
异构模式中关联数据的一致性规则发现方法
2020-09-24 08:41:26杜岳峰李晓光宋宝燕
计算机研究与发展 2020年9期
杜岳峰 李晓光 宋宝燕
(辽宁大学信息学院 沈阳 110136)duyuefeng@lnu.edu.cn)
数据一致性是质量管理的一项核心事务[1],主要针对数据中存在的冲突情况进行处理.规则约束作为数据一致性管理的重要技术,可以从语义层面对数据实体关系进行形式化地抽象,有效地对冲突数据进行检测和修复,比如条件函数依赖(conditional functional dependencies, CFDs)[2].
随着信息产业的发展和大数据的普及,现实生活中的数据呈现出海量数据增长和多源多模态的分布特点,导致大数据环境下的一致性问题变得更加突出.具体表现为:一是数据中潜在的错误更容易产生;二是对异构模式数据的管理更加复杂.
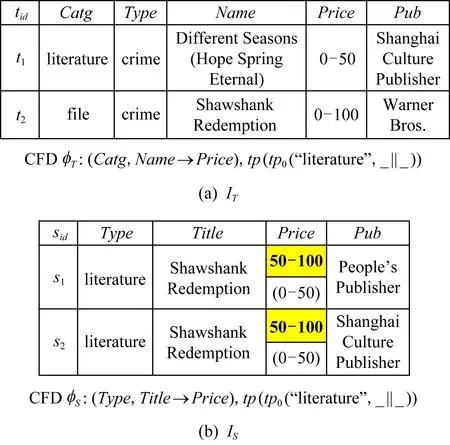
Fig. 1 Inconsistencies under heterogeneous schemas图1 异构模式中的数据冲突
图1描述了异构模式中的数据冲突情况.
T,S是商品销售记录的2种关系模式.版权分类(Catg)、类型(Type)、名字(Name)、价格区间(Price)、出版商(Pub)是T上的5个属性.类型(Type)、书名(Title)、价格区间(Price)、出版商(Pub)是S上的4个属性.IT,IS是T和S上的关系实例.其中,黑体部分为错误数据,括号内为现实生活中对应的真值情况.
文献[2]中,CFDs是一种可以根据元组的特定条件属性判定数据一致性的规则约束方法.具体地,对于CFDφ:(X→Y,tp),X→Y是函数依赖(functional dependencies, FDs)的一般形式,tp是特定的条件属性模板.对于任意元组u,v,在u[X]=v[X]=tp[X]的情况下,如果u[Y]=v[Y],则称u,v是一致的;否则,如果u[Y]≠v[Y],则称u,v是不一致的.
φT,φS是T,S上的CFDs.以φS为例,φS描述了在S上,对于所有的文学作品,它们的名字可以决定它们的价格区间.虽然φT和φS表达的意思相近,但是由于处于异构关系模式,所以对应的属性也不尽相同(如T中Catg与S中的Type对应).另外,对于相同的Type属性,它们在T和S中表达的含义也不相同,会造成属性的二义性.这些都增加了规则融合的难度.
其次,尽管IT,IS中的记录都分别满足φT,φS的一致性要求,比如对于s1,s2,在s1[Type]=s2[Type]=“literature”,s1[Title]=s2[Title]=“Shawshank Redemption”的情况下,有s1[Price]=s2[Price].文学作品“Shawshank Redemption”的价格区间都是50~100元,说明它们在IS中是一致的.但是s1[Price],s2[Price]与真实值相不符,使得它们成为一种潜在的错误.
对于异构关系模式中的潜在错误数据,可以使用如图2所示的条件包含依赖(conditional inclusion dependencies, CINDs)[3]和内容相关的条件函数依赖(content-related conditional functional dependencies, CCFDs)[4]来进行处理.
η可以根据特定的文学作品名字,将T,S模式中的Pub、Price、类型(Catg,Type)、名字(Name,Title)属性进行匹配.现实生活中的数据是相互关联的[5],可以利用这种关系将关联数据放在一起进行检测.现实生活中,“Shawshank Redemption”和“Different Seasons (Hope Spring Eternal)”指的是同一本文学作品,因此,可以把2类数据放在一起进行检测.进而,可以通过η将模式T,S联系到一起,然后使用φT检测出s1,s2中的潜在错误.

Fig. 2 CINDs and CCFDs under heterogeneous schemas图2 异构模式中的CINDs和CCFDs
但是,由于人们对领域和专业知识的局限,缺乏对数据关系的深层理解,使用人工方法进行规则发现有可能出现规则缺失、混淆和冲突的情况.在耗费大量人力资源的情况下还无法得到可靠的结果,这就需要一种可靠高效的自动规则发现方法.本文在进行异构模式一致性规则发现的研究过程中遇到的挑战有:
1) 异构模式中的属性关系复杂,存在不同属性之间的匹配问题,在规则中混合CINDs进行规则发现会对一致性规则的发现问题产生影响,可能造成属性对应关系的混乱.
2) 在使用CINDs对一致性规则进行融合和规则发现时,由于CINDs的属性之间存在包含问题,这会对融合后的一致性规则的条件范围产生影响.
针对上述问题,本文利用CINDs对CCFDs进行异构关系模式下的规则发现,具体贡献为:
1) 对使用CINDs进行异构关系模式下CCFDs规则发现问题进行分析,解释规则发现的可满足性、蕴含性和可验证性问题.
2) 提出了一种使用CINDs进行异构模式和实例的融合方法.
3) 设计了一种基于2级lattice结构的CCFDs规则发现方法,对所有规则空间进行搜索.
4) 通过在NBA数据和豆瓣数据上进行实验,验证本方法的有效性和高效性.
1 相关工作
数据质量管理是数据库领域研究的一个经典问题.本文主要研究异构模式关联数据中一致性规则的发现问题.目前与本文研究最为密切的相关工作包括3个方面:
1) 规则约束.规则约束是数据质量管理的一个重要技术,包含很多种类,如条件函数依赖(CFDs)[2]、扩展条件函数依赖(extended conditional functional dependencies, eCFDs)[6]、内容相关的条件函数依赖(CCFDs)[4]、条件包含依赖(CINDs)[3]等.特别地,文献[7]提出了一种图函数依赖(graph entity dependencies, GEDs),可以对图上的实体数据进行一致性分析.
通常,不同类型的规则可以混合使用,同时解决多类数据质量的混合问题.文献[3]使用CINDs对特定条件的异构模式数据进行匹配,并分析了CINDs与CFDs之间的相互作用关系.文献[8]提出了一种针对实体一致性的链接算法.
2) 规则发现.规则发现是对规则约束进行形式化语义抽象的自动发现方法.具体地,Huhtala等人在文献[9]中基于lattice结构提出了一种用于FDs规则发现的TANE方法.基于此,钟评等人在文献[10]提出了一种基于置信度的FDs规范发现方法.再者,Chiang等人在文献[11]中提出了一种CFDs规则方法,可以搜索特定条件下的函数依赖.此外,文献[12-13]提出了GEDs和OFDs(ontology functional dependencies)的规则发现方法.
3) 异构数据清洗.异构数据清洗主要针对异构模式的数据和语义2方面内容进行质量管理.具体地,马茜等人在文献[14]中提出了一种针对多源多模态数据的动态感知方法.Dallachiesa等人在文献[15]中提出了一种自动商业数据清洗系统,可以对多种类型的语义规则进行管理.文献[16-19]对质量管理的评价标准和可扩展的大规模数据质量管理等内容进行了相关研究.
此外,时序数据[20]、知识图谱、图数据[21]、实体数据质量管理的研究内容正在逐渐升温,成为数据质量管理的研究热点.其中,樊文飞等人通过长期对数据质量的研究,在文献[7,22]中着重描述了未来数据质量管理的研究和发展方向.Ortona等人在文献[23]中对使用知识图谱进行规则发现的相关内容进行了研究.
2 异构关联数据的一致性问题
本节针对异构模式关联数据的一致性规则发现问题,首先对CINDs和CCFDs进行介绍,然后给出了规则发现问题的相关概念及分析.
本文使用R=(tid,A1,A2,…,AN)形式的关系模式,其中tid表示记录编号;A1,A2,…,AN表示R上的属性,dom(A)表示属性A的定义域,R上的所有属性集合记作attr(A),|attr(A)|表示集合中的属性个数.
2.1 规则约束
定义1.内容相关的条件函数依赖(CCFDs)[4,24].CCFDs是一种可以同时对多个条件之进行一致性检测的完整性约束.关系R上的CCFD记作
φ:(C|Y→A,Sc=∪Sci),
(1)
其中,C为条件属性集合,Y为变量属性集合,C和Y由“|”分隔,并且C,Y⊂attr(R),C∩Y=∅,C,Y合称为规则左部,记作lhs(φ),单属性A称为规则右部,记作rhs(φ);Y→A是一个标准函数依赖;Sci是关于C的属性值集合,Sci⊂dom(C),Sc是Sci的集合,即Sc=∪Sci.并且,对于任意元组ti,tj,如果ti[C],tj[C]∈Sci,ti和tj需要放在一起进行检测.图2中的φT就是模式T上的一条CCFD规则.

定义2.条件包含依赖(CINDs)[3].CINDs是一种可以对异构模式进行属性匹配的规则约束.关于模式Ra,Rb的CIND记作
η:(Ra[X;Xk]⊆Rb[Y;Yk],Tk=∪tk),
(2)
其中,X,Xk⊂attr(Ra),X∩Xk=∅,同理有Y,Yk⊂attr(Rb),Y∩Yk=∅;Ra[X]⊆Rb[Y]是一个标准包含依赖;Tk是条件属性集合的模板,Tk=∪tk,tk是条件属性值的对应情况,tk=(tk[Xk]‖tk[Yk]),tk[Xk]∈dom(Xk),tk[Yk]∈dom(Yk),使用“‖”进行分割.图2中的η就是关于T,S的一条CIND规则.
2.2 异构模式下CCFDs发现问题
本文主要针对异构关联数据中的一致性规则发现问题进行研究,使用CINDs对CCFDs进行异构模式下的规则发现,其问题描述如下:
定义3.异构模式下CCFDs发现问题.给定关系模式Ra,Rb下的实例Ia,Ib以及对应的CINDs规则集合Γ,找到模式融合Ra⊕ΓRb上所有CCFDs的最小性规则集合Σ.
1) 异构模式融合并不简单等同于模式和实例的合并,具体的异构融合过程Ra⊕ΓRb将在3.1节中进行介绍.
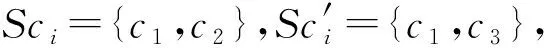
3) 对于发现得到的CCFDs规则集合需要满足Armstrong最小性和规则数量最小性[4]要求.
本文对CCFDs规则的可满足性、蕴含性和可验证性3个基本问题进行分析.
定理1.CCFDs规则的可满足性、蕴含性和可验证性问题分别属于NP-complete,coNP-complete,PTIME.
证明. CCFDs是在CFDs的基础上,对关联数据的条件值进行合并得到的一种特殊情况,这里以CCFDs规则可满足性为例进行说明.Fan等人在文献[25]中使用合取范式γ:X1∨X2∨…∨Xn(其中,Xi都是由小项合取得到的)对MAXGSAT(maximum generalized satisfiability)问题[26]进行规约,证明CFDsφ的可满足性问题是属于NP-complete的.具体地,MAXGSAT是MAXSAT(maximum satisfiability)的一般问题,描述了最大可满足性问题的一般形式,被证明是满足NP-complete的.其中,X1,X2,…,Xn∈lhs(φ),Xi满足l1∧l2∧l3的形式,l1,l2,l3是Xi在条件值tp下的取值情况,Xi的定义域为dom(Xi,tp),进而判定γ:X1∨X2∨…∨Xn的真值情况.对于CCFDs而言,其证明过程满足CFDs证明的基本过程,区别在于l1,l2,l3是Xi在条件值Sci下的取值情况,Xi的定义域为dom(Xi,Sci).这样可以在O(|Sci|)时间内将CCFDs可满足性问题转化为CFDs可满足性问题,其中|Sci|表示Sci中包含的条件值的个数.因此,可以把CCFDs可满足性问题看作是CFDs可满足性的等价问题.所以,CCFDs规则的可满足性问题是属于NP-complete的.同理,可以将CCFDs规则的蕴含性问题和可验证问题等价转化成CFDs规则的蕴含性问题和可验证性问题,并且CFDs规则的这2个问题在文献[3]中被证明是分别属于coNP-complete,PTIME的.因此,CCFDs规则的蕴含性问题和可验证问题也分别属于coNP-complete,PTIME的.
证毕.
需要说明的是,对于CCFDs和CINDs混合规则的可满足性、蕴含性、可验证性问题满足文献[3]描述的情况,均属于不确定性问题.
3 异构模式下的CCFDs规则发现方法
针对2.2节中提出的CCFDs发现问题,本节将从异构模式融合、搜索结构和规则发现方法的设计这3个方面对规则发现的实现过程进行描述.
3.1 异构模式融合
在异构关系模式中,由于关系模式的差别,一种关系模式上的规则集合很难在另一种关系模式上产生作用.这样一方面会降低规则的复用率和作用效果,另一方面也会影响规则对整体数据进行归纳抽象.因此,首先需要对异构数据进行融合.但是,异构融合不能等同于简单的模式和实例合并.针对这一问题,对于给定异构关系模式Ra,Rb下的实例Ia,Ib以及CINDs规则集合Γ,本文提出了一种异构模式融合和异构实例融合的概念.
对于η∈Γ,η:(Ra[X;Xk]⊆Rb[Y;Yk],Tk=∪tk),本文首先给出Ra,Rb关于η的模式融合形式:
Ra⊕ηRb=(X⊕ηY,Xk⊕ηYk,
attr(Ra)-lhs(η),attr(Rb)-rhs(η)),
(3)
其中,X⊕ηY(或者Xk⊕ηYk)表示属性X和Y(或者Xk和Yk)融合后组成的新的模式属性,dom(X⊕ηY)=dom(X)∪dom(Y),dom(Xk⊕ηYk)同前.lhs(η)表示η的左部属性集合,即lhs(η)=X∪Xk.这样,原来异构模式中能够通过η进行匹配的属性将被放在一起,共同作为融合模式中的一个属性;不能被匹配的属性仍然单独保留在融合后的模式中.并且,对于融合后的属性值,其阈值为2个属性的并集.
定义4.异构模式融合Ra⊕ΓRb.Ra⊕ΓRb表示整个异构模式空间中的模式融合形式,融合过程为
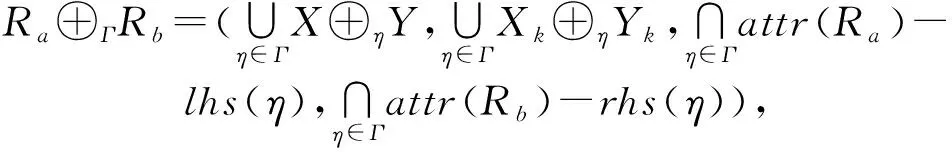
(4)
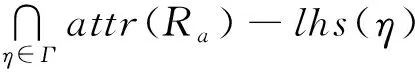
规则发现问题通常是从实例中对语义关系进行抽象.模式融合会对关系属性进行扩展,这样也会对关系实例产生变化,进而对规则发现产生影响.接下来给出异构实例融合的概念.
定义5.异构实例融合Ia⊕ΓIb.Ia⊕ΓIb表示在融合模式下合并得到的关系实例,构建过程为
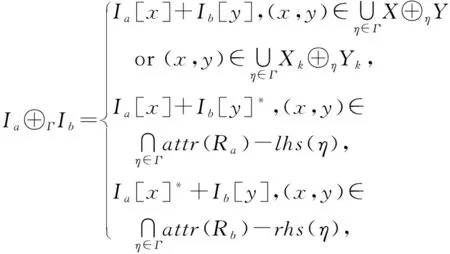
(5)
其中,Ib[y]*表示对于Rb中原本不存在的属性,使用“*”值进行填充.需要说明的是,“*”值是一个特殊值,既不是空值,也不是实值,不能用“*”值来表示数据的真实情况,但是认为“*”值与任何数据都不冲突,即对于∀t,s∈Ia⊕ΓIb,如果t[A]=“*”或者s[A]=“*”,则t[A]=s[A].这种情况在实际数据中是不允许的.但是,规则发现作为数据分析的一个中间过程,“*”值不会对规则发现造成影响,是可以接受的.表1给出了融合后的Ra⊕ΓRb及Ia⊕ΓIb.

Table 1 Fusion Instance Ia⊕ΓIb on Fusion Schema Ra⊕ΓRb表1 融合后Ra⊕ΓRb模式的Ia⊕ΓIb
3.2 2级lattice结构
函数依赖FDs、条件函数依赖CFDs、扩展函数依赖eCFDs是进行数据一致性管理的重要技术.在关系模式R中,FDs可以表示为γ:X→A,属性集合X,A∈R.对于R上的实例I,γ表示X在I上的属性值可以唯一决定A的属性值,即对于∀u,v∈I,如果u,v是一致的,那么有u[X]=v[X],u[A]=v[A].文献[8]提出了一种用于FDs规则发现的lattice搜索结构,可以根据属性个数从左部属性和右部属性对规则空间进行划分,直到遍历所有的搜索空间,可以有效对FDs进行发现,图3(a)是一个lattice结构实例,其中边(AB,ABC)就表示FDγ:AB→C的规则空间.
对于CFDs和eCFDs,由于在FDs规则的基础上,在规则左部中对条件属性进行了划分,在进行规则发现的过程中就需要分别考虑条件属性和变量属性的情况.特别地,CCFDs是CFDs和eCFDs的一种特殊情况,规则将CFDs和eCFDs中具有关联关系的规则进行了合并.基于lattice结构的基础原理,本文提出了一种异构模式的2级lattice结构,如图3所示.在进行规则发现时,从|AB→C开始,经过A|B→C,B|A→C直到AB|→C结束.图2中的φT就是在Catg,Name|→Price层次中对条件值进行合并得到的CCFD.
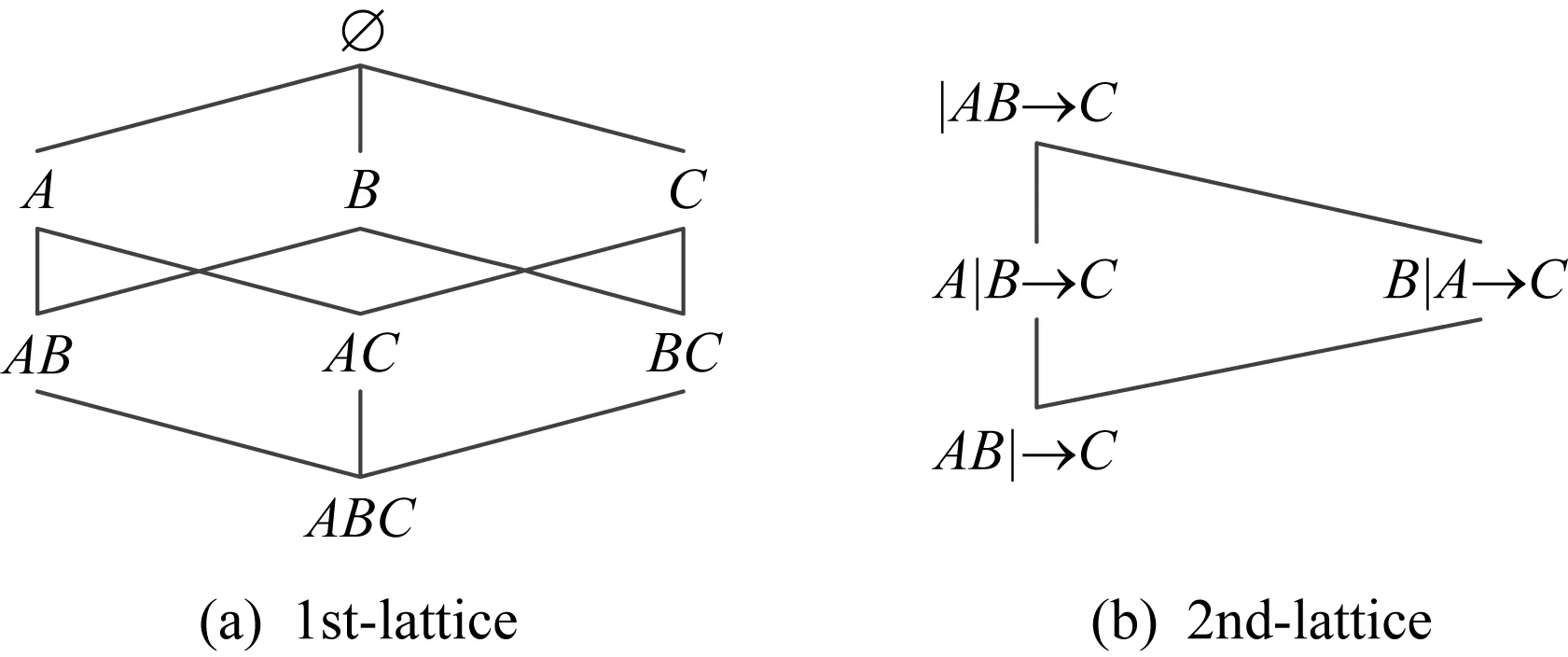
Fig. 3 2-level lattice图3 2级lattice结构
3.3 CCFDs规则发现方法
本文使用Ra⊕ΓRb对异构关系模式进行融合,然后使用2级lattice结构构建CCFDs的搜索空间,对于满足相同形式C|Y→A的条件值进行合并,得到对应的CCFD.但是,并不是所有的条件值都能进行合并,有的条件值之间是相互冲突的.因此,本文提出了一种用于条件值冲突的判定方法,如定理2所示.
定理2.一条CCFDφ:(C|Y→A,Sc=∪Sci)关于实例Ia⊕ΓIb是不冲突的当且仅当:
对于∀Sci∈Sc,有
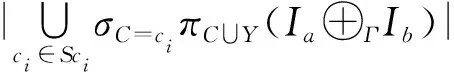
证毕.
需要说明的是,定理2从条件值冲突的角度对规则合并进行分析,也可以使用定理2对规则是否成立进行判定,进而用于CCFDs的规则发现.
对于2.2节描述的规则最小性问题.本文研究的条件值合并是在满足Armstrong最小性的CFDs上进行的,因此合并后的CCFDs仍然满足Armstrong最小性.文献[4]中证明CCFDs规则数量最小性是最大子团的一个等价问题,属于NP-complete.对于本文所描述的异构关系模式下的CCFDs规则发现问题,通过CINDs将Ra,Rb进行融合成Ra⊕ΓRb,其条件属性可以在PTIME内转化成Ra和Rb的条件属性,使得异构模式下的CCFDs规则发现的数量最小性问题仍然是一个NP-complete问题.
对于给定层次形式C|Y→A,需要合并候选条件值集合C及样本实例Ia⊕ΓIb,本文提出一种启发式的条件值合并方法,如算法1所示.
4 实验分析
对于异构模式下关联数据的CCFDs规则发现问题,本文通过在2组真实数据进行实验来验证方法的有效性和高效性.
4.1 实验设置
硬件方面,本实验使用Intel Core i5-7400 (3.00 GHz) CPU,搭载8 GB RAM主机进行实现,程序设计使用Java语言进行实现.
实验数据集,本文使用NBA数据和豆瓣数据进行融合,并使用融合后的数据进行规则发现.
1) NBA数据.队员数据Players和赛季比赛统计信息Stat是从体育信息数据库(1)https://www.rotowire.com/basketball/上抽取得到的真实数据.Players数据包含14个属性、超过11 000的信息记录.Stat数据包含11个属性、超过200 000的比赛信息.以球队作为条件设计使用30条CINDs对Players和Stat进行融合,例如η:Players(player,pos,season,min,drafted,pts,team=“HOU”)⊆Stat(player,pos,lea,min,no,pts,tname=“HOU”).
2) 豆瓣(Douban)数据.豆瓣电影Movie和豆瓣读书Book是从豆瓣网站(2)https://www.douban.com/上抽取得到的部分真实数据.Movie数据中包含10个属性,元组数为50 000条.Book数据中包含12个属性,元组数为47 000条.并且,对Movie和Book融合后得到的数据包含62 000条元组和14个属性.
4.2 实验结果及分析
本文从规则发现方法的基本性能和扩展性2个方面进行验证和分析.
4.2.1 基本性能
首先从运行时间和规则数量对整体性能进行评价,然后给出规则发现的部分实例,其中,豆瓣数据使用合并元组9 332条,包含3 112条电影实体.
图4(a)给出了NBA和Douban数据集中,规则发现过程融合阶段(fusion)、2级lattice下CFDs发现阶段(2-lattice)、规则合并阶段(h-CCFD)的运行时间情况.
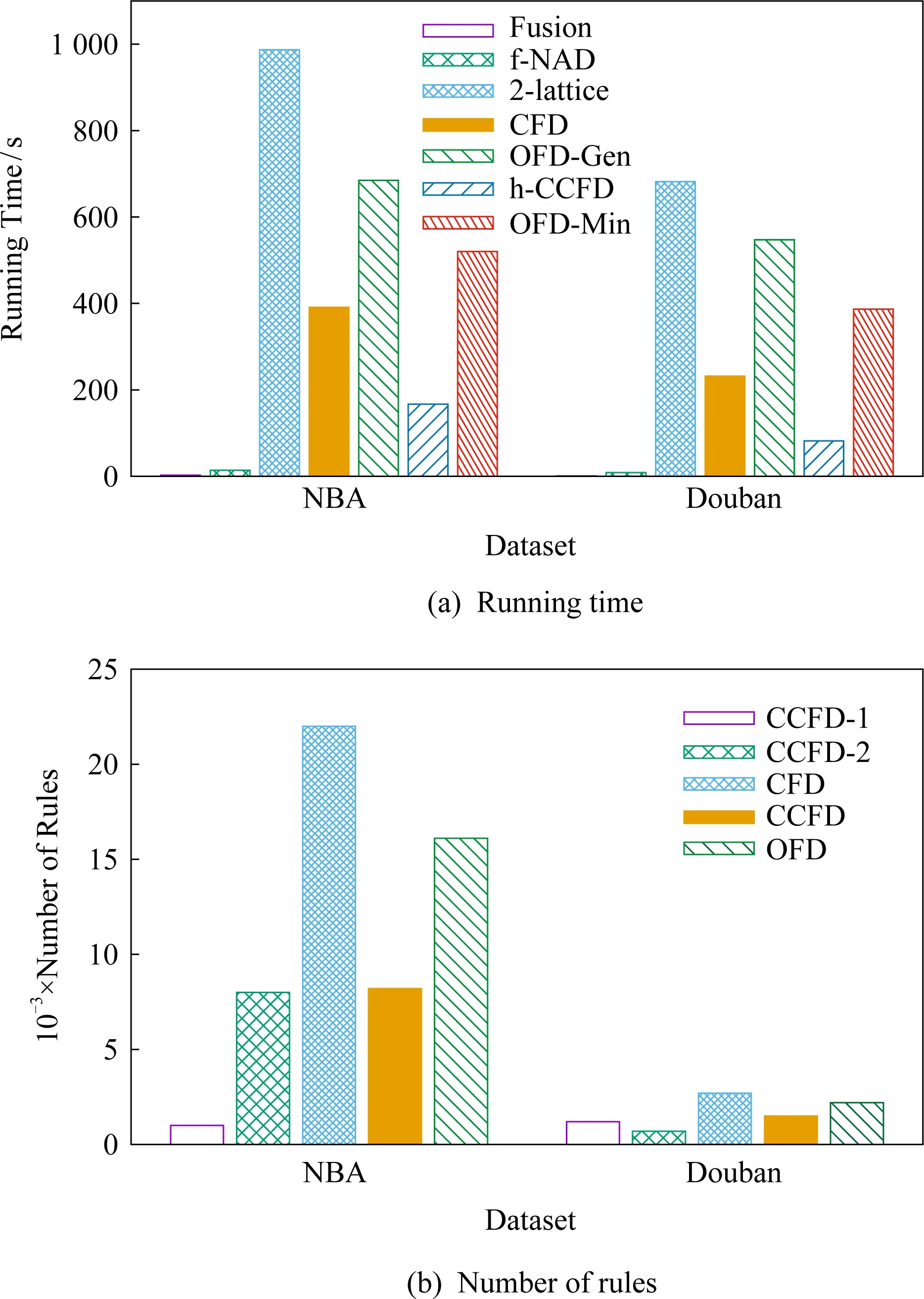
Fig. 4 Performance of rules discovery图4 规则发现的基本性能
其中,模式和实例的融合时间(fusion)最短,分别为2.6 s和0.8 s,只占整个运行时间的极小比例.同样情况下,使用文献[15]中的规则融合方法(f-NAD)需要14.1 s和8.8 s,这是因为f-NAD需要对规则中的各个属性进行拆分,然后使用统一的形式进行表达.
CFDs作为CCFDs合并的候选规则.在进行候选规则发现过程的实验中,如2-lattice所示,在2级lattice结构下对CFDs规则进行发现的时间最长,相比较文献[2]中使用的freeset-closedset方法,对应图4(a)中的CFD方法,时间要超过1倍左右.但是,该方法不利于对规则进行C|Y→A形式划分并用于CCFDs合并,所以这里仍推荐使用2级lattice结构进行CCFDs规则发现.OFD-Gen是在fusion的基础上,对每个实体使用1级lattice方法进行候选规则发现的过程,但是由于实体的数量较多,增加了整体的运行时间.对于NBA和Douban数据,由于融合的属性个数基本相同,所以构成的2级lattice空间的大小也基本相同.
在对规则进行合并的过程中,h-CCFD在2-lattice结构发现CFDs的基础上,使用启发式方法对候选条件值进行合并,可以在较短时间内完成.OFD-Min在进行规则发现的过程中首先对实体进行判定和识别,然后根据实体的内容、属性及相互关系进行规则发现,需要大量的运行时间,在NBA和Douban数据上分别需要520s和387s,是h-CCFD方法的3.8和6.2倍.并且,OFD方法(OFD-Gen与OFD-Min之和)要高于CCFD方法(2-lattice与h-CCFD之和)分别为6%和25%,具体会受到实际数据分布的影响.
图4(b)给出了NBA和Douban数据中规则发现的数量情况.其中,CCFD-1和CCFD-2指在2个数据集中分别在未融合情况下进行规则发现的情况,比如NBA中CCFD-1指单独在Players数据中发现CCFD的规则数量,CCFD-2指单独在Stat数据中发现CCFD的规则数量.其中,NBA数据集中,CCFD-1,CCFD-2、CCFD合并得到的规则数量分别为1 009,8 028,8 238条,并且有878条来自Players和Stat的规则合并到了一起,合并的比率为10.7%.在Douban数据集中,合并的数量是425条,比率为28.3%,这是因为合并的情况会受到实际数据分布的影响.
从CFD对CCFD的规则数量情况来看,由于NBA中各个队伍的整体差别不是很明显,所以各个队伍可以合并在一起,并且平均每2.7条规则就可以合并成1条规则.特别地,现实生活中条件值的合并情况由数据的实际分布情况来决定.OFD使用同义词进行实体识别,将同一指向的规则合并到一起,分别在NBA和Douban上得到16 132条和2 237条规则,但是合并的效果不如CCFD明显.
下面给出在实验过程中发现的部分规则实例.NBA数据集中发现的规则实例分别为CCFDφ1:(player⊕player|team⊕tname→drafted⊕no,Sc)Sc{Sc0{“Jordan”,“MJ”,“Air Jordan”}}和OFDρ1:(player⊕player|team⊕tname→{‘Jordan’,‘MJ’}drafted⊕no).同样,Douban数据集中发现的规则实例分别为CCFDφ2:(Title⊕Name|Type⊕Catg→Writer⊕Writer,Sc)Sc{Sc0{“Shawshank Redemption”,“Different Seasons”}}和OFDρ2:(Title⊕Name|Type⊕Catg→{‘月黑高飞’,‘肖申克的救赎’}Writer⊕Writer).
4.2.2 可扩展性
本节将从模式属性和元组数量2个方面考量规则发现方法的可扩展性.具体地,通过分别改变属性个数和元组个数,观察运行时间和规则数量的变化情况.
1) 属性数量变化.Douban数据集使用9 332条合并元组,包含3 112条电影实体.图5给出了属性数量变化情况下规则发现过程的时间变化和规则数量的变化情况.CFDs和h-CCFD的运行时间和规则数量都随属性数量呈指数增长趋势,这是因为2级lattice结构是一种随属性个数而呈指数变化的结构.OFD中虽然使用的是1级lattice结构,但是需要对每一个实体都进行识别和规则发现,所以整体运行时间更长.
另外,图5(b)所示的规则数量指数增长缓慢,是因为新增属性之间关系较弱,不易形成新的规则约束,这是属性结构和数据分布所决定的.特别地,规则数量呈现指数增长,这反映了规则发现的实际计算情况.但是,这种增长的速度过快,不是一个有利因素,尤其是对于大数据计算和实时计算而言,这种计算代价难以接受.因此,还需要针对这一问题设计剪枝方法、线性代价的近似方法,甚至亚线性方法.
2) 元组数量变化.图6给出了元组数量变化情况下规则发现过程的时间变化和规则数量的变化情况.CFDs,h-CCFD,OFD的运行时间和规则数量都随属性数量呈线性增长趋势,而且变化比较平缓,这是因为在随着元组数量增加的过程中,元组中包含的不同值也在均匀增加.当NBA数据大于150 000,Douban数据大于40 000时,随着元组数量的增加,新增元组所包含的不同值的数量却没有明显增加,所以规则数量增加的情况也会变得更加平缓.
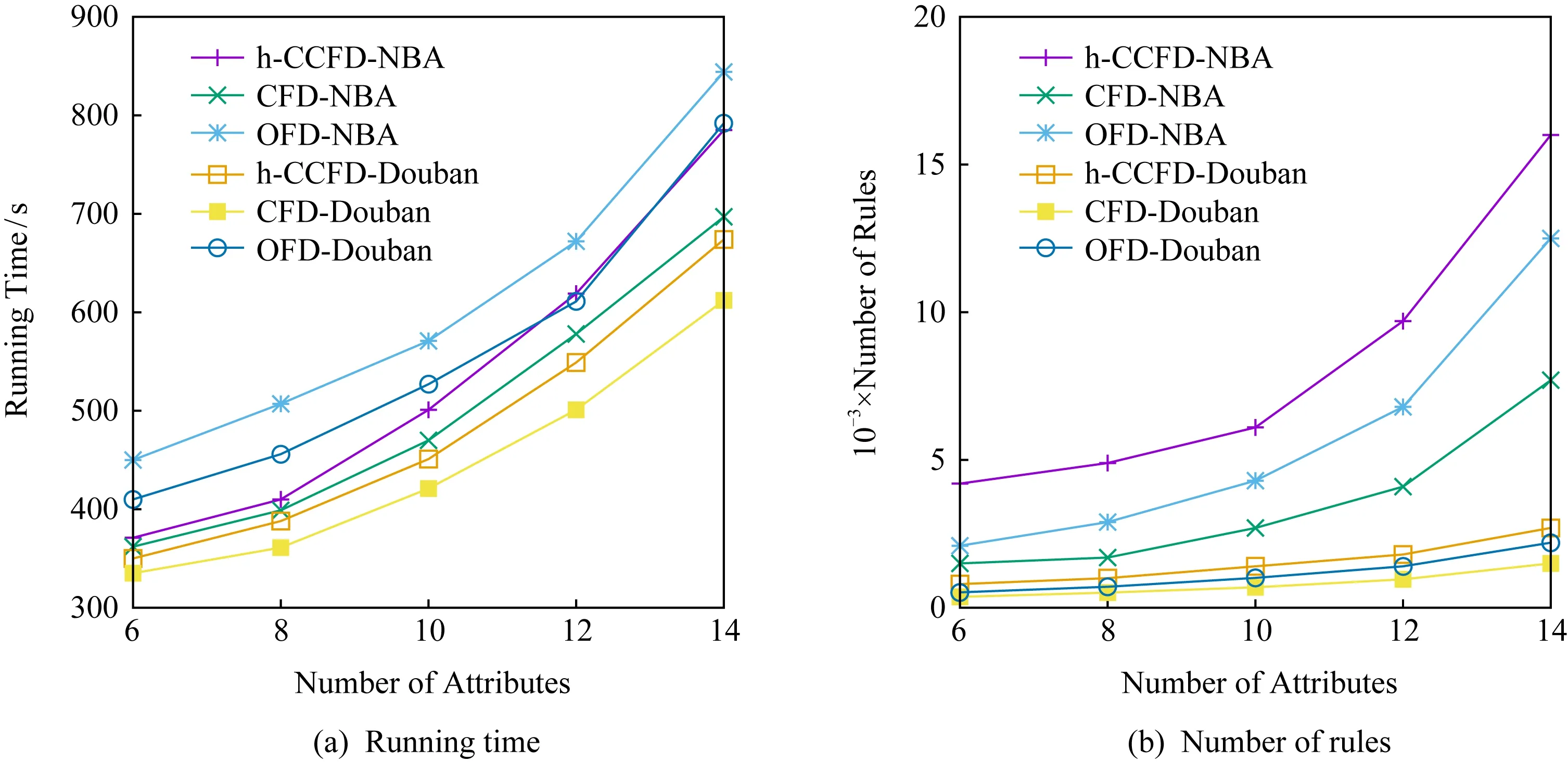
Fig. 5 Scalability on attributes图5 属性变化情况下的可扩展性
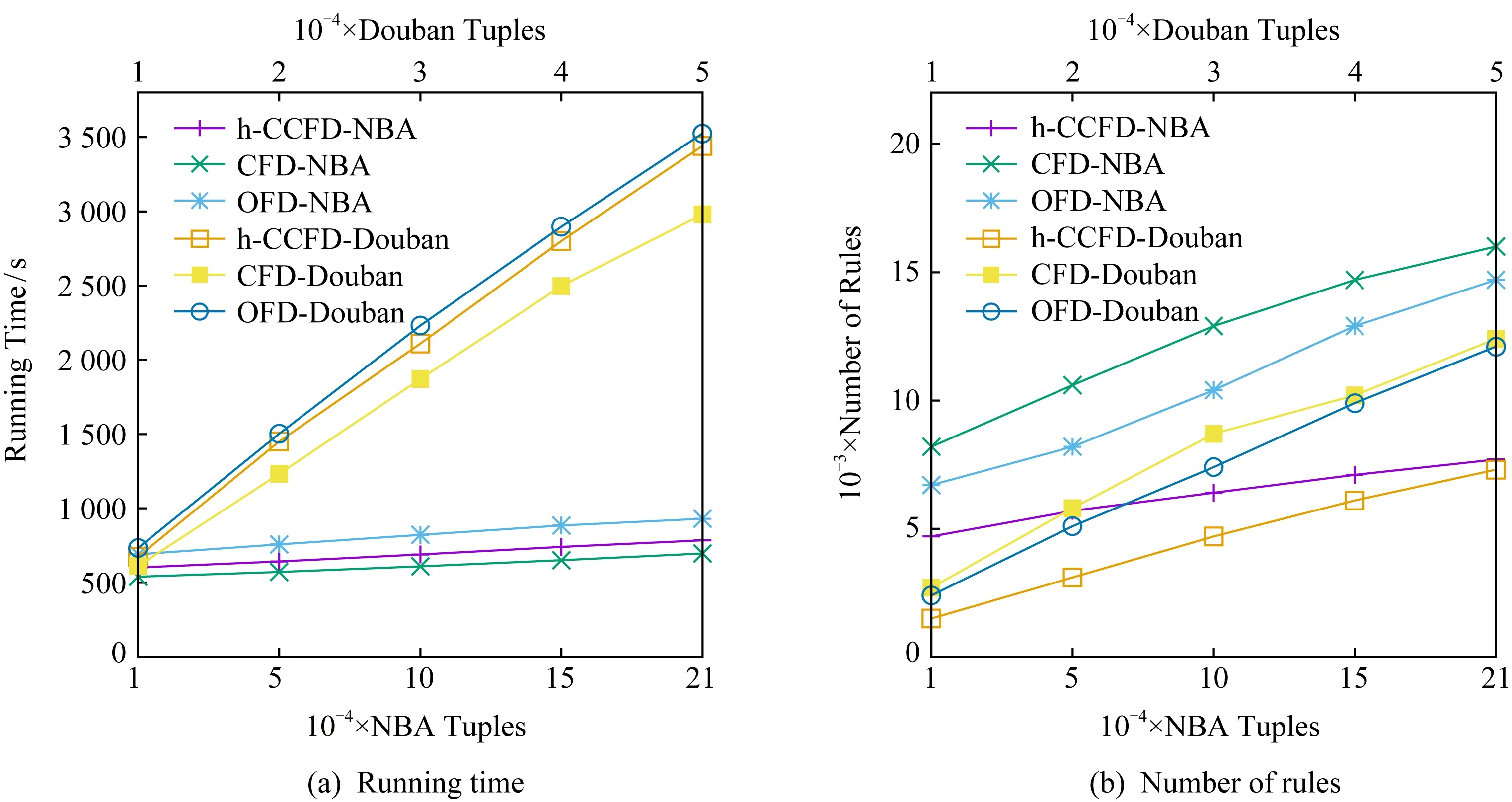
Fig. 6 Scalability on tuples图6 元组变化情况下的可扩展性
通过上述实验,说明本文提出的方法可以有效对异构数据进行融合,并且可以通过数据关联关系快速、准确地对CCFDs进行规则发现.
5 结束语
本文通过对异构关联数据的一致性问题进行分析研究,提出一种异构模式下一致性规则约束的发现方法,并对规则发现的可满足性、蕴含性和可验证性问题进行了分析.具体地,本文使用CINDs对异构模式进行融合,提出一种基于2级lattice结构的CCFDs规则发现方法,最后通过实验验证了本文所提方法的有效性和高效性.
猜你喜欢
小学教学研究(2022年5期)2022-04-28 21:29:36
电脑报(2021年14期)2021-06-28 10:46:22
计算机与生活(2019年5期)2019-07-18 01:08:56
吉林大学学报(理学版)(2018年2期)2018-03-29 04:58:03
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
汽车零部件(2014年10期)2014-11-11 12:25:04
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
电信科学(2013年10期)2013-08-10 03:41:54
