
融入Attention机制改进Word2vec技术的水利水电工程专业词智能提取与分析方法
2020-09-08 05:56李明超JonathanShi
水利学报 2020年7期
李明超,田 丹,沈 扬,Jonathan Shi,韩 帅
(1.水利工程仿真与安全国家重点实验室 天津大学,天津 300350;2.中国长江三峡集团有限公司,北京 100038;3.College of Engineering,Louisiana State University,Baton Rouge,LA 70803,USA)
1 研究背景
在水利水电工程建设过程中,产生了大量对水利水电工程施工过程反馈、管理评估、质量验证等具有重要作用的文本,增加了文本管理与分析的难度[1-2]。在文本管理与分析中,自然语言处理(Natural Language Processing,NLP)技术具有较高的应用率与可靠性,能够实现海量文本数据的系统管理。虽然NLP技术在文本分析中取得较大发展,但现有的NLP术语研究主要针对日常生活用语,较少涉及具体专业领域。基于此,不同领域的学者目前都针对自己的领域发展专业性较强的NLP技术,增强NLP技术在专业领域的应用能力[3]。然而,针对水利水电工程专业的NLP技术尚处于起步阶段,未形成具体的专业文本识别提取与分析体系。
采用NLP技术分析水利水电工程专业文本最关键的环节之一是专业词识别,在海量的多源文本中准确提取专业词,有利于提高专业文本信息分析的准确率。现有NLP技术缺乏完善的水利水电工程专业词识别方法,难以直接用于水利水电工程专业词提取,同时已有水利水电工程专业词典无法囊括所有专业词,随着施工技术的进步,大量的水利水电工程新工艺、新技术被开发,同时产生许多新的专业词[4]。水利水电工程专业词智能识别能有效提高水利水电工程管理信息的理解与分析效率,便于在工程各阶段快速查找与反馈工程内容,完成海量工程信息检索,增强工程管理效率,提高对施工现场的管理效果,对于水利水电工程质量、进度、成本、安全等管理与评价具有重要意义。因此,建立实现水利水电工程专业词识别体系,智能化识别提取文本中的新旧专业词,构建丰富水利水电工程专业词库,是当前亟待解决的问题,对于水利水电工程文本分析尤为重要。
已有的专业词识别方法主要分为有监督方法与无监督方法两种[5]。有监督方法以统计学为基础,主要包含经典统计学、隐马尔可夫、袋决策树、信息熵、条件随机场等模型。经典统计学主要以专业文本为对象,利用SPSS 等统计软件,统计文本中关键词、主题词的出现频率,获取词语共现矩阵,确定文本专业词汇,阐述文本主题[6-7];隐马尔可夫模型将专业词提取问题转化为序列标记问题,集成词汇信息与专业词句法信息[8];袋决策树模型是以词频为基础,提取文本中的专业词;信息熵模型结合词频与共现频率,计算词语间的关联度,实现专业词的识别[9];条件随机场模型考虑词语上下文信息与位置关系,从单词本身、单词在组合型术语中的位置、词频等多个角度出发,完成专业词识别[10]。上述有监督方法主要从统计学的角度实现专业词的识别,对文本中语义分析不足,使得专业词识别的准确性降低。与有监督方法不同,无监督方法将统计学与神经网络技术相结合,关注文本内容与词语语义,将专业词与文本内容相结合,进而提高专业词提取的准确性[11]。无监督方法主要通过语义分析、主题提取、序列标记、文本分类等方式,识别文本中的专业词[12]。Cui 等[13]针对短文本语义分析问题,提出了深度Hashing模型,从语义层面获得文本中的关键术语;Wei 等[14]以文本主题为标准,提出了一种基于条件共现度的语义主题生成方法,提取语义相关的组合词,形成文本主题;陈睿等[15]提出使用双向长短期记忆神经网络和条件随机场进行专业词实体识别问题的序列标记过程,实现实体词语的标记与分类;Hu 等[16]利用RNN提取文本中词语特征,利用词语反映文本信息,实现词语与文本的分类。然而,现有的无监督专业词识别方法所能识别的专业词多为系统提前定义,或结巴(Jieba)分词库中定义的词语,且在日常出现频率较高,对于水利水电工程专业领域的词语识别能力较弱。同时,对于词语间相关性的计算,多是从统计角度出发,缺乏对词语间关系的量化分析[17]。
基于上述分析,本文引入Attention机制对Word2vec技术加以改进,以词向量为基础,计算词语间相关性,提取文本中的专业词,结合专业文本,验证所提取专业词的准确性,构建水利水电工程专业词智能识别提取与分析方法,并结合实际的水利水电工程施工管理文本进行应用分析,为水利水电工程建设与运行智能化管理提供新的技术方法和手段。
2 基于NLP的词向量计算方法
文本量化的主要手段是词向量的计算,词向量计算是NLP的重要基础环节,现有词向量计算方法大多是在神经网络的基础上,进行计算结构与输入模式的改进。
2.1 基于神经网络的词向量计算技术在NLP中存在许多基于神经网络的词向量计算技术,如:神经网络语言模型(Nerual Network Language Model,NNLM)、Word2vec 等,其中,Word2vec是由Miko⁃lov T 在2013年提出[18],在词向量计算中被广泛应用[19]。在Word2vec计算词向量之前,需要对文本进行分词。在目前已有的中文分词系统中,Jieba分词具有较高普遍性与可靠性,能够实现基础词汇的识别与标注[20]。
在词向量计算方法中,应用最普遍的是Word2vec技术[21]。根据语言表达习惯,以Jieba分词结果为导向,Word2vec技术的主体理念是根据句子中词语间相互作用关系,定义语句中第n个单词的出现概率受前面n-1个单词的影响,如下式:
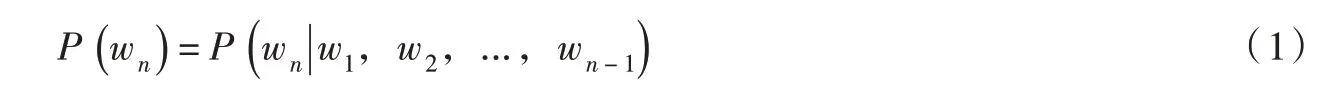
式中:P(wn)为语句中第n个单词出现的概率;w为语句中的单词。
Word2vec技术中包含了2种不同的词向量计算模型:CBOW(Continuous Bag-of-Words)模型与Skip-gram模型[22]。由于Skip-gram模型的预测次数多于CBOW模型,训练时间比CBOW模型要长,适合数据量较少的计算,对于文本量较大的数据计算复杂度较高,与Skip-gram模型不同,CBOW模型适合文本数量较大的运算,具有较高的计算精度。因此本文采用CBOW模型,其核心思想是利用文本中上下文内容来预测句子中某位置可能出现的文字,是一种根据历史词语信息预测当前词语出现概率的模型,框架结构如图1所示[23]。
CBOW模型主要采用三层神经网络训练词向量,处理词之间的关系,模型输入是某个特征词上下文相关词的词向量,模型输出是该特定词的词向量,隐含层主要通过输入词向量训练并预测特定词的向量[24]。在CBOW模型中训练目标是最大化对数似然函数L[25]:
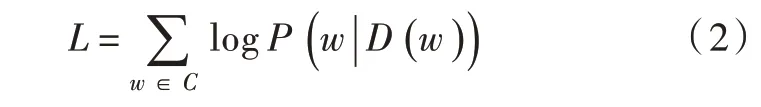
式中:D(w)表示语句中除词语w以外的其他词语;w为语料库C中的任意一个词语。
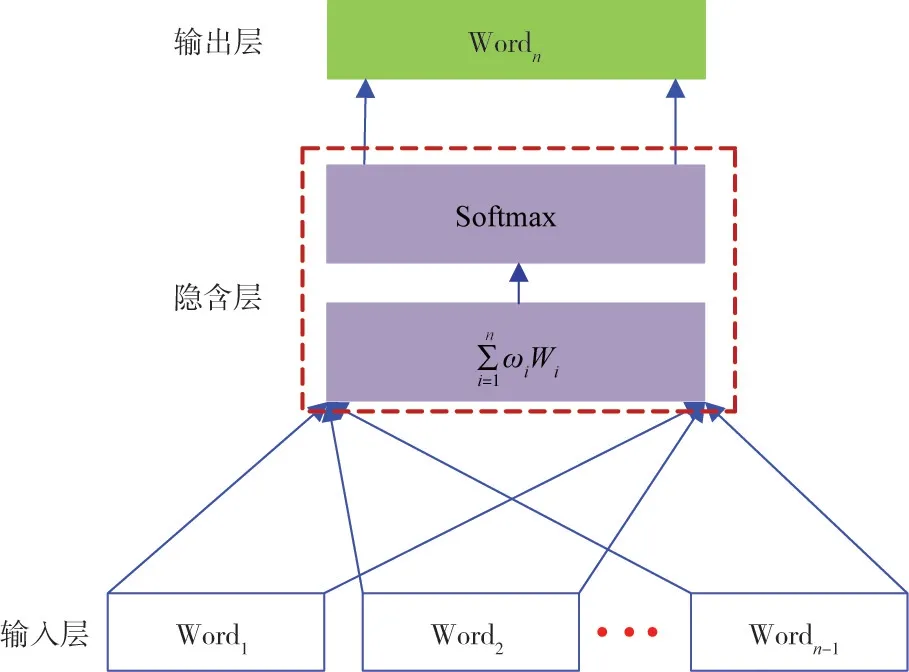
图1 Word2vec神经网络结构
以对数似然函数为导向,计算语料库中词w 在文中出现概率,实现特定词的预测;以预测特定词与实测特定词相似度最大为目标,反馈修正输入词的词向量,得到最终词向量Vword。
2.2 Attention机制随着神经网络技术的逐步发展,Attention机制广泛应用于NLP技术中,对提高文本分析准确度具有重要作用[26]。Attention机制的本质主要来自于人类的视觉注意力机制,人们在观察认知事物时,不是从头到尾的关注,而是对有注意的部分关注,当遇到相似场景时,也会将注意力放到该部分上,进而实现对事物的认知[27]。Attention机制主要用于提升神经网络学习的效果,经常与编码-解码模型结合使用,将编码的数据通过Attention机制进行筛选,再输入解码模型中,提高数据计算的准确性[28]。与传统的编码-解码过程不同,融合Attention机制的编码-解码过程主要采用动态的语义编码,实现不同文本环境下的语义解码。因此,在文本分析过程中,Attention机制的实质主要是实现不同文本语句环境下的权重学习,将学习权重与编码后的输出相关联,作为解码的输入,进而有针对性地实现文本的解码。在Attention机制计算过程中,主要是实现一个查询到一系列键值对的映射,如下式所示[29]:
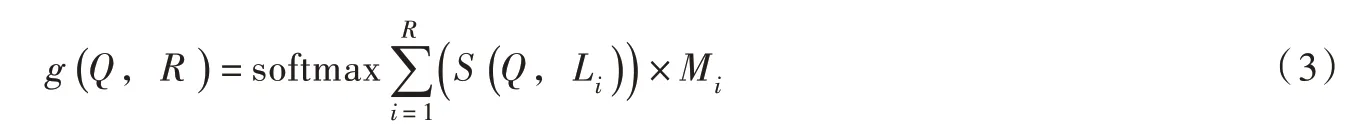
式中:g(Q,R)为一个查询到一系列键值对的映射函数;Q为一个查询的值;L为Attention机制中的一个键值;M为键值集合R中的一个值。
通过式(3)可以看出,Attention机制计算主要分三阶段:第一阶段是将查询值Q与每个键值L 求相似度;第二阶段是使用softmax函数(Normalized exponential function)对相似度进行归一化;第三阶段是将键值M与相应权重进行加权求和,得到最后注意力值。
3 水利水电工程专业词智能识别提取与分析方法
3.1 改进Word2vec技术的词向量计算模型建立水利水电工程专业文本中包含许多专业词,目前常用的Jieba分词无法准确识别;而且文本资料整理人员语言描述规范性问题,使文本中常存在专业词与口语混杂的现象,严重影响文本提取分析的准确性。Word2vec技术是基于Jieba分词基础上进行,分词的准确性直接影响词向量的准确性[22]。同时,文本语言上的不规范,易出现意思相近句子在语言表达上的差异,加之口语化词汇以及文本中停用词(如“的”“了”等)的干扰,使得词向量计算难度增大。
为避免文本中的干扰词的影响,结合中文文本的行文规范,从主谓宾三个主要句子成分出发,提取文本语句中的关键词,减少文本中无关词的干扰。Attention机制能够快速定位文本中的焦点信息,依据少量文本信息做出准确判断,从海量文本信息中过滤无效信息[24]。因此,为提高水利水电工程文本词向量计算精度,在Word2vec技术中引入Attention机制,在Word2vec的输入层与隐含层之间,加入Attention机制,如图2所示,实现对文本中口语化表达与干扰词的过滤,完成对关键词的提取。
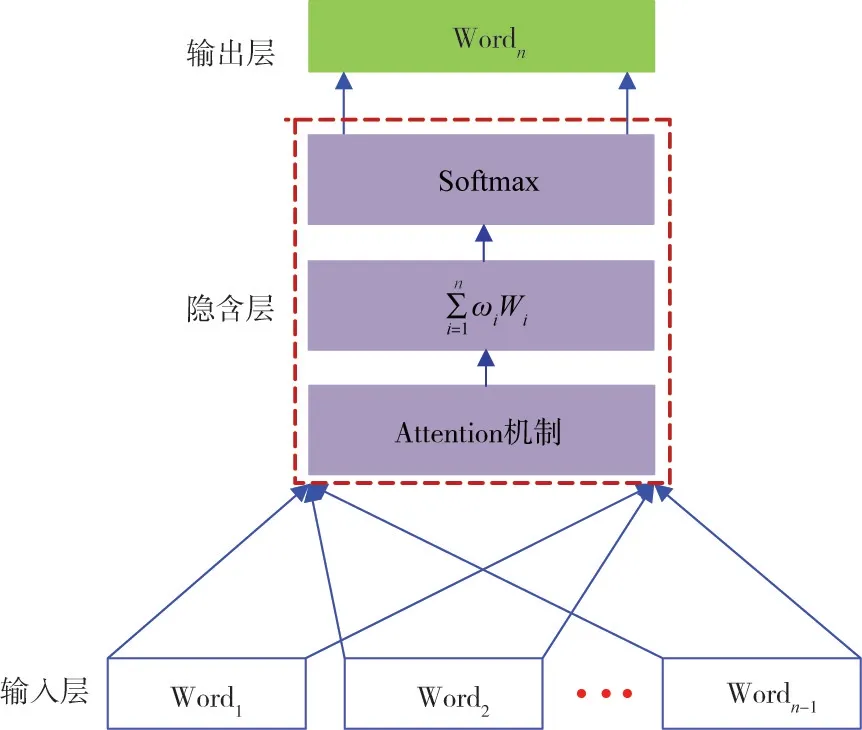
图2 Word2vec+Attention机制网络结构
经过Attention机制处理后的Word2vec输入可表示为:
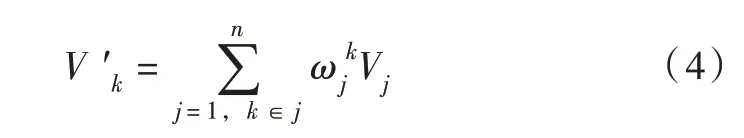
式中:V′k为Attention机制处理后第k个词的Word2vec输入;Vj为第j个词的one-hot向量,one-hot 向量是文本单词量化的一种形式,以0-1表示词语在文本中是否出现,进而将每个词表征为一个多维向量,以便于文本计算;ωjk为计算第k个词向量时第j个词的权重,计算式如下:


式中:Wk、Uk是由文本中单词共现性确定;Zk为注意力模型中需要训练的参数。
在Word2vec+Attention机制中,Attention机制的输出为Word2vec 隐含层输入,经过隐含层计算后,得到文本处理后的第n个单词的词向量,计算式如下所示:
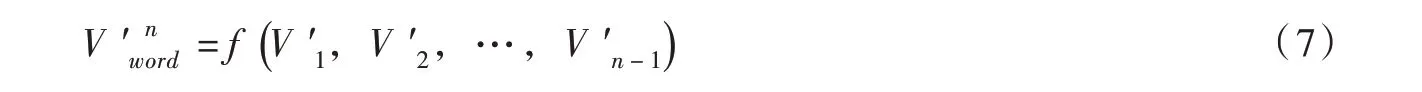
式中 f(V′1,V′2,…,V′n-1)为Word2vec中隐含层函数。
3.2 基于词向量的水利水电工程文本专业词识别提取在水利水电工程文本中,受中文表达规则与习惯的影响,存在许多不同形式的标点符号与停用词,在进行专业词提取中,需要删除文本中的停用词、阿拉伯数字、标点符号与特殊符号等,以提高文本分析的准确率,减小系统的计算负荷[30-32]。
在水利水电工程建设与运行中,受专业对象的限制,工程文本中许多专业词会重复出现,以保证文本内容描述的准确性与丰富性。在专业词的提取过程中,常常会出现以下三类问题:(1)部分专业词仅出现在特定的文本部分,具有一定针对性,在文本中出现频率较低,无法通过统计频数的方式获取;(2)受Jieba分词库的限制,部分专业词无法准确识别,导致许多专业词可能被分割为多个词组成。因此,在统计专业词时,会出现许多单个词不是专业词,但组合在一起就形成了专业词的现象;(3)在文本表达过程中,由于语言表达规范问题,部分专业词可能出现表达上的口语化现象(如安全的管理、质量的控制等),导致在分词过程中,专业词组成词无法相邻,专业词组成词之间出现其他词语,使得专业词无法直接被识别。
为解决上述问题,融合词向量计算过程,分析水利水电工程文本中词语关系,发现如下规律:(1)频率低专业词的组成词之间共现频率较高,但与其他词之间的共现频率较低;(2)无论专业词的组成词是否相邻,专业词的组成词在同一句话中的共现频率较高;(3)文本中词之间共现频率越高,词语间相似度较高[33]。基于上述三个特征,结合文本词向量,计算词语之间的相似度,利用相似度判别词语间的相关性大小,发掘文本中的低频专业词,处理文本中的口语化表达,将相关性较大的词进行组合形成初始专业词。词语相似度计算公式如下:

式中:Ski为文本中词i与词k之间的相似度;V′为词向量。
在文本中不是每个词都能组成专业词,因此,为减小专业词提取工作量,将某个词的相似度进行降序排列,取每个词相似度最大的前m个词进行组合,公式如下:

式中S ′k为词k 相似度最大的前m个词集合。
在集合S ′k中,当词k与词i 具有较高相似度时,以词k为主体,词i组合在词k的右边,逐步提取专业词,形成初始专业词集合T。
3.3 识别提取可信度验证可信度是指初始专业词集合中专业词的可信程度,即判断专业词的专业性与独立应用性。以词间相似度为衡量指标,在初始专业词集合中,每个词都有m个相关词与之组合,词语的组合形式存在以下两个问题:(1)由于文本词语众多,专业词的组成词较少,存在许多干扰词,在专业词的提取过程中,干扰词也会逐一组合,成为初始专业词集合T中的元素;(2)以相似度为衡量标准,组合专业词的组成词,会出现两种组合结果,但专业词只满足其中一种组合,因此,初始专业词集合T中存在专业词组合错误的元素。因此,需构建专业词评判标准文本,对组合的专业词进行进一步判断,验证专业词的正确性。在水利水电工程建设与运行过程中,为规范工程管理过程,理清管理思路,构建标准工程建设体系,存在许多专业书籍、国家标准和行业规范等,包含了大量规范的专业词。基于这些标准文本,判别初始专业词集合中的元素是否在标准本中出现,统计初始专业词集合中元素在标准文本中的出现频率,归纳出现频率大于0的词,验证初始专业词集合T中的词是否在标准文本中出现;如果出现频率等于0,则表明该词属于干扰词与错误组合词,应将该词剔除,进而判断该词是否被标准文本使用,排除初始专业词集合T中的干扰词及错误组合,实现专业词的识别。
文本中的专业词并非只包含两个组成词,存在多个组成词的情况,对于标准文本验证后的专业词,可能属于某个专业词的组成词。因此,标准文本验证后的专业词存在以下两个问题:(1)文本中词的组合主要涉及的是两个词的组合,在实际分词过程中,部分词可能被分成三个或者三个以上的组成词,进而导致两两组合出现误差;(2)当一个专业词有多个组成词,无法判断专业词组成词是否属于专业词。如果某词被标准文本验证后的专业词只能作为其他专业词组成词,不能被独立使用,但由于专业词组成词与专业词会同时出现标准文本中,会被标准文本验证,从而造成专业词识别错误的情况。
针对文本中多个词语组合问题,将已识别的专业词导入Jieba分词库,多次迭代专业词识别流程,进而识别多个词语组合的专业词;针对专业词的组成词是否是专业词的问题,存在两种不同的情况:一种是验证后的专业词属于独立专业词,可以单独使用;另一种是验证后的专业词不属于专业词,不能单独使用,仅仅是其他专业词的组成词。结合上述两种情况,可以得到词语独立性是判断专业词组成词是否是专业词的关键。词语独立性是通过对比专业词组成词与专业词在标准文本中的出现频率来实现,如果专业词组成词与专业词具有相同的出现频率,专业词组成词不是专业词;如果专业词组成词与专业词具有不同的出现频率,专业词组成词是专业词。具体如下式所示:
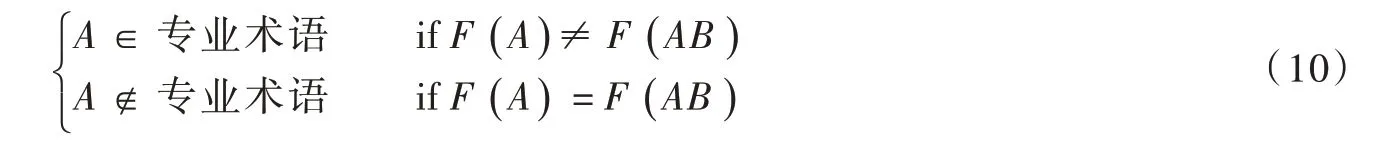
式中:词语A是专业词AB的组成词,两者属于真包含关系;F (A)与F (AB)分别表示词语A与专业词AB 在标准文本中的词频。
当某两个词在标准文本中的词频相同时,且一个词是另一个词的组成词,则表示该组成词在标准文本中不能独立应用,只能以组成词的形式出现,无法定义其为专业词。
综上所述,水利水电工程专业词识别提取的验证过程如图3所示。
3.4 方法实现结合水利水电工程专业词提取与可信度验证过程,其方法实现流程如图4所示,具体操作步骤如下:
(1)预处理水利水电工程专业文本,收集权威书籍、标准规范等标准文本,对文本进行分词;(2)利用标准文本进行识别,筛选出现有Jieba分词能够直接识别的专业词;
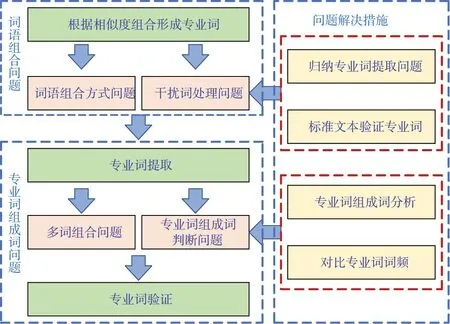
图3 专业词识别验证流程
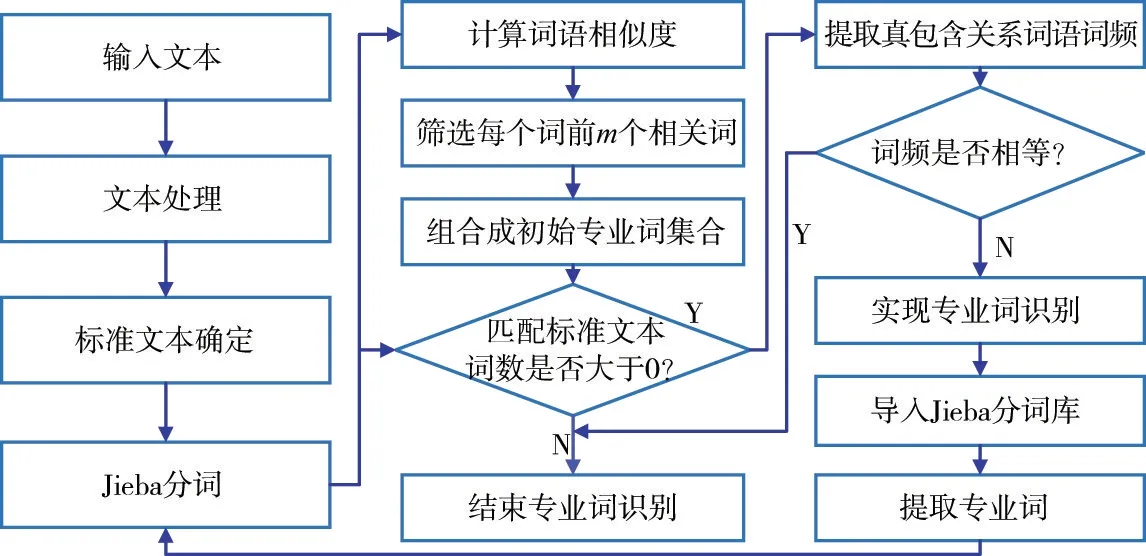
图4 水利水电工程专业词识别提取实现流程图
(3)计算文本中词语间的相似度,将文本中的词两两组合,形成初始专业词集合,利用标准文本进行提炼,实现专业词识别;
(4)将已识别的专业词导入Jieba分词库,对文本进行Jieba分词,组合形成的专业词词向量为组成词词向量加权平均,计算分词后词间相似度,利用标准文本,验证专业词的可信度;
(5)统计已识别的具有真包含关系专业词,即专业词与专业词组成词,计算专业词在标准文中的出现频率,利用式(10)进一步提炼专业词;
(6)重复步骤(4)和步骤(5),直到最终没有新的专业词被识别为止。
4 实例应用与分析
某混凝土大坝施工周期为54个月,期间由监理单位监督管理整个工程施工进度、质量、安全、环保等,总共获得施工监理周报229期,包含工程进度、工程质量、工程安全、环保控制、设计管理、施工资源和监理管理等主要内容,详细记录了施工过程中各个工程管理细节、施工工艺等,每期约10 000字(不包含图片),文本信息丰富,含有大量的专业词,采用所提出的方法对专业文本进行智能识别提取与分析。
4.1 专业文本词向量计算在进行专业词识别之前,需预训练文本的词向量。为保证文本词向量的准确性,在词向量计算过程中,无须预处理文本,尽量保持文本结构完整。以原有Word2vec技术中神经网络结构为基础,构建Word2vec+Attention机制计算网络,定义向量维度为128,计算文本的词向量,得到每个词的词向量。为验证所得词向量的准确性,以Word2vec+Attention机制计算得到的词向量为基础,对比Word2vec得到的词向量。将模型迭代20次,计算Word2vec与Word2vec+Attention机制的损失值,如图5所示。
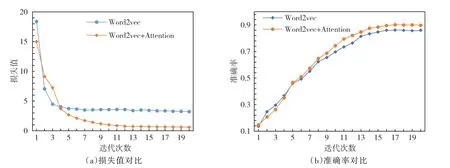
图5 Word2vec+Attention机制损失值与准确率
以损失值与准确率为评价指标,据图可知当迭代到2、3次时,Word2vec+Attention机制的损失值大于Word2vec,当迭代次数大于4次时,Word2vec+Attention机制的损失值小于Word2vec。Word2vec与Word2vec+Attention机制准确率随着迭代次数的增加逐渐增加,最终趋于稳定,Word2vec的准确率为86.78%,Word2vec+Attention机制的准确率为89.73%,验证得到Word2vec+Attention机制在词向量的计算结果优于Word2vec。
4.2 专业词识别提取监理周报内容信息来源于施工现场,真实反映水利水电工程施工现场进度、质量、安全、环境等问题。在监理周报中,存在许多结构化数据与非结构化数据混合的表格,为充分分析文本内容,需要提取表格中的文本信息。同时,对于文本中的一些标点符号与特殊符号需要进行清洗,以减少数据运算压力。在水利水电工程专业词识别过程中,由于阿拉伯数字与计量单位在专业词中的出现频率较低,在文本预处理过程中,将施工管理文本中的阿拉伯数字、计量单位、标点符号、特殊符号、停用词去除,进而减少计算难度,保证专业词提取精度。
为验证所提取专业词的准确性,以水利水电工程施工监理管理工作为基础,收集行业内权威的书籍、标准规范、部门规定、管理手册等,作为验证专业词的标准文本。结合该工程监理报告编写依据与行业相关的专业书籍,收集了相关专业书籍、国家标准和行业规范[34-39],将提取的专业词与上述标准文本进行匹配,实现专业词的识别。
利用Jieba分词处理预处理后的文本,分词后的文本中包含10 541个词,经过标准文本过滤后,得到136个专业词词云与频率,如图6所示。
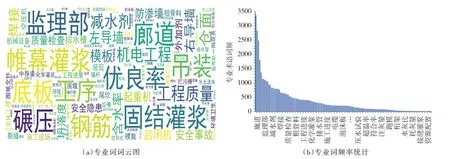
图6 水利水电工程专业词词云与频率
水利水电工程监理周报中存在大量专业词,Jieba分词无法准确识别,因此,为解决这个问题,将136个专业词导入Jieba分词库,对文本进行二次分词,在Word2vec技术中引入Attention机制,将词向量维度定义为128,计算每个词的词向量,依据式(8),计算得到词之间的相似度。定义每个词最相关的前8个词作为专业词组成词,最终得到如表1所示的词语间相似度及相关性较强的词语。

表1 相关性较强词语
利用标准文本对每个专业词进行验证,得到最终的专业词。将已识别的专业词导入Jieba分词库,对监理周报进行再分词,专业词的词向量等于其组成词词向量加权平均,根据词向量计算词语间相似度,利用标准文本验证专业词,进一步识别提取新的专业词。逐步重复专业词生成过程,直到新生成专业词在标准文本中的出现次数为0为止。在新生成的专业词中,存在一些常规语言表达、不完全描述、专业术语组成词等,这些词都属于干扰词。常规语言的表达结构不属于专业名词,可以独立表达句子含义,如“近期阴雨天气较少”“留待日后统一处理”等;不完全描述主要包含两个方面,一方面是还未描述完全的句子,如“监理对表面质量”“使用情况进行”等,另一方面是由于在预处理阶段,删除了数字与特殊符号,进而形成的不完全描述,如“完成量占设计量”“本周投入运行”“累计生产混凝土约”等。将新生成专业词中的干扰词剔除,统计剔除干扰词后的专业词数量,计算专业词提取准确率。与专业词提取可信度不同,专业词可信度检验是一种判断流程,主要是为判断初始专业词集合中词语的专业性与独立应用性,准确率则是表达在经过专业词智能提取后,所形成专业词的准确程度,如下式:

以229份监理报告为对象,最终经过3轮迭代,在第4轮迭代时,通过标准文本检验的单词数为0,因此,只需3轮迭代计算完成专业词的识别,各轮次的识别结果如表2所示。
经过3轮专业词识别提取,采用融入Attention机制的Word2vec技术得到9034个专业词,以专业文本为依据,逐一判别所提取专业词的正确性,准确提取的专业词为7912个,准确率为87.58%,总体识别精度较高;加上Jieba分词直接识别的专业词,总共得到有效水利水电工程施工管理专业词8048个。
通过对比Word2vec+Attention机制与单独采用Word2vec技术的专业词识别准确率,可以得到单独采用Word2vec技术专业词数为8575个,其中准确提取的专业词数为7085个,准确率为82.62%,低于Word2vec+Attention机制的专业词识别精度。单独采用Word2vec技术无法识别一些语言表达上的误差,例如工程质量的评定、齿槽混凝土的质量、细骨料中石粉含量的合格率等,进而导致专业词识别数量与准确率降低。同时对比识别提取过程中的准确率,可以看到Word2vec+Attention机制在各迭代轮次的准确率比单独采用Word2vec技术有较大提升,进一步验证了融入Attention机制的Word2vec技术的有效性。对比Word2vec技术与Word2vec+Attention机制的计算时间,Word2vec技术完成3轮迭代所需时间为276 min,Word2vec+Attention机制完成3轮迭代所需时间为384 min,由于Attention机制突出强调了各个句子中重点词,从而增加了计算步骤,所以时间会增长,但相较于Word2vec技术,Word2vec+Attention机制计算时间增加值较小,且有效的提高了专业词提取准确率与计算精度,因此从运行效率的层次说明了Word2vec+Attention机制的可操作性。此外,无论是Word2vec技术还是Word2vec+Attention机制,各轮次准确率的变化趋势基本相同,随着轮次的增加,专业词识别的准确率逐步降低。这是因为,Jieba分词直接识别的专业词主要属于基础专业词,第一轮识别提取的专业词组成词多为基础专业词,组成词个数较少,词语组合的复杂度较低,专业词识别的准确度较高;在第二、三轮识别提取过程中,专业词的组成词个数增加,词语的组合形式及表达形式更为复杂多样;同时,随着专业词组成词数量的增加,专业词应用频率较低,导致专业词判别出现误差,进一步影响专业词识别的准确率。
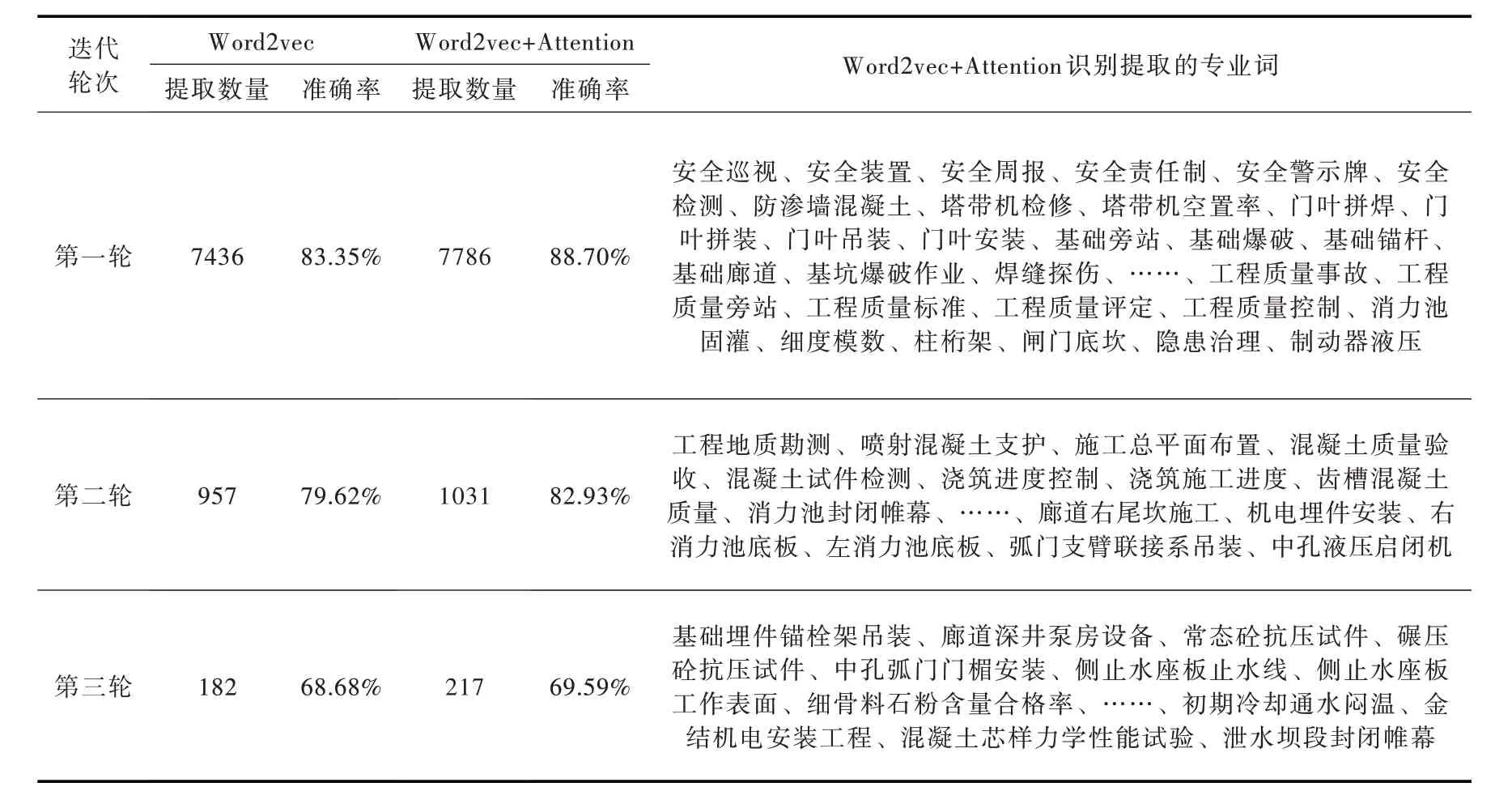
表2 各轮迭代专业词识别提取结果
5 结论
本文将Attention机制融入Word2vec技术,计算了专业文本词语相似度,实现了水利水电工程专业词的智能识别提取与分析,得到以下结论:
(1)在已有Word2vec技术的基础上,引入Attention机制,关注专业文本语句中的重点词汇,构建了Word2vec+Attention机制的改进算法,计算文本词向量;以词向量为基础,计算词语之间的相似度,获得相关性较强词语组合,依据专业文本判断专业词的正确性,提出了水利水电工程专业文本智能分析方法,实现专业词的识别提取。
(2)以实际水利水电工程监理周报为实例,根据所建立的专业词识别体系,计算监理周报词语间相似度,提取监理周报中的专业词;引入与监理管理相关的专业文本,验证专业词的准确性,实现专业词进一步提炼;经过3次专业词识别,获得专业词9034个,识别准确率为87.58%,验证了所提出方法的有效性和准确性。
(3)专业词的识别能够提高文本分词质量,提升水利水电工程信息的分析效率,为水利水电工程文本智能管理奠定基础。但是,在水利水电工程施工管理专业词识别过程中,存在大量的标准文本,标准文本的深度与广度影响着专业词识别的准确率。因此,需收集更多水利水电工程专业文本,进一步提高专业词识别提取的准确率。同时,在准确率的判断过程中,还存在人工判断过程,可能出现人工误差,在后期需要进一步修正,提高计算精度。
因此,结合专业词识别方法,在下一步研究中,以已识别专业词为基础,利用深度学习算法,分析文本信息间的相互依存关系与语义结构,提取水利水电工程文本中的关键知识与重要信息,构建面向文本数据分析的水利水电工程文本信息的智能分类与检索体系。实现文本数据的深度挖掘,增强水利水电工程文本分析管理效率,为水利水电工程信息化与智能化管理提供新的手段。
猜你喜欢
建材发展导向(2022年12期)2022-08-19
建材发展导向(2022年2期)2022-03-08
湖南水利水电(2021年6期)2022-01-18
建材发展导向(2021年6期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
校园英语·月末(2021年13期)2021-03-15
健康体检与管理(2021年10期)2021-01-03
智富时代(2019年6期)2019-07-24
