
SSD神经网络的人脸检测方法
2020-09-24 07:22:02赵艳芹陈真朋
黑龙江科技大学学报 2020年4期
赵艳芹, 陈真朋
(黑龙江科技大学 计算机与信息工程学院, 哈尔滨 150022)
0 引 言
现今,5G技术和人工智能飞速发展,各种智能化终端产品进入大众视野,并逐步取代人工方式。人脸的智能识别作为其中重要一环也被广泛使用在诸如监控系统、智慧交通、活体检测等各领域[1]。人脸检测作为面部识别的重要组成部分,其检测性能的好坏直接影响识别的结果。因此,提高人脸检测算法的精度对人脸识别具有十分重要的意义。
传统的人脸检测方法是从数据集中手工提取特征,再将提取到的特征送入人脸分类器进行训练。目前,最经典的传统人脸检测方法主要有两种:基于Adaboost的人脸检测方法和基于DPM的人脸检测方法。基于Adaboost的VJ算法是由Viola等[2]提出,该算法由Haar特征表示人脸,利用Adaboost算法训练人脸分类器,最后通过滑动窗口提取人脸区域。M.Mathias等[3]提出了一种可以检测多角度人脸的改进DPM算法,通过提取人脸不同方向的HOG特征构造人脸检测模型,该算法发现了非极大值抑制的重要性有效提高了人脸检测精度。虽然传统人脸检测方法在一定程度能解决检测问题,但是在复杂的环境和图片质量参差不齐的情况下,检测程度仍然受限。
随着深度学习技术和硬件的不断发展,利用卷积神经网络[4]可以解决检测问题。Yin Sun等[5]提出了基于神经网络的CNN Facial Point Detection算法,该算法主要是实现面部关键点的检测,运行速度快、执行效率高并且可以检测侧脸。目前,基于深度学习的主流人脸检测方法主要有R-CNN系列检测算法包括R-CNN[6]、Fast-RCNN[7]、Faster-RCNN[8]算法和基于直接回归的YOLO[9]、SSD[10]系列算法。R-CNN系列检测算法将检测过程分为产生候选区、候选区分类这两个阶段进行,增大了时间开销。而SSD检测算法采用端到端的方式直接回归目标位置,相对于YOLO系列算法,SSD可以在不同大小的特征图上同时进行目标的检测。因此,笔者将传统的SSD目标检测算法用在人脸检测中并改进主干网络结构,以此来提高对低分辨率的小目标检测精度。
1 SSD卷积神经网络
1.1 SSD网络模型构造
SSD网络模型作为一种目标检测领域广泛使用的网络结构,其原始SSD网络结构如图1所示。
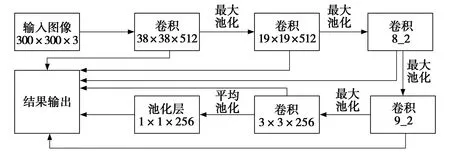
图1 SSD网络模型结构Fig. 1 SSD net model structure
典型的SSD网络模型属于全卷积神经网络的一种,由11个block组成,输入图像尺寸为300×300,使用VGG16[11]作为主干网络,改变了第五分块的第四层卷积,去掉全连接层,Conv8_2以后的卷积层是在VGG16后增加的。SSD网络分别在不同的特征图上同时提取特征,并且在提取特征图上设置不同的滑动窗口来检测相应的目标。根据SSD网络结构能看到,SSD使用了6个不同尺度的特征图检测不同尺度目标,大尺度特征图来预测小目标,小尺度的特征图来预测较大目标。
1.2 SSD网络损失函数
SSD网络模型在其每个检测层后分两路3×3卷积核分别用来做目标的分类和回归,其中一个输出每个检测框的位置(x,y,w,h)四个值,另一个卷积层用来输出每个检测框检测到不同类别目标的概率,输出个数就是预测的类别个数。分别计算所有检测框位置和类别与目标的真实位置类别误差,组成向量,构造成总损失函数。因此,总的损失函数就是分类和回归误差的加权和。
SSD总的损失函数为
(1)
式中:N——匹配到检测框的数量;
i——检测框序号;
j——真实框的序号;
i∈s——从匹配到的正样本中取到的检测框序号;
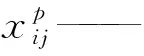
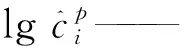
i∈e——从负样本中取检测框序号;

α——分类误差和回归误差对总损失函数的权重,通常设为1;
xp、yp、w、h——匹配到的检测框为类别p时的中心位置坐标及检测框的宽、高;

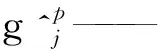
SL——soomthL1函数,当自变量绝对值小于1时,SoomthL1函数取值为自变量的二次平方值;当自变量绝对值为其他值时,soomthL1函数取值为自变量和定值0.5的差值。
第一个累加表示检测框i与真实框j关于类别p匹配,如果p的概率越高,则损失越小,第二个累加表示检测框中没有物体,预测为背景的概率越高,损失越小。使用softmax计算概率,通过最大化累加和达到最小化置信度损失函数的目的。
1.3 SSD网络特点
从SSD 的网络模型结构可以看出其有三个特点:一是SSD由主干网络和金字塔网络构成,主干网络为VGG16的前四层网络,金字塔网络是特征图逐渐变小的简单网络,SSD网络将尺度大小不同的特征图直接作用到预测层进行结果预测。可以更准确的预测不同大小的目标;二是SSD网络属于端到端的训练方式,依靠目标标注直接在图像上生成正负样本并采用hard negative mining技术控制正负样本数量进行训练,大大提高了训练速度;三是SSD网络在低层预测小目标,而最低的预测层只有VGG16中38×38卷积层。因此,对小目标的检测效果不强。
2 SSD网络模型的人脸检测
2.1 检测过程
文中的人脸检测与传统的目标检测流程一样,比传统的分类任务多出一个分支用于进行目标位置的判断。根据训练集人脸的标注,直接在训练集特征图上生成大小比例不同的default box目标框进行人脸定位回归,最优化损失函数,训练出人脸检测模型,随后使用训练后的检测模型直接进行人脸检测。检测过程如图2所示。
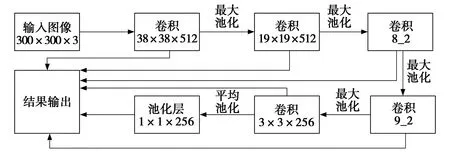
图2 SSD网络的人脸检测流程Fig. 2 Flow of face detection based on SSD net
2.2 人脸图像预处理
人脸图像由于人种、肤色、光照、尺度等因素影响,对训练和检测结果都具有影响。采用人脸图像数据集是WIDERFACE人脸数据集,总共有32 203张标注图像,标注信息为人脸数目和真实检测框坐标。数据集中人的姿势、种族、遮挡具有高度可变性。
数据集中图像在训练前要进行标准化处理,标准化是将像素去均值实现中心化的处理,标准化符合数据分布规律,更容易取得训练之后的泛化效果。图像在采集传输过程中受设备和环境影响,会产生噪声,预处理中需要将图像中的噪声予以去除,减少对训练检测结果的影响。图像尺寸不一,需要统一resize到300×300,为保证图像人脸不会发生扭曲变形影响实验结果,需要进行同比例放缩,空白部分进行填充。图3a为数据集原始图像,图3b是经过预处理之后得到的图像。

图3 人脸图像预处理结果对比Fig. 3 Comparison of face image preprocessing results
2.3 SSD 人脸检测模型
利用SSD网络进行人脸图像的训练与检测需要对网络结构进行优化和改进,SSD的改进主要有两方面:一是原始的SSD的主干网络由VGG16的前五层卷积堆叠而成,使用传统的3×3的卷积核进行特征的提取。参数量大耗时长,本文对比试验几种主流的基础网络,最终选定mobilenet_v3[12]作为SSD的主干网络,该基础网络使用3×3的深度卷积和1×1的普通卷积构成深度可分离卷积减少计算量和全新的激活函数保证损失函数收敛。将原来最底层在38×38的特征图上进行检测向下转移到128×128作为检测的最底层特征图,提高对小目标的检测能力。二是Anchor框比例优化。在处理人脸任务时,为了挖掘人脸框之间的相关性,文中不再将检测框的比例直接设置为1∶1,而是对数据集中的真实人脸框进行K均值聚类,具体聚类过程如下:
步骤1随机抽取2 000张图像,将其中真实框的宽度和高度标注取出,将高度和宽度进行归一化,统一尺度。
步骤2从数据空间中随机选取六个对象作为初始聚类中心。
步骤3对于样本中的其他数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心所对应的类。
步骤4将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值。
步骤5判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回步骤3。
重复上述实验步骤5次,对所有结果取均值。得到检测框长宽比最终结果为:1∶1、1∶1.6、1∶2、1∶2.5、1∶3、2∶1六种,使用以上六种不同比例的default box 去大小不同的特征图中对真实框进行训练检测。
3 实 验
实验在win10 64位操作系统下进行,CPU型号为i5-8400,主频为2.81 GHz,GPU型号为NVIDIA GeForce GTX 1060,内存大小为16 G,使用python语言在Pycharm平台上编程实验,深度学习框架为caffe。
实验所用的训练集为WIDERFACE训练集,用WIDERFACE测试集和FDDB数据集作为文中实验测试集。测试文中所提模型在其他数据集的鲁棒性情况。
3.1 步骤
SSD网络主要用于处理多目标多类别检测任务,在人脸检测中,因其只需要检测一种类别,所以只需要处理该检测目标是人脸或是背景。实验步骤如下:
步骤1从WIDERFACE训练集中顺序抽取2 000张图像,进行预处理,将数据集转换格式后送入网络模型。
步骤2根据本机配置,设置batch_size为5,2 000张图像完成一轮epoch需要迭代400次,学习率初始值设置为0.01,学习衰减率设置为0.97。使用小批量梯度下降法更新损失函数。
步骤3每400次迭代,将学习率、损失函数、训练时间输出,观察损失函数是否收敛。
步骤4重复上述步骤,将数据集图像epoch 100次。将训练好的模型,在WIDERFACE测试集和FDDB数据集上进行测试。
3.2 结果对比
实验训练一轮时间为38 h,为进一步测试实验模型的性能,对目前主流的人脸检测算法MTCNN、Faster-RCNN、YOLOv3在相同的实验环境下,对比实验结果。
准确率只针对样本中所有分对的样本,一般用来评估网络模型全局准确的程度,不包含其他信息,不能全面评价一个模型性能。实验使用平均精确度和检测速度来综合衡量网络模型的好坏。准确率ε计算公式为
(2)
式中:nTP——将人脸正确检测成人脸的样本数;
nTN——将背景检测为背景的样本数;
nFP——将背景误检成人脸的样本数;
nFN——将人脸误检为背景的漏报数。
精确度表示的是被分成正例中实际为正例的比例
(3)
对验证数据集中的每张图片的精确度进行平均得到平均精度
(4)
式中,N——总样本数。
将目前主流的三种人脸检测算法分别在WIDERFACE数据集的验证集中三种难度下进行对比实验,分别计算简单验证集的平均精度(φe)、中等验证集的平均精度(φm)、困难验证集的平均精度(φh)。实验结果如表1所示。
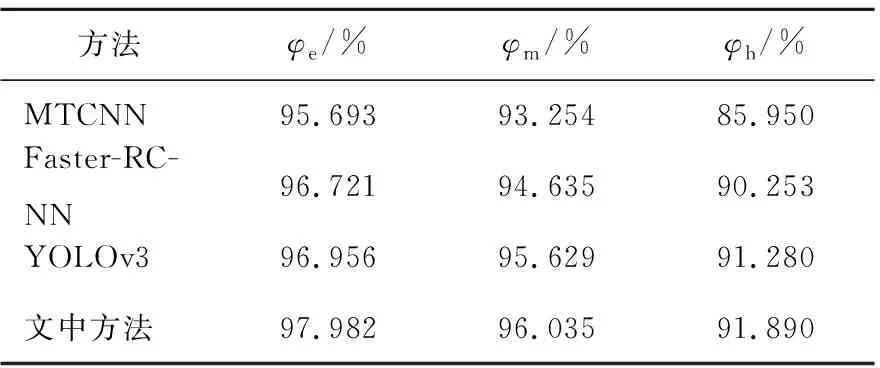
表1 各方法人脸检测精度结果对比Table 1 Comparison table of face detection accuracy results of each method
通过对比实验可以看出,文中方法在验证集三个难度上的精度均高于主流方法,在困难验证子集上的平均精度提高到了91.890%。实验结果表明,文中方法在人脸检测精度要高于目前主流的方法。
人脸检测模型不仅需要关注精确度指标,还需要关注速度指标以满足实时性的要求,现在目标检测模型日益朝着轻量化方向改进,为了验证文中实验模型在检测速度方面是否满足实时性的要求,将模型每秒检测图片的张数(FPS)作为速度评价指标,分别计算了在CPU下检测张数(εC)和GPU下的检测张数(εG)。与上述模型进行实验对比,实验结果如表2所示。

表2 各方法人脸检测速度结果对比Table 2 Comparison table of face detection accuracy results of each method
实验在同一硬件条件下进行,在WIDERFACE测试集上取相同的1 000张图片,分别在上述算法中进行检测,计算各方法每秒的平均帧数。结果表明,文中方法在CPU下能够满足实时性的要求,在GPU下能达到每秒62张的速度。相比于其他方法能够更快速的完成检测图片任务。综合精度和速度指标,全面的评估了实验方法的性能。文中方法均优于目前主流的方法,证明了对SSD网络的改进具有有效性。
将SSD网络的基础网络换成了mobilenet_v3,为了验证改进后的网络与原始网络及其他主干网络的差异,文中置换不同的主干网络进行实验,在同等实验条件下,比较不同主干网络的精度和检测速度,结果如表3所示。
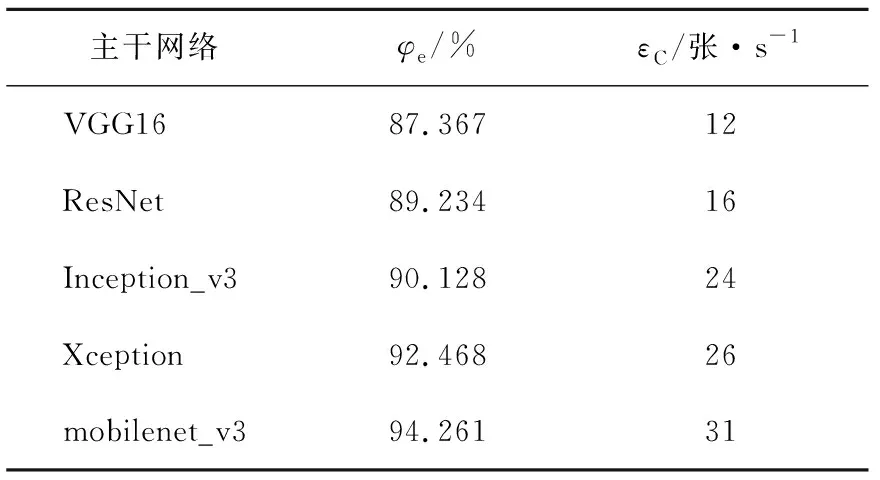
表3 各主干网络人脸检测性能对比Table 3 Comparison table of face detection accuracy results of each method
实验在WIDERFACE验证集中进行,取三种难度的平均精度和相同时间的平均FPS结果,通过对比不同的主干网络,可以发现相比使用原始主干网络,替换成另外四种基础网络均对模型性能有不同大小的提升,其中替换成mobilenet_v3网络较原始的VGG16在验证集上的平均精度提升约7%,在CPU上每秒检测图片数量增加了19张。因此,mobilenet_v3对SSD网络的平均精度和检测速度均比其他基础网络提升幅度大。
使用各种不同的人脸检测模型,对WIDERFACE验证集中图像进行检测,检测结果如图4所示。分别对四种模型进行相同轮数的训练后进行检测,由图4可以看出,MTCNN和Faster-RCNN对人脸检测框有明显偏移,且检测不到目标较小的人脸和被遮挡的人脸,YOLOv3与文中方法能够检测到小目标人脸,但YOLOv3对背景存在一定误检,将多个背景误检为人脸。综合对比,文中方法相比其他主流算法更能完成复杂环境下的人脸检测任务。

图4 不同模型检测结果对比Fig. 4 Comparison detection results of different models
交并比IOU比例是衡量模型检测好坏的重要指标之一,其值在0~1之间,计算方法检测框和真实框交集与其它们并集的比值。IOU计算的是“预测的边框”和“真实的边框”的交集和并集的比值。通过对比多个检测模型在相同数据集上的平均IOU比例,就可以评估检测效果。实验结果如表4所示。
文中将五种检测模型在WIDERFACEE验证集进行IOU计算,将IOU>0.5视为正检,将IOU对验证集取均值,由表4可以看出,文中方法的平均IOU要优于其他几种检测方法,还将文中方法跟检测框比例直接设置成1∶1的传统SSD方法做对比实验,平均IOU提升了25.3%,证明了根据真实人脸框聚类几种不同大小的检测框更能精准的完成检测框定位。
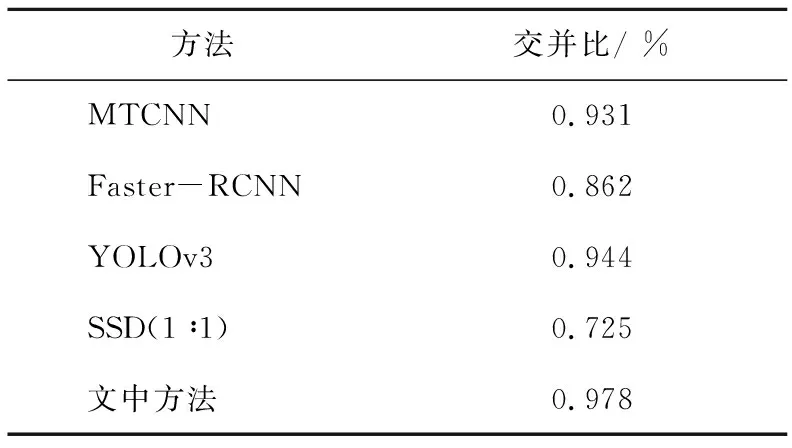
表4 各主干网络人脸检测性能对比Table 4 Comparison of face detection accuracy results of each method
ROC曲线可以全面评估模型分类器的性能,通过设置不同的IOU阈值,可以得到多组的TPR和FPR点对,将检测器映射成ROC平面上一条曲线,ROC曲线越靠近左上方则表明该检测模型分类效果越好。通过实验绘制各检测模型ROC曲线如图5所示。
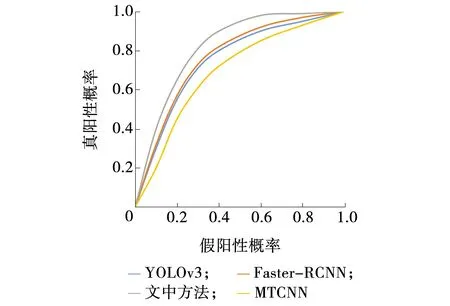
图5 各模型ROC曲线Fig. 5 Comparison the detection results of different models
由图5可以看出,MTCNN的检测效果最差,Faster-RCNN和YOLOv3检测效果相当,文中方法检测效果相比其他三种方法最好。为了进一步直观的计算检测器的性能,文中用ROC曲线下的面积(AUC)来量化模型检测性能。AUC表示检测模型检测正确比检测错误的概率还要大的可能性,用来表示各方法在ROC曲线下的面积占比γA。实验结果如表5所示。

表5 各模型AUC对比Table 5 Comparison table of face detection accuracy results of each method
为评估文中方法的准确性,在WIDER FACE验证集上对比实验了MTCNN等四种方法,可以看出,本文方法相比MTCNN的AUC提升了11.62%,这是因为文中方法在更低的特征层对检测框进行预测,提高了对小目标的检测能力。设置了不同比例的检测框,使检测框和真实框的交并比的值得到进一步提升。
上述实验证明了文中方法在WIDERFACE数据集上的优越性能,为了进一步了解文中方法在其他数据集的适用性,设计实验进行对比,如表6所示。

表6 文中方法在各数据集上性能Table 6 Comparison of face detection accuracy results of each method
FDDB是公认的人脸检测标准数据集,AFLW和CelebA也是进行人脸检测被广泛使用的数据集,它们相比WIDER FACE中图像更清晰,人脸受其他因素影响较少。通过将文中方法在其他三种数据集上进行实验,可以发现精准度和AUC值没有明显下降,证明了文中方法在其他数据集有广泛适用性。
在检测结果图像中,挑选出了一些检测错误的难分样本,包括人脸误检为背景、背景误检成人脸的样本,如图6所示。

图6 难分样本举例Fig. 6 Hard samples example
由图6可以看出,这些难分样本处在模糊、光照变化剧烈、人脸被遮挡、变形扭曲的环境中,因此各模型对此类样本检测率都不高。上述难分样本影响检测成功率,如何抑制对难分样本的误检是下一步研究目标。
4 结束语
通过分析SSD的主干网络VGG16结构的特点,使用了mobilenet_v3构造更轻量级的网络模型,提高模型运算效率,将预测层向更低的特征图偏移,提高了对小目标的检测能力。分析真实人脸框比例,对预测框的比例进行聚类,使得检测框和真实框更加吻合。通过对数据集图像进行预处理,送入网络模型训练并设计多组对照实验。
在数据集上的适用性较强,但是针对人脸模糊、遮挡、光照变化的图像检测还有待提高,后期将针对这些难分样本进行研究,提高对这些图像的检测能力。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
作文小学中年级(2020年6期)2020-07-24 08:33:10
动漫星空(2018年9期)2018-10-26 01:17:14
高中生学习·高二版(2015年12期)2016-01-05 13:08:35
发明与创新(2015年33期)2015-02-27 10:40:09
奇闻怪事(2014年5期)2014-05-13 21:43:01
自然资源遥感(2014年3期)2014-02-27 11:56:38
意林(2011年10期)2011-05-14 07:44:00
中学英语之友·上(2008年2期)2008-04-01 01:19:30
