
基于特征选择和超参数优化的恐怖袭击组织预测方法
2020-09-04 10:00肖跃雷张云娇
计算机应用 2020年8期
肖跃雷 ,张云娇
(1. 西安邮电大学现代邮政学院,西安710061; 2. 陕西省信息化工程研究院,西安710075)
0 引言
近年来全球恐怖袭击事件频繁发生,直接造成了巨大的人员伤亡和财产损失,严重阻碍了社会稳定和经济发展,恐怖袭击事件问题已成为当前国际社会比较关注的一个热点问题[1]。为了保护人们的生命财产安全,维护社会经济的稳定和发展,针对恐怖袭击事件的分析和预测势在必行。通过对历史恐怖袭击事件进行分析,可以寻找出恐怖袭击事件的发生特点和规律,进而对恐怖袭击事件进行预测,以便帮助各国政府及时采取有效的反恐措施。
目前针对恐怖袭击事件的研究有很多,其中运用机器学习[2-4]对恐怖袭击事件进行分析预测已成为当前的研究热点。文献[5-7]中运用分类预测方法对恐怖袭击事件进行大量分析,得到了恐怖袭击事件中攻击的模式、区域和行为等特征,挖掘了恐怖袭击事件特征之间的一些潜在联系。文献[8-9]中对恐怖袭击组织的关系进行分析,研究了恐怖袭击组织的属性特征之间的联系,发现了恐怖袭击组织的网络结构和重要犯罪组织。文献[10]中利用N-gram 模型对恐怖袭击事件的常见动机进行挖掘,通过大数据分析,提高了预测精度。文献[11]中对恐怖袭击事件进行分类预测,利用最大相关和最小冗余进行特征选择,通过不同分类器的性能比较,验证了机器学习在恐怖袭击事件分类预测领域的可行性。文献[12]在恐怖袭击事件的检测环境中,使用随机森林(Random Forest,RF)作为分类器,并与决策树(Decision Tree,DT)算法和模糊C 均值(Fuzzy C-Means,FCM)方法作比较,发现RF 方法的分类错误率较低,且不会出现过拟合现象。文献[13]中提出了一种运用加权的贝叶斯方法对恐怖袭击组织行为进行预测,提高了算法的预测精度和计算效率;该算法在准确度及时间复杂度上优于基于频繁模式的分类算法,但存在计算繁琐、耗时长等问题。文献[14]中提出了一种基于机器学习的恐怖分子预测方法,通过Bagging 分类器、DT、RF 和全连接神经网络对恐怖袭击事件制造者进行预测,并对各个分类算法中的参数进行寻优,提高了分类预测的准确率。恐怖袭击事件数据通常是一个不平衡数据集,例如:全球恐怖主义数据库(Global Terrorism Database,GTD)[15]。上述恐怖袭击事件分析预测方法均没有很好地解决恐怖袭击事件数据的样本不平衡问题,预测性能有待进一步提高,特别是针对少数类样本的预测性能。
为此,针对恐怖袭击组织的分类预测,本文提出了一种基于特征选择和超参数优化的恐怖袭击组织预测方法。该方法首先利用基于随机森林迭代的后向特征选择算法进行特征选择;然后利用 DT[16-17]、RF[18-19]、Bagging[20-21]和 XGBoost[22-23]这四种主流分类器对恐怖袭击组织进行分类预测,并利用贝叶斯优化方法对这些分类器进行超参数优化;最后,评价这些分类器在多数类样本和少数类样本上的分类预测性能。通过实验和结果分析可知,该方法提高了对恐怖袭击组织的分类预测性能,其中使用RF和Bagging 时的分类预测性能最佳,特别是在少数类样本上有明显提高。
1 恐怖袭击组织预测模型
本文提出的恐怖袭击组织预测模型如图1 所示,主要包括数据预处理、特征选择、超参数优化和分类器分类四个步骤。
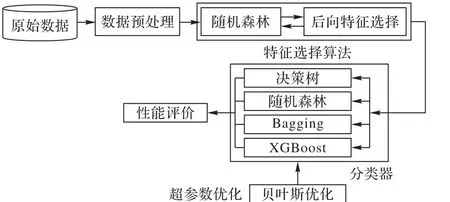
图1 恐怖袭击组织预测模型Fig. 1 Prediction model of terrorist attack organization
1.1 数据预处理
本文对恐怖袭击事件原始数据的预处理主要包括数据清洗和数据转换。
数据清洗过程为:首先删除一些对预测模型无用的文本描述性特征;然后通过数据完整性分析删除一些数据严重缺失的记录和特征,接着对数据缺失值进行相应的填充;最后利用Pearson(皮尔逊)方法进行特征相关性分析,删除一些不显著的自变量特征,并根据共线性删除一些冗余自变量特征。此外,还需要删除少数类样本只有1 条的记录,因为1 个样本无法同时用于分类预测方法中的训练过程和测试过程。
转换过程为:首先对一些文本型数据进行数值转换,然后对一些连续型数据进行离散化处理,最后对数据进行数据标准化转换。
1.2 特征选择
文献[24]中提出了RF在处理不平衡数据上的应用,并通过实验证明了它在处理不平衡数据上的优势。由于恐怖袭击事件数据通常是一个不平衡数据集,所以本文在文献[24]的基础上,提出了一种基于RF 迭代的后向特征选择算法,通过RF迭代来进行后向特征选择,具体如下。
算法1 基于RF迭代的后向特征选择算法。
输入 具有特征集合F ={ fi|i = 1,2,…,n}的数据集DF;
输出 具有被选择特征子集S的数据集DS。
1) DS← DF
2) 当前验证错误率Ec← 1
3) do{
4) 对数据集DS执行RF算法
5) for i ← 1 to n
6) 计算每个特征fi的重要性值IVi
7) end for
8) 最小重要性值IVmin←IV1
9) 最小重要性值特征序号j ←1
10) for i ← 2 to n
11) if IVi≤ IVmin
12) 更新最小重要性值IVmin= IVi
13) 更新最小重要性值特征序号j = i
14) end if
15) end for
16) 从数据集DS中删除特征fj
17) 更新n ← n - 1
18) 之前验证错误率Ep← Ec
19) 当前验证集DV← DS
20) 基于DV计算当前验证错误率Ec
21) }while(Ec≥ Ep)
22) return DS
算法1中,特征fi的重要性值IVi的计算公式如下:

其中:对于RF 中的每一棵DT,使用相应的袋外数据(Out Of Bag,OOB)来计算它的袋外数据误差,记为EOOB1;随机地对OOB 所有样本的特征fi加入噪声干扰,再次计算它的袋外数据误差,记为EOOB2。N 表示RF 有N 棵DT。基于当前验证集DV计算当前验证错误率Ec的计算公式如下:

其中:ne表示当前验证集DV使用RF 后的错误分类样本数目,表示当前验证集DV的样本总数目。
1.3 超参数优化
超参数优化[25-26]就是一组超参数的机器学习模型,它的目标就是通过验证误差目标函数,找到在验证集上产生最小误差的一组超参数,并且能够很好地应用于测试集。
本文运用Python 中一个用于超参数优化的类库Hyperopt,通过设定分类器的超参数取值范围,假设解空间,然后利用贝叶斯优化[27-29]快速寻找一个满足目标函数的合理解。贝叶斯优化就是通过基于过去对目标的评估结果建立一个不断更新的概率模型来找到使得目标函数最小的值。
1.4 分类器
本文使用DT、RF、Bagging 和XGBoost 这四种主流分类器对恐怖袭击组织进行分类预测,并对其性能进行评价比较。
DT[16-17]是机器学习中一种基本的分类方法,它的模型为树形结构。DT对训练数据来说分类能力会很好,但对未知的测试数据分类能力不一定好。由于节点的划分过程会一直反复,可能会使DT的分支过多,存在过拟合现象,所以要对生成的树进行由上到下的剪枝。首先去掉过于细分的叶节点,使其回退到父节点,甚至更高的节点;然后将父节点或更高的节点改为新的叶节点,使树变得简单,从而使它具有更好的泛化能力。本文采用的DT 为分类与回归树(Classification And Regression Tree,CART)。
Bagging[20-21]也称自举汇聚法(boostrap aggregating),是一种在原始数据集中有放回地抽取m次后得到m个采样集的技术。在m个采样集建好之后,首先利用每个采样集分别对m个基分类器进行训练,然后通过基分类器的组合策略得到最终的集成分类器。本文在Bagging 中按照少数服从多数的原则来投票确定最终类别。
RF[18-19]是通过集成学习的思想利用多棵树对样本进行训练并预测的一种分类器算法,该算法通过在训练时间内构建多棵DT 并输出作为类的标签(分类)或个体树预测的平均值(回归)。由于RF将多棵决策树集成在一起训练和预测,所以RF可以修正因决策树的归纳偏好产生的过拟合问题。
Boosting[22]的基本思想是通过某种方式使得每一轮基学习器在训练过程中更加关注上一轮学习错误的样本。Gradient Boosting 将负梯度作为上一轮基学习器犯错的衡量标准,在下一轮学习中通过拟合负梯度来纠正上一轮的错误。XGBoost[22-23]在 Gradient Boosting上作了一些改进:主要是引入了二阶导数,用一阶与二阶导数逼近损失函数,这样在优化过程中有更多的信息;同时XGBoost 在损失函数中加入了正则项,用于权衡模型的复杂度,使得模型更加简单,防止过拟合。XGBoost 通过一组分类器的串行迭代计算实现更高精度的分类效果,其基学习器是CART,在预测时将多个基学习器的预测结果综合考虑得出最终结果。
1.5 性能评价
对于分类预测问题,基本的性能衡量指标为混淆矩阵,如表1 所示。表1 中:TP(True Positive)表示实际类别为True,预测类别也为True;FN(False Negative)表示实际类别为True,但预测类别为False;FP(False Positive)表示实际类别为False,但预测类别为True;TN(True Negative)表示实际类别为False,预测类别也为False。

表1 混淆矩阵Tab. 1 Confusion matrix
常用分类预测性能评价指标准确率(Accuracy)、精确度(Precision)、召回率(Recall)和F1 分数(F1-score)的计算公式如下:

其中:Accuracy是所有预测正确的样本数与总样本数的比值;Precision是所有预测为正样本的样本中,真实为正样本的比例;Recall(也称为检测率)是预测为正样本的数量占所有正样本总数的比例;F1-score是精确度和召回率的调和平均数。由于对恐怖袭击组织的预测是一个分类预测问题,所以本文以这4 个性能评价指标作为恐怖袭击组织预测模型的性能评价指标。
为了评价恐怖袭击组织预测模型在多数类样本和少数类样本上的性能,本文首先对恐怖袭击事件数据按照多数类样本到少数类样本进行分段划分,然后利用以上4 个性能评价指标来评价恐怖袭击组织预测模型在多数类样本和少数类样本上的性能。
2 实验与结果分析
本文实验的数据集为1998—2017 年的全球恐怖主义数据库(GTD)[15],其中每条恐怖袭击事件数据记录有135 个属性字段信息,包括事件发生时间、地点、伤亡人数、武器类型、财产损失等重要信息。
首先,通过数据预处理筛选出了GTD中的43 335个样本,39 个特征。筛选出的39 个特征为:年、月、日、是否为持续事件、国家、地区、省/行政区/州、城市、地理特征编码、附近地区、入选标准1、入选标准3、事件组的一部分、成功的袭击、自杀式袭击、攻击类型1、目标/受害者类型、目标/受害者子类型、实体名称、具体目标/受害者、目标/受害者的国籍、动机、第一涉嫌犯罪集团、个人袭击、凶手数量、抓获的凶手数量、声称负责、武器类型1、武器子类型、死亡总数、美国死亡人数、凶手死亡人数、受伤总数、美国受伤人数、凶手受伤人数、财产损失、财产损失程度、人质或受害者和恐怖袭击组织。前38 个特征为自变量特征,最后1个特征为因变量特征。
这43 335个样本的恐怖袭击组织个数为826,其中每个恐怖袭击组织的样本个数(即每个恐怖袭击组织的袭击次数)最小为2,最大为6 310,且差异很大,如图2 所示。因此,这43 335个样本是一个不平衡数据集。
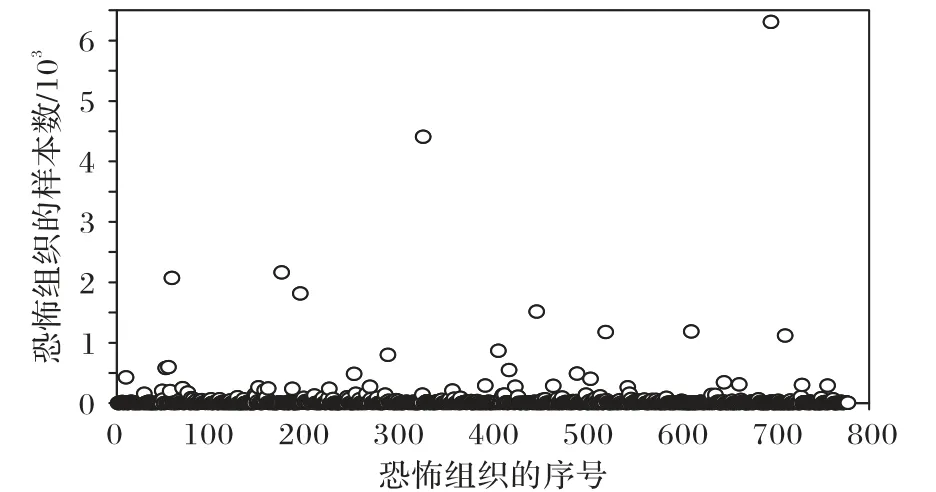
图2 恐怖袭击组织的样本个数分布Fig.2 Distribution of sample number of terrorist attack organizations
从图2数据统计分析可知,样本个数为100及以上的恐怖袭击组织有56 个,但是总样本个数为34 374,属于多数类样本;而样本个数为100 以下的恐怖袭击组织有770 个之多,但是总样本个数只有9 151,属于少数类样本;特别地,样本个数为20 及以下的恐怖袭击组织有641 个之多,但是总样本个数只有3 519。
为了更好地评价恐怖袭击组织预测模型在多数类和少数类样本上的性能,如表2 所示将43 335 个样本划分为多个区间。
然后,通过上述特征选择算法最终筛选出了28 个影响最大的自变量特征,分别为:年、月、日、是否为持续事件、国家、地区、省/行政区/州、城市、地理特征编码、事件组的一部分、攻击类型1、目标/受害者类型、目标/受害者子类型、实体名称、具体目标/受害者、目标/受害者的国籍、动机、第一涉嫌犯罪集团、凶手数量、抓获的凶手数量、声称负责、武器类型1、武器子类型、死亡总数、受伤总数、凶手受伤人数、财产损失和财产损失程度,它们累计特征贡献率达到90%以上。

表2 样本分段Tab. 2 Sample segments
最后,将特征选择后的数据集的70%划分为训练集,30%为测试集,使用DT、RF、Bagging和XGBoost这四种主流分类器对恐怖袭击组织进行分类预测,并利用Hyperopt 来对这四种分类器的超参数进行优化。在开始搜索时,Hyperopt会默认进行随机搜索,而且在搜索过程中会对函数的输出进行预估,然后不断地根据之前的结果来调整搜索空间,计算出参数空间内的一个点的损失函数值。经过贝叶斯优化后,DT的最大深度max_depth= 40;RF 的最大特征数max_features= 0.8,基分类器个数n_estimators= 120,最大深度max_depth= 40;Bagging的max_features= 0.6,n_estimators= 130;XGBoost 的学习率learning_rate= 0.5,max_depth= 40,n_estimators= 130。
同样将预处理后数据集的70%划分为训练集,30%为测试集,但仅使用 DT、RF、Bagging 和 XGBoost 这四种主流分类器对恐怖袭击组织进行分类预测,不进行上述特征选择和超参数优化。表3 为这四种主流分类器在特征选择和超参数优化前后的准确率对比。从表3 可知,在进行特征选择和超参数优化后,使用这四个分类器的分类预测准确率都有相应的提高,特别是RF、Bagging 和XGBoost的准确率提高较大,其中RF和Bagging的准确率分别达到0.823 9和0.831 6。
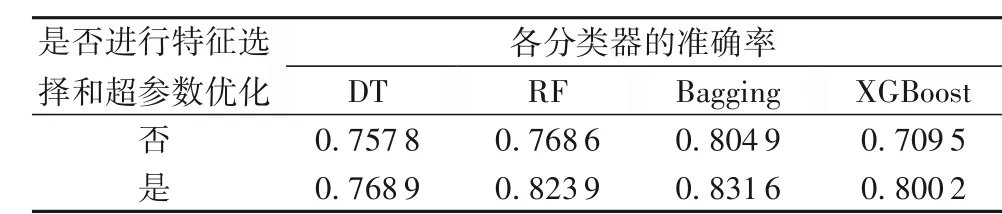
表3 各分类器在特征选择和超参数优化前后的准确率Tab. 3 Accuracy of different classifiers before and after feature selection and hyperparameter optimization
图 3 为 DT、RF、Bagging 和 XGBoost 这四种主流分类器在特征选择和超参数优化前后不同样本分段的精确度、召回率和F1分数对比,其中空心柱状图为各分类器在特征选择和超参数优化前不同样本分段的结果,而有图案填充的柱状图为各分类器在特征选择和超参数优化后不同样本分段的结果(后续实验中的图形含义一致)。
从图3 可知,在进行特征选择和超参数优化后,在不同样本分段上,使用这四个分类器的分类预测精确度、召回率和F1 分数都有相应的提高。特别地,在少数类样本分段上,RF和Bagging 的分类预测精确度、召回率和F1 分数均提高明显,优于DT 和XGBoost。因此,通过特征选择和超参数优化,可以提高DT、RF、Bagging 和XGBoost 这四种主流分类器对恐怖袭击组织的分类预测准确率、精确度、召回率和F1分数,其中RF 和Bagging 对恐怖袭击组织的分类预测准确率分别达到0.823 9 和0.831 6,并且在少数类样本分段上对恐怖袭击组织的精确度、召回率和F1分数有明显的提高。
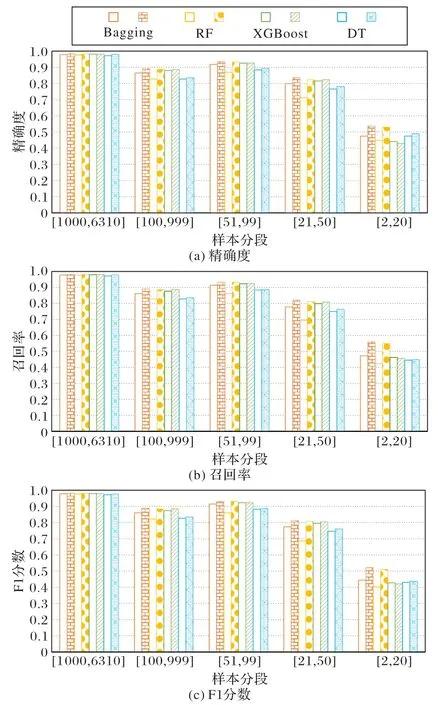
图3 各分类器在特征选择和超参数优化前后在不同样本分段上的精确度、召回率和F1分数对比Fig. 3 Comparison of accuracy,recall and F1-score of different classifiers on different sample segments before and after feature selection and hyperparameter optimization
10 折交叉验证法[14]和随机过采样[30]是缓解数据不平衡问题的常用方法。为了与本文方法进行对比,针对数据预处理后的数据集,首先分别进行10 折交叉验证和随机过采样(70%为训练集,30%为测试集),然后使用DT、RF、Bagging 和XGBoost 这四种主流分类器对恐怖袭击组织进行分类预测,并进行超参数优化。表4 为三种方法的准确率对比,可以看出,在按本文方法进行特征选择和超参数优化后,四种主流分类器的预测准确率要高于使用10 折交叉验证法+超参数优化,以及使用随机过采样+超参数优化的方法。
图4、5 分别为表4 中本文方法与使用10 折交叉验证和随机过程采样时针对不同样本分段的精确度、召回率和F1分数对比。从图4、5 可知,在各个样本分段上,特别是在少数类样本分段上,本文方法的精确度、召回率和F1 分数总体上要高于使用10 折交叉验证法和随机过采样,从而说明本文方法更能缓解GTD这种数据集的数据不平衡问题。
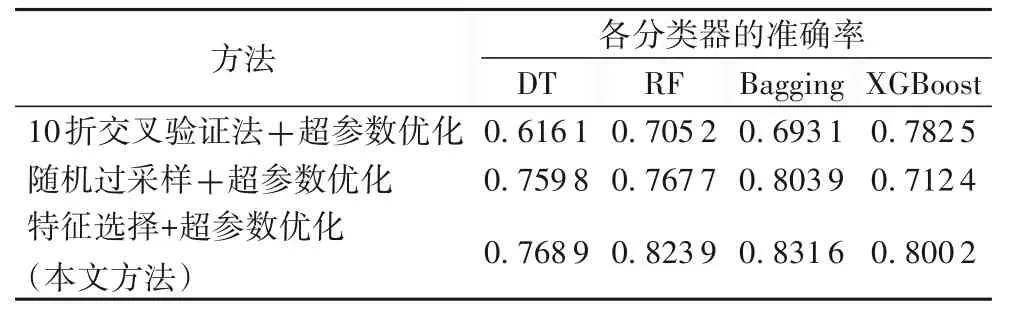
表4 各分类器在使用10折交叉验证法和随机过采样时的准确率Tab. 4 Accuracies of different classifiers when using 10-fold validation and random oversampling

图4 本文方法与使用10折交叉验证时针对不同样本分段的精确度、召回率和F1分数对比Fig.4 Comparison of accuracy,recall and F1-score of different sample segments between the proposed method and 10-fold validation method
3 结语
针对恐怖袭击事件数据的样本不平衡问题,本文提出了一种基于特征选择和超参数优化的恐怖袭击组织预测方法。首先利用RF 在处理不平衡数据上的优势,通过RF 迭代来进行后向特征选择,每次迭代删除一个重要性值最小的特征,直至验证错误率不能再降低为止;然后,使用DT、RF、Bagging 和XGBoost 这四种主流分类器对恐怖袭击组织进行分类预测,并利用贝叶斯优化方法对这些分类器进行超参数优化;最后,评价这些分类器在多数类样本和小数类样本上的分类预测性能。通过实验和结果分析可知,该方法提高了对恐怖袭击组织的分类预测性能,其中使用RF 和Bagging 时的分类预测性能最佳,特别是在少数类样本上对恐怖袭击组织的分类预测性能有明显的提高,要优于使用DT 和XGBoost 时的分类预测性能。
由于恐怖袭击事件数据的少数类样本占比太大,而且每个恐怖袭击组织的样本个数太少,使得本文方法在少数类样本上的分类预测性能还是较低,未来还将进一步探讨如何提高在少数类样本上的分类预测性能。
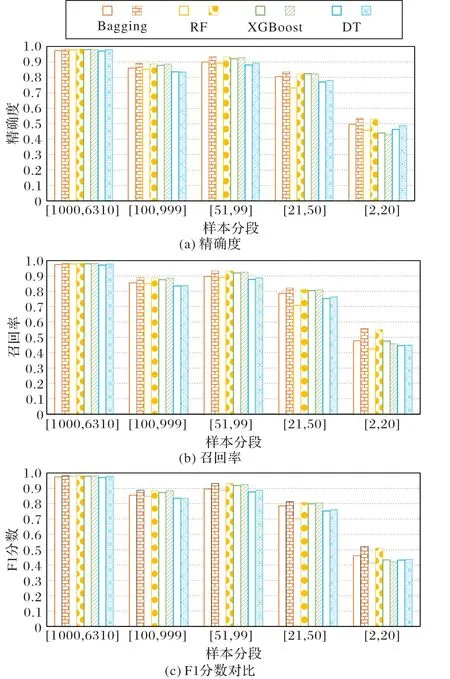
图5 本文方法与使用随机过采样时针对不同样本分段的精确度、召回率和F1分数对比Fig.5 Comparison of accuracy,recall and F1-score of different sample segments between the proposed method and random oversampling method
猜你喜欢
电子产品世界(2022年4期)2022-04-21
英语文摘(2021年1期)2021-06-11
计算机系统应用(2021年2期)2021-02-23
计算机测量与控制(2019年4期)2019-05-08
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
科普童话·百科探秘(2015年4期)2015-05-14
环球时报(2014-08-30)2014-08-30
