
Clothes Keypoints Detection with Cascaded Pyramid Network
2020-09-23 02:39LIChaoZHAOMingbo赵鸣博
LI Chao(李 潮),ZHAO Mingbo(赵鸣博)
College of Information Science and Technology,Donghua University,Shanghai 201620,China
Abstract: With the development of the society,people’s requirements for clothing matching are constantly increasing when developing clothing recommendation system. This requires that the algorithm for understanding the clothing images should be sufficiently efficient and robust. Therefore,we detect the keypoints in clothing accurately to capture the details of clothing images. Since the joint points of the garment are similar to those of the human body,this paper utilizes a kind of deep neural network called cascaded pyramid network(CPN) about estimating the posture of human body to solve the problem of keypoints detection in clothing. In this paper,we first introduce the structure and characteristic of this neural network when detecting keypoints. Then we evaluate the results of the experiments and verify effectiveness of detecting keypoints of clothing with CPN,with normalized error about 5%-7%. Finally,we analyze the influence of different backbones when detecting keypoints in this network.
Key words: deep learning; keypoints estimation; convolutional neural network
Introduction
Human pose estimation is a fundamental challenge for computer version. It aims to accurately detect the position of the joint point of a person and achieve an understanding of a person’s posture. The classical approach to estimate pose is pictorial structure model[1-3],in which spatial correlations between parts of body are expressed as a tree-structured graphical. In recent years,many detection algorithms of human joint points have been continuously improved by the involvement of deep convolutional pose machines. For example,Pfisteretal.[4]regarded pose estimation as a detection problem and reinforced the feature maps with optical flow,which achieved good results. Liuetal.[5]proposed the FashionNet network to obtain more distinguishing features by jointly predicting the keypoints and attributes of clothing. Geetal.[6]proposed Match R-CNN,which builds upon Mask R-CNN to solve the above four tasks including clothes detection,pose estimation,segmentation and retrieval in an end-to-end manner. Sunetal.[7]proposed an HRNet and demonstrated the effectiveness through the superior pose estimation results. Liu and Yuan[8]recognized human actions as the evolution of pose estimation maps.
Convolutional pose machine(CPM)[9-10]is a sequential deep learning network based on the convolutional neural network which proposes a serialized structure that fuses the spatial structure and the texture structure to improve the accuracy. Each stage in CPM is divided into two parts. One is an initial convolutional neural network which aims to extract the initial features of the picture. The other is convolutional neural network of current stages,which aims to further extract the features of the image. In this way,the position of the joint point is continuously updated and refined. The total PCKh of the algorithm on the MPII dataset is 87.95%,and it also has high accuracy in other datasets. But CPM doesn’t use different scales of feature maps. As a result,the accuracy of detecting keypoints is not always satisfied.
Hourglass[11]is another prevalent method for pose estimation. It is motivated by capturing information at every scale for fusion and strengthens the position of the space of each joint point to locate points accurately. It stacks eight hourglasses which are top-down and bottom-up modules with residual connections. The heatmap given by the first hourglass network as the input of the next hourglass network means that the second hourglass network can use the relationship between joint points,thus improving the prediction accuracy of the nodes. However,stacking two hourglass modules have a relatively good effect compared with eight modules.
A key step to understand clothes in images is detecting keypoints of clothes accuratly. Given a picture of clothing,we wish to determine the precise pixel location of important keypoints of the clothes. Achieving an understanding of clothing’s keypoints and limbs is useful for further study such as clothing retrieval and recommendation.
Detecting keypoints of clothing is similar to human pose estimation. Different nodes have similar distribution,and there is a spatial position connection between these nodes. In recent years,the effects of detecting keypoints have been greatly improved by deep convolutional neural networks[12-13]but lots of challenges still exist,such as occluded keypoints,invisible keypoints and complex background,which are hard to be addressed. Detecting keypoints of garments also has these difficult problems. This paper will introduce the point detection method proposed in cascaded pyramid network(CPN)[14]to locate points in clothing. We first introduce the structure of network and advantages of CPN when detecting keypoints in clothing. CPM and Hourglass are utilized as our baseline. After that,we analyze the influence of different backbones on CPN,including ResNet-50[15],DetNet[16]and SE-ResNet-50[17]. The results and visualizations of experiments are demonstrated at last.
1 Methods
1.1 Network structure
CPN[14]is a top-down approach for multi-person keypoints estimation. It applied a human detector[18]on the image to generate a set of human bounding-boxes and locate keypoints for each person. Since the ultimate aim is detecting keypoints in clothing,we don’t need the human detector and we can directly locate keypoints in clothing. The input of the network is pictures of different clothes and the ground truth is the location of keypoints in the pictures. As shown in Fig. 1,the whole network architecture is divided into GlobalNet and RefineNet.
1.1.1GlobalNet
ResNet-50 is used as the backbone of CPN to extract initial features of clothes and the feature pyramid is formed from outputs of different stages of ResNet. The arrow appears on the left in Fig. 1 is backbone of CPN. Feature maps in different scales produced by ResNet are sent up into GlobalNet sequentially,which can be denoted as C2,C3,C4,and C5. In this part,each feature map with particular resolution turns into two kinds of feature maps. One is created by 3×3 convolution filters to calculate “global loss” and the other is created by 1×1 convolution filters for RefineNet. This structure can achieve a balance between maintaining semantic information and spatial resolution for features and it is different from feature pyramid networks[19]because 1×1 convolutional kernel is applied before elem-sum in unampling. Based on the feature pyramid,GlobalNet is able to locate obvious points in clothing. But GlobalNet may fail to precisely recognize the occluded or invisible keypoints. These “hard” keypoints usually require more context information.
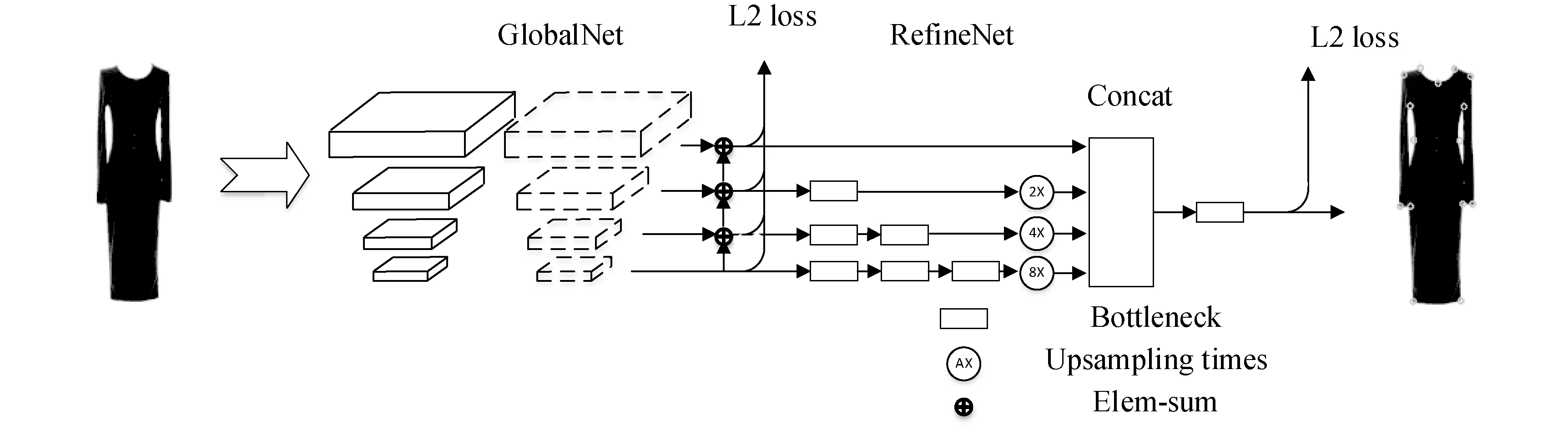
Fig. 1 Structure of CPN
1.1.2RefineNet
In CPN,four scale features produced by GlobalNet are transmitted into RefineNet to locate “hard” keypoints. The way that process features cross all scales is similar to that in HyperNet[20]. For the feature map with lower spatial resolution,CPN stacks more bottlenecks and upsamples more times to achieve trade-off between efficiency and effectiveness. Bottleneck is a residual unit and is a little different from that in Ref.[21]. The strategy in stacking bottleneck is different from that in Hourglass,which just utilizes the upsampled features at the end of hourglass module. After that,all feature maps are concated and sent up into the last bottleneck to output “refine map”,and “refine loss” is created by the output and labels.
1.2 Loss function
Corresponding to the network structure,the total loss consists of global loss and refine loss. Global loss is created by the four outputs of GlobalNet and labels. Refine loss is created by the output of RefineNet and labels. Figure 2 shows the output of GlobalNet and RefineNet. The outputs are fixed-sizei×j×kdimensional cube wherekmeans the number of joints (herek=14).

(a)

(b)
Labels in CPN are ground truths of points in the form of 2D Gaussian. Figure 3 illustrates a point in the form of 2D Gaussian and Fig. 4 illustrates all points in a clothing in that form. Both global loss and refine loss are mean square errors (L2 loss).

Fig. 3 2D Gaussian

Fig. 4 Points of clothing in form of 2D Gaussian
We denote training images as (x,y),whereystands for coordinates ofkjoints in the image. We denote the network regressor asφ,the training objective is estimation of the network weightsλ:
2 Results and Discussion
2.1 Hyper-parameters and normalized errors
The dataset we used in the experiments is FashionAI. To have normalized input sample of 384×384 for training,we resized more than 15 000 images into the same scale for each clothing. The input picture is randomly enhanced by flip and rotate augment. Data processing can minimize the influence of picture background on clothing detection,improve generalization and ensure accuracy. For testing,we perform similar resizing on 1 000 images for each category. We only train 50 epochs with stochastic gradient descent(SGD) and our initial learning rate is 1×10-4. We use a weight decay of 1×10-5and the momentum is 0.9. Batch normalization is also used in the network.
In these experiments,the average normalized error (NE) between the predicted points and the ground truth is used as the evaluation method,and the formula of the evaluation is
(2)
wherekis the number of keypoints,vkmeans whether the keypoint is visible,anddkmeans the distance between the predicted points and the ground truth.skis normalized parameter,which means the Euclidean distance of two armpits for shirts,coats and dress and the Euclidean distance of the top of trousers and skirts.
2.2 Evaluation on different networks
We adopt CPM and Hourglass as our baselines. Hyper-parameters in baselines are the same with that in our methods. Table 1 illustrates the results of these methods on the same dataset. The numbers in Table 1 mean normalized error of each clothing. Since CPN works best in three networks,we finally use this method to detect the keypoints of clothing. Detecting results of different clothing by CPN are shown in Fig. 5. To verify the effects of backbone on CPN,we try three backbones without changing other conditions as follows: ResNet-50,DetNet and SE-ResNet-50. Table 2 shows the performance of different backbones in CPN. The results illustrate the effects of different backbones in CPN when detecting keypoints,which are the same as pose estimation. Other excellent backbones[22-23]also achieve good results when detecting keypoints in clothing with CPN.

Table 1 Errors of different methods on detecting keypoints in clothing (Unit: %)

Fig. 5 Results of different clothing by CPN: (a) and (c) are inputs of CPN; (b) and (d) are outputs

Table 2 Errors of different backbones on CPN (Unit: %)
3 Conclusions
In this paper,we utilize a kind of deep neural networks about estimating the posture of human body to solve the problem of detecting keypoints of clothes. The results show that the network which merge feature maps in different scales for final predictions can improve the accuracy when predict keypoints to some extent. Our method is able to detect keypoints of clothing with normalized error about 5%-7%. Last but not least,the backbone of the neural network plays an important role in detecting keypoints in clothing like the case in pose estimation. Better backbone has stronger capability to extract initial features in clothing,which contributes to locate keypoints in clothing precisely.
 Journal of Donghua University(English Edition)2020年3期
Journal of Donghua University(English Edition)2020年3期
- Journal of Donghua University(English Edition)的其它文章
- Recent Progress for Gallium-Based Liquid Metal in Smart Wearable Textiles
- Accident Analysis and Emergency Response Effect Research of the Deep Foundation Pit in Taiyuan Metro
- Effect of Elastane on Physical Properties of 1×1 Knit Rib Fabrics
- Knowledge Graph Extension Based on Crowdsourcing in Textile and Clothing Field
- Analysis on the Application of Image Processing Technology in Clothing Pattern Recognition
- Encryption and Decryption of Color Images through Random Disruption of Rows and Columns