cloud data center security auditing system[C]//2014 IEEE International Conference on Services Computing. 27 June-2 July 2014, Anchorage, AK, USA. IEEE, 2014:605-612.
[5] 张之宣.云计算环境下实时日志分析系统的设计与实现[D].杭州:浙江大学,2016.
[6] 梁文楷.基于Elasticsearch全文检索系统的实现[J].电脑编程技巧与维护,2019(6):116-119.
[7] 叶雪梅,毛雪岷,夏锦春,等.文本分类TF-IDF算法的改进研究[J].计算机工程与应用,2019,55(2):104-109,161.
[8] 俞皓芳,孙力帆,付主木.基于改进K-means++聚类的多扩展目标跟踪算法[J].计算机应用,2020,40(1):271-277.
[9] 姜文,刘立康.基于Selenium的Web軟件自动化测试[J].计算机技术与发展,2018,28(9):47-52,58.
【通联编辑:唐一东】
猜你喜欢
北京大学学报(自然科学版)(2022年1期)2022-02-21
制造技术与机床(2019年6期)2019-06-25
图书馆建设(2018年8期)2018-08-31
西南石油大学学报(自然科学版)(2018年4期)2018-08-02
中国交通信息化(2016年9期)2016-06-06
图书馆研究(2015年5期)2015-12-07
图书馆研究(2015年5期)2015-12-07
海军航空大学学报(2015年1期)2015-11-11
中央民族大学学报(自然科学版)(2014年3期)2014-06-09
图书馆建设(2010年12期)2010-05-12
