
基于图像处理和卷积神经网络的文本验证码识别方案
2020-09-10 06:50陈振昂黄星期秦中元
网络空间安全 2020年8期
陈振昂,黄星期,秦中元
〔1.东南大学网络空间安全学院,江苏南京 211189;2.网络空间国际治理研究基地(东南大学),江苏南京211189〕
1 引言
验证码技术的全称是“全自动区分计算机和人类的图灵测试”(Completely Automated Public Test to tell Computer and Humans Apart,CAPTCHA),基本思想:根据预先人为制定的规则,由计算机系统自动生成一个用户可以很容易解决但是计算机系统却很难或者根本无法解决的问题。其中文本验证码是使用最广泛的验证码技术之一,目前对于它的识别研究已经成为了一个比较热门的领域[1]。
George D等人[2]根据神经科学基础—人体记忆物体时总是同时记忆该物体的轮廓和表面特征,提出了递归皮层网络(Recursive Cortical Network,RCN),将验证码的识别过程分为表征、推理和学习三个步骤。尽管该方案能获得较好的识别准确率,对训练集样本数量要求要较低,但计算量庞大,需要较好的硬件设备。Dazhen Lin等人[3]针对基于汉字的验证码提出了新的卷积神经网络模型,对混合干扰的验证码进行测试,识别准确率均达到85%以上。但实验样本字符间有明显间隔,且反分割手段较差。Xing Wu等人[4]对带有噪声的可变长的基于汉字的文本验证码进行了研究,实验结果表明,所提出的方法能够有效地识别出带有噪声的可变长汉字验证码。但该方法受数据集影响明显,并且字符分割方案不适用于具有复杂反分割手段的验证码。
基于国内外学者的研究,本文提出了一种基于图像处理和卷积神经网络的文本验证码识别方案,本文设计的图像分割算法具有较好的通用性,能够有效提取出字符并且识别具有较高的准确率。
2 相关工作
2.1 预处理
原始验证码图片一般为RGB彩色图片,并且带有噪声弧线等干扰。预处理阶段的主要目的是去除验证码图片中的冗余信息(如背景颜色、噪声弧线等)。此阶段的流程如图1所示。其中,二值化过程采用最大类间方差法,采用3×3的中值滤波去除噪声。经过预处理的图像如图2所示。

图1 预处理流程图
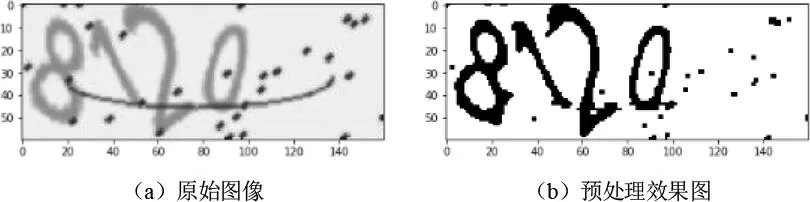
图2 预处理效果图
2.2 腐蚀
形态学腐蚀[5]可以细化字符,从而进一步减少噪声,并去除毛刺,腐蚀后的效果图如图3所示。
2.3 颜色填充算法
颜色填充算法(Color Filling Segmentation,CFS)[6]是一种连通域分割算法,其基本思想是以某一像素点为起始点遍历其所在的连通域。但是此方法的缺陷在于无法将断裂的字符识别为同一连通域,因此本文将对其改进。
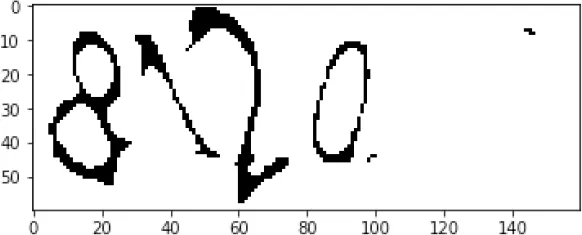
图3 形态学腐蚀效果图
2.4 滴水算法
滴水算法是一种用于分割手写粘连字符的算法,它模拟水滴的滚动,通过水滴的滚动路径来分割字符,可以解决直线切割造成的过分分割问题。但该方法无法处理图中的水平线条遇到边界导致算法异常结束,因此本文将对其改进。
3 字符分割
3.1 改进颜色填充算法
本文研究方案对颜色填充算法做三个方面的修改:
(1)去除像素个数小于6的连通域;
(2)合并边界重合率达到70%以上的连通域;
(3)计算保留连通域的平均像素个数,设为T,去除像素个数小于T的四分之一的连通域。
值得说明的是,边界重合率是两个不同连通域的位置重合程度指标。设连通域1的横坐标范围为[a,b],连通域2的横坐标范围为[c,d](其中a 算法效果如图4所示。 图4 改进颜色填充算法效果 为更好分割字符,本文对滴水算法做出的修改为: (1)水滴水平滚动时,记录其左右边界,当边界距离超过8像素或再次到达边界时,取中心位置为下一滴落点; (2)水滴到达底部时,若距离其左侧边界过近(小于右侧三分之一)或过远(大于右侧的3倍),则将水滴起始位置分别向右或向左移动1像素,重新开始算法,校正次数超过8次,便判定为分割失败。 滴水算法效果图如图5所示。 图5 改进的滴水算法效果图 对于已经预处理完毕的图片,如果颜色填充算法所得连通域个数正好等于实际字符个数,则直接使用连通域分割,否则,使用滴水算法分割。 如图6所示为提取的字符效果图,为降低后续计算量,将其压缩到32×32。 图6 提取字符效果图 本文利用卷积神经网络(Convolutional Neural Network, CNN)构建了一个模型,并使用字符信息对其进行训练。 本文设计的卷积神经网络架构包含三个卷积层、三个池化层、两个全连接层等,具体架构参数如表1所示。 表1 CNN模型架构参数列表 中心损失(Center Loss)函数是由Wen Y等人[7]针对人脸识别任务提出的一种可以增强深度学习模型判别力的损失函数。中心损失会学习每个类的深层特征从而得到一个类中心,并惩罚每个深层特征与其对应类中心的距离,即更关注类内差异。 具体实现过程可概括为: (1)初始化类中心、学习率等参数; 表2 实验数据集 (2)如果已收敛,则结束;否则根据每批次输入数据计算中心损失,根据梯度计算反向传播误差,再更新每个类的中心。 在本文设计的方案中,类深度特征中心的学习率η与误差反向传播的学习率相同,中心损失占总损失的权重λ为0.01。 本文数据集均来自生成和网络采集,具体如表2所示。 本文设计并实现的字符分割算法,联合投影分析、颜色填充算法等多种技术进行字符预分割操作,根据每张验证码图片中字符间的实际情况决定采用连通域分割或者修改的滴水算法分割,从而提取出独立字符。本文对于表2中的实验数据集进行了试验评估,各数据集的字符分割成功率如表3所示。可以看出,本文的方法在各数据集上的效果都很好。 为了进一步评估本文提出的文本验证码识别算法,本文还将实验结果与相关研究进行了比较。本文复现了引言中提到的各方案,在各数据集上识别准确率的比较如表4所示,可以看出本文提出的方案在各实验数据集上均能表现出一定优势,仅在实验数据集F和H略逊于RCN和FRN,这是由于本文使用了CNN作为识别网络,该网络需要较庞大的训练数据集,而实验数据集F和H却偏小,造成了一定的过拟合,但在实验数据集G和I(分别是对数据集F和H的扩充)上,本文方案识别准确率取得了明显的提升,可以超过使用RCN和FRN的方案。值得说明的是,表4中存在一些空缺项,空缺原因是该算法不适用于对应的数据集。 总体来看,本文提出的文本验证码识别方案对于字符独立和存在字符粘连、噪声块与噪声线等反分割设计的文本验证码均能表现出更好的识别性能,当字符训练数据集较小时也能通过扩充的方式提高识别准确率。 验证码是互联网业务的安全基础设施之一,也是目前保障电子商务业务安全的重要环节之一。本文提出了一种通用的文本验证码识别方案,即先进行预处理,再使用改进的颜色填充算法和滴水算法进行字符分割,最后进行字符识别。此外,本文构建了一个具有三个卷积层、三个池化层、两个全连接层的卷积神经网络,并引入了中心损失来最小化类内差异。实验部分,本文复现了四种典型的文本验证码方法,通过准确率的比较发现,本文提出的方案在各实验数据集上均能表现出一定优势。虽然在数据集F和H上不如RCN和FRN,但是在扩充数据集G和I上,解决了过拟合现象后,实现了准确率的明显提升。实验结果表明,本文提出的方法能够有效提取出验证码字符,并且能获得更高的识别准确率。
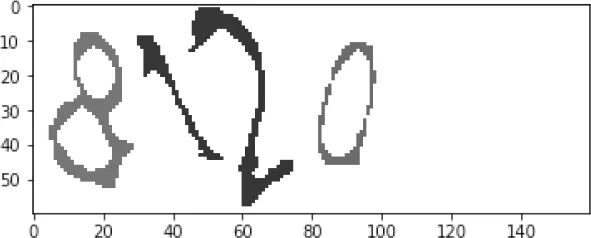
3.2 改进的滴水算法
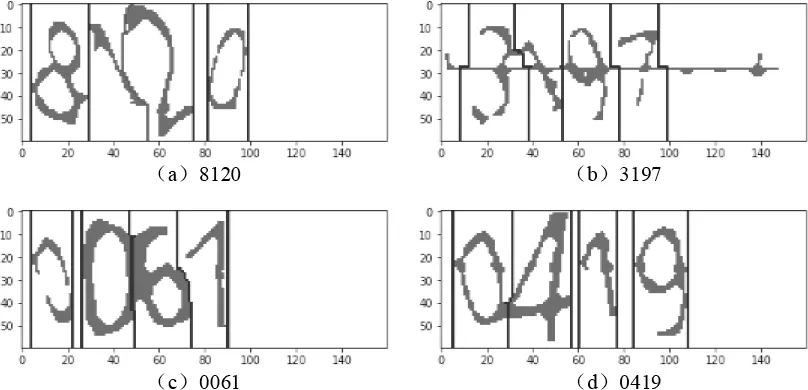
3.3 提取字符
4 字符识别
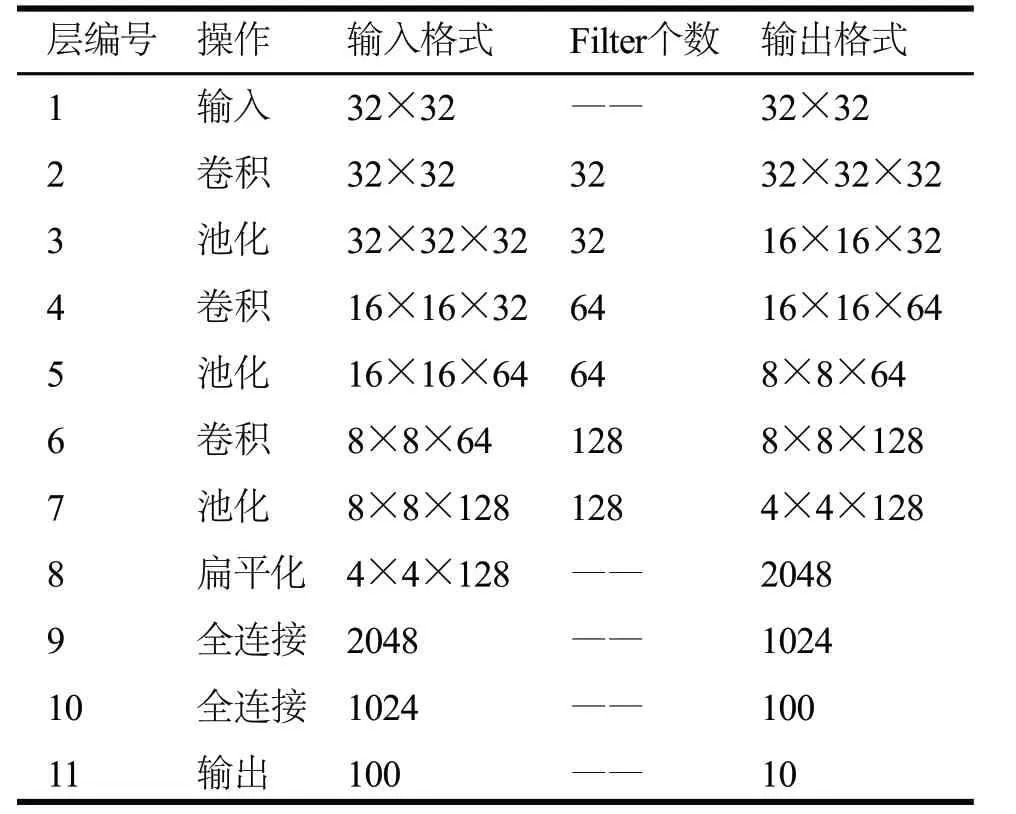
4.1 神经网络结构
4.2 中心损失
5 实验结果
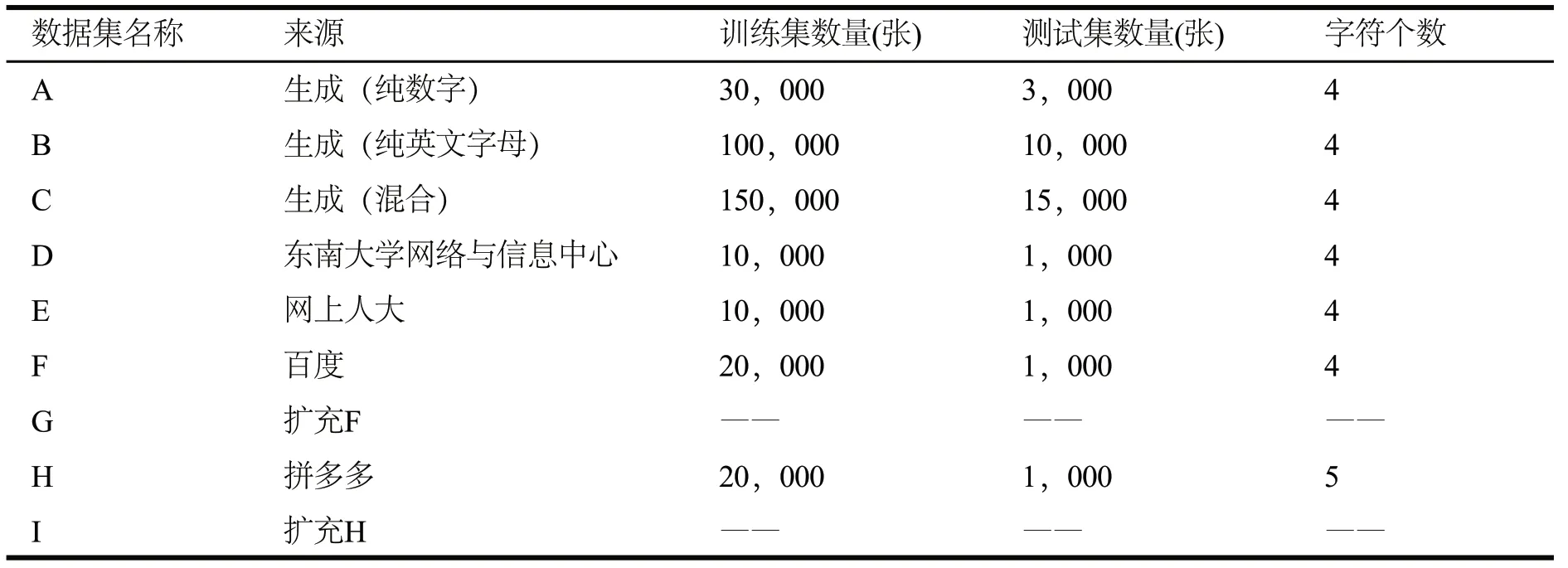
5.1 实验数据集
5.2 字符分割算法评估
5.3 模型评估
6 结束语
猜你喜欢
大众文艺(2021年20期)2021-11-10
电脑报(2021年41期)2021-11-04
大众文艺(2021年15期)2021-08-25
华人时刊(2021年19期)2021-03-08
喜剧世界·中旬刊(2020年7期)2020-09-10
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
幼儿教育·父母孩子版(2017年1期)2017-04-05
艺术评论(2017年12期)2017-03-25
科学启蒙(2015年6期)2015-08-04
