
轻量级目标识别深度神经网络及其应用
2020-09-15 04:47付佐毅周世杰李顶根
计算机工程与应用 2020年18期
付佐毅,周世杰,李顶根
1.华中科技大学 能源与动力工程学院,武汉 430074
2.华中科技大学 中欧清洁与可再生能源学院,武汉 430074
1 引言
近年来,深度卷积神经网络成为计算机视觉的主流技术手段,正在被广泛应用到各个领域。然而深度学习模型所设计和使用的神经网络通常是为了追求性能而忽略模型的体积和速度[1]。在将目标识别深度神经网络应用到各领域时,视觉目标识别的各个功能模块对神经网络的速度要求非常高,一些业界领先的深度神经网络并不能达到这种要求。RCNN 系列网络模型(包括fast RCNN,faster RCNN)[2-4]不断将识别的准确率进行了提升,但都对帧速度没有做很大的关注(帧速值较低)。Liu等人[5]提出的SSD模型具有较高的识别准确率(74%map)以及帧速(TitanX GPU 上为59 帧/s),但没有考虑模型的体积问题。YOLO[6-8]系列网络模型在具备较高的识别准确率的同时达到了较高的帧速(70 帧/s 左右,在不同的数据集有不同的表现),但没有考虑网络模型的体积问题。吴进等[9]设计了一种紧凑型卷积神经网络,使用多个小型卷积层,减少了网络的参数量并得到较高的准确率。本文使用轻量化措施设计一种轻量级的深度卷积网络,并将其应用到智能驾驶领域。轻量级深度卷积神经网络具有在保证准确率的前提下,内存占用小、模型体积小、运算速度快等特点,适合应用于智能驾驶的目标感知。
2 轻量化深度卷积神经网络的结构设计
在智能驾驶汽车的检测系统中,目标检测需要使用车上摄像头捕获汽车周围环境,识别出障碍物,并利用雷达等传感器确认障碍物的空间,然后路径规划决策系统再给出合理的路径,使得智能驾驶汽车在行驶中绕开障碍物。受限于硬件性能和实时性等因素,在智能驾驶系统中使用的深度学习模型的体积不能太大,推理速度也不能太慢。所以此次设计方案设计的模型体积不能太大,推理速度必须足够快。本文在设计网络时采用单次检测器的设计方式。
目标检测网络按照功能可分为两个子网络,一个是主干网络(另称backbone),主要功能是提取图像特征;另一个是检测网络(另称fronthead),主要功能是从主干网络提取的特征中提取目标的坐标框和类别置信度。
在本文中,主干网络自行设计,利用一系列轻量化措施设计轻量级的网络;检测网络前端获取预测坐标和置信度部分主要参照SSD网络[5],充分利用卷积神经网络不同尺度的信息。
2.1 Backbone
卷积神经网络中存在大量的参数,前向推理时涉及大量的运算。其中,全连接层包含大量的参数,计算量相对于其参数量比较小;池化层不包含参数,由于池化层通常用来降低特征图分辨率,在网络中使用的数目不多,所以运算量相对比较小;卷积神经网络的运算量主要集中在卷积层。为了使网络体积变小,应当少使用全连接层,使用小尺寸卷积核。为了提升模型速度,应当降低模型的运算量。网络的运算量除了与卷积核本身相关外,还与输入特征图的尺寸相关,在单层卷积运算中,特征图尺寸减半,运算量将降低至原来的1/4。
全连接层占有大量参数,训练时容易过拟合,且包含全连接层的网络对数据输入尺寸敏感;另外,相关研究表明,去掉部分全连接层,对模型的准确率影响不大。所以在设计的网络中,不使用全连接层。
卷积层提取特征时会产生大量运算,为了降低模型的运算量,在网络的前几层充分降低特征图的分辨率尺寸,然后在小尺寸特征图上进行大量卷积操作,来避免模型运算量过多。
在网络中,包含有大量的模型参数设置,为了便于设计,设计几个简单的最简模块,然后使用这些模块堆叠得到最终模型。设计的基本卷积模块见图1。在图中,左图为对特征图进行不变分辨率提取特征,即特征图通过卷积模型后,特征图尺寸和深度都不发生变化。右图为对特征图进行下采样,经过下采样后,特征的尺寸减半,通道数加倍。

图1 降采样模块和不变分辨率模块
不变分辨采样模块中使用残差连接[10]来提升模型性能和加速训练过程,并且使用深度分离卷积来降低参数量和运算量;另外,还使用1×1卷积调整数据通道数,控制运算规模。在下采样模块中,同样使用深度分离卷积[11]和1×1卷积控制数据维度,与不变分辨率模块不同的是,模块输入和输出的特征图分辨率发生了变化,不能简单地使用残差连接,所以使用卷积来替代原有的残差连接,以控制数据分辨率。
主干网络设计如表1。在表中,Output Size表示数据经过每个卷积模块后的分辨率,Output Channel表示数据的通道数;Stride表示卷积或池化的滑动步长,步长为1 表示经过该层后数据分辨率不变,步长为2 表示数据经过该层后分辨率减半。Repeat 表示该模块的堆叠次数,只有不变分辨率卷积模块的Repeat次数不是1,在网络中,通过控制模块重复次数来控制网络的参数规模。

表1 网络结构示意表
在主干网络中,接近输入端的几个卷积、池化和下采样单元直接使特征图分辨率下降到输入图像的1/8左右,充分降低了特征图的分辨率,也预先降低了模型的运算量规模。降低特征图尺寸后,进入每个分辨率前,首先使用下采样模块降低数据的分辨率,然后使用多个堆叠的不变分辨率卷积模块提取特征。在网络中,设计好不变分辨率卷积模块和下采样模块后,模型中的超参数仅包括每个分辨率中模块的堆叠次数,输出通道数等少量参数。
2.2 Front-head
在检测部分需要将主干网络提取的特征转化为预测的类别置信度和坐标框。在这部分,主要参照SSD网络结构,将多个分辨率的特征纳入转换范围中(见图2)。选取分辨率列表中每个分辨率的最后一个输出进行转换。假定某一层的分辨率为M×M。网络为特征图上每个特征像素点设置一系列预设目标包围框,这些包围框以该像素为中心,拥有不同的高宽比,预设目标数目和长宽比另设超参数,通常称这些包围框为default box或anchor box。网络在预测时,预测与这些预设目标一一对应的可能类别和偏置。将预测坐标问题转化为预测与预设包围框的偏置问题。
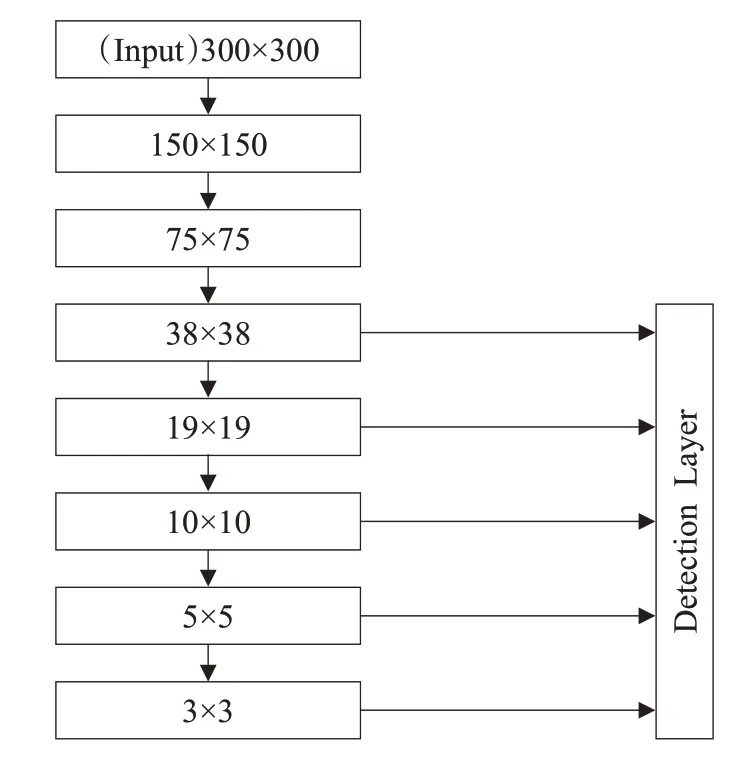
图2 目标检测网络中的坐标提取示意图
网络每个阶段的数据分辨率用N×N来表示,网络一共进行了7 次下采样,其中,只有第二次使用池化层进行,其余地方均用滑动步长为2 的卷积来完成,这是为了避免过多的使用池化层,造成小目标信息丢失的问题。
网络在预测时,使用one hot编码处理类别信息;预测目标包围盒时,预测包围框与预设目标框之间的偏置。图中每条连接的实际意义见图。每个转换包含有对目标类别的预测和坐标框偏置的预测。由于检测时使用了多个分辨率的特征图,在训练时,图像特征相当于以不同的尺度被检测器训练,可看作同时完成了多尺度训练。
如图3所示,每个坐标转换分支使用两个卷积来完成,一个是类别置信度卷积,另一个是物体坐标卷积。图中,M×M×C某个特征图的分辨率;mbox表示该分辨率的特征图中使用的不同长宽比的anchor box 的数目;Ncls表示数据集中包含的类别数目。类别置信度卷积的输出通道数由训练数据集的类别数目和该分辨率特征图使用的不同长宽比的anchor box 数目共同决定;位置坐标卷积的输出通道数由该分辨率特征图使用的anchor box数目决定。

图3 每个坐标转换分支的实际过程
2.3 损失函数
在训练时,首先要判定每个预测是否正确,然后依此训练检测器,判定过程称为匹配。在训练阶段,网络首先寻找与每个anchor box的IoU最大的标签目标(IoU阈值通常设置为0.5)。如果一个anchor box 找到了匹配的标签目标,则该default box 就是正样本,该anchor box 的类别就是该ground truth 的类别,如果没有找到,该anchor box就是负样本。匹配完成后,获得每个预测的正确性,然后就可以计算损失函数,利用反向传播算法进行训练。本文中损失函数与SSD相似,公式如下:

损失函数包含两部分,一部分是分类预测损失,另一部分是坐标预测损失。假定预测坐标框为l,真实坐标框为g;将预测的坐标框转换为中心宽高表示方式,即每个坐标框用(cx,cy,w,h)表示。式中各项参数计算公式见表。其中,Pos 和Neg 分别表示匹配后的正样本和负样本。在训练时,类别损失使用交叉熵函数。坐标预测损失使用Smooth L1函数,计算预测坐标和真实坐标的偏差时,为了避免差值过大造成损失函数出现大波动,中心坐标归一化到0~1 区间;宽高使用对数函数进行归一化。α的取值一般为1,但在一些特定的实验中,会进行另外设置。
3 剪枝
视觉识别模型设计好后,可以使用剪枝方法进一步优化网络内部结构,压缩模型体积和运算量,提升模型运行速度。本章中主要采用结构化剪枝,为了便于实验和分析,将主干网络在CIFAR10和CIFAR100数据集上进行训练和剪枝,再将剪枝得到的网络用到视觉识别任务中。
剪枝的核心任务是衡量卷积核对最终结果的重要性。在本文中,主要针对网络中卷积核尺寸为3×3的卷积层进行分析和裁剪,裁剪完成后,调整特征提取模块内其他层的通道数来匹配剪枝结果。主要利用卷积层后的Batch Normalization 内的训练参数来评估卷积核的重要性。
Batch Normalization层[12]主要作用是防止数据分布在多层之间发生偏移,主要方法是将数据的分布重新归一化到均值为0方差为1的分布。为了维持模型的表达能力,给归一化的数据赋予偏置β和系数γ。
Batch Normalization层的前向计算过程为:

其中,xi为BN 层输入数据,yi为BN 层输出数据,BN层在计算参数的均值和方差后,然后对数据进行归一化,为了提升模型的非线性拟合能力,引入参数γ和β。
在BN层中,γ和β都是训练参数,经过训练后,每个BN 层的γ和β都有具体的值,由于网络中BN 层和卷积层通常一一对应,那么训练得到的系数γ就可以大致表示对应卷积核的重要性。γ越大,该卷积核对输出结果贡献越大;因此,可以通过分析BN层中的γ参数来剔除不重要的卷积核。
3.1 网络剪枝配置
对于要剪枝的主干网络,为了便于分析,移除多余的BN层,只有3×3卷积后才配置卷积层;由于CIFAR数据集中图像的分辨率只有32×32,不能进行过多的降采样,所以只对主干网络中的Feature 3 以前的阶段纳入剪枝网络的范围。在网络的末端,加入一个卷积层、ReShape层和全连接层,卷积层的主要作用是降低数据通道数,防止全连接层参数过多;Reshape层是为了变化数据维度,便于进行全连接。剪枝网络的结构示意见表2。
3.2 剪枝训练集剪枝结果
获得剪枝网络结构后,将网络在CIFAR-100数据集上进行训练。训练时,batchsize 设置为64,初始学习速率设置为1,使用SGD 优化器控制权重参数更新,训练的总epoch 数为160。在训练轮数的50%和75%处,将学习速率减半。在训练时,对数据进行的增强处理和预处理包括随机缩放裁剪、随机水平翻转及归一化等。
训练完成后,分析网络中的每个BN 层的参数。将每个BN层的γ参数按照绝对值进行排序,然后按照设定好预定剪枝比例获得边界值,参数γ低于边界值的卷积核不纳入剪枝后的网络。剪枝后网络中3×3 卷积层的卷积核数目见表3。在表中,layer 为每个层的索引值,对应该层在网络中的深度;before 为初始的网络结构设计;rate表示剪枝比例,表中后三列表示剪枝后每个卷积层应该保留的卷积核数目。

表2 剪枝网络结构表
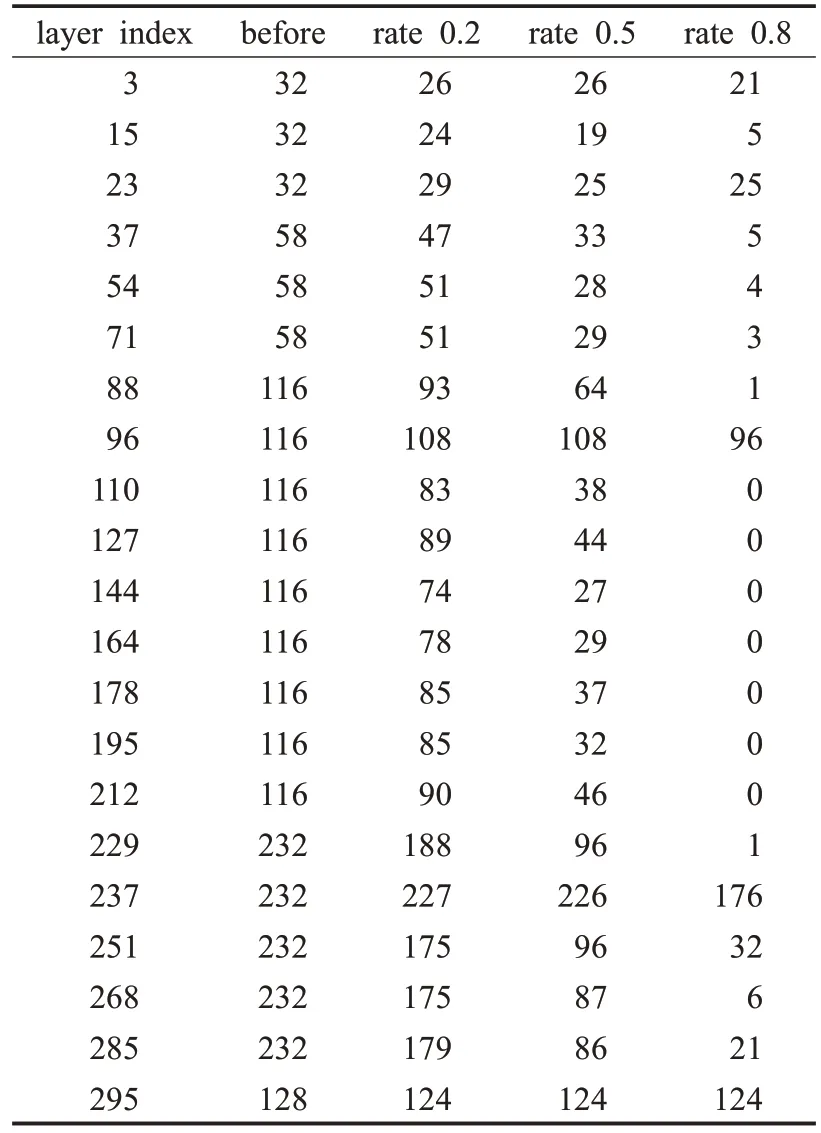
表3 剪枝后每个卷积层的卷积核数目
从表3可知,网络的头部和末端的卷积层的重要性更大,中间层次之;在每个分辨率阶段,第一个特征提取层更重要,降分辨率采样层次之,后面的其余特征提取模块重要性更低。剪枝比例很大的时候会急剧减小模型的体积,但同时会使得识别准确率降低很多,因此在保证识别准确率的同时要尽量提高剪枝比例。剪枝实验表明在剪枝比例为0.5 的时候,保证了较高的识别率的同时模型体积较小,若再增大剪枝比例,识别准确率将急剧减小。因此在后续训练中,使用剪枝比例为0.5的模型进行训练。
4 智能驾驶视觉目标识别的样本训练
4.1 数据集
本章模型训练所使用的图片来自VOC 2007、VOC 2012、Udacity 和 KITTI 等数据集中的目标检测部分[13],以此创建数据集(为方便,下文统称KITTI数据集)。为了便于训练和评估模型性能,统一将数据转换为VOC格式,并使用VOC 的评估方式,模型的评估指标mAP。另外,Udacity 和KITTI 两个数据集要么没有给出测试集,要么没有给出测试集的标签;处理方法是将所有的带标签图像按照6∶4的比例划分训练集和测试集。
4.2 数据预处理
在网络中,包含有大量的参数,需要使用大量数据进行训练,否则容易过拟合。数据集的采集和标注成本限制了数据集的规模,而数据增强技术能够以极小的成本丰富数据集,有效防止过拟合。数据增强一方面能够以极小成本增加训练的数据量,提升了模型的泛化能力;另一方面,数据增强给图像增加了噪声数据,提高了模型的鲁棒性。实验中使用的数据增强方法包括光学畸变、水平翻转、平移等。
虽然设计的模型没有使用全连接层,对输入尺寸并不敏感,但是,为了便于批量运算,送入网络的图像尺寸需要统一。在实验中,首先对图像进行数据增强变换,然后将数据增强后的图像缩放至300×300,并对数据做去均值处理。
4.3 训练环境
实验中使用的硬件环境见表4。其中至强CPU 共有两块,每块有 8 个核心,16 个逻辑处理器;GPU 为1080Ti,每块GPU的显存为11 GB;内存64 GB。

表4 硬件参数表
卷积网络的前向计算和反向传播过程都可以矩阵化表示,在训练时可用并行计算加速训练过程。GPU内包含有大量的并行计算单元,非常适用于训练深度卷积神经网络。本文在实验中使用GPU来加速训练过程。
本文使用的深度学习计算框架为pytorch,其余软件工具包括opencv、pillow、matplotlib 等。相关的网络定义代码和训练代码均由Python编写完成。
4.4 训练设置
在进行迁移学习时,对于与预训练模型对应层匹配的部分,直接利用预训练模型进行初始化。不能直接从预训练模型获取的权重再使用Xavier[14]进行初始化。
在训练时,使用随机梯度下降算法进行训练,即使用SGD 优化器。在训练过程中,所有训练参数都有SGD 优化器进行统一维护和更新,使用统一的学习速率。当训练进行到一定阶段时,损失曲线可能不再下降,参数学习过程变得艰难,需要降低学习速率,使模型损失在训练中继续下降。在训练目标识别网络时,使用SGDR来调整学习速率。
5 实验结果分析
在训练中,数据集每完成一个epoch的训练,记录一组损失函数的值。训练完成后,绘制网络损失和时间的变化关系图,见图4 及图5。在图中横轴表示数据训练的轮数。

图4 置信度损失变化曲线

图5 坐标定位损失变化曲线
从图4 及图5 可看出,置信度损失和坐标定位损失都随着训练时间的增加而不断下降,当训练接近终止时,损失已收敛。训练完后,用测试数据集对网络的性能进行评估。对于模型给出的每张测试图片的预测结果,按照预测的置信度进行排序,然后按照预测坐标框与真实坐标框的IoU 值判定一个预测结果属于正例还是反例,如果一个预测结果与某个真实坐标框阈值符合要求,但是已经有某个置信度更高的预测与这个真实标注坐标框匹配,那么该预测同样属于反例。对每个预测结果进行归类后,计算预测的精确率向量和召回率向量。然后取不同的召回率阈值,绘制Precision-Recall曲线。模型在KITTI数据集上的PR曲线见图6。

图6 模型在测试集上的Percison-Recall曲线
图6 中可知,模型在“car(汽车)”,“tram(电车)”,“truck(卡车)”中都有很好的精确率和召回率;在“van(面包车)”中的召回率一般,不是特别好。在“person(人)”和“cyclis(t骑自行车的人)”中的召回率较低,这主要是由于数据中的大多数行人和自行车在图像中占有的像素空间太小,模型在对这类目标进行预测时很容易误判,使得模型在追求高召回率的时候,预测精度下降。绘制好PR 曲线后,计算每个类别PR 曲线下的面积,所得面积即为模型在每个类别下的平均准确率AP,然后对所有类别的AP 取均值,即可获得模型在测试集上的mAP,具体参数值见表5。最终,模型在KITTI测试集上获得meanAP为0.727。作为对比,使用VGG-SSD、YOLO、MobileNet[15]网络模型在数据集上进行实验,最终的对比结果如表6所示。

表5 各个类别的AP值

表6 模型性能对比表
通过对比可知,本文模型在识别精度上比VGG-SSD模型相差9 个百分点;但是模型的速度是VGG-SSD 的两倍,体积仅是VGG-SSD模型的1/5。而对比于YOLO和MobileNet来说,本文模型体积大量减少,运算速度大量提升。本文提出的模型体积仅有19 MB,处理速度可以达到66.67 帧/s,将其应用到智能驾驶时,能够实时地对道路上的目标进行检测识别。部分样例识别结果见图7。

图7 识别结果展示
6 总结与展望
基于深度分离卷积和残差连接等思想,设计了一个不变分辨率特征提取模块和一个降分辨率下采样模块,通过堆叠设计的特征提取模块和降分辨率下采样模块,获得了主干网络。初始主干网络设计完成后,修改网络的末端,加入分类器,在CIFAR100数据集上对网络进行训练,通过BatchNormalization 层的参数γ来衡量每个卷积核的重要性,然后将不重要的卷积核从网络中剔除出去,进一步优化网络的结构。对主干网络进行剪枝后,在构建的KITTI 数据集上(由VOC 2007、VOC 2012、Udacity 和KITTI 数据集中目标识别图片构成)对整个识别网络进行训练。最终,设计的模型在构建的数据集上取得了72.7%的mAP,速度为66.7 帧/s,达到实时,能够很好地应用到智能驾驶领域。
猜你喜欢
保健医苑(2022年5期)2022-06-10
北京航空航天大学学报(2021年9期)2021-11-02
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
电子制作(2019年13期)2020-01-14
数学物理学报(2019年3期)2019-07-23
电子制作(2019年11期)2019-07-04
家庭影院技术(2018年9期)2018-11-02
北京航空航天大学学报(2018年1期)2018-04-20
制造技术与机床(2017年7期)2018-01-19
