
一种基于对抗样本的验证码安全性增强方法
2020-09-10 06:51沈言玉张三峰曹玖新
网络空间安全 2020年8期
沈言玉,张三峰,2,3,曹玖新,2,3
〔1.东南大学网络空间安全学院,江苏南京 211189;2.计算机网络和信息集成教育部重点实验室(东南大学),江苏南京 211189;3.网络空间国际治理研究基地(东南大学),江苏南京 211189〕
1 引言
验证码作为互联网安全的第一道防线[1],被广泛应用于账号登录、注册、密码找回等验环节,以防止恶意脚本程序滥用网络资源或者暴力破解攻击。然而,随着深度学习技术的发展,基于深层网络模型的破解工具的识别准确率和攻击成功率越来越高,验证码系统的安全性逐渐降低[2]。
尽管深度学习模型对多数样本的识别准确率很高,但近期的研究发现它对某些精心设计的样本的识别率很低[3]。在原始样本的基础上精心构造对抗样本,并欺骗神经网络模型的攻击技术称为对抗攻击。Szegedy[4]等人首先指出了对抗样本的存在。对抗攻击在样本上添加的微小扰动对人类视觉系统而言几乎不可察觉,因此对于验证码来说不影响其可读性。
本文研究基于对抗样本增强文本验证码安全性的技术,提出基于区域更新的模型集成白盒生成方法(Model Ensemble White-Box Generation based on Region Update,MEWG-RU)。MEWG-RU同时使用如VGG、ResNet、DenseNet等多个模型生成对抗验证码,根据每个生成模型的预测结果对损失函数进行加权求和,将验证码文本区域和背景区域相区分,并通过梯度下降的方式更新验证码图像的像素值以最小化目标函数。MEWG-RU可以有效地提高对抗验证码的迁移性,降低未知模型的识别率,同时可以避免识别模型预处理对扰动的破坏,有效地增加了文本验证码的安全性。
2 相关工作
在原始样本添加特定噪音后使得模型出错的样本称为对抗样本。原始样本添加的噪音称为对抗扰动或对抗噪音。在已知目标模型的网络结构、参数、训练数据的基础上添加特定噪音,构造对抗样本的方法称白盒生成。某些对抗样本除了能够欺骗生成它的模型之外,对其它的基于深度学习的模型仍然可以使其输出错误的分类结果,这种性质称为对抗样本的迁移性[7]。验证码通常需要面临未知的识别模型,迁移性尤为重要。
Goodfellow等人提出一种称为快速梯度符号法FGSM[5]来快速生成对抗样本,它沿着每个像素的梯度符号方向执行一步梯度更新。其扰动计算方法为:

Kurakin等人通过迭代扩展FGSM设计了BIM[6],在每次迭代时计算扰动方向,同时通过剪裁操作避免在每个像素上有过大的改变:

对抗样本则通过多次迭代产生:

Osadchy等人[9]首次将对抗样本技术结合在验证码中,提出DeepCAPTCHA方法生成图像验证码。DeepCAPTCHA在对抗样本生成过程中把容易被样本预处理去除的噪音事先去除,保证最终对抗样本添加的扰动不会被预处理操作去除。Shi等人[10]设计并实现了一个名为aCAPTCHA的对抗性验证码生成和评估系统,该系统集成了图像预处理技术、验证码攻击技术和对抗性验证码生成方法。与之相比,本文通过模型集成和区域更新的方法提高对抗样本在迁移性和抗扰动噪音去除能力,可进一步增强对抗验证码的安全性。
3 对抗验证码生成方法
3.1 问题定义
对抗验证码生成问题定义为求解满足条件的对抗样本x',条件为:

即根据验证码y生成对抗验证码x',目标模型f的识别结果y'至少有一个或多个字符和y不吻合。其中x为原始验证码样本,为模型输出的第i个字符中类别j的概率值,L为文本验证码的字符长度,扰动大小d(x,x')为优化问题的约束,这里仅要求添加的扰动在范围内,添加的噪音不影响肉眼识别效果即可。
3.2 模型集成
在对抗验证码的生成过程中,MEWG-RU利用现有的数据集训练得到多个不同网络结构的模型,然后能够同时欺骗这些模型的对抗验证码才可以作为结果输出:
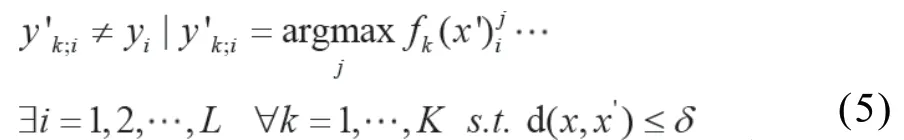
其中y'k;i为模型fk输出第i个字符的预测结果,为模型fk(x')的概率输出结果,K为模型数量。该目标函数同时也是MEWG-RU的结束条件,即当对抗验证码x'可以使所有模型输出至少一个错误文本的结果时返回x'。
3.3 目标函数
将公式5的问题求解转化为公式6的目标函数T(x'),并通过梯度下降的方式更新验证码的像素值以最小化目标函数。
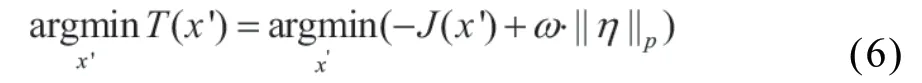



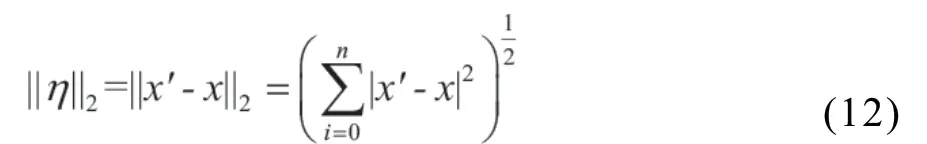
MEWG-RU的目标函数最终为:
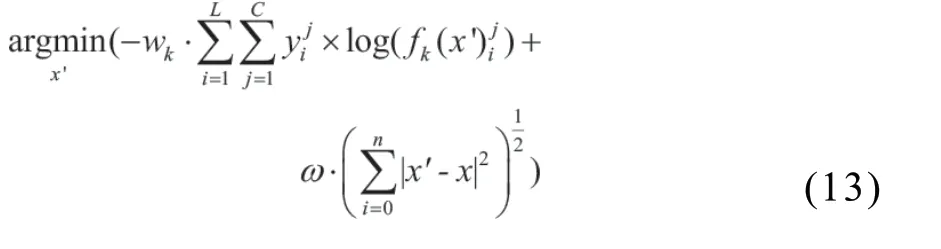
3.4 区域更新
文本验证码的图像形式较为简单,可以明显地区分为背景区域和文本区域。如果在文本验证码的所有区域上添加噪音,在背景区域添加的噪音很容易被去除,从而降低了对抗样本的有效性。因此,MEWG-RU在生成过程中限制添加噪音的区域为文本区域。
首先对文本验证码进行二值化处理,根据二值化结果选择图片中的文本区域,在生成过程中,不再在所有区域上添加噪音,而是根据二值化的结果选择需要添加的区域。有效区域的计算方法为:

其中,T为二值化的阈值,在本文使用的文本验证码中,实验发现将T设置为0.8便可以有效区分背景区域和文本区域。公式14对原始文本验证码灰度化,公式15对灰度化后的结果二值化得到有效区域。
4 实验与分析
4.1 实验设置
实验中使用Python的Captcha库随机生成文本验证码作为数据集。设置生成的文本验证码的字符集包括36个字符,生成的文本验证码图片的分辨率为128×64。训练集和测试集的图片数分别为4万和1万。训练得到多个不同结构的卷积神经网络模型(VGG16、VGG19、ResNet18、ResNet34、GoogLeNet、DenseNet)。实验采用两种经典的白盒生成算法FGSM和BIM作为对比。实验以文本验证码破解模型的识别率作为评估标准衡量安全性,以添加的扰动大小(L2范数)衡量可用性。
4.2 集成模型数量的影响
实验首先分析集成模型数量K分别为1、2、3、4、5时,MEWG-RU的识别率和扰动大小的变化情况。图1所示为各目标模型识别对抗验证码的成功率,可以看出,随着模型数量的增多,对抗验证码在不同目标模型下的识别率都在逐渐变小。MEWG-RU算法在多个模型的时候,设置要求每个模型识别错误才输出结果,否则持续增加扰动,因此模型个数的增加导致扰动增加,在集成模型数量为1~5的时候,对应扰动的二范数分别为3.60、4.11、4.52、4.83和5.16。后文实验中,设置集成模型数量为4。

图1 MEWG-RU中模型数量对识别率的影响
4.3 区域更新的影响
验证码识别方法分为直接识别与图像预处理后识别。如图2所示,整体更新生成的对抗验证码在面对端到端的卷积神经网络时具有较低的识别率,但是如果在预处理之后识别率就较高。相比之下,样本图片预处理对区域更新生成的对抗文本验证码的影响较小。由于区域更新只改变原始文本验证码文本区域的像素点,而预处理操作无法去除添加在文本区域的噪音。

图2 整体更新和区域更新的识别率对比
4.4 MEWG-RU和经典白盒生成算法的对比
考虑到MEWG-RU和经典的白盒生成方法FGSM和BIM也存在添加的扰动越大其对应的识别率越低的特性,这里重点对比三种方法的识别正确率随扰动大小的变化规律。在对抗验证码生成过程中,难以直接控制扰动的大小,只能通过调节扰动步长和迭代次数的方式生成不同扰动大小的对抗验证码,然后分别确定其识别率。图3为在表1的参数下三种方法的识别率,可以看出,MEWG-RU生成的对抗样本在四种不同模型识别下的识别率明显优于其它两种算法。
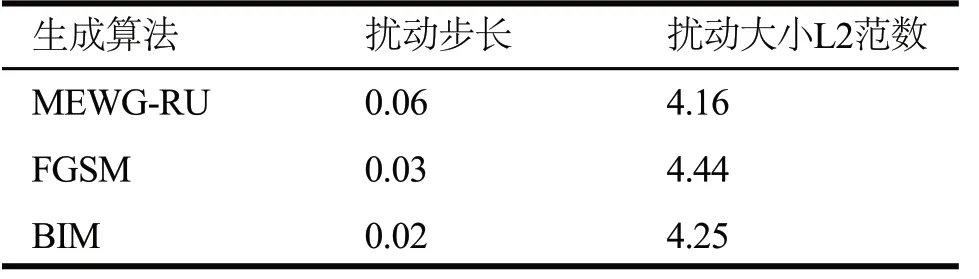
表1 三种对抗验证码生成方法的扰动步长和扰动大小
图4为三种对抗样本生成方法对应的识别正确率和对应的扰动大小的关系,可以看出MEWGRU可以在较小的扰动的情况下实现相对较低的识别率。
4.5 MEWG-RU的可视化效果
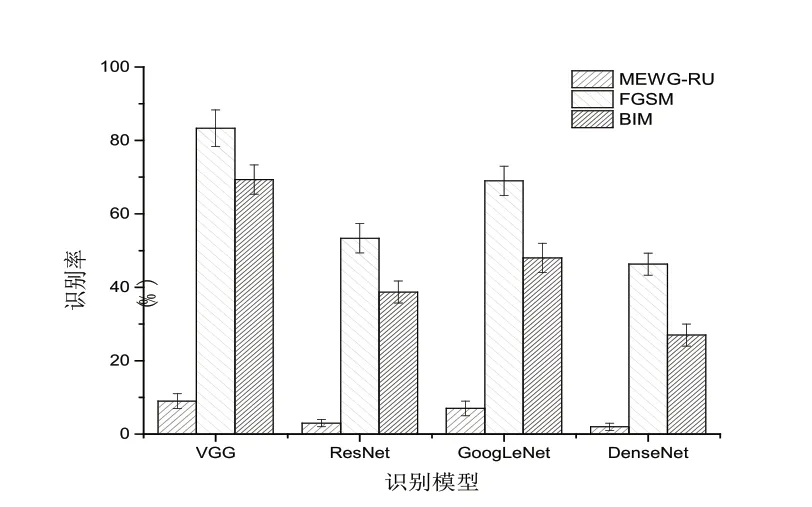
图3 对抗文本验证码面对不同识别模型的识别率
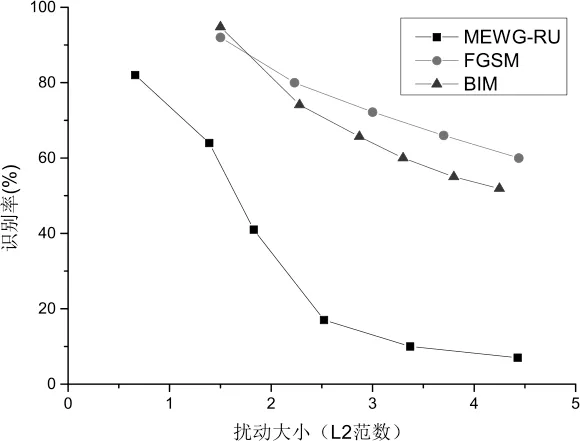
图4 不同方法扰动大小和识别率关系
图5 所示左边一列为原始样本,右边一列为对抗样本。PQPG、PIU2和5WET三组验证码分别在扰动大小为2.5617、3.3765和4.3463的时候,在不做预处理的情况下被识别成了PQVS、PIJZ和5WFJ。可以看出MEWG-RU生成的对抗文本验证码仅在文本区域上添加噪音,当扰动大小L2范数大于3时,便可观察到添加的噪音,当扰动大小L2范数大于4时在文本字符上添加的噪音较为明显,但是仍然不影响肉眼识别效果。

图5 区域更新MEWG-RU生成的对抗验证码
5 结束语
本文提出了一种基于区域更新的模型集成白盒对抗验证码生成算法MEWG-RU,重点考虑了对抗验证码的迁移性和面对识别工具的图像图像预处理去除扰动的问题。测试结果表明,MEWGRU具有良好的安全性和可用性。后期还可以在图像验证码和验证码的系统测试方面继续完善相关工作。
猜你喜欢
材料与冶金学报(2022年2期)2022-08-10
纺织标准与质量(2022年3期)2022-08-10
上海师范大学学报·自然科学版(2022年3期)2022-07-11
健康体检与管理(2022年4期)2022-05-13
汽车实用技术(2022年5期)2022-04-02
北京航空航天大学学报(2021年7期)2021-08-13
建材发展导向(2021年23期)2021-03-08
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
