
基于剪枝AlexNet的普米语孤立词识别
2020-09-10 07:22侯俊龙潘文林何翠玲
云南民族大学学报(自然科学版) 2020年4期
侯俊龙,潘文林,王 璐,何翠玲,王 翠
(云南民族大学 数学与计算机科学学院,云南 昆明 650500)
语言是人类进行思想交流、情感传达最为重要的工具,是文化传承与发展的重要载体,而语音作为语言的声学表现形式,对丰富和发展中国传统文化起着至关重要的作用.近年来,随着深度学习逐步发展成为语音识别领域的研究热点,越来越多的基于深度学习的语音识别技术也得到了高速发展.百度使用的基于神经网络的端到端模型能够高效的识别出英语或普通话[1];谷歌提出的无界交错状态递归神经网络能以92%的准确率识别出每个人的声音[2].虽然该技术取得了先进性的进展,但到目前为止,所做的工作大多集中于汉语、英语等国际主流语言,在少数民族语言方面的研究仍屈指可数,这也使得该技术距离广泛的应用尚存在很大差距,该文选用无本民族文字的普米语作为研究对象,开展少数民族语言的孤立词语音高效识别研究.随着科技的不断发展,语言的衰退和消亡在所难免.解鲁云[3]研究发现,普米族是我国曾经有着不断迁徙历史的人口较少、呈杂居分布的少数民族,该民族没有统一的文字,但有其独立的语言-普米语.其发展与传承历代以来均依赖于口耳相传,并且该民族与汉族在杂居中逐渐吸收和顺应汉民族文化,使得普米语正逐步走向消亡.为更好的保护和发展正处于濒危状态的普米族语言,我国研究员正努力的探寻有效方法及途径.为濒临灭绝的普米语建立语音语料库,开展普米语孤立词识别研究是解决濒危语言问题最为有效的方法.
现有的普米语孤立词识别研究工作大多是利用传统的深度学习方法对普米语孤立词进行识别,主要的研究工作有:李余芳等[4]通过建立HMM模型,然后采用Viterbi算法对普米语孤立词进行识别,其识别精度超过了95%.胡文君等[5]为提高普米语语音识别系统的性能,通过引入深度学习模型对普米语语音展开研究发现,基于深度学习的语音识别具有比其他模型更强的鲁棒性.杨花等[6]对支持向量机中的惩罚参数和核函数参数使用粒子群算法进行优化,然后将其用于普米语语谱图识别,其实验发现基于最优参数的分类准确率达到89.8%.不难看出,普米语孤立词识别研究取得了一定的成果,但识别精度仍相对较低,尚未达到可用程度.人们为了提高普米语孤立词识别的性能,开始不断的增加模型复杂度,王翠等[7]将卷积神经网络的AlexNet模型用于佤语语谱图识别,其实验表明利用AlexNet模型对语谱图进行识别可有效避免清、浊音的干扰,识别精度高达96%.复杂模型固然具有更好的性能,但该模型也带来了更多的计算资源消耗和更长的训练时间等问题,使得神经网络的训练成本变得越来越高,如何让神经网络得到高效快速的训练也逐渐地成为了语音识别领域亟待处理的问题.
近来麻省理工学院计算机科学与人工智能实验室的研究人员发现任何1个密集的、随机初始化的前馈神经网络都包含着稀疏的子网络,这些网络能够通过保留初始权重,从零开始以与原网络同样的速度进行相应的精度训练[8].本文为有效降低神经网络的训练成本、加速模型训练,选用无本民族文字的普米语作为研究对象,将卷积神经网络中的AlexNet模型利用迭代剪枝算法以逐层剪枝的方式进行修剪,然后从生成的稀疏网络中探索一个具有比原网络更快学习速度的剪枝网络用于普米语语谱图识别.
1 相关工作
目前,在深度学习研究领域大致有2个研究派别:一派为了追求更高的模型精度,不断的扩充神经网络的网络层数[9]或神经元数量[10],通过将模型变得更为复杂,来使得神经网络具有更高的精度.另一派则旨在将模型高效、稳定的部署于设备.但是,随着神经网络结构的日趋复杂,网络的训练成本也变得越来越高,这些均使得复杂模型很难在设备上有效的部署.从模型压缩[11]与优化加速[12]的研究工作中发现,神经网络剪枝技术能够在保持模型精度的前提下删除那些对模型最终输出影响不大的参数.
近年来,普遍使用的神经网络剪枝技术可以分为2类:神经元剪枝[13-14]、权值连接剪枝[15].神经元剪枝是选择某种评价指标来度量神经元的贡献度,剪除那些对模型最终输出贡献度较低的神经元或卷积核,该方法可使神经网络变得更“瘦”.其次,权值连接剪枝是通过从训练好的网络中剪除那些具有较小权重的连接,最终使神经网络变得更为“稀疏”,该方法相比于神经元剪枝,信息丢失相对较少,对模型的精度影响不大.
在早期,剪枝算法被广泛应用于模型压缩等问题,文献[16]通过训练网络来学习网络中连接的重要性,然后在不影响模型精度的前提下,修剪那些不太重要的连接,将AlexNet模型中近6 100万的参数减少到670万,模型被压缩将近90%.彭冬亮教授[17]所提出的阈值剪枝算法通过训练网络和修剪较低权重连接和再训练网络可以减少GoogLeNet中近94%的参数,并且经过较少的迭代次数以后,修剪后的网络具有与原网络相似的精度,模型压缩取得了较为显著的效果.受到这些研究成果的启发,将采用迭代剪枝算法从1个随机初始化的前馈神经网络中逐层修剪那些具有较小权重的连接,从生成的稀疏网络中寻找1个具有比原网络更快学习速度的稀疏网络,并将其用于普米语语谱图识别,探索迭代剪枝算法在普米语孤立词识别中的加速效果.
2 剪枝原理
2.1 “迭代剪枝”算法
“迭代剪枝”用于从原始网络中生成不同修剪程度的稀疏网络,算法具体描述如下:
Step 1 随机初始化一个前馈神经网络f(x;θ),并构造1个与θ相同维数的mask矩阵M=1|θ|;
Step 2 训练神经网络f(x;θ⊙M)的参数k次直至模型收敛,保存最终权重矩阵Wk;
Step 3 将各层权重按绝对值大小进行排序,把排序后权重矩阵中的前p%参数所对应的mask设置为0,其余(1-p)%参数所对应的mask设置为1,更新mask矩阵M为M′;
Step 4 利用mask矩阵M′生成稀疏网络权重矩阵W′=W⊙M′;
Step 5 将W′中剩余的非0参数重置为初始值并重新训练经剪枝生成的稀疏网络;
Step 6 迭代进行Step 3~Step 5,直至生成1个充分修剪的稀疏网络.
2.2 “迭代剪枝”流程
过参数化神经网络虽然具有很好的性能,但其应用常因内存消耗过大、训练速度缓慢等情况而受到限制.剪枝作为解决这类网络难以训练等问题的一项关键技术,能够有效的加速模型训练.迭代剪枝分为4个阶段:首先,随机初始化1个过参数化网络并训练直至收敛;其次,按一定比率逐层修剪较低权重;接着重新训练经剪枝生成的稀疏网络;最后反复进行上2步中的剪枝及再训练操作,直至生成1个充分修剪的稀疏网络.
2.3 剪枝前后神经网络结构
深度神经网络通常是密集连接的全连接网络或卷积神经网络,网络中的神经元按接受信息的先后可依次分为输入层、隐藏层和输出层.在未进行剪枝操作前,网络中后一层的各个神经元均与前一层的每个神经元相连,其网络结构如图1(a)所示.近年来,网络剪枝研究成果显示,在密集连接的神经网络中,存在大部分连接对模型的最终输出贡献不大,可以在保持模型精度的前提下修剪那些对模型贡献度不大的连接.深度神经网络经剪枝后,原先密集连接的神经网络就变成了稀疏网络,生成的稀疏网络结构如图1(b)所示,后一层的神经元不再与前一层的各个神经元均相连,后一层的部分神经元甚至不再有信息输入,这些使得网络的规模得以大幅度缩减、网络间的计算量大大降低,进而实现模型的加速训练.
3 “迭代剪枝”算法实现
“迭代剪枝”的任务是以迭代的方式逐层的修剪网络中较低的权值连接,最后从生成的稀疏网络中寻找一个最佳的剪枝网络,我们将该问题表述为:
(W1,W2,…,Wl)*=arg minL(A(W1,W2,…,Wl).
(1)
其中A表示剪枝前网络,我们试图通过迭代剪枝找到一组最佳稀疏权重(W1,W2,…,Wl)*使模型的训练损失最小.为此,我们通过随机初始化1个神经网络f(x;θ)并进行如下操作.
(2)
2) 模型采用随机梯度下降法来训练1组使R(W)最小的参数W(l).在每次梯度下降迭代中,第l层参数W(l)的学习更新方式如(式3)所示.
(3)
3) 保存模型最终训练得到的各层权重W(l)并构造1个与W(l)相同维数的二元mask矩阵M(l)=1|θ|,如(式4)所示.
(4)
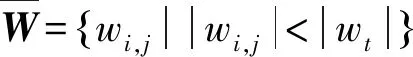
(5)
5) 将mask矩阵M中与所选权重对应位置的值设为0, mask矩阵变为M′,如(式6)所示.
(6)
6) 使用mask矩阵M′生成稀疏矩阵W′,其中{wi,j|mi,j=0}被设置为0,如(式7)所示.
(7)
7) 迭代进行4)~6).
4 AlexNet模型
AlexNet模型是在LeNet的基础上通过堆叠3个卷积层和1个汇聚层而成的第1个现代卷积神经网络,该模型总共有8个可训练层,其中包含5个卷积层和3个全连接层,具有多达上千万的待训练参数.模型中的卷积层可看成是特征提取层,而全连接层则看作是特征映射层.在模型最后1层采用softmax激活函数对普米语语谱图进行分类,卷积层与全连接层均使用relu激活函数.为加速模型收敛,还在该模型的每个卷积层之后都加入1个批量归一化(batch normalization, BN)层,其网络结构及其参数如图2所示.
图中Input表示输入层,输入的是100×100×3的图像;conv1表示第1个卷积层,使用96个11×11的卷积核,s=4表示步长;MaxPooling表示汇聚层,在该模型中均采用大小为3×3的最大汇聚,Flatten表示展平层,常用于将多维输入一维化;fc表示全连接层.
5 实验
在本节中,我们将验证经迭代剪枝生成的稀疏网络在普米语语谱图识别上的性能.第1,给出普米语孤立词识别的流程;第2,介绍如何自建数据集;第3,对实验设置的参数进行了说明;第4,分别在AlexNet原网络与剪枝网络中对普米语孤立词进行识别;最后,比较不同的剪枝策略并说明迭代剪枝的优势.
5.1 普米语孤立词识别流程
普米语孤立词识别的流程大致如图3所示,首先通过对采集的原始声音语料经预处理转换为语谱图,然后由其组成数据集输入到神经网络中进行模型训练,最后给出识别结果.
5.2 自建数据集
1) 实验选用无文字的普米语作为研究对象,首先从汉文词库中挑选600个孤立词,由3个会说普米语的人分别在录音棚环境下录制语音,每个孤立词读8遍,得到14 400条语音语料.
2) 在录制得到普米语孤立词语音语料后,尚且不能直接将采集到的原始声音语料用于模型训练或测试,一个重要的工作是对每条语音语料进行归类整理,最后生成600类带标签的孤立词语音语料.
3) 由于声音是随时间变化而变化的短时平稳信号,所以可以对普米语孤立词语音在每个时刻连续的进行短时傅里叶变换将其转换为短时谱(又称语谱图),经变换生成的语谱图如图4所示,最终由这14 400张100×100×3的普米语孤立词语谱图组成数据集.
4) 数据集生成以后,还需将数据集划分为训练集、验证集和测试集.结合对本文数据集规模大小的考虑,我们随机选取整个数据集中每一类的50%将其标记为训练集,20%标记为验证集,其余的30%标记为测试集.
5) 数据集划分完成后,为便于神经网络读取数据,将数据集及标签分别转化为Numpy数组文件,模型训练时通过直接读取生成的文件来获取样本特征及其标签.
5.3 设置实验参数
在模型开始训练前,先将模型参数设置为:训练轮数为1 500轮,批次大小为128,每层剪枝比率为β=15%,迭代剪枝次数为15次,选择随机梯度下降法(SGD)作为参数学习更新的方法,SGD中的学习率α设置为0.001 2,动量μ为0.9,模型选用交叉熵损失函数,并且为了减小模型在数据集上的过拟合现象,模型还加入l2正则化项.
5.4 AlexNet模型剪枝结果分析
为验证经迭代剪枝算法生成的稀疏网络在普米语语谱图识别中的性能,利用卷积神经网络中的AlexNet模型在自建数据集上进行实验.首先,随机初始化1个AlexNet模型并训练其直至收敛,然后采用上文所述的迭代剪枝算法以逐层剪枝的方式修剪网络15次,每次修剪完成后都将剩余参数重置为初始值并再训练剪枝后网络相同的轮数.每次剪枝生成的稀疏网络在验证集和测试集上的正确率随剪枝次数的变化情况如图5所示,由图中曲线变化可见,随着剪枝次数的增加,网络中剩余的参数量逐渐减少,这将使网络计算量得以大幅度地减少,网络的泛化能力得到显著提高.神经网络从随机初始化开始至剪枝9次期间,剪枝网络的准确率均达到了与原网络类似的精度,后面再接着对网络剪枝发现剪枝网络在验证集与测试集上的精度开始逐渐下降.
迭代剪枝完成后,从生成的稀疏网络中寻找1个最佳的剪枝网络.实验中选取剪枝7次后生成的稀疏网络为最佳剪枝网络,这时网络中剩余的参数仅占原网络的32.06%.在得到最佳剪枝网络后,再在训练集上分别训练AlexNet原始网络和搜寻到的最佳剪枝网络,并在测试集上评估它们的性能,剪枝前后网络在验证集上的正确率及损失变化情况如图6所示.由图6(a)可见,AlexNet剪枝网络经过近450轮迭代训练后开始逐渐收敛,而原网络则需经过近1300轮的迭代训练后才逐渐收敛,并且由图6(b)可见,剪枝后网络在验证数据集上的损失下降得比原网络快.
在上述剪枝策略下,发现剪枝前后网络的精度基本一致,但剪枝后网络具有比原网络更快的收敛速度.最终结果显示,AlexNet剪枝网络在测试数据集上的识别正确率(98.53%)比原网络准确率(98.37%)高0.16%.
5.5 不同剪枝策略比较
将迭代剪枝策略与传统的一次性剪枝方法进行比较,迭代剪枝是对模型进行反复的训练-修剪-再训练操作,每次修剪较少的权重.而一次性剪枝则是一次性修剪较多的权重,最后再对生成的稀疏网络进行训练.利用AlexNet模型在这2种不同的剪枝策略下分别进行实验.在一次性剪枝方法中,一次性修剪原网络68%的参数,实验结果见表1.

表1 不同剪枝策略比较
由表中数据可知,经迭代剪枝生成的稀疏网络具有和原网络类似的较高识别精度,但经剪枝生成的网络具有比原网络快得多的收敛速度.此外,我们还将迭代剪枝策略与一次性剪枝方法相比较发现,二者的收敛速度大致相同,但我们的方法具有比一次性剪枝策略更高的识别精度.在一次性剪枝实验中出现部分精度损失可能的原因是一次性修剪过多的权重,对网络造成了破坏,使网络在后续的训练中精度很难恢复.
6 结语
本文针对语音识别领域,神经网络学习速度慢、训练成本高等问题,选用迭代剪枝算法对随机初始化网络以迭代的方式进行逐层修剪,并从剪枝生成的稀疏网络中搜寻1个最佳的剪枝网络用于普米语语谱图识别.实验结果表明,将经迭代剪枝生成的AlexNet剪枝网络用于普米语语谱图识别具有和原网络类似的较高识别精度,并且剪枝后网络还具有比原网络更快的收敛速度.对随机初始化网络进行迭代剪枝具有如下优点:①能够大幅度缩减网络规模、有效降低网络计算量,促进模型快速训练;②可以避免神经网络中过多的参数冗余、提高模型泛化能力.然而,通过该算法来生成最佳剪枝网络往往需要反复的进行模型训练,相比于一次性剪枝,所耗费的时间较长.在接下来的工作中,将探索更为快速、有效的剪枝方法来生成最佳剪枝网络.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
保健医苑(2022年5期)2022-06-10
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
天津诗人(2017年2期)2017-03-16
