
X射线荧光光谱结合BP神经网络识别进口铜精矿产地
2020-09-05 04:12秦晔琼朱志秀邢彦军
光谱学与光谱分析 2020年9期
刘 倩, 秦晔琼, 刘 曙*, 李 晨, 朱志秀, 闵 红, 邢彦军
1. 东华大学化学化工与生物工程学院生态纺织教育部重点实验室, 上海 201620 2. 上海海关工业品与原材料检测技术中心, 上海 200135
引 言
铜精矿是低品位含铜原矿石经过选矿工艺处理达到一定质量指标的精矿, 是冶炼铜及其合金的基础工业原料。 全球铜矿资源主要分布于北美, 拉丁美洲和中非三地。 按国家分布主要集中在智利、 秘鲁、 美国、 菲律宾等国家。 不同产地来源的铜精矿由于地质成因差异, 主次元素含量存在着一定的区域特征。 中国是全球最大的铜精矿进口国, 2018年进口量为1 972万吨, 同比增长13.7%。 进口铜精矿伪报、 掺杂、 有害元素超标案件多发, 已危害到了国家经济安全。 基于历年铜精矿的口岸检测数据, 建立入境铜精矿产地识别方法, 将有助于风险分级、 预警, 对保障入境铜精矿的安全, 具有重要意义。
梅燕熊[1]等根据全球铜矿资源地质构造背景与成矿特征, 划分了4大成矿域以及21个巨型成矿区带。 其中位于安第斯成矿带的智利和秘鲁, 东亚成矿带的菲律宾属于环太平洋成矿域, 地中海成矿带的西班牙和阿尔巴尼亚、 中南半岛成矿带的马来西亚及西亚成矿带的伊朗属于亚特提斯成矿域。 环太平洋成矿域和亚特提斯成矿域的成矿地质构造背景主要是显生宙造山带, 其次是新生代风化壳。 位于非洲-阿拉伯成矿区的纳米比亚属于冈瓦纳成矿域, 其成矿地质构造背景主要以前寒武纪地块及叠加其上的显生宙沉积盆地和构造带, 其次是新生代风化壳。 由于矿床的成因极其复杂, 导致了矿床的地理位置的不同在铜矿样品的产地识别中具有较大的难度, 以至于到目前为止, 还未见进口铜精矿产地识别的相关报道。
神经网络是一种有监督的模式识别方法, 在光谱分析应用领域方面日益广泛。 Giulio Binetti[2]等应用近红外光谱和核磁共振光谱与人工神经网络相结合的方法对不同品种的特级初榨橄榄油进行品种和产地鉴定。 Moncayo[3]等应用激光诱导击穿光谱与人工神经网络相结合建立一种对红酒原产地保护分级的方法。 孟海东[4]等利用不同矿产品的矿物形态, 物理化学性质不同的特点与BP神经网络结合对铜矿石和铁矿石进行分类识别。 人工神经网络作为一种具有高度非线性映射能力的计算模型, 能进行全局优化, 提高资源预测的准确率[5]。 阴江宁[6]等应用神经网络对化探数据进行金矿床规模和铜矿床类型的分类。 Navid Khajehzadeh[7]等应用X射线荧光光谱结合神经网络对赤铁矿、 磁铁矿、 石英和铁矾矿进行识别。 目前, 尚未发现光谱分析结合神经网络, 应用于铜精矿产地识别的报道。
本课题组应用判别分析对X射线荧光光谱检测的铁矿石进行产地及品牌识别, 其模型对建模样品, 交叉验证和预测样品的识别准确率分别为97.4%, 95.3%, 95.5%和100%, 97%, 100%, 显示出XRF结合化学计量学在矿产品识别上的可行性, 但Fieher判别分析对于线性不可分的情况无法确定分类。 因此本文引入了一种反向传播人工神经网络的机器学习算法, 可看作是Fisher线性判别的一种非线性多维推广。 通过采集来自全国主要铜精矿进出口口岸的智利、 秘鲁、 菲律宾、 西班牙、 纳米比亚、 伊朗、 马来西亚和阿尔巴尼亚8个国家280批进口铜精矿代表性样品(见表1), 应用波长色散-X射线荧光光谱无标样分析法共计检出53种元素, 选择17种元素含量用于判别分析与BP神经网络建模, 对比了这两种方法对铜精矿产地识别的适用性, 讨论不同国别铜精矿的化学成分差异, 通过建模样品验证、 交叉验证以及预测样品验证, 可确证模型的准确性和适用性。
1 实验部分
1.1 样品收集
根据SN/T 4111—2015《进口铜矿石取样和制样方法》, 从我国主要的铜精矿进口口岸采集并制备来自8个国家的进口铜精矿化学分析样品, 共280批次样品。 采集的样品容量大, 分布地域广, 具有一定的独立性和代表性, 包含了我国进口铜精矿主要来源国。 样品信息如表1所示, 所在地理位置如图1所示。

表1 铜精矿样品信息
图1 铜精矿国别分布图
1.2 方法
将样品分装到干燥瓶中于105 ℃下烘干4 h。 采用压片机对烘干样品进行压片, 压片前用乙醇清洗模具, 使用聚乙烯环将粉末样品聚拢, 压制样品在30 t压力下维持30 s。 检查压制样品表面均匀且无裂纹、 脱落现象, 测量前用洗耳球吹净样品表面。
使用德国布鲁克公司S8 Tiger波长色散-X射线荧光光谱仪中的无标样分析方法检测铜精矿中的元素含量。 无标样分析也称半定量分析, WDXRF谱仪半定量分析方法最大的特点是快速。 检测中使用铑靶光管、 三个分析仪晶体(XS-55, PET, LiF200)、 流气计数器(FC)、 闪烁计数器(SC)等元件。
1.3 数据处理
1.3.1 逐步判别-费歇尔判别分析
逐步判别分析属于有监督的分类方式, 先对已知的样品进行分类来建立模型, 再对未知样品进行预测分类。 在逐步判别分析中通过费歇尔分数(F-score)算法[9]进行变量评估和特征选择, 其本质是选取类内差异小, 类间差异大的特征。 具体描述如给定训练样本集Xk∈Rm,K=1, 2, …,n, 其中正类和负类的样本数分别为n+和n-, 则训练样本第i个特征的F-score值定义为
(1)
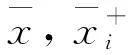
Fisher判别分析的基本原理是投影, 将高维数据投影到某个方向, 使组与组之间区别最大, 组内区别最小, 采用方差分析的思想建立判别函数, 因此只要计算出每个样品在典型变量维度上的具体坐标位置, 再比较它们分别离各类中心的距离, 就可得知它们的分类结果[11]。
本文分析来自我国主要铜精矿进口口岸的8个国别280个铜精矿样品, 应用SPSS 23.0软件建立判别分析模型, 建模过程中选取226个样品作为训练集, 54个预测样品用于检验模型的准确性。 训练样品及预测样品的选取如表1所示。 建立铜精矿产地溯源模型, 首先采用逐步判别分析对O, Mg, Al, Si, P, S, K, Ca, Ti, Fe, Cu, Zn, Mn, As, Mo, Ag和Pb共17个元素进行变量筛选, 变量能否进入模型主要取决于协方差的F检验的显著性水平, 当F-score大于指定值时保留该变量, 而F-score小于指定值时, 该变量从模型中剔除。 选取合适的F-score可用最少的变量达到最佳判别效果。 本文选取的F-score为3.84, 经过逐步判别分析, O, Mg, Al, Si, P, S, K, Ca, Cu, Zn, Mo, Ag, Pb共13个元素留在模型中用于建立判别函数, Ti, Fe, Mn, As因未通过F检验(F值<3.84)而从模型中剔除, 因此可用13个元素建立Fisher判别分析模型。
1.3.2 反向传播人工神经网络
人工神经网络简称神经网络, 是一种基于连接学说构造的智能仿生模型, 由大量神经元组成的非线性大规模自适应动力系统[12]。 目前, 应用最广泛的是反向传播人工神经网络(back propagation artificial neutal networks, BP-ANN), 属于有监督的学习方式, 包括了输入层, 隐含层和输出层[13]。 神经网络拓扑图如图2所示。
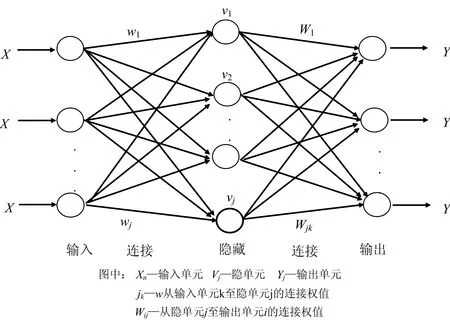
图2 神经网络拓扑图
利用MATLAB R2018a软件平台中的神经网络模式识别工具箱对铜精矿进行分类分析, 在神经网络模式识别进行数据分析前, 将8个国家共280份样品按8: 2的比例分为两部分: 226个建模集和54个预测集。 在建模的过程中, 为确保模型的随机性, 226个样品由计算机按比例自动随机抽取训练集, 校正集与验证集分别为: 70%(138个样品)、 15%(34个样品)、 15%(34个样品), 建立模型, 再利用建立的模型对54份预测样品进行识别。
将X射线荧光光谱测得的O, Mg, Al, Si, P, S, K, Ca, Ti, Fe, Cu, Zn, Mn, As, Mo, Ag和Pb共17种元素含量建立铜精矿识别模型。 由于神经网络模型中的输入层对输出层的结果起决定性作用, 因此考虑将通过逐步判别分析F值筛选的O, Mg, Al, Si, P, S, K, Ca, Cu, Zn, Mo, Ag和Pb共13种元素含量作为输入层建立另一个铜精矿识别模型。 8个不同国别作为输出层, 建立了两个具有10个隐藏层的三层人工神经网络, 即输入层-隐藏层-输出层分别为: 17-10-8, 13-10-8。
2 结果与讨论
2.1 铜矿类型及主要特征
全球铜矿山主要集中分布在北美科迪勒拉铜矿带、 南美安第斯铜矿带、 地中海铜矿带、 冈底斯铜矿带、 西亚铜矿成矿带等铜矿带上。 世界铜矿类型较多, 主要有斑岩型, 砂页岩型、 矽卡岩型、 火山成因块状硫化物(VMS)等[8]。
斑岩型铜矿是一类与浅成, 超浅成中酸性侵入体(斑岩)有关的规模大, 品位低的铜矿床。 集中于环太平洋成矿域、 古特提斯成矿域和古亚洲成矿域。 斑岩型铜矿是目前世界上最主要的铜矿类型, 占世界铜矿资源和产量的一半以上, 如智利(33-42Ma)、 秘鲁(10-20Ma)和菲律宾等国的80%~90%的铜资源来自斑岩型铜矿。 大型的矽卡岩型铜矿通常与斑岩铜矿伴生, 如秘鲁的安塔米纳是主要的矽卡岩型铜矿, 与斑岩侵入系统伴生。 火山成因块状硫化物型铜矿矿床(VMS)是指与海底火山作用有一定联系的含大量黄铁矿和一定数量铜, 铅, 锌的矿床。 如西班牙的里奥延托(铜450×104t, 铜品位0.9%)。 因此位于同一成矿域不同产地的铜精矿具有相同的成矿类型, 使不同产地的铜精矿识别难度增加。
本文收集8个国别的铜精矿样品中除西班牙成矿类型为VMS型, 其余7个国别的铜精矿的成矿类型均含有斑岩型铜矿, 建立识别模型有一定的难度。
2.2 元素的选择
采用波长色散-X射线荧光光谱无标样分析方法对收集的280份已知产地国的铜精矿样品进行检测, 结果表明, 收集铜精矿样品共计能检出53种元素。 这些元素在280个样品中的检出情况为: 100%检出的元素有O, Al, Si, S, Fe和Cu, 检出数量大于85%以上的元素有Mg, Ca, K, Mn, Zn, Ti, Mo, Pb, As和P, 检出比例分别为: 99.29%, 99.29%, 98.93%, 98.57%, 98.57%, 96.07%, 95.36%, 92.50%, 87.50%和87.14%, 检出数量比例低于85%的元素有Ni, Sr, Ag, Se, Er, Cr, Zr, Na, Cl, Bi, V, Sb, Ba, Rb, Cd, Gd, W, Co, Ho, Ce, Sn, Hf, F, Hg, Br, Ga, Nb, Rh, Ir, La, Tl, Sc, Ge, Lu, Te, Eu和Y, 检出比例分别为: 79.64%, 77.86%, 77.50%, 76.43%, 76.43%, 68.57%, 64.29%, 60.71%, 60.71%, 39.29%, 31.79%, 26.43%, 24.64%, 23.57%, 14.29%, 13.57%, 9.64%, 7.86%, 7.14%, 7.14%, 4.29%, 2.50%, 2.14%, 1.43%, 1.07%, 1.07%, 1.07%, 0.71%, 0.71%, 0.71%, 0.36%, 0.36%, 0.36%, 0.36%, 0.36%, 0.36%和0.36%。 建立铜精矿产地识别模型, 考虑到实际应用, 应选择铜精矿样品中检出比例尽量高的元素, 因此选择280个铜精矿样品中检出比例大于85%以上的O, Mg, Al, Si, P, S, K, Ca, Ti, Fe, Cu, Zn, Mn, As, Mo和Pb共16种元素含量作为特征变量, Ag虽检出比例为77.50%, 但确是铜精矿检测合同规格中的必检元素之一, 因此也一并提取, 以上17种元素含量, 如涉及到未检出, 均用检出限含量进行代替。
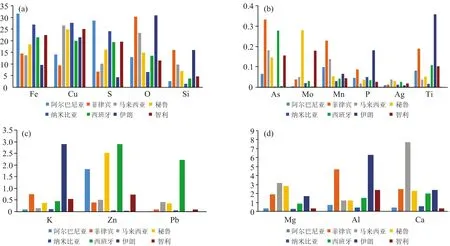
图3 铜精矿样本的元素均值含量条形图
由图3中17种元素8个国别铜精矿含量的均值对比分析表明: 阿尔巴尼亚中的Fe和S含量分别比伊朗的高了约3倍和5.3倍。 菲律宾中的O和Si含量分别比纳米比亚的高了约4倍和13倍, 菲律宾As含量高于其余7个国家, Ti含量仅次于伊朗。 马来西亚中的Cu含量仅次于纳米比亚, Mg和Ca含量均高于其余7个国别。 马来西亚的K和Ti含量均低于伊朗。 秘鲁中的Mo含量比其余7个国别的含量要高出10~100个百分点。 纳米比亚Fe, Cu和S含量均高于其他7个国家的含量, O, Si, Al, Zn, K和As相对其他国家含量偏低。 西班牙Zn和Pb, 含量均比其余国家的含量高出100~1 000的百分点。 伊朗O, Al, K, Mo, P和Ti, 含量均比其余国家要高, 且O和Al在纳米比亚中相对于其他国别而言含量最低。
综合以上元素分析, 阿尔巴尼亚中的Fe和S含量较高, Cu和Ca含量较低; 菲律宾中的O, Si, As和Ti, 含量较高, Cu含量较低; 马来西亚中的Cu, Mg和Ca含量较高; 纳米比亚中的Fe, Cu, S和Al含量较高, O, Si, Zn, K和As, 含量较低; 西班牙中的Zn和Pb, 秘鲁中的Mo, 均高于其余7个国别, 智利铜精矿检测的含量用肉眼很难与其他国家进行比较。 不同国别间的元素含量不同, 对判别分析模型的贡献度不同, 因此后文对这17种元素采用了费歇尔分数对变量进行筛选。
2.3 逐步判别-Fisher判别分析
针对不同进口国别铜精矿建立产地溯源模型, 用O, Mg, Al, Si, P, S, K, Ca, Cu, Zn, Mo, Ag和Pb共13个元素建立Fisher判别分析模型, 得到7个判别函数和相应的组质心处的函数。 取前两个判别函数和组质心处的函数作图如图4所示。
F1=0.069X1+0.251X2-0.213X3-0.045X4-18.201X5+0.033X6-1.529X7-0.033X8+0.138X9+0.001X10+4.499X11-13.889 5X12+2.686X13-3.625
F2=-0.047X1+0.536X2-0.327X3-0.045X4-6.618X5-0.1X6+1.494X7+0.011X8+0.16X9+0.464X10+2.196X11+73.322X12-3.636X13-4.144
F3=0.105X1+0.205X2-0.509X3-0.273X4+13.51X5-0.063X6+3.058X7+0.011X8+0.154X9+0.371X10-0.513X11-40.253X12+2.393X13-4.342
F4=0.056X1-0.012X2+0.111X3+0.14X4-1.643X5-0.096X6-1.048X7-0.161X8-0.03X9+0.626X10+4.268X11+9.56X12+0.659X13-0.668
F5=-0.203X1+0.289X2+0.165X3+0.095X4+4.196X5-0.018X6+0.412X7-0.156X8-0.059X9+0.417X10+4.484X11-25.523X12-0.261X13+3.121
F6=0.237X1-0.117X2-0.736X3-0.255X4+2.821X5+0.144X6+1.591X7+0.139X8-0.131X9+0.364X10+1.444X11+12.061X12-1.055X13-1.539
F7=-0.155X1+0.243X2-0.174X3+0.25X4+28.721X5-0.008X6-1.632X7-0.004X8+0.24X9+0.148X10-2.185X11-15.951X12+0.203X13+0.338
式中,X1—X13分别代表O, Mg, Al, Si, S, P, K, Ca, Cu, Zn, Mo, Ag和Pb含量。
用判别函数1和判别函数2的判别得分作散点图(图4), 判别函数1得分为横坐标, 判别函数2得分为纵坐标, 可以看出模型中的伊朗, 西班牙, 菲律宾, 阿尔巴尼亚质心间的距离较远, 马来西亚和秘鲁, 智利和纳米比亚质心间的距离较近, 在对智利的铜精矿识别中有少数样品落在离纳米比亚, 马来西亚和秘鲁质心更接近的位置。 其原因可能是由于此次分析的样品均为斑岩型铜矿, 成矿类型较为相似, 且智利铜矿的元素特征较不明显, 故被判到其他国别的可能性增加。 用于建模样品的准确率达94.2%, 交叉验证准确率达92.8%, 预测样品准确率达96.7%。 说明此模型可以对铜精矿有较好的识别, 具体的分类结果如表2所示。
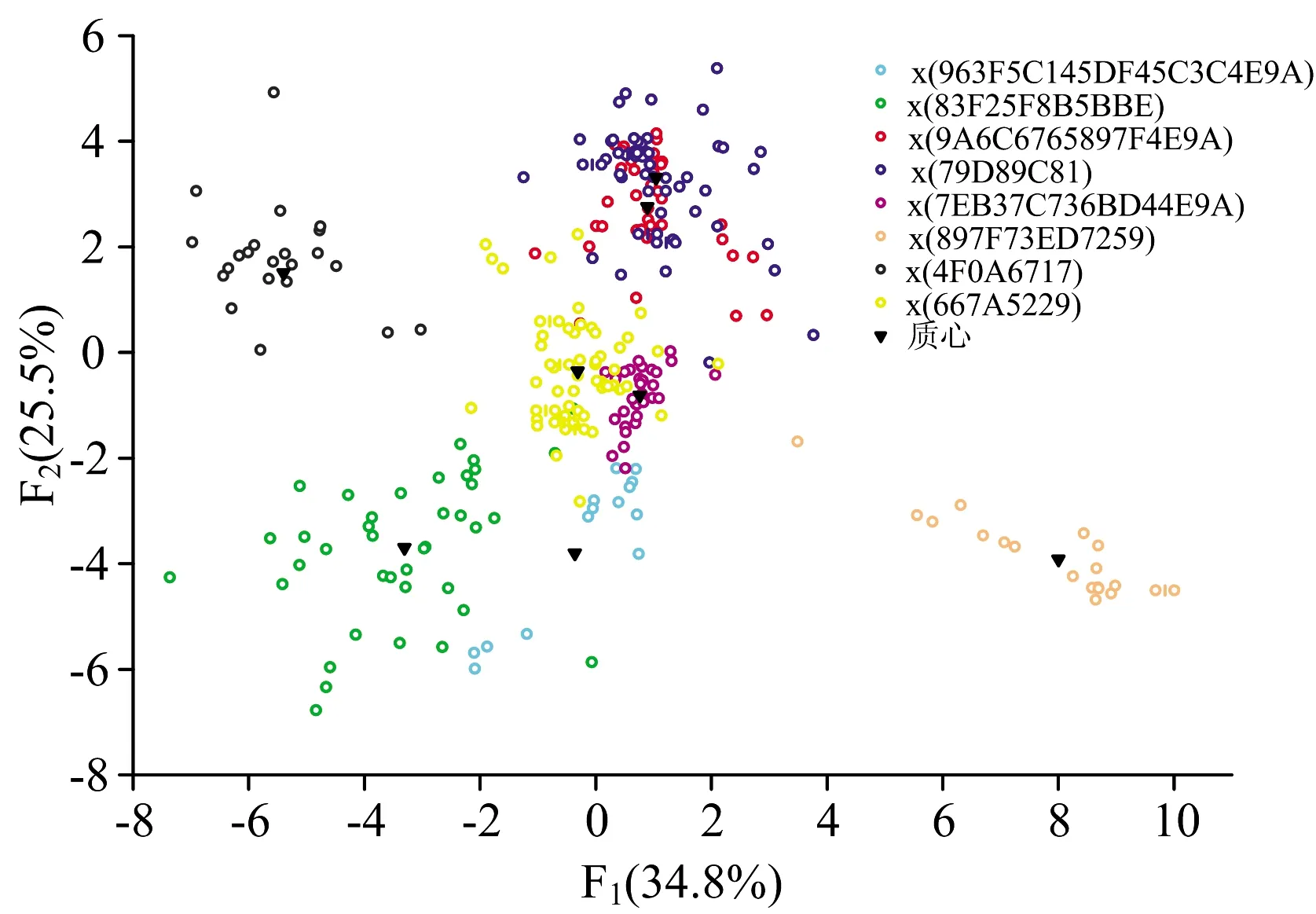
图4 判别函数散点图
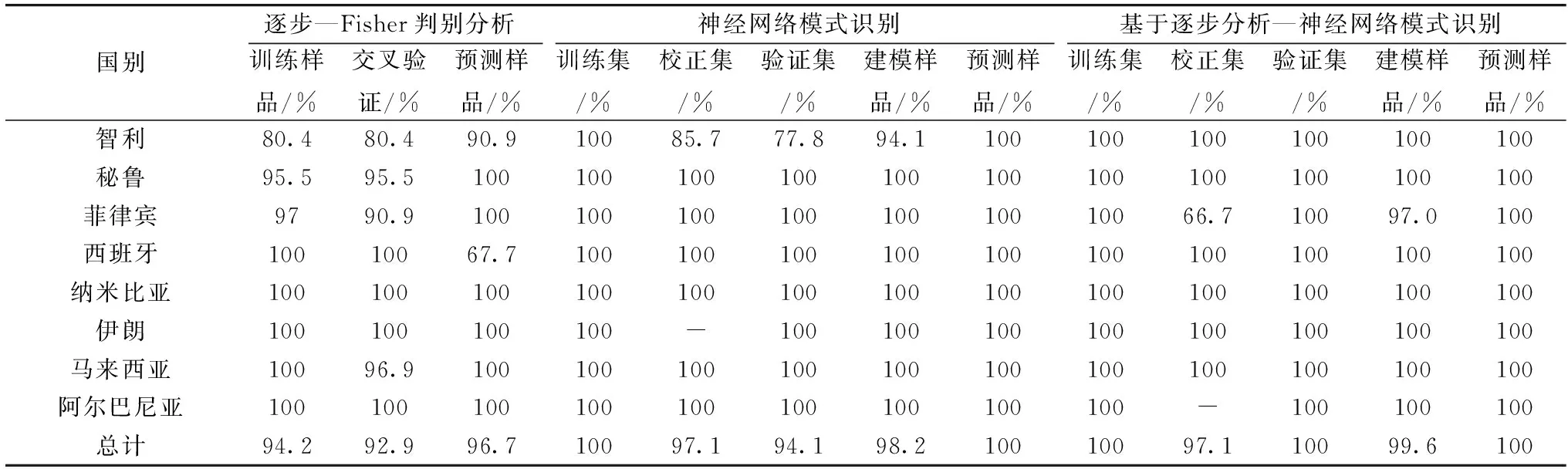
表2 铜精矿建模的分类结果
2.4 BP神经网络模式识别
利用神经网络模式识别建立铜精矿产地识别模型, 模型结构为17-10-8和模型结构为13-10-8的226份样品的训练集, 校正集, 验证集以及建模样品识别准确率分别为100%, 97.1%, 94.1%, 98.2%与100%, 97.1%, 100%, 99.6%, 且两个模型均对54份预测样品100%识别正确; 具体的分类结果如表2所示。
从两次神经网络模式识别的具体分类结果来看, 输入层为17时, 校正集中一个为智利的样品被识别为秘鲁, 验证集中有一个智利的样本被识别为西班牙。 在地理位置上智利和秘鲁接壤, 且均位于南美洲的南美安第斯斑岩铜矿成矿带, 本次检测的样品可能是来自同一矿脉下的样品, 矿石元素含量相近, 所以出现识别错误的情况。 输入层为13时, 校正集中一个为菲律宾的样品被识别为智利。 菲律宾位于环太平洋的东亚成矿带, 智利位于南美安第斯成矿带, 两者虽在矿带之间没有联系, 但本次检测的样品可能均为斑岩型铜矿, 矿石成因相似, 元素含量相近, 因此识别错误。
对比3次建模的结果如表2, 3次建模的结果均高于90%以上, 可知对这8个国别的铜精矿样品的识别效果很好。 对比神经网络模式识别与Fisher-判别分析, 发现神经网络模式识别比Fisher-判别分析具有更高的识别准确度, 其原因在于神经网络可以逼近任何连续的非线性曲线, 具有自适应性, 自组织性, 容错性的优点, 相比Fisher-判别分析体现出更佳的识别率。 比较两个输入变量不同的神经网络模型的结果可知, 经过F值筛选元素后的准确率更高一些, 其原因可能是因为F值的筛选能减少特征变量个数, 选择差异大的信号特征, 从而提高识别率。
3 结 论
利用波长色散-X射线荧光光谱无标样分析法测定8个国家280份铜精矿样品的元素含量, 选择226个样品作为训练样本, 54个样品作为预测样本, 建立不同国别的分类模型。 比较三次模型的结果, 两次神经网络模式识别的结果都要优于逐步-Fisher判别分析的结果, 从算法上来看, 机器学习神经网络的非线性判别要优于Fisher的线性判别。 两次神经网络模式识别的结果都很好, 由于逐步分析具有特征提取的作用, 因此建议采用F-score筛选出O, Mg, Al, Si, P, S, K, Ca, Cu, Zn, Mo, Ag和Pb共13种元素含量作为特征变量, 减少变量个数, 建立对铜精矿国别的产地溯源模型。 该模型为不同国别铜精矿元素含量提供了基础数据与理论依据, 通过X射线荧光光谱无标样分析测定铜精矿样品的13种元素含量建立神经网络模式识别模型, 可以快速识别铜精矿国别。 模型识别准确率与模型样品的产地及建模样品数量存在很大关系, 随着后续收集样品数量增加, 模型的稳定性将得到进一步的提升。 当然, 无标样分析方法毕竟是一种半定量分析方法, 定量分析方法的应用必将进一步提升产地识别模型的普适性。
猜你喜欢
矿产勘查(2020年3期)2020-12-28
矿产勘查(2020年3期)2020-12-28
铜业工程(2020年4期)2020-09-22
中华建设(2019年8期)2019-09-25
中国外汇(2019年22期)2019-05-21
意林·全彩Color(2018年9期)2018-10-12
中成药(2018年8期)2018-08-29
中成药(2017年4期)2017-05-17
中国资源综合利用(2016年12期)2016-01-22
中国资源综合利用(2016年12期)2016-01-22
