
基于矩阵变换的文本风格迁移方法①
2020-09-22 07:45黄若孜
计算机系统应用 2020年9期
黄若孜,张 谧
1(复旦大学 软件学院,上海 201203)
2(复旦大学 上海市智能信息处理重点实验室,上海 201203)
近年来,文本风格迁移是自然语言处理中的一个热点,该领域深刻影响着很多NLP 应用的发展,比如在生成诗歌的任务中,利用风格迁移的方法来生成不同风格的诗歌[1].文本风格迁移的目标是将原文本重写成其他的风格的新文本,新文本应该流畅逼真,同时保留原文本中与风格无关的其他的信息.举例来说,从Yelp 数据集中可以拿到用户对餐厅的评论,我们希望将这些评论从正面改为负面,此时文本的风格即为评论中包含的态度.对于这个任务,如果有评论的内容一一对应而态度相反的两组文本集,我们可以很容易的设计一个Seq2Seq 的模型、有监督的进行训练.然而,在大部分风格迁移的场景中,这样的数据集是缺失的,于是很多研究者选择利用没有成对句子的数据集学习文本风格迁移的模型.
在已有的文本风格迁移的研究中,绝大部分工作都认为一个文本集的风格是一个认为给定的标签,而不是从文本集中自动提取的表示.比如对于Yelp 数据集,评分大于(小于)3 的评论被认定为正面(负面)态度.从这个观点出发,一种常见的思路是学习句子与风格无关的语义表示,然后利用这个表示和另一种风格的标签恢复出句子[2-4],这实际上是假设句子包含的语义信息和风格信息是相互独立的.具体来说,这些工作利用自编码器将不同的风格的句子压缩到一个共享的语义空间,并将来自不同风格文本集的语义表示的分布进行对齐,这可以通过附加一个分类器实现,分类器试图区分出句子的域,而自编码器试图骗过这个分类器,经过对抗的训练,最终使学到的语义表示不包含风格标签的信息.
虽然上述基于对抗训练的模型可以取得一定的效果,但是正如文献[5,6]所指出,这些工作难以同时改变风格并且保留其他的语义信息.这些观察表明,由于句子中风格和语义信息是以复杂的方式混杂在一起的,独立性假设可能是不合理的.此外,基于对抗训练的方法往往收敛缓慢,非常耗时.
在本文中,对于文本的风格,我们提出了新的观点:如果可以将句子的全部语义信息压缩到一个连续空间中,则得到的向量包含了该句子全部的语义信息.那么一组句子的风格,可以被其对应语义向量的高阶统计量所捕捉.在具体的实验设置中,我们选择了协方差矩阵来捕捉文本的风格.图1中,我们将Yelp 中的评论按照对应的评分划分成小的文本集,并且分别计算其对应的协方差矩阵,然后我们对得到的四个矩阵进行特征值分解,保留了各自前50 维特征向量绘制成热力图.可以看到,随着评论态度的变化,得到的特征向量的颜色呈规律性渐变.这说明了协方差矩阵确实能够捕捉文本风格,甚至可以区分出风格的强度.

图1 Yelp 对应不同评分的文本子集的协方差矩阵
基于这一观点,我们提出了一种半监督学习的方法将句子映射到一个连续空间,使得来自不同文本集句子的连续表示是可分的.之后我们提出了一对矩阵变换的算子,将语义向量先后经过白化和风格化变换以实现风格迁移.
后文组织如下:第1 节介绍如何获得文本集中风格的表示;第2 节介绍白化-风格化迁移算法;第3 节介绍实验设置以及实验结果;第4 节进行总结各前50 维特征向量的热力图.其中R5 对应最正面的评价的文本集,R1 对应最负面的评价的文本集.
1 获取文本中的风格信息
1.1 句子的语义向量
对于句子x={x1,x2,···,xn},其中xi是词表中的单词,我们首先需要将句子嵌入到连续空间.虽然目前已有很多成熟的句嵌入算法[7,8],但是为了便于进行后续的风格迁移工作,我们需要该空间满足以下两个条件:
(1)句嵌入应该是无损的、可以被重建的.
(2)不同文本集得到向量应该是可分的.
其中第一点意味着该向量需要包含句子的全部信息,以便于我们从向量中恢复出原始的句子;第二点意味着,来自不同文本集的句子在该空间构成的分布应该尽可能不重叠.
我们首先利用映射函数E:x→z∈Rd,将句子从原始离散空间映射d维连续空间.为了满足条件(1),我们需要一个逆向的映射函数D:z→y,重建文本y={y1,y2,···,yn}满足y=x,这两组映射构成一个自编码器.由于原始文本和重建文本都是离散的序列,我们选择用常见的Seq2Seq模型[9]来实现这个自编码器.Seq2Seq 模型是一种基于循环神经网络(RNN),对于成对的序列通过最小化重建误差进行端到端训练的模型,比如机器翻译任务中,有英文和法文一一对应的训练集,就可以使用Seq2Seq模型进行训练.使用Seq2Seq 模型可以选择不同的循环单元,在本文的实验部分,我们验证了使用长短期记忆网络(LSTM),门控循环单元网络(GRU),以及双向的GRU 等都可以很好的获取文本的风格.下面我们以LSTM 为例,对自编码器的训练目标进行说明.
用作编码器的循环单元记为LSTME,第i次迭代得到的隐变量记做hi,经过下式所示编码过程,原始句子被映射为语义向量z:
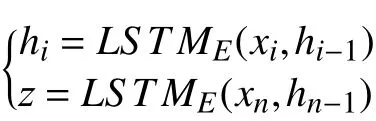
用作解码的循环单元记做LSTMD,得到的隐变量记做si:
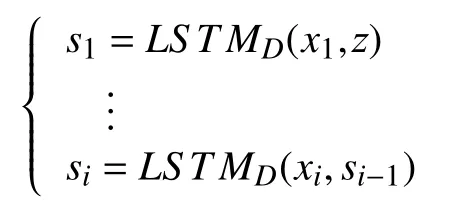
为了从隐变量预测出具体的词,可以经过一个全连接层之后再做Softmax 变换,这样就得到了词表V中各个词在当前位置i出现的概率,从这个概率中采样单词来生成句子:
其中,W1∈R|V|×d.
自编码器的目标是重建出输入的文本,可以通过最小化下式交叉熵损失函数来实现:
我们再来考虑第二个句嵌入的条件,为了使得来自不同文本集的向量的分布尽可能不重叠,可以加入一个分类器来半监督的训练.假设有两个文本集X1和X1,我们利用同一个自编码器来将两组文本映射到同一个d维空间,在这个空间中我们定义了如下分类器:
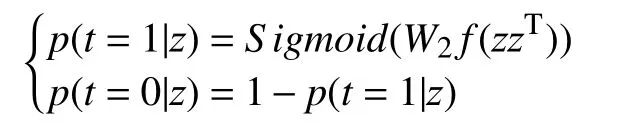
其中,f代表flatten 函数,作用是将矩阵展平成一个向量;W2∈Rd2是一个线性变换,可以产生一个标量,这个标量经过Sigmoid 函数得到一个概率值,表示该句子来自第一个文本集的可能性.我们为两个文本集的文本标定标签t为0 或1,然后利用如下目标函数进行训练:
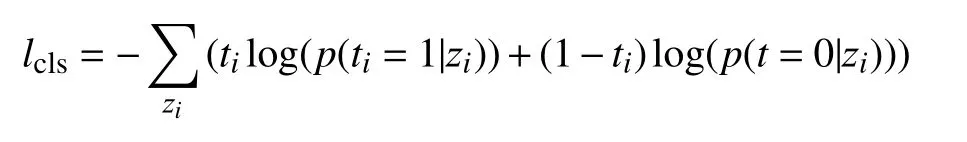
最终的训练目标为:
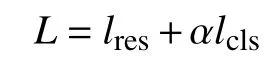
其中,α是调节两部分相对权重的超参数.
1.2 文本集的风格
在日常的生活中,人们总是可以直观感受到不同文本的风格差异.在很多语言学的文献中[10],也已经有了一些成熟的理论来描述生活中的风格现象.为了得到机器可以理解的文本风格的表示,我们先给出该表示需要满足的性质,这些性质与我们的经验是一致的.
首先,文本的风格是一种统计现象.单一句子无法形成一种“风格”,而包含多个句子的文本集中蕴含着人类可以辨别的风格.因此我们要学到的表示是对文本集整体而言的.第二,文本的风格蕴含在文本的语义中.举例来说,对于评论“The food is awful and I will not come again.”来说,如果认为情绪是一种风格,我们很难区分“not come”是句子的语义部分还是风格部分,这两部分信息往往不是相互独立的.最后,文本的风格是有不同强度的,如果将上面的句子改为“The food is so awful and I will never come again.”,尽管都是负面的评价,蕴含的情绪会比原句更强烈一点.
为了满足这些性质,我们提出了用文本集语义向量的协方差矩阵来捕捉文本的风格.对于有N个句子的文本集,假设所有语义向量构成的集合为Z=[z1,z2,···,zN]∈Rd×N,则协方差矩阵为:
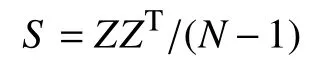
为了验证该矩阵是否能够捕捉文本的风格,我们用Yelp 数据集中评分为1、2、4、5 的评论各自构成文本集,取这4 个文本集的协方差矩阵的前50 维特征向量,进行了可视化.图1表明,我们提出的表示确实可以捕捉文本集的风格,甚至可以区分风格的强度.
2 一种无学习的风格迁移方法
为了利用我们提取的风格表示控制文本集的风格,我们提出了一种基于矩阵变换的文本风格迁移方法:如果语义向量的协方差矩阵可以代表文本集的风格,我们可以直接将另一个文本集的协方差调整至和该文本集相同,从而实现风格的“对齐”.
由于协方差矩阵是半正定的,可以进行特征值分解:
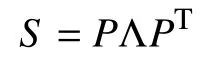
其中,Λ是由S特征值构成的对角矩阵,P是由对应的特征向量构成的正交矩阵
如果有两个文本集X1和X2,根据第1 节的方法,我们可以得到各自的风格表示S1和S2.现在想要将第二个文本集的风格迁移成和第一个文本集相同,为此我们对第二个文本集的语义向量组Z先后进行如下矩阵变换:
ZCA 白化:白化变换会拆除向量各维度之间的相关性,经过白化之后的向量协方差矩阵为单位矩阵:
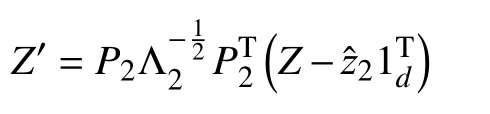
风格化:风格化是白化的逆变换,可以按照第一个文本集的风格重新建立各维度直接的相关性.
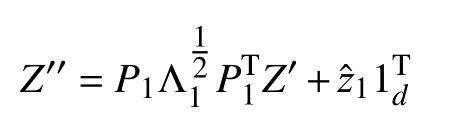
上式展示了如何将文本集X2迁移为X1的风格,反之亦然.整个迁移的过程不需要训练一个端到端的网络结构,只需要进行矩阵变换.将变换后的向量用1.1 节定义的解码器进行解码,即得到了迁移之后的句子.
整个模型结构见图2,两侧方框表示文本集,梯形框表示需要训练的网络结构,中心方框表示实现风格迁移的白化-风格化变换算子.整个算法步骤如下:
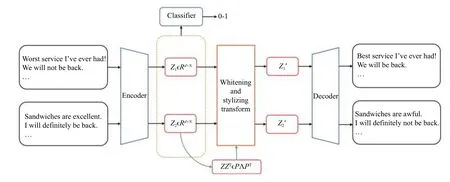
图2 无学习的风格迁移方法

算法1.白化-风格化算法(1)预训练:对于左侧情绪分别为正负的两个文本集,利用自编码器进行重建,同时在隐层语义空间中利用一个分类器半监督的训练,从而调整该空间的分布.(2)获取风格表示:预训练收敛以后,用得到的语义向量,得到两个文本集的语义协方差矩阵.(3)风格迁移:利用白化-风格化变换算子将两个文本集的语义向量进行风格迁移,迁移后的向量利用已经训练好的解码器进行解码.
3 实验
3.1 实验设置
我们使用了Yelp 数据集进行了实验,该数据集收集了Yelp 网站上用户对餐厅的评价.其中每一句评价都与一个从1 到5 的分值相关联,分值越高意味着该评价越正面.我们将该分值超过3 的作为情绪正面的文本,低于3 的作为情绪负面的文本,从而得到一组风格对立的文本集,在这一对文本集上,我们利用提出的白化-风格化算法进行风格迁移.经过上述处理的Yelp文本集的词表大小为9603,训练集中包含173000 个情绪正面的句子和26300 个情绪负面的句子,验证集中分别包括37 614 和24 849 个句子,测试集分别包括76392和50278 个句子.
我们使用了以下两个基于对抗训练的基线模型:
CrossAligned[3]:该模型假设不同风格的文本集存在一个共享的、与风格无关的语义空间,该模型通过对抗的训练来对齐不同文本集在这个空间的分布,以达到去除风格信息的目的.
StyleEmbedding[2]:该模型显式地学习了不同风格的嵌入,将风格嵌入和语义向量一起作为解码器的输入,从而对于多种风格,只需要一个自编码器.
本文使用了以下两个指标来评估模型在不成对文本风格迁移上的表现:
Accuracy:为了评估生成的文本是否符合预期的风格,我们首先在训练集上预训练了一个文本风格的分类器,该分类器使用TextCNN 模型[11],在测试集上的分类准确率可达到97.23%.我们用该分类器对迁移之后的文本的分类准确率作为评估指标,也就是说,迁移之后的文本越多可以“骗过”风格分类器,在这一指标的表现越好.
BLEU:为了评估生成的文本在改变了风格的同时是否保留了源文本的内容信息,我们以源文本为参考文本计算了累积4-gramBLEU 值.BLEU 越高,意味着和源文本更加相似.
正如文献[5,6]提出的,这两个指标之间往往呈负相关.直观来看,成功的改变句子的风格会不可避免的降低BLEU 值.所以我们需要一个综合指标来判断模型的效果,由于两个指标的区间相同,我们简单的取均值来评估,其他的综合评估的方法留待之后的工作探索.
我们还考察了不同模型的效率,用不同模型的训练时间来评判.所有实验都在同一个Linux 服务器上运行,该服务器搭载Ubuntu 16.04 系统,使用Intel theanoXeon E5-2620 v4 的32 核处理器和两块NVIDIA GeForce GTX 1080 显卡.
3.2 实验结果
我们先使用CBOW 算法[12]将词表嵌入到一个300维的连续空间中,然后固定学到的词嵌入,利用我们提出的白化-风格化迁移算法在多种循环单元上进行了实验.用到的网络结构包括300 维的LSTM(WSLSTM),300 维的GRU(WS-GRU),以及两个方向各150 维的双向GRU(WS-BiGRU),我们也实验了引入了注意力机制的效果(WS-attention).对所有的结构,在预训练阶段超参数 α都设置为1,训练50 个epochs,此外我们还设置了一个没有监督信息的对照组(WSunsupervised),超参 α设置为0;在之后的阶段,除了LSTM 拼接了隐层状态和单元状态得到了600 维的语义向量,其他结构都使用300 维的隐层状态作为句子的语义向量.
将基线模型和基于不同结构的白化-风格化算法的表现展示为图3.可以看到本文设置的对照组WS-unsupervised 在保留语义内容上效果特别好,但是风格迁移的能力较差,这是因为在预训练阶段没有引入风格类别的监督信号,这样学到的语义空间不满足我们提出的第二个条件,不同文本集得到语义向量不可分.在引入了监督信号后,Accuracy 得到的巨大的提高,同时BLEU 值有所下降,综合表现优于WS-unsupervised.注意到,此时各种网络结构下我们的模型都是优于两个基线模型的,除了WS-attention,这是因为引入注意力机制后,得到的语义空间不满足我们提出的第一个条件,语义信息不是无损的嵌入到这个空间里,很多信息是由编码器直接提供给了解码器.
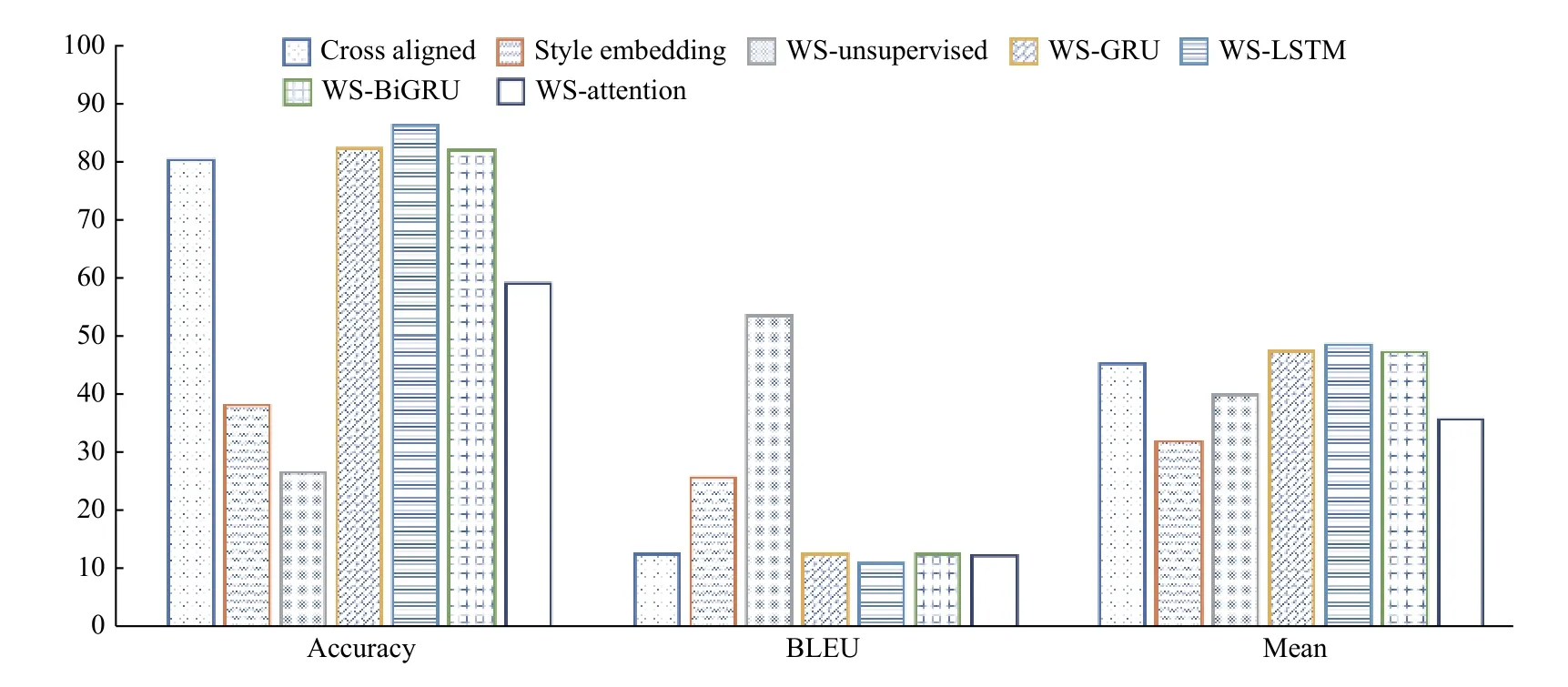
图3 实验结果
表1展示了不同模型训练到收敛的时间,可以看到,我们的模型只在预训练阶段需要端到端的学习一个自编码器,风格迁移的阶段是不需要学习的,整体效率远远高于基于对抗训练的基线模型.
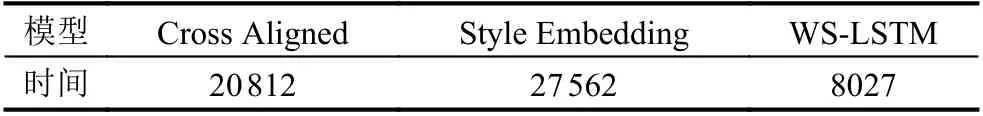
表1 不同模型的训练时间(单位:s)
4 结语
本文提出了一种从文本集中提取风格信息的方法,即将句子嵌入到连续的语义空间,利用这些语义向量的协方差矩阵来捕捉风格.利用提取到的风格表示,我们进一步提出了一种基于矩阵变换的风格迁移方法,即白化-风格化算法.实验表明,该算法的效率远远高于基线模型,同时迁移的效果也更好.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
野生动物学报(2022年3期)2022-08-11
野生动物学报(2022年1期)2022-02-24
数学学习与研究(2018年3期)2018-03-14
考试周刊(2016年54期)2016-07-18
现代电子技术(2015年10期)2015-05-29
长江学术(2015年1期)2015-02-27
