
基于全卷积神经网络的黄花梨采收期可见-近红外光谱检测方法
2020-09-05 04:12刘辉军魏超宇
光谱学与光谱分析 2020年9期
刘辉军, 魏超宇, 韩 文, 姚 燕
中国计量学院计量测试工程学院, 浙江 杭州 310018
引 言
果实采收期的成熟度决定了水果最终食用品质和商业价值, 选择果实最佳的采收时间, 是降低水果损失率和提高水果品质的关键。 近红外光谱技术在水果品质检测领域已有大量成功应用, 其快速、 无损的特点, 非常适合用于水果生长状态、 成熟度和采收期等方面的持续性检测, 尽管一直受到学者、 行业的重视, 但相关研究、 应用进展缓慢。
Sharpe等较早发现不同成熟度的梨、 西红柿等漫反射光谱均呈现较大差异, 提出该技术可进行水果成熟度检测[1]。 Peris等通过商业采收前的天数确定苹果的成熟度, 建立了苹果采收期的光谱预测模型[2], 并且发现当不同年份果实品质的变异系数较小时, 模型精度较高[3]。 Zude等利用NIRS技术对3个不同采收期的苹果正确识别率为66%[4]。 Liew等经催熟得到6个不同成熟度的香蕉并建立了其可溶性固形物含量(SSC)和硬度的近红外光谱检测模型, 结果表明单一成熟度模型精度较高, 多成熟度模型预测误差增大[5]。 赵娟等利用多个品质指标提取苹果成熟度SIQI指数, 建立了苹果成熟光谱检测模型, 表明支持向量回归(SVR)分类模型优于极限学习机(ELM)[6]。 McCormick等开发了可用于田间的苹果采收期检测仪, 指出需结合大数据技术, 气候、 果树负载和果径等信息以提高检测精度[7]。
受光照强度、 光质等影响, 水果品质个体差异大, 常用的化学计量学方法需进行复杂的光谱预处理, 所建模型难以满足不同季节、 果园等需求, 是影响近红外光谱技术在水果采收期检测领域应用的主要原因。 卷积神经网络模拟人脑机制获取信息, 可通过自学习逐级进行特征提取, 在目标检测、 图像分类和自然语言处理等领域取得了令人瞩目的成绩。 近年来, 利用卷积神经网络进行近红外光谱处理也倍受关注。 有研究通过PCA方法构建了样本的协方差二维光谱矩阵, 利用CNNs方法进行了近红外光谱土壤含水率预测, 结果表明不同训练样本模型结果趋于一致。 Malek等将CNNs方法用于测量橙汁蔗糖含量、 葡萄酒中酒精含量和肉类脂肪含量的光谱检测, 实验表明当训练样本量较少时, 粒子群优化算法(PSO)优于随机梯度下降法[8]。 Bjerrum等用贝叶斯优化算法调整网络的超参数, 利用CNN-GP结合样本光谱扩增建立了药片中麻醉剂含量回归模型, 模型表现了出较好的传递性能[9]。 鲁梦瑶等采用改进的LeNet-5网络, 利用近红外光谱进行了烟叶产地的分类[10]。 Acquarelli等统计每次迭代后CNNs网络最后一层神经元的正系数频次, 得到其特征分数, 表明对特征光谱区域的选择有较好的解释性[11]。 Cui等通过随机抽取部分样品光谱与CNNs输出分类结果的相关系数得到模型的回归系数, 结果表明CNNs模型与PLS模型相比有更好的精度和更低的噪声[12]。
本研究提出了利用卷积神经网络进行基于近红外光谱的水果采收期检测方法, 研究了黄花梨采收期的端对端检测, 采用了不同年份测试的样品集, 分析了CNNs模型的解释性和泛化能力, 并与偏最小二乘判别(PLSDA)方法结果进行了比较。
1 实验部分
1.1 样品
样品采自杭州市东部的商业果园, 实验前标记了15棵树形、 树龄相近的果树, 每次在果树的东、 西、 南、 北和中方位随机采集样本。 最佳采收期根据果园当年的商业采收期确定, 在商业采收期及前后间隔10 d左右进行3次采样, 分别定义成熟度为1, 2和3。 第一批样品(2016年)每次收集130个样本, 随机选择其中100个样品归入训练集, 其余30个归入测试集, 共300个样品组成训练集, 90个样品组成测试集1。 第二批(2017年)样品每次收集20个样品, 共60个样品组成测试集2。
1.2 光谱测量
实验采用MCS600(Zeiss, Germany)阵列式光纤光谱仪, 光源为CHL600(10 W), 结合自制积分球漫反射附件, 波长范围为500~1 700 nm, 所用软件为Aspect Plus。 沿果实赤道测量对其向光面、 背光面和任一侧面的漫反射光谱, 取三个区域测量的平均光谱为样品光谱。
1.3 建模方法
1.3.1 一维卷积神经网络模型
光谱数据是一维信号, 相邻波长有强的相关性, 样本量少的问题, 采用了包含5层的一维浅层卷积神经网络, 包括1个输入层、 2个卷积层、 1个池化层、 1个全连接层和1个softmax输出层(见图1), 采用误差反向传播算法结合随机梯度下降法进行层与层之间的连接权重调节。 在卷积层中利用多个卷积核提取不同属性的光谱特征, 采用非饱和线性修正单元(rectified linearunits, ReLU)为激活函数, 池化层采用Max-pooling方法进行下采样, 其有利于减少因样本光谱平移、 旋转产生的干扰, 保留主要特征并增大输出特征的感受野。 为进行不同光谱特征的融合, 使用卷积层代替LeNet等网络中输出层前普遍采用的全连接层, 实现了全卷积, 尽管在一维网络中两者具有相同的参数数量, 前者有更明确的物理意义。 输出层使用了Softmax分类器, 将预测结果转换为非负值, 输出类别的归一化概率, 得到黄花梨的采收期类别。
(1)
式(1)中,x为输入向量,wi为第i个神经元对应的权重系数,k为类别数, 取3个类别。
Softmax分类器常采用交叉熵为损失函数, 与传统多层感知器相比, CNN网络的参数少, 结合所用的网络中神经元数目也较少, 未采用随机失活(dropout), 在损失(Loss)函数中加入了L2正则项, 将网络权重控制在较低的水平, 可降低模型的过度拟合并提高模型泛化能力。
(2)
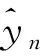
CNNs网络的权重采用随机初始化, 利用第一批390个样品以内部交叉验证法进行网络参数的选择。

图1 卷积神经网络结构
1.3.2 PLSDA
偏最小二乘判别方法(PLSDA)建立在PLS算法基础上, 以二进制类别变量取代目标变量值, PLSDA计算光谱向量与类别向量的相关关系, 常用“1”和“0”来表示属于或不属于某一类, 一般取临界值0.5来判定样品的类归属。
1.4 模型回归系数
相关系数法是近红外光谱模型特征变量波长选择方法, 常用于模型的解析, 通过计算光谱变量与被测量间的相关系数, 系数越大表示对应的波长所含信息量越大, 但其不适用于非线性模型。
互信息是机器学习和数据挖掘的特征选择中常用方法, 可衡量变量间的非线性关系, 互信息值越大表示两个随机变量相关程度越高, 可用于特征波长的筛选。
(3)
式(3)中,X为样品任一波长的光谱反射率,Y为样本类别,p(x,y)为两个随机变量X和Y的联合概率分布函数,p(x)和p(y)分别是X和Y的边缘概率分布函数, 利用校正集样本波长变量与成熟度类别的平均互信息MI(X∶Y)计算CNNs模型中光谱变量与样本类别的相关程度, 以减少互信息MI(x∶y)的随机性。
1.5 模型评价
采用训练集和测试集的判别正确率作为模型评价指标。
1.6 软件
CNNs模型基于Tensorflow平台构建, 利用Python完成编程。 PLSDA模型利用了PLS_toolbox_70工具箱。
2 结果与讨论
2.1 模型结果
PLSDA和CNNs方法模型采用了相同的训练集和测试集。 PLSDA模型中使用了Savitzky-Golay(SG)二阶导数进行光谱预处理, 选用的隐含变量个数为5。 当训练次数为1 200时, 模型达到稳定。 表1为两类模型对黄花梨采收期判别的结果, 训练集和测试集1正确识别率均为100%。 PLSDA模型对测试集2的采收期正确识别率降为41.67%, 最佳采收期的正确识别率仅为40%。 可见, 尽管PLSDA方法常被用于水果成熟度的检测, 但多未采用不同年份样品对模型进行测试。 采收期前后果实内部品质变化复杂, 不同年份果实品质差异大, 同时, 水果类物质含水率高, 近红外光谱谱峰重叠严重, PLSDA方法通过选择隐含变量个数不能有效克服光谱数据的非线性影响, 难以提取样本稳健的光谱特征, 在同一年份测试集中往往有较好的效果, 但不适用于其他年份测试集[13], 模型不能用于不同年份黄花梨的采收期判别。 CNNs模型对测试集2的采收期正确识别率降为88.33%, 最佳采收期的正确识别率为85%, 错误识别主要表现为相邻采收期间的误判, 对不同年份的黄花梨采收期判别有较好的精度。

表1 黄花梨采收期检测结果
2.2 卷积核对CNN模型的影响
由于水果类样品在可见-近红外区域的光谱峰较宽, 为有利于提取谱峰信息, 第1个卷积层中使用的卷积核个数、 长度和步长分别为1~10, 3~50和1~15。 增加卷积核数量, 可以提取更多不同的光谱特征, 但当样品数量较少时, 会降低网络的泛化能力, 考虑所建的CNNs网络规模以及训练样品数量, 当卷积核数为6、 长度为25、 步长为10时, 模型达到最优。 图2为模型训练生成的6个卷积核, 分别如图2(a)—(f)所示。
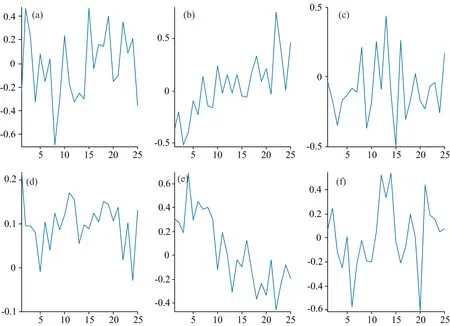
图2 CNN模型中第1个卷积层的卷积核
由于激活函数、 池化等增加了卷积神经网络的非线性, 如何提高CNN模型可解释性是深度学习领域的研究热点, 目前针对光谱处理中CNNs模型解释性的研究较少。 Bjerrum[10]和Cui[12]和等指出, 适当的光谱预处理, 可减少CNNs模型的训练时间, 且对模型精度的影响较小, 本研究所建CNNs模型中未进行光谱预处理。 由图2(a,b,c)分别可以看出, 卷积核的作用类似于不同偏斜、 缩放的一阶SG或分数阶微分, 且均含有大量的非零元素, 表现出较好的平滑性。 其中, 卷积核2和5的变化趋势表明分别进行前向和后向微分, 卷积后结果经ReLU后输出; 当反射率增大时, 卷积核3输出的非零值减小; 当反射率降低时, 卷积核5输出的非零值增大, 有利于在全波段中提取稳定的光谱特征。 在模型训练中, 卷积核参数被不断优化, 较传统方法选择光谱预处理节省了的大量人力, 其可解释性尚待进一步研究, 后者则有较明确的物理意义。
2.3 模型回归系数
两类模型训练集样本波长变量与输出采收期类别间的回归系数如图3, 其中, (a)为黄花梨的平均光谱。 PLSDA和CNNs模型的回归系数曲线均含有一定噪声, 可能由果形变化等因素引起, 但两者呈现较大差异[如图3(b)和(c)所示]。 在PLSDA模型中, 与黄花梨成熟度相关性大的波长主要集中在可见光波段, 800~1 700 nm范围内相关系数接近零, 主要反映了果实成熟期叶绿素、 花青素等含量的变化。 在CNNs模型中, 互信息在0.31~0.42呈较均匀分布, 除可见光波段, 在1 430 nm附近互信息也较强, 对应水分的一阶倍频吸收区域, 主要反映水果的干物质(DM)含量, DM是进行水果成熟度检测中常用指标, 800~1 200 nm区域多用于可溶性固形物含量(SSC)相关的检测, SSC易受冠层条件、 气候等影响, 其较少用做成熟度单一评价指标。 980 nm附近对应水分的二阶倍频吸收, 互信息较低。
PLSDA模型中所用相关波长变量较少, 不能充分反映果实采收期品质变化, 模型易出现过拟合, CNNs模型则较好地利用了样品的全波段信息, 有效避免了模型的过拟合, 且波长变量与黄花梨采收期主要品质变化有较好的相关性及可解释性。
图3 PLSDA, CNNs模型的回归系数
3 结 论
提出一种基于全卷积神经网络的黄花梨采收期近红外光谱检测方法。 设计了一种5层的一维卷积神经网络, 采用交叉熵结合L2正则项为损失函数, 无光谱预处理, 实现了黄花梨采收期的端到端检测, 有利于实现水果分期分批的精细化采收。
(1)利用卷积神经网络良好的自学习功能可有效地提取光谱特征, 避免了复杂的光谱预处理。 通过对PLSDA和CNNs模型的相关系数、 互信息的分析, CNNs模型结合与样品波长变量有较好的相关度, 能较好地反映黄花梨采收期主要品质变化, 且有较好的可解释性。
(2)结果表明与PLSDA方法相比, CNNs模型有较强的泛化能力, 对不同年份样品采收期正确识别率达到88.33%, 有效克服了不同年份样品品质变化对模型的影响。
(3)进一步结合果园管理、 物候等先验信息, 将有利于加快近红外光谱技术在水果采收期、 成熟度检测方面的实际应用。
猜你喜欢
课外生活·趣知识(2021年9期)2021-09-05
航天工业管理(2020年9期)2020-12-28
航天工业管理(2020年1期)2020-04-20
艺术品鉴(2019年9期)2019-10-16
种子(2018年9期)2018-10-15
收藏界(2018年3期)2018-10-10
天然产物研究与开发(2018年8期)2018-09-10
学苑创造·B版(2018年12期)2018-03-04
益寿宝典(2018年25期)2018-01-26
中成药(2017年5期)2017-06-13
