
论文分析技术与算法研究
2020-09-04 07:56宁莉莉
科学技术创新 2020年26期
宁莉莉
(咸阳职业技术学院,陕西 咸阳712000)
1 文档数据分析
整个系统对于文档数据的分析主要从数据采集、文档分析、信息分类、数据统计以及关系发现的5 个步骤逐步实现。
主要是在用户提交文档时由系统提示用户填写的基本信息,该功能比较简单,可以和文档分析一起作为第一步的数据获取功能,主要的工作步骤如下图所示:
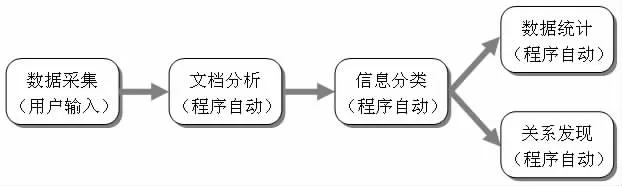
图1 数据分析过程示意图
上面的过程并不一定对每一次论文分析适用,每一个步骤的信息都能够为整个系统提供所需要的论文数据,每一个步骤也都能够为下一步工作提供输入的数据和信息。下面就根据上图的顺序,逐一研究和讨论相关的实现算法。
2 文档操作与分析技术研究
文档的操作与分析技术主要研究的有两大类:分析技术和生成技术。除了用户所输入的论文的基本信息外,为了提高后面文档分析算法的有效性,需要对文档进行深度的分析工作,因为有些内容,仅凭用户的输入永远很难完全获得,而且很多情况下,用户可能会选择不深入相关信息。虽然可以强迫用户输入,但是这样的必填项目不能过多,否则会降低系统的友好程度。而文档的生成技术,是系统自动生成论文所必须的技术。
3 论文分类算法研究
在完成了文档的中文分词后,算法就可以获的全部文档的基本内容,这些内容以中文词组的方式存储在数组中可供分析。“近年来,借助模式识别算法,文本分类技术飞速发展。文本分类大致分为几个要素:文本向量模型表示、文本特征选择和文本训练分类器。目前比较流行的分类方法主要有SVM、改进余弦相似度、贝叶斯方法、神经网络、K2 最近邻方法、遗传算法、粗糙集等”。使用这些技术,就可以根据论文的基本内容,对论文的领域和类型进行归类。
3.1 余弦相似度分类
余弦相似度分类技术是利用上面所计算的TF-IDF 结果与当前数据库中保存的已知类型的文档中的关键词TF-IDF 进行比较,以此来自动判断当前所分析的文档与已知文档是否一致。余弦相似度越接近的论文就应该认为属于同一类型。余弦相似度分类算法最常见的应用就是计算文本相似度。通过将两个文本分别按照所包含的词建立向量,向量可以通过分析文本包含词语的数量,或者以论文为例可以简化为关键词和引用论文,计算两个向量的余弦值,就可以知道两个文本在统计学方法中他们的相似度。
3.2 样本信息收集
样本信息的收集过程可以如下图所示的过程实现:
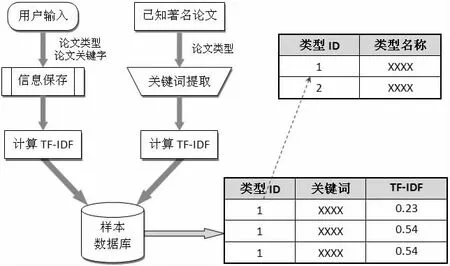
图2 样本信息收集及存储结构示意图
3.3 朴素贝叶斯分类
有了大量的精确度较高的样本信息,系统就能够对任意的新论文信息有效的分类。除了上面所研究的余弦相似度算法外,还有一个比较重要,同时分类效果也非常好的算法是朴素贝叶斯分类算法。与余弦相似度算法相比,贝叶斯分类算法利用了概率论的知识,通过比较样本库中大量的数据的概率与当前分析文档的概率,来确定该论文属于某一类型的可信程度。贝叶斯分类算法的基础是一个明显的常识,即同一条词条在不同类型的文本中出现的概率通常是不一样的,很多词条只会在某些类别的文本中出现,例如“微软”、“索尼”、“乔布斯”等词条出现在有关战争的文本中的概率要远远低于“师团”的概率。因此,通过概率的计算和比较,就能够确定文本的分类。
3.4 分类算法的效率
论文的分析和分类需要花费大量的计算资源,而算法的运行效率会随着论文数量、样本信息等数据量的增加而迅速下降,而对于公用的系统,运行的效率决定着用户的体验度和继续使用该系统的信心。解决效率问题的一个最直接的手段就是提高计算机的运行效率,但是这样的花费将会非常巨大,而且对于一个新系统对计算机效率的估计也十分的困难,开始用户少的时候可能不需要特别快的系统,而随着用户和数据的增长则需要增加计算机的性能。
解决上述问题的一个可能方案是本研究所提出的使用公有云计算平台,来解决系统的扩展性难题。但是再快的计算机系统也会存在极限,但是对于互联网系统来说,数据量的增长早已超过计算机性能的增长。虽然使用云计算平台,但是如果只是依靠单机的性能来完成算法运行的任务,则很快就会碰到效率的瓶颈。因此,更加有效的方案应该是充分的利用分布式计算技术,将分析算法尽可能的分配到不同到计算机上同时并行。则可以解决上述的难题。
目前可能的选择是利用Storm 这样的并行计算框架来实现高并行的算法实现。Storm 框架利用集群系统来完成相关的并行计算,并且能够动态的可靠管理运行在计算机集群上的算法片段。Storm 的框架研究不是本研究的重点,但是通过研究了该框架的具体功能后发现,本系统的论文分析和归类算法,完全可以适应Storm 框架的并行计算要求。Storm 框架设计之初就是为了满足海量的文本数据的并行分析需求。
4 论文统计算法研究
相对于论文分析与归类算法,论文的统计算法相对难度会低一些。相关的功能的信息对用户非常有用,但是算法只是利用系统所存储的所有数据进行统计计算。因此对于论文统计算法的研究重要的是相关数据的存储结构的设计问题。所有的统计结果都是通过不同的角度来对平台内的用户、论文或者学术圈情况进行分析,并且供感兴趣的用户或者研究人员进行查询或者分析。各个角度的统计信息之间,平台并不提供统一的比较。
4.1 最热门论文统计
最热论文的统计主要是解决最热论文的定义问题。可以使用四种不同的方式或计算方法实现:查询次数最多、下载次数最多、引用次数最多、评论次数最多。前面三种标准可以反映该论文在整个系统内部整体的活跃程度,而评论次数最多则可以认为当前的一个短期时间内最热火的论文。
4.2 最活跃用户统计
最热用户既是最活跃用户,可以通过如下三种数据进行标识:论文数目最多、评论最多(包括评论别人或者获得评论最多)、登录系统次数最多、加入的兴趣小组最多。这些信息在数据库中都有直接的存储,因此统计分析也十分简单。最热用户可以与最热论文一起,在用户登录系统后直接推送给用户。可以包括系统内部以及用户所关注的相关领域内部等不同的统计结果信息。
相关的查询比较简单,主要是几个相关表格的联合查询,以半年内上传论文的数目的查询为例,相关SQL 示例如下所示。依靠论文发布的数目并不能准确的确定用户的活跃程度,应该结合最近发布的评论、登录的次数等一起联合作为活跃程度评判的标准。
综合活跃度的计算可以使用:综合活跃度(GA)=论文数目*C1+评论数目*C2+登录系统次数*C3+兴趣小组数目*C4。不同的用户统计方案可以使用不同的系数,期望关注登录次数的统计结果,可以将C3 的百分比提高即可。
有关于热门用户的统计不需要更多的算法设计,SQL 查询就可以获得所有的相关统计结果,计算出综合的活跃度,并通过用户的相关性推送给用户。在所有用户的基础上,可以增加相关领域用户的热门用户统计,提高用户之间的联系。兴趣小组内的用户可以获得小组内最活跃用户的统计结果信息。用户活跃度的信息提供综合查询接口,用户可以通过浏览发表论文数目最多的100 位用户来从系统中搜寻自己感兴趣的用户,并可以尝试与其建立联系。
4.3 最热门领域统计
与用户的信息统计类似,热门领域的统计类似,可以从当前论文数目、关注用户数目来确定最热门的领域。最热门的领域信息对于研究人员来说,是一个非常有趣的信息。但是在系统的初期这样的信息不会特别准确,只有大量的样本信息已经存在后,才能让相关的统计比较准确。统计信息提供给平台用户访问,用户可以通过这样的统计信息筛选出当前最热门的领域。
4.4 领域内最热门引用统计
领域内最热门的引用统计是一个非常重要的信息,用户可以了解到当前该领域里被其它研究人员使用最多到书籍、论文等信息。这项统计功能的算法并不复杂,一旦论文的分析成功提取出所有的引用数据后,通过SQL 的查询就可以获取该领域里被引用最多的论文信息。该项统计也同样需要非常大量的样本数据,越多的数据,才能够获得准确的热门引用统计结果。论文引用信息需要单独存放,一旦分析完论文后,可以查询论文中的引用是否存在,如果存在则该引用的被引用数加一。
5 推荐算法研究
一旦系统有了大量的样本数据后,围绕着论文信息、用户信息、类型、领域等数据生成更多等相关性信息。如何使用这些信息来发掘出更多的隐藏关联,是大数据分析领域的重要课题。本系统由于时间的限制无法进一步的开展相关的数据挖掘技术的研究工作,但是海量数据的存在,为后续的研究工作奠定基础。在本研究中,将重点放在如何利用现有数据,构建推荐功能的技术。
大量的样本数据和用户评论和论文查询的数据,就可以构成一套协作型过滤(Collaborative filtering)技术。该技术通常的做法就是对一大群人进行搜索,并从中找出与某一个用户兴趣相近的推荐。协作型过滤是David Goldberg 在1992 年在施乐帕克研究中心(Xerox PARC) 的一篇题为《Using collaborative filtering to weave an information tapestry》的论文中首次提出的术语,在论文中所设计的系统,可以允许人们根据自己对文档感兴趣的程度为其添加标注,并利用这一信息为他人进行文档过滤。
根据上述的说明,可以通过用户使用系统时的偏好分析,获取与用户最相似的用户的使用偏好,并推荐给用户相关信息。这样就比单纯通过用户是否在一个领域、或者在一个兴趣小组内更加具有广泛性。毕竟静态的研究领域的划分,有时很难真正的标识出用户的正在喜好。但协作型过滤算法就可以做到。目前广泛在购物网站上使用的推荐功能就是该应用的一个很好例证。
6 结论
通过上述的算法根据用户兴趣计算出了兴趣相近的用户后,就能够根据设计,将兴趣相近用户的喜好,推荐给当前用户。系统可以提供的推荐功能包括:当用户查询、浏览以及下载某个论文后,可以立即根据与其兴趣相似度最高的用户的兴趣,向其推荐可能感兴趣的论文信息。由于兴趣相似用户感兴趣的论文可能非常多,因此在获取了论文列表后,可以进一步根据与当前用户所操作的论文分析出最相近的论文,并推荐给用户。相关的算法都已经进行过讨论。
使用上述的方案,就能够构建一个相对准确的论文推荐系统,帮助研究人员从海量的论文信息中发现自己最感兴趣的部分。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
鄱阳湖学刊(2018年3期)2018-07-28
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
电脑爱好者(2017年7期)2017-05-06
鄱阳湖学刊(2016年5期)2016-11-15
鄱阳湖学刊(2016年1期)2016-01-28
