
基于STIX标准的威胁情报实体抽取研究
2020-09-10 06:51王沁心杨望
网络空间安全 2020年8期
王沁心,杨望,2
(1.东南大学网络空间安全学院,江苏南京 211189;2.网络空间国际治理研究基地(东南大学),江苏南京211189)
1 引言
安全研究人员通常会将网络安全事件进行整理和分析后以文本的形式发布,这类文本通常包括安全类新闻、博客等,但其中最具价值的是安全厂商针对高级持续性威胁(Advanced Persistent Threat, APT)攻击事件溯源分析后形成的APT报告,其中蕴含大量的威胁情报相关信息,但这些信息无法进行自动化处理,也不方便进行共享。
因此,为了便于威胁情报的存储、传输、自动化处理,以及情报的共享和分析,业界提出了许多威胁情报表达规范,比如OpenIOC[1]、MAEC[2]、STIX[3]等,它们拥有不同的特点,适用于不同的场合,其中STIX标准提供了完整的结构化威胁情报表达框架,具有类型丰富,共享方便等特点,可以适用于各种场景。
在过去,从安全文本到STIX等结构化威胁情报这一转换过程往往由研究人员完成,需要耗费大量的人力和时间。近年来,随着自然语言处理(Natural Language Processing, NLP)等技术的发展,已经能使用多种自动化方法对文本进行抽取和理解。但现有研究抽取的内容较为单一,也不适用于STIX标准,利用价值较低。
为了解决上述问题,本文引入了STIX标准中的主要威胁情报实体,并构建了标注数据集,在此基础上对基于该数据集的威胁情报自动抽取方法进行研究,并对不同抽取方法下的效果进行了对比。
2 相关工作
2.1 STIX标准
STIX(Structured Threat Information Expression)是由OASIS推出的威胁情报交换标准,在STIX 2.0中定义了12种称为STIX Domain Objects(SDOs)的实体,比如攻击模式(Attack Pattern)、应对措施(Course of Action)、威胁指标(Indicator)等,以描述对应类型的威胁信息。除实体外,STIX还定义了实体之间的关系,称为STIX Relation Objects(SROs)。
使用SDO、SRO等标准化的定义进行情报表示,有助于威胁情报的共享和自动化处理。不过,完整的STIX定义结构较为复杂,同时为了保证其扩展性和灵活性,STIX定义中也存在部分模糊和宽泛的内容,因此本文仅仅选取了STIX的部分子集进行标注和预测。
2.2 威胁情报抽取的相关研究
目前,安全文本抽取的相关研究主要集中在两个方面:数据集的构建和如何获取不同类型的威胁信息。在数据集方面的代表性工作是Lal[4]提出的安全实体的标注数据集,包括了对文件名、网络名词、操作系统、软件名等实体的标注。
在威胁信息类型方面,现有的安全文本抽取工作已经涵盖了多种类型的威胁情报。对威胁指标(Indicator of Compromise, IOC)进行抽取的代表性工作是Liao等人提出的iACE[5],综合运用了正则表达式和机器学习等方法实现抽取。此外刘浩杰等人[6]提出了检测恶意域名的集成学习方法。在行为信息的挖掘方面,主要有Husari等人开发的TTPDrill[7]系统通过基于文本相似度匹配来判断攻击行为。
在安全实体的抽取方面,Bridges等人[8]提出的通过综合运用数据库匹配,启发式规则和术语词典实现安全实体的自动抽取。
不过,现有的安全实体标注或文本抽取相关研究中并未涉及本文提出的对恶意软件或攻击者身份相关信息的识别,也并非基于STIX标准,无法转换为结构化的威胁情报进行共享,因此本文提出的标注框架更具有实用价值。
2.3 网络安全领域NLP的应用特点
上述研究表明NLP技术在安全领域得到广泛的应用。在方法上,常用的模型都可以直接应用于安全领域的文本数据集,比如传统的特征工程+机器学习,以及近年兴起的深度学习方法,包括CNN、RNN模型等。
但安全领域的NLP应用和传统NLP相比也存在以下重要的区别。(1)安全领域的文本普遍比较“脏”,为了清晰描述安全事件,作者会在文中加入大量的URL、IP、Hash值、代码片段以及各类图表等信息,如果不进行处理会在训练过程中引入大量的噪声,这些信息大多数情况下需要进行识别并从文本中去除。(2)当前绝大部分NLP技术是基于监督学习的,需要大量的人力参与标注,但由于安全文本具有专业性的特点,难以和普通文本一样通过众包来获取大量标注数据。(3)由于安全文本中存在的大量专有名词,在普通文本上预训练的模型无法在安全领域的任务中取得满意的效果,比如常用的各类词向量。
可以看出,在安全领域应用NLP技术的挑战主要在于文本处理和构建数据集,因此本文也在这两个方面进行了重点说明。
3 数据集构建过程和实验方法
由于上述安全文本的特性,本文对数据集的标注和扩展流程进行了详细介绍。在实验方法上,本文选择了几种常用的NLP模型,用于对比不同方法在本数据集上的有效性。
3.1 数据集构建
本文从APTnotes[9]等来源收集了近10年共528篇APT报告,对其中31篇进行了人工标注,将另外497篇用于扩展标注数据集。31篇标注的文档经过仔细筛选,时间均为2018-2019年,保证了时效性。在作者方面,选取了多家不同安全公司的报告,包括Symantec、FireEye、Palo Alto Networks、Trend Micro、360等。在题材选取上主要有三种类型,包括对攻击组织的分析、对某次攻击活动的分析和对恶意软件的分析,从而保证了题材多样性,对于题材的具体统计如表1所示。
(1)预处理
对于所有的文档,本文建立了如图1所示的文本预处理流程。
由于所有的文档均为PDF格式且语言为英语,本文首先使用PDFMiner[10]将其转为文本文件,并在此过程中过滤掉所有非ASCII字符。PDFMiner可以根据PDF文档的布局,初步对文档进行分段,但无法进行分句。经测试,现有的分词和分句工具无法准确处理安全类文本。因此,本文根据安全文本的特点,重新编写了分句规则。
对于每一个经PDFMiner处理得到的段落,本文使用首先去除段落内所有的换行符,连续空格,空括号等多余符号,并准确判断并处理文档换行处单词的截断问题(比如ser- vice),得到一个单行的段落,再在此基础上分句。本文测试了多种分句规则,发现最简单的基于句号和单空格的规则(r'.s')最为有效。

表1 所选报告的题材分布
在分词方面,为了保证不同实验中分词结果的一致性,本文使用了BERT[13]提供的Tokenizer对单个句子进行分词,由于BERT提供的分词工具会进行WordPiece Tokenization, 产生众多以##开头的单词片段,在使用词向量等方法作为输入时,需将被拆分的单词重新合并。
(2)标注内容
对于STIX 2.0标准中定义的12个SDO,本文选取了以下5项SDO进行标注,它们在文中都以名词或名词短语的形式呈现:
1) Identity—身份信息,通常是个人或组织的名称,用于说明攻击目标、信息来源等;
2) Intrusion Set—具有共同属性的攻击行为和资源的集合,比如APT报告中经常使用APT+编号的方式指代攻击背后的组织;
3) Malware—恶意软件名称,一般出现在APT报告中的都是恶意软件的家族名称而非完整的正式命名;
4) Threat Actor—恶意行为的具体实施者;
5) Tool—用于攻击行动的合法软件。
(3)标注过程
对于31篇手工标注的数据集,本文在上述预处理流程的基础上进一步手动检查了无效信息并将其移除,以确保文本中只包含完整的句子,随后使用Brat Rapid Annotation Tool (Brat)[11]工具进行文本标注,其界面如图2所示;标注完成后将Brat自动生成的ann格式文档转为常用的BIO标注格式,如表2所示。
在实际标注中发现,Intrusion Set和Threat Actor在定义上的区别比较模糊。在许多APT报告中,这两种类型甚至使用同一个词语表示,不同的人很容易给出不同的标注。因此在实验中,本文将Intrusion Set和Threat Actor的标注进行合并,自定义一个新的实体Attacker,以消除模糊性从而在实验中取得更好的效果。

表2 BIO标注格式

图1 预处理流程

图2 Brat标注界面
(4)数据集扩展
为了进一步扩大样本数量,本文将手工标注的31份报告中标注的实体整理为字典,对于剩余的497份报告,经过上述预处理流程进行分句和分词后进行字典匹配,对于匹配到的句子则将其加入训练集。由于扩展的样本基于字典匹配,因此存在一定的噪声,但考虑到大部分实体都以特殊名词的形式存在,一般为首字母大写或全大写,基本可以忽略由于词语相同所产生的错误样本。
对于扩展的数据集,本文去除了所有小于5个单词以及结尾没有标点的词组,从而去除了大部分自动处理的报告中非句子的部分,并进一步平衡了各类别的数量,最终形成的数据集比手工标注的部分增加了8,825个样本。
最终数据集中各项实体标注数量的统计如表3所示。可以看到通过字典扩充训练集的方法增加了数倍的样本,在提高样本数方面具有显著效果。
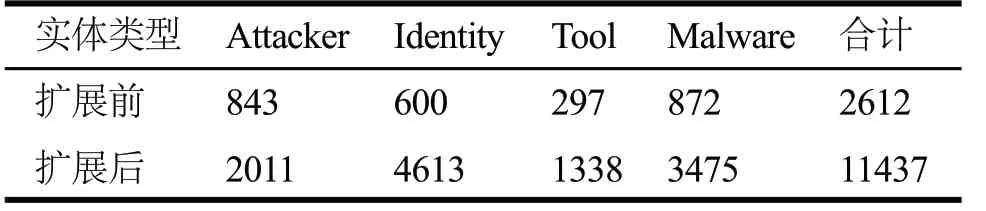
表3 数据分布
3.2 词嵌入方法和模型选择
在完成数据集构建后,在输入模型前需要将文本中的单词进行嵌入,得到固定长度的向量。除了随机生成输入向量外,使用更广泛的是通过预训练得到的词向量。由于预训练的词向量能够在一定程度上表达自身的语义,能有效提升下游任务的效果。本文中使用了传统的静态词向量GloVe[12]和基于自注意力(Self-attention)机制的BERT[13]作为输入并进行了对比。
在模型方面,本文分别使用CRF模型,BiLSTM模型以及二者的组合对四种实体进行识别,同时也比较了LSTM的变种GRU(Gated Recurrent Units)网络。
4 实验及结果分析
实验中,数据按8:1:1划分为训练集、验证集和测试集,同时随机初始化的向量和GloVe词向量的维度均为300。在指标方面,计算每种方法下每个类别的精确率(Precision)、召回率(Recall)和F1值(F1 score)以及所有实体类别的平均值,具体结果如表4所示。
本文首先使用单一的CRF模型作为基准值。可以看出本文的数据集在该方法下取得了一定的效果,但召回率偏低。在单独使用BiLSTM模型的情况下,平均召回率有了显著的提升,但仍不如组合模型。
随后本文在CRF前加上BiLSTM模型,并使用随机向量作为输入,与模型共同训练。可以看出组合模型的效果要好于单一模型,这主要是由于加入CRF层能够满足标签之间的依赖关系,修正单一模型的错误。

表4 实验结果
最后是使用GloVe词向量作为神经网络输入。在该方法下,所有指标均低于仅使用CRF的基准值,主要是由于GloVe这类传统词向量的词汇表固定且使用普通文本进行训练,很多词语的预训练向量无法准确描述该词在安全文本中的语义。此外,GloVe无法处理安全文本中大量特殊的OOV(Out of Vocabulary)词语,而很多这类词汇正是本文中需要预测的实体名称。最后,GloVe词向量对所有词语进行了小写化,丢失了部分文本中的信息,因此此类词向量的加入起到了反效果。
最后一种方法使用了预训练BERT作为输入,比起传统词向量,BERT使用的Transformer模型能更有效捕捉上下文语义,同时WordPiece Tokenization能够有效处理OOV词汇,得到字符级别的特征,因此该方法取得了最好的效果。
此外,本文也将LSTM替换成双向GRU进行了实验。一般来说,LSTM的结构更为复杂,拥有更好的表达能力,但本数据集规模相对较小,从表4可以看出因此二者的性能几乎一致,在使用BERT作为输入的模型中,GRU网络的召回率和F1值都略优于LSTM,详细指标如表5所示。
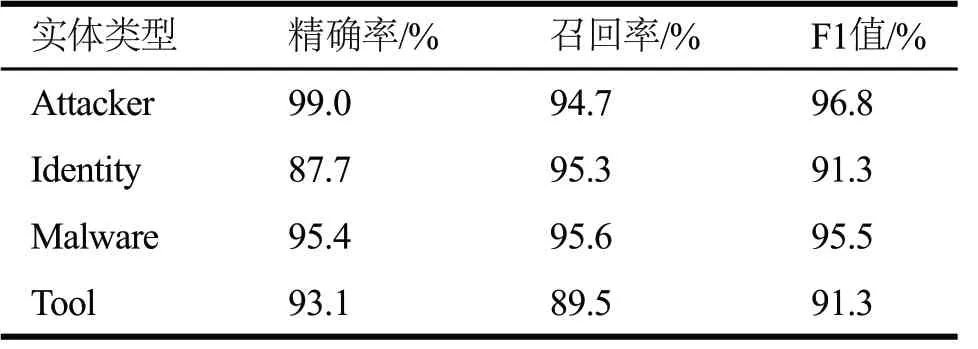
表5 BERT-BiGRU-CRF分类指标
在几乎所有方法中,Attacker和Malware的结果都要优于Identity和Tool,这是因为Identity涵盖的范围较大,既包括了各类公司或组织的名称,也包含了一部分人名,模型并不能很好地学习到该类型中所有的信息,而Tool指标较低则是由于其标注规模小于其他类型的实体。
5 结束语
本文基于STIX 2.0标准定义了一组安全文本中常见的实体,首先对31篇APT报告进行了手工标注,并将其中被标注的实体作为字典匹配更多未标注报告中的句子,有效扩充了标注数据的数量。得到标注数据后,本文对比了不同方法和不同初始化条件下实体抽取的效果,可以看出该系统可以有效捕捉APT报告中的实体信息,以用于后续的威胁情报构建。
由于本数据集手工标注的部分相对较小,为了进一步提升模型的泛化能力,在后续工作中将扩大手工标注的文档数量。同时,还将对STIX标准中的行为信息以及实体间关系(SRO)的抽取进行研究,以生成更加全面的威胁情报数据。
猜你喜欢
现代装饰(2022年5期)2022-10-13
现代装饰(2022年3期)2022-07-05
现代装饰(2022年2期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
红领巾·探索(2020年5期)2020-05-19
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
小天使·一年级语数英综合(2015年10期)2015-10-14
文理导航·科普童话(2015年6期)2015-07-29
