
基于面部动作编码系统的表情生成对抗网络
2020-09-15 04:47胡晓瑞林璟怡
计算机工程与应用 2020年18期
胡晓瑞,林璟怡,李 东,章 云
广东工业大学 自动化学院,广州 510000
1 引言
人类面部信息的提取和分析在计算机视觉领域有着非常广泛的应用,例如常见的人脸表情识别[1]、人脸检测[2]、身份识别[3]、带属性条件的人脸图片生成[4]等任务。随着生成对抗网络[5]的提出,人脸图像生成的相关研究日益增多,例如Bulat等人[6]提出利用图像退化学习过程的思想实现人脸超分辨任务,对于输入单张低分辨率人脸图片生成对应的高分辨率图片;Song等人[7]利用人脸几何信息来辅助人脸补全的模型对人脸图像缺失部位进行以假乱真的图像补全与修复;He等人[8]提出一种面部属性编辑生成网络,通过控制表示不同的,如发色、性别、年龄等面部属性的一维向量,从而在不改变原图人物其他身份纹理信息的情况下生成对应的符合条件属性的人脸图像;除此之外,人脸面部表情的感知是除语言交流外重要的核心信息,Choi等人[9]提出的StarGAN网络基于RaFD数据集[10],生成了由伤心、愤怒、厌恶、开心等8个二值标签控制的人脸表情图像。
但是,目前人脸图像的表情类别标签往往都采用较为单一的常见8种表情,这对于表情丰富的人脸来说是远远不够的,尤其是自发产生的微表情更是需要一个更好的表情编码方式。由于面部表情是面部各个肌肉联合和协调行动的结果,瑞典解剖学家卡尔赫尔曼基于心理学和生物学开发出一套面部动作编码系统(Facial Action Coding System,FACS)[11],这是一种以人脸面部各个肌肉群作为动作单元(Action Units,AUs)对其不同运动类别进行编码分类的系统,通过将面部不同肌肉群标记为30个AU模块,且每个模块激活程度分为5个幅度等级,从而利用7 000 多种不同的AU 组合表示不同的人脸面部表情,例如人类愤怒的表情主要有如下几个动作单元激活产生:眉毛下垂(AU4)、上眼睑提升(AU5)、眼睑收紧(AU7)、下颚下垂(AU26)[12]。根据每个动作单元对应肌肉收缩程度大小,对应相应标注编码幅值的大小,从而该面部单元组合的表情会相对传递一定程度的愤怒表情。
本文基于面部动作表情编码系统提出了一种创新的人脸表情合成方法,通过控制表示不同面部动作单元激活程度的一维目标条件向量,对输入的单张人脸图像,在保持图中人物信息和其他部分不变的情况下,只改变目标条件向量对应部位纹理,生成与目标表情编码一致的人脸图像。本文还提出一种新的网络结构,利用编码解码模块实现生成对抗网络,同时解码模块通过融合注意力机制[13],可以让网络在训练过程中更好地关注每个动作单元对应的面部位置,此外本文设计了一种可以更好指导人脸表情生成的目标函数,在BP4D人脸数据集上获得了较为真实的人脸表情生成图像。
2 基于面部动作编码系统的人脸表情生成对抗网络
主要介绍基于面部动作编码系统的人脸表情生成对抗网络的网络结构和原理。如图1所示,网络主要分为编码器Genc和解码器Gdec组成的生成模块,以及图2判别器D和分类器C组成的判别模块。假设输入的RGB人脸图像为Ia∈ℝH×W×3,其对应的表示N个AU是否激活的二值一维AU属性标签向量为a=(a1,a2,…,aN)T,将原图的标签向量a编辑为目标AU 属性标签向量b=(b1,b2,…,bN)T,经过生成模块处理后可输出一张符合属性b的编辑图像Ib∈ℝH×W×3。下面将详细介绍网络架构和训练过程。
2.1 融合注意力机制的生成模块
在生成模块中,给定带有AU属性标签向量a的人脸表情图像Ia,将Ia输入到编码器Genc中,得到隐含特征向量z,编码器结构采用文献[8]中的网络结构,用公式可表示为:
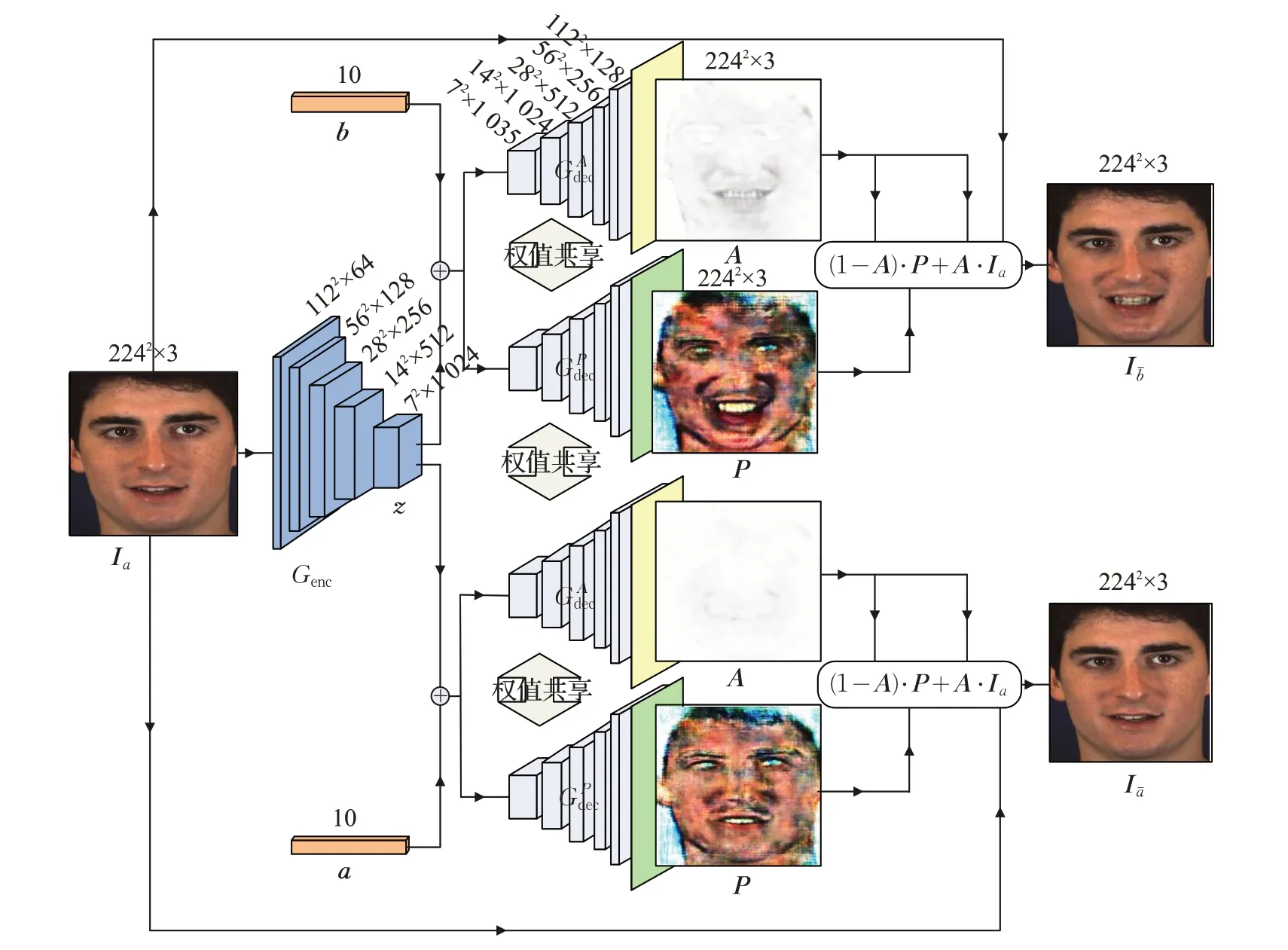
图1 生成模块网络架构
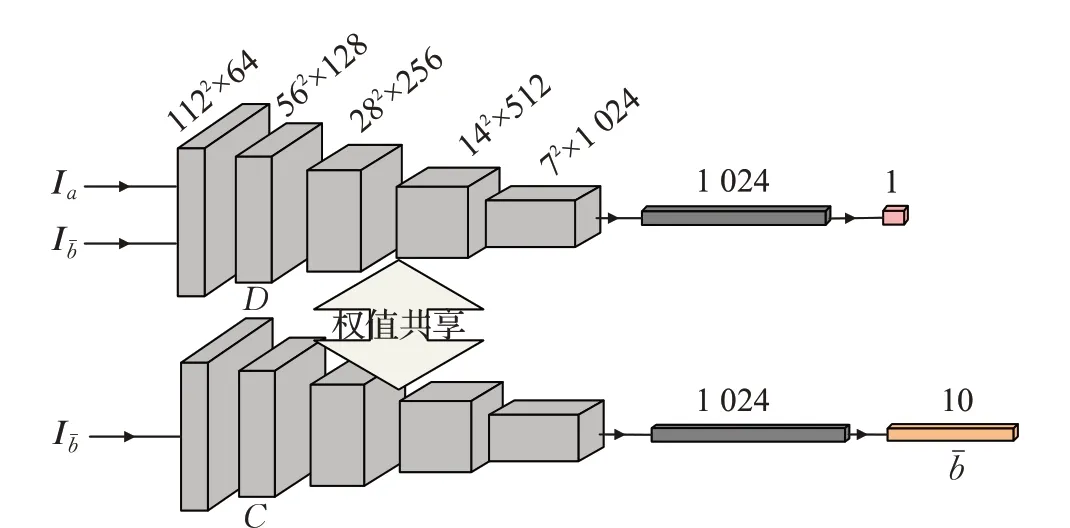
图2 判别模块网络架构

其次,利用解码器Gdec将隐含特征向量z和目标AU标签向量解码为输出图像Ibˉ,所得Ibˉ即为符合目标AU 标签属性向量b的人脸表情图像,且该生成图像保留与原标签相比未发生变化的AU 标签对应的原图像人脸区域和身份信息不变。可表示为:

从上述生成网络结构来看,编码器的目的在于用隐含特征向量z学习到图片中充足的信息细节,从而使得当z和AU属性标签向量送入解码器时,z用来提供原图充足的信息,而AU属性标签向量用于表情图像生成条件的控制。换言之,如果编码器输入的是z和原图像AU属性标签向量,那么最终生成的图像Iaˉ应该尽可能近似于原图,即表示为:
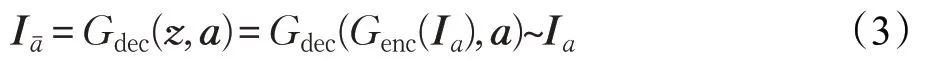
除此之外,为了更好地使得生成图像尽可能地保留原图的人物身份信息,本文的解码器融合了文献[13]中的注意力机制,使生成网络只针对有改变的AU标签对应的人脸图像区域进行编辑生成,可以学习到如何重点关注每个AU 编码对应的人脸区域,仅修改该AU 对应区域,保留原图其他区域,如图1所示,解码器Gdec分为解码出注意力特征图A的,和解码出纹理特征图P的除最后一层外权值共享。最终,将注意力特征图A和纹理特征图P按如下公式生成输出图像Ibˉ:

其中,符号⊕表示注意力特征图A和纹理特征图P结合为最终输出图像,符号·表示特征图矩阵元素对应点乘,符号+、-表示特征图矩阵元素对应加减。最终输出的生成图像Ibˉ既符合目标AU属性标签向量b,同时保留未编辑AU标签对应区域信息不改变,从而达到控制人物特定表情图像生成的目的。
2.2 判别模块
本文的判别模块主要包括判别器和分类器,判别器和分类器除最后一层外其他层权值共享,不同之处为分类器最后一层为N维全连接层,而判别器最后一层为单个神经元作为判断生成图像是否真实的概率值输出。其目的在于,与传统的生成对抗网络相比,需要所生成的最终人脸表情图像符合对应的AU 标签属性向量,换言之,将生成图像或原图像送入分类器中得到的标签应尽可能近似于b:

2.3 目标函数
2.3.1 对抗损失
本文生成对抗损失采用WGAN[14]中的损失函数,相比于原始GAN所用的KL散度、JS散度容易导致梯度消失或者模式崩塌问题,WGAN使用了平滑的Wasserstein距离,可有利于生成模型的训练和生成结果的多样性:
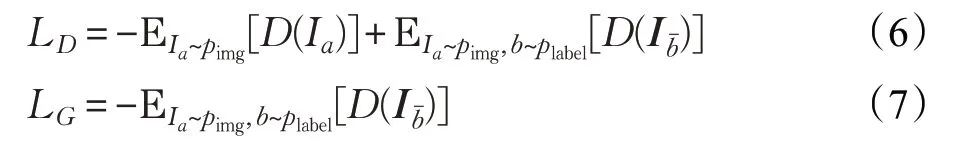
其中,pimg表示真实图像分布plabel表示真实AU标签分布。公式(6)和公式(7)中D( )表示对输入的人脸表情图像Ia或对输出图像Ibˉ的判别概率。生成网络的目标是尽可能生成真实性高的图片去欺骗判别网络。而判别网络的目标是尽可能将生成的图片和真实的图片分别开来,即构成了一个动态博弈过程。
2.3.2 重构损失
重构损失主要用于保证隐含特征向量z保留原图像中充足的信息细节,根据公式(3)可知,当编码器的输入为原图像AU属性标签向量,可使用l1损失表示最终生成的图像和原图的距离,当该距离越小,则说明两幅图越相似,利用l1损失构造重构损失用公式可记为:
2.3.3 注意力损失
注意力特征图在训练过程中往往会出现全部趋向于最大值的问题,从而失去根据关注程度调节权重大小的作用,为了解决这一问题并且使得注意力特征图A中的元素在训练过程中更平滑更关注小区域信息[15-16],利用对A计算矩阵向右和向下分别平移一个像素的差方值和第二范数,构建注意力损失,使得注意力特征图更平滑:

其中,Ai,j表示矩阵A的第i行第j列元素。λatten是用于平衡损失的超参数。
2.3.4 分类损失
如前所阐述,利用分类器C对生成图像或原图进行分类,可指导生成模块所生成图像更符合对应的AU属性标签向量。分类损失可用二值交叉熵损失表示分类器的分类结果与标签的差距,交叉熵越小,则分类效果越好,越能指导生成网络生成符合目标条件向量的表情图像:

将对抗损失、重构损失、注意力损失和分类损失相结合,可指导网络实现给定任意目标AU 属性标签,可将原图转化生成对应符合标签的表情图像的任务。对于编码器和生成器,目标函数可表示为:

对于分类器和判别器,目标函数可表示为:

其中,λ1、λ2、λ3、λ4是用于平衡损失的超参数。通过公式(12)和公式(13)的最小化过程,即为对编码器、生成器、分类器和判别器的优化训练过程,最后训练最优得到的生成模块即能根据输入的目标条件向量生成符合条件的人脸表情图像。
3 实验与分析
3.1 实验细节与数据预处理
所提出的网络架构是在文献[8]的基础上进行改进的,新添加了注意力机制并设计了一个符合人脸表情动作编码特征的损失函数。同时也将原网络的属性编辑任务应用到人脸表情生成任务中,并与本文结果相对比。其中,网路输入图像大小为224×224,批量大小为32,学习率为 0.000 2,λ1=50,λ2=0.01,λ3=20,λ4=1,λatten=0.000 1,采用Adam优化[17](β1=0.5,β2=0.999)。
算法采用的数据为常用BP4D 人脸数据集[18],共计23名女性和18名男性青年参与了视频数据采集。每个被测试者参与8 次实验,共计328 个视频。每个视频中有效的具有AU 标注的视频帧数量从几百到数千不等。大约14 万张带有AUs标签的图像可供使用。但是,实验过程中发现原数据集标注的AUs标签主观性较大,且无论对应肌肉激活位移幅度多大都用0/1 两种激活或被激活状态标注,无法区分AU对应激活肌肉的位移幅度大小,且每个AU 分布出现频率不一,差距较大,不利于网络训练。所以本文采用MTCNN[2]先对BP4D数据集图像进行人脸区域裁剪,再利用Openface[19]对图像重新进行AUs标注,标注结果用0~5表示每个AU的激活幅度,最后根据表1中每个AU的幅度阈值TAUi进行数据均衡,大于TAUi的记为激活状态1,小于TAUi的标注记为非激活状态0,从而每幅图对应得到一个新的人脸表情动作编码二值向量,表1 第二行展示了每个AU进行数据均衡后分别的正样本数量NAUi,最终从中随机采样20 000张作为训练集。
3.2 单个AU属性标签控制
图3 展示的是通过对数据均衡后的原属性标签向量a中某单个标签置1,其他标签不变得到b,并最终得到各个不同AU 对应表情图像生成Ibˉ的结果。第一列为原图像Ia,第二列为重构图像Iaˉ,第三至第十二列为各个AU标签对应生成图像。

表1 AU的阈值与正样本个数

图3 单个AU属性标签控制下的表情图像生成结果
其中,第a1和a2行展示的是根据公式(4)和文献[13]将注意力特征图A和纹理特征图P结合得到表情生成图像。从图中可以看出,网络已经学到了对于注意力特征图A中颜色较暗的区域为AU关注的区域,而较亮部分为保留原图像纹理。例如,AU1、AU2、AU4、AU7、AU45主要关注眉毛和眼部区域变化;AU9关注鼻翼和脸颊部位变化;AU12到AU26主要关注嘴巴部位变化。通过注意力特征图,网络可以对原图像对应的每个区域逐像素学习到是否需要按照一定权重保留或者改变,只有与AU 标签相关的区域才会重点进行图像生成,其他无关区域基本维持原图纹理不变,从而使得最终的生成图像更好地满足目标属性标签向量。
3.3 连续性AU标签值控制
网络训练时,AU 属性标签向量为0 或1 的二值标签。由于网络结构中,通过目标标签向量b控制注意力特征图A和纹理特征图P结合生成最终表情生成图像Ibˉ,且不同强度的AU属性标签值(标签值范围为0至1)可以控制最终的生成结果,连续性的AU属性标签值控制生成不同AU 编辑程度的图像。如图4 所示,列举了不同AU 标签值:0,0.25,0.50,0.75,1 对应的生成结果。可以看出,同一行AU标签值较小的生成结果图像对应改变人脸部位的表情幅度较小,AU 标签值较大的生成图像表情幅度较大。结果表明,本网络可达到一个使用连续AU 属性标签值大小控制生成图像表情幅度强弱的良好效果。
3.4 细节与性能对比
所提出的网络架构是在AttGAN[8]网络框架的基础上进行优化改进。若将AttGAN网络架构不变,把原属性编辑任务直接修改至人脸表情生成任务中,训练后与本文实验结果相对比,对于基于面部动作编码系统的人脸表情生成任务来说,例如图5所示,第一行表示AttGAN生成结果,第二行表示本文生成结果,可发现虽然对于部分表示嘴巴脸颊等表情变化幅度较大区域的AU 标签来说,如 AU9、AU12、AU15、AU26对应两种方法得到的表情生成结果十分相近,本文所提方法具有更好的局部细节编辑能力,但是AttGAN 在局部细节上较为欠缺,尤其是例如眼部、眉毛这种局部细微模块很难学习到如何编辑改变。

图4 连续性AU标签值控制下的表情图像生成结果
具体为:(1)图5中如 AU1、AU2主要描述眉毛内测上移和眉毛外侧上扬眼部微瞪的肌肉移动行为,AttGAN的结果基本没有学习到这一变化,与原图相比没有发生明显修改;但是本文所提方法根据目标AU成功生成良好结果,第三列中眉毛内测上移,且额头会产生皱纹,第四列中眼眶变大显示微瞪,符合目标条件向量。(2)如AU4和AU7分别为皱眉和下眼睑上移眯眼,AttGAN的两幅图像生成结果难以分辨出两者差别表现不佳,但本文方法由于注意力机制可以更好地关注局部细节从而生成结果的针对性细节修改较为明显,实现了眉心的明显褶皱和眼睛的眯起缩小。(3)将第二列重构图中绿色和红色方框区域放大至图6 所示,可看出,本文所提方法重构结果牙齿边缘清晰,胡须细节不发生变化,无明显模糊,睫毛和黑色点痣保持与原图基本一致,而AttGAN结果相对模糊,牙齿处有局部修改,黑色点痣与毛发不清晰,与原图相比,AttGAN 的重构图有明显更大的差距。所以本文所提方法可以很好地保持无变动AU 标签对应的不需要改变位置区域的原图信息,使得真实性更高。

图5 AttGAN与所提方法结果对比

图7 AttGAN与所提方法在不同肤色图像下的生成结果

图6 AttGAN与所提方法局部细节图
根据对比结果还发现,如图7 所示,本文方法在肤色较深的人脸图像生成结果上也保持了更好的表现,如对于AU1标签,即使肤色较深也成功实现了眉毛内侧上移,AU4和AU7分别列举了肤色不同的人脸情况下,本文所提的方法结果都优于AttGAN,实现了皱眉和下眼睑收缩的表情生成。除此之外,有时AttGAN无法对一些基于局部的面部动作单元进行正确修改,例如AU25对深肤色的嘴部牙齿生成和AU45对眼部闭合有时会无法达到目标效果。
综上所述,本文所提出的网络结构对于基于面部动作编码系统的人脸表情生成任务来说比AttGAN 在细节上更具有细腻性和真实性,在细节上的关注与更好的局部细节编辑能力比起以往方法更适用于微表情任务,解决了现存方法中大都关注图像整体的表情生成类别,而忽视局部细节微表情的生成效果这一问题,具有一定研究价值。
4 结束语
面部动作编码系统是一种以人类面部各个肌肉群作为动作单元对其不同运动类别进行编码分类从而描述人脸表情的系统,本文提出一种融合了注意力机制的编码解码生成对抗网络,以表示面部各个动作单元激活状态的一维向量作为属性控制条件,对输入的人脸图像进行表情控制,用一种新的目标函数最终指导生成符合目标属性的人脸表情图像。使用BP4D 数据集进行实验,与AttGAN 相比,所提出的网络可以更好地关注每个动作单元对应的面部位置、身份信息和局部图像细节保留更完整,真实性更高,证明了本文方法的有效性和先进性。本文未来研究工作主要是提高生成图像的分辨率实现高清人脸表情图像生成和困难人脸图像样本的表情生成,以及利用表情生成网络提高人脸微表情识别准确率。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
孩子(2019年5期)2019-05-20
动漫星空(2018年9期)2018-10-26
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
读者(2018年6期)2018-03-01
数位时尚(幼儿教育)(2017年12期)2018-01-05
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
