
基于自注意力机制的多域卷积神经网络的视觉追踪
2020-09-04 10:00李生武张选德
计算机应用 2020年8期
李生武,张选德
(陕西科技大学电子信息与人工智能学院,西安710021)
0 引言
视觉追踪在无人驾驶、行人检测、智能交通等视觉应用中扮演着越来越重要的角色。基于相关滤波的追踪器可以利用一个循环矩阵在傅里叶域中完成快速计算,实现快速的目标跟踪,基于此,出现了很多高速且简易的追踪器[1-3]。随着卷积神经网络(Convolutional Neural Network,CNN)的不断发展,基于其强大的特征表示能力和高效的特征提取方式,CNN 的应用领域不断扩展,各种针对特定问题设计的CNN 模型不断被建立并成功地应用到各种图像任务中。在视觉追踪领域内,随着众多性能顶尖的以CNN 为基础的深度视觉追踪算法的出现,它在追踪任务中应用的有效性已经得到了充分的验证。
一些基于CNN 的模型算法就是利用其优秀的特征表示能力,致力于强化目标的表示,例如对抗学习跟踪(Visual Tracking Via Adversarial Learning,VITAL)[4]借鉴了生成对抗网络(Generative Adversarial Net,GAN)[5]的思想,在CNN 中引入了对抗特征生成器来获取更加鲁棒的特征表示;结构感知网络(Structure-Aware Network,SANet)[6]通过将基于 CNN 的跟踪器和循环神经网络(Recurrent Neural Network,RNN)[7]结合起来,以获得目标的独特结构信息,提升模型对含有相似语义物体的鉴别能力;树结构卷积神经网络(CNNs in a Tree structure,TCNN)[8]通过构建树形结构的多个 CNN 来提高跟踪模型的可靠性,其中模型沿树中的路径在线更新,因此可以获得更鲁棒的模型。
多域卷积神经网络(Multi-Domain CNN,MDNet)[9]是VOT2015[10]的冠军算法,也是CNN 在深度视觉追踪中应用最成功的代表性算法之一。MDNet的提出是受到用于目标检测的 R-CNN[11]网络启发,该算法在 ImageNet-Vid[12]数据集上离线训练好模型后,利用测试视频的首帧图像微调模型作为初始化,然后生成候选区域,最后确定预测框。
尽管基于CNN 框架的MDNet 算法在视觉追踪领域里取得了巨大的成功,但是受制于CNN 框架内部存在的一些问题没有解决,如在追踪中的主要目的是在复杂环境中聚焦于目标的状态信息,而对其他外部信息不感兴趣。而一般的基于CNN 框架的模型在处理数据时,等价地处理每一个特征图和特征子空间,没有重点关注的区域,尤其是在目标发生了剧烈的形态变化时,缺乏动态响应机制,这就限制了模型的多样表征能力。此外,针对在多域训练中,其中一个域对应一个用于训练的视频序列,会出现当前视频训练序列中的追踪目标在其他数据集中属于背景的情况,这种情况会导致网络鉴别目标的二义性,影响网络的识别精确率。本文通过在MDNet 算法中引入自注意力(self-attention)机制和复合损失函数来解决上述问题。自注意力机制是由Vaswani 等[13]首次提出的,通过利用该机制来获取输入的全局依赖性并且应用于机器翻译中。与此同时自注意力机制也开始逐渐应用到视觉图像处理领域中,如Zhang 等[14]利用自注意力机制来学习一个良好的图片生成器;Wang等[15]将自注意力机制融入网络结构中用于图像分类,充分验证了在空间维度上非局部操作在图像和视频处理中的有效性。不同于这些工作,本文针对MDNet 算法中存在的问题,通过引入自注意力机制提出了自注意力多域卷积神经网络(Multi-Domain convolutional neural Network based on Self-Attention,SAMDNet)视觉追踪算法,配合精心设计的复合损失函数,得到了显著的性能提升,最后通过充分的实验,验证了所提模型的有效性,并在多个广泛使用的测试基准上与数个先进的算法相比表现出众。
1 MDNet追踪算法
MDNet算法的目标是训练出一个MDNet使得该网络能够在任意域中也就是任意视频序列中将目标和背景区分出来。尽管不同的视频序列带有不同的目标和背景标签,然而在各种场景下目标和背景都存在一些共有的属性,例如对照明变化的鲁棒性、运动模糊、缩放比例变化等。在网络模型的离线训练阶段,MDNet 通过其多域学习结构将不同的训练视频序列中的通用属性保留在网络的卷积层部分,最后的多分支全连接层对应不同的序列,负责在各自对应视频序列中甄别输入的候选框属于目标类还是背景类。在测试追踪阶段,新生成的单分支全连接层替换掉原来的多分支,构成追踪网络,追踪过程中综合利用网络更新策略、边界框修正策略和样本生成策略来完成对目标的分类和定位。
2 自注意力多域卷积神经网络
本文提出的自注意力多域卷积神经网络SAMDNet 结构如图1 所示,网络的输入为107 × 107 大小的RGB 图像,整个网络主要由两部分组成。其中一部分为网络主体结构,由3个卷积层(CONV1~CONV3)和2 个全连接层(FC4、FC5)组成,卷积层和VGG(Visual Geometry Group)网络中对应的部分完全一样。此外,网络末端还有k个全连接层(FC6[1]~FC6[k])作为对应的k 个域,也就是k 个用于网络训练的视频序列,全连接层FC6 中的每一个分支均使用Softmax 交叉熵函数来计算目标和背景概率,另外也参与在离线训练阶段复合损失的计算。另一部分为引入的自注意力机制,自注意力机制的实现主要由空间注意力模块(Spatial Attention Module,PAM)和通道注意力模块(Channel Attention Module,CAM)具体完成,其中 PAM 位于卷积层 CONV1 和卷积层 CONV2 之间,CAM 位于卷积层CONV3和全连接层FC4之间。
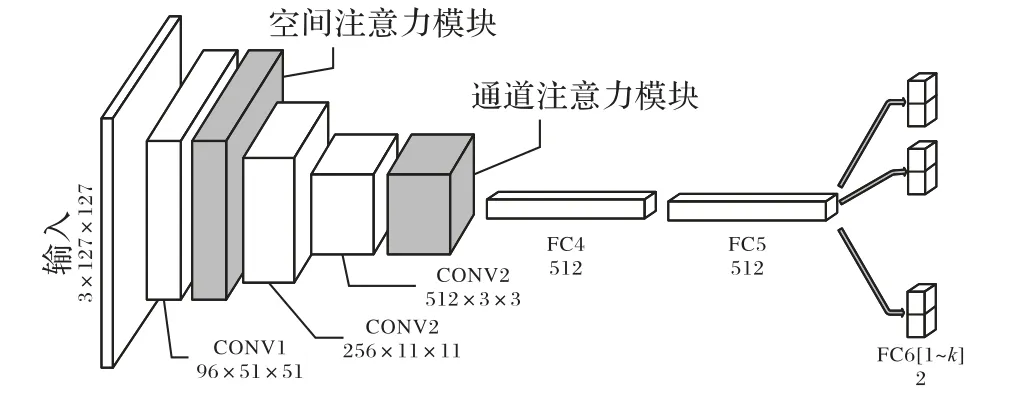
图1 自注意力多域卷积神经网络结构Fig. 1 Network structure of multi-domain convolutional neural network based on self-attention
2.1 自注意力机制算法
注意力机制从本质上来讲类似于人类的视觉注意力机制,当人类在观察事物时,视觉系统快速扫描捕获的图像,获得了重点关注的目标区域,也就是视觉的注意力焦点,之后视觉系统在焦点附近分配更多的资源来获取更多的细节信息,同时其他的不相关或者无用的信息就被抑制了。而自注意力机制是对注意力机制的改进,它减少了对外部信息的影响,更加擅长去捕捉数据和特征的内部相关性。本文提出的算法就是利用自注意力机制的特性,动态地在空间和通道两个维度上去自学习注意力矩阵,而后将注意力融入模型进而驱动多域卷积神经网络聚焦于关注追踪目标内部特征,最后获得更为鲁棒的目标表示。
本文算法中的自注意力机制主要是通过空间注意力模块和通道注意力模块实现:空间注意力模块将所有位置上的特征的加权总和选择性地聚合到特征图中的所有位置上,使得相似的特征彼此相关;通道注意力模块通过整合所有特征图来使得网络重点去关注那些互相关联的通道特征图,有选择地提取重要通道的特征信息。
2.1.1 空间注意力模块
空间注意力模块的结构如图2 所示。网络模型的输入样本图像通过第一个卷积层(CONV1)后得到特征图F ∈ RC×H×W,其中上标C、H、W 分别代表特征图通道数、特征图高度和特征图宽度,F 即空间注意力模块的输入。输入F分两次经过同一个一维卷积层后生成特征图A 和B,且{A,B}∈ RC×H×W,特征图 C 和 F 相同,A 和 B 矩阵重构后得到{A*,B*}∈ RN×C,其中N 为特征图中单个通道的像素个数,即N = H × W,之后将B*和A*的转置矩阵A*T作矩阵乘法,然后将得到的结果输入到Softmax 层来计算注意力矩阵Tp∈RN×N,计算方式如式(1)所示。
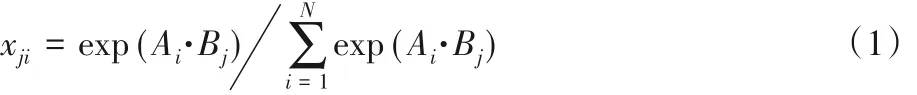
式中:xji是用来度量位置ith的像素对位置jth像素的影响,xji的值越大,位置为ith和jth的元素之间关联程度越高,越相似。与此同时特征图C 进行矩阵重构得到C*∈ RC×N,将C*和注意力矩阵Tp的转置矩阵TpT 作矩阵乘法后得到的结果融入原输入的特征图F,最后得到空间注意力模块的输出E ∈RC×H×W,计算方式如式(2)所示。

α 为自学习参数,初始值为0。特征图E 将作为之后网络组件的输入,此时特征图E 中的每个位置都是来自原对应位置输入特征值加权和与来自所有位置的特征之和,因此每个位置的特征值都获得了一个全局的上下文信息,相似的特征会互相得到增益,有助于跟踪过程中目标的精确分类和定位。
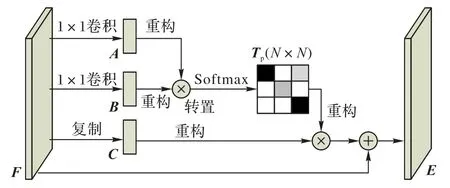
图2 空间注意力模块Fig. 2 Spatial attention module
2.1.2 通道注意力模块
通道注意力模块结构如图3 所示。和空间注意力不同的是,通道注意力 Tc∈ RC×C是从输入特征图 F ∈ RC×H×W直接计算出来的,其中上标C 为特征图的通道数。首先将F 重构为F*∈ RN×N,再将F*与其转置矩阵F*T作矩阵乘法,输出的结果送入Softmax 层中计算得到通道注意力矩阵Tc,计算方式如式(3)所示。
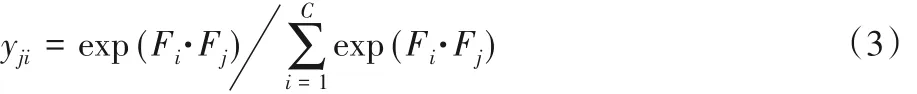
其中:yji是用来度量通道ith对通道jth的影响,之后将Tc的转置矩阵TcT 和F*作矩阵乘法后再重构使乘积的维数为RC×H×W。通道注意力模块的最终输出 E ∈ RC×H×W的计算方式如下:

其中:β 为自学习参数,初始值设置为0。通过自适应的方式,在总体上控制通道注意力对每个通道的影响,最后将得到的通道注意力和原特征图进行融合得到了输出E,特征图E 将作为之后网络组件的输入。
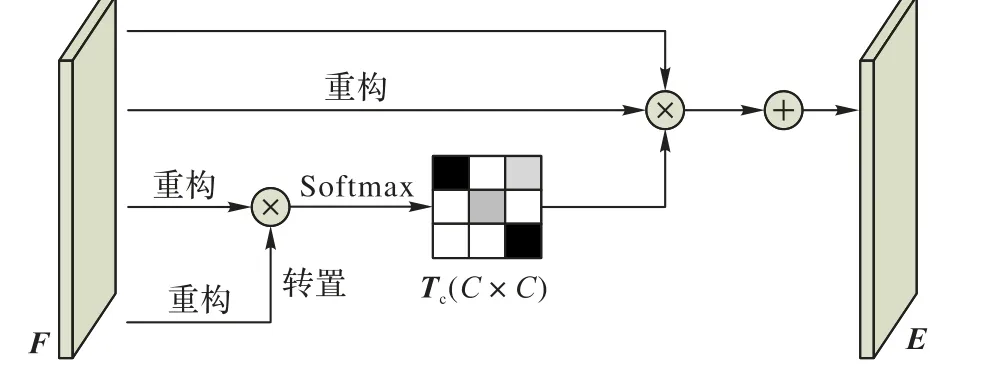
图3 通道注意力模块Fig. 3 Channel attention module
2.2 用于离线训练的复合损失函数
在离线训练模型阶段,本文采用复合损失函数来统计误差,利用反向传播更新模型参数。复合损失函数由两部分损失项构成:一个为分类损失项,另一个为实例判别损失项。
离线训练时,多域卷积神经网络中的输出分数Sd定义方式如下所示:

其中:xd表示在第d个视频序列中的样本图片;R为d视频序列中的目标真实框标记;D 为训练视频集中序列的总个数;φd(;)表示第d 个序列对应的二分类分数。最后的全连接层(FC61,FC62,…,FC6D)的输出被同时送入用于二分类的Softmax 函数 σcls和用于实例判别的 Softmax 函数 σins,且完成一次迭代训练后得到S ∈Rp×q的矩阵,p 为单次迭代中参与的样本数量,q 为样本图片属于的类别数量,i 和j 分别是S 的行和列索引。则σcls和σins定义方式如式(6)和式(7)所示:
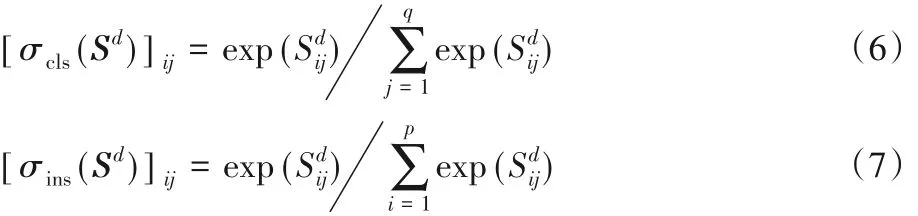
复合损失函数的定义方式如式(8)所示:

其中:Lcls为二分类损失函数,比较目标和背景的分数来指引分类;Lins为实例判别损失函数,用来提高当前目标在当前序列中属于目标的正分数,抑制它在其他序列中属于目标的分数;γ 为一个超参数,作用是平衡两种损失的权重,本文根据多次实验设置的理想值为0.15。在离线训练网络的过程中,最内层的单次迭代只处理一个视频序列。假设当前序列为d(k) = k mod K,则第k 次迭代的二分类损失计算方式如式(9)所示:
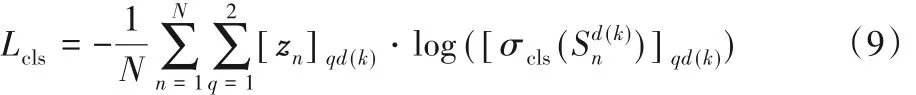
其中:zn∈ {0,1}D×2为对应真实目标的标签,当d 序列中的预测框 Ri对应的类为 q 时[zn] qd = 1,否则为 0;N 为处理单个序列时循环迭代的总次数。实例判别损失定义如下:
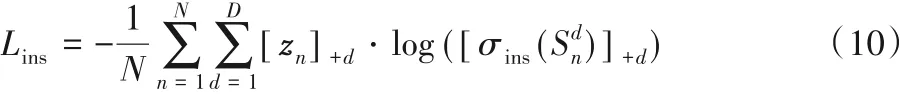
和Lcls不同的是,实例判别损失函数Lins仅计算的是d 序列中预测框Ri对应类为目标的样本,用符号+表示。该损失函数会使得目标物体在当前序列中的分数变得较大,而在其他序列中变得较小,最终使得网络模型在多个物体含有相似语义信息但是属于不同类别的情况下,能够有效保持其判别能力的鲁棒性。
2.3 SAMDNet的离线训练
SAMDNet 离线训练时,其离线训练模型的多分支全连接层对应不同的视频序列,卷积层是共享的。离线网络模型中卷积层参数的初始化是直接加载已在ImageNet上预训练好的VGG-M 网络中对应卷积层的参数,全连接层中的参数由标准正态分布初始化,整个网络的所有参数均是可学习的。在离线训练的每次迭代中,训练数据来自于每个视频序列的正负样本集,样本集是以目标真实框为中心,以高斯随机的方式在其周围选取固定数目的图像块而来的,离线训练的每次迭代只处理单个视频序列,单次迭代中随机抽选当前序列中的4帧图片,每帧图片提取4个正样本和12个负样本,因此网络的输入为16 个正本和48 个负样本组成的样本集。图片网络样本集中每个样本和目标真实框的重叠率大于0.7 的被标记为正样本,重叠率小于0.5的样本被标记为负样本。
训练数据集为ImageNet-Vid,该数据集包括3 862 个短时视频序列作为训练集,555 个作为验证集,937 个用于测试集。该数据集基于目标检测任务建立,其中的每个短时视频序列都是经过精心挑选的,全方位地考虑了各种因素,如运动类型、视频背景干扰、遮挡等。
2.4 SAMDNet的测试追踪
SAMDNet 中为了预估目标的位置,预设的候选目标集合是由前一帧确定的目标框为中心在位移和尺度两个方向按照高斯分布生成的N 个候选框 Xi=(xi,yi,si)(i = 1,2,…,N),其中 xi、yi为前一帧目标框中心坐标,si为缩放比例,Xi的协方差是对角矩阵,对角线值满足(0.09r2,0.09r2,0.25),其中r 是前一帧的目标框的宽和高的均值,每个候选框的大小为前一帧目标框大小的1.05si倍。当前帧目标框的确定方式如下,记当前为第t帧,{xti}i=1,2,…,N为t帧中按高斯分布生成的N个候选框集合,则当前帧的目标框xt*定义方式如式(11)所示:

其中f+()为候选框图像经过网络模型后得到的正分数,分数最高的候选框作为当前帧的预测目标框。当选定的目标框分数f+(xt*)≥0.5时,在下一帧处理前使用边界框回归算法[11]来修正当前得到的目标框,使得当前帧更加贴合真实框。同时在负样本生成过程中使用了负样本挖掘技术[16]选取分数最接近正样本阈值的负样本作为在线训练的负样本,以此来提高模型区分正样本和负样本的能力。
网络模型的在线更新方式分为长时更新和短时更新两种:长时更新是指网络以固定处理帧数为间隔更新网络,目的是为了保证模型的鲁棒性;短时更新发生在获得的目标框分数f+(xt*)<0.5时,使用保存的历史正负样本特征立即进行网络的更新,目的是为了提高网络模型的自适应性。
3 实验结果与分析
为了验证本文提出算法的有效性,选择了近年来数个先进算法来进行对比实验。本文所提出的模型是在Pytorch 1.1.0 框架上训练的,实验平台为一台配置了Intel Xeon Bronze 3106 CPU 和一块 NVIDIA GeForce TITAN XP 显卡的计算机。
3.1 在OTB50和OTB2015上的评估
本文算法在两个公开且被广泛使用的测试基准集OTB50[17]和 OTB2015[18]上进行测试。OTB2015 包括 100 个视频序列,该数据集中充分包含11 种追踪过程中可能遇到的挑战性问题,如平面内旋转、遮挡、关照变化、运动模糊等;OTB50为OTB2015中前50个视频序列,而且这50个序列几乎涵盖了整个测试集中最复杂的视频序列。两个测试基准集有两个相同的度量标准:成功率和精确率。成功率是指预测框和标记框交集区域像素个数和并集区域像素个数之比;精确率是指预测框和标记框的中心误差在一个特定的阈值内的视频帧数占总帧数的百分比,本文算法评估采用的阈值为20。
本实验中采用的评估方法为单次通过方式(One-pass Evaluation,OPE),除了和MDNet算法对比外,另选择了多个性能顶尖的追踪算法,分别是:高效卷积算法ECO[19],ECO算法不使用 CNN 特征的版本 ECO-HC[19],2016 年视觉目标跟踪挑战(VOT2016)的冠军——连续域卷积相关滤波算法C-COT[20],空间约束相关滤波器(Spatially Regularized Correlation Filter,SRDCF)添加了深度CNN特征的版本DeepSRDCF[21],作为深度视觉追踪的基准对比算法CNN-SVM[22],全卷积孪生网络算法(Fully-Convolutional Siamese network,SiamFC)的多尺度版本SiamFC-3s[23],以 及 判 别 式 相 关 滤 波 器 网 络(Discriminant Correlation Filter Network,DCFNet)[24]。
图4 为OTB50 数据集下的测试结果,可以看出本文的SAMDNet 算法相较于原算法MDNet 在精确率率指标上提高了2.5个百分点,在成功率指标上提高了1.6个百分点。本文算法在精确率和成功率两个指标上全面超过了CCOT和ECOHC 算法,在精确率指标上与ECO 算法相比提高了1.4个百分点。图5 为OTB2015 数据集下的测试结果,可以看出本文的SAMDNet 算法在精确率指标上取得了0.907 的优异表现,超过MDNet 算法1.8 个百分点,也超过了CCOT 算法接近1 个百分点,此外和CCOT 的改进版本ECO 算法仅仅相差0.3 个百分点,SAMDNet 在成功率指标上也超过了CCOT 和MDNet 等其他算法。
为了进一步验证本文算法的有效性,选择了7 个性能先进的算法进行了属性对比实验,结果如表1 所示,选择的测试基准集为OTB2015。本文选取的对比属性有背景杂斑(Background Clutter,BC)、尺度变化(Scale Variation,SV)、遮挡(OCclusion,OC)、形变(DEformation,DE)、平面内旋转(In-Plane Rotation,IPR)、平面外旋转(Out-of-Plane Rotation,OPR)、超出视野(Out of View,OV)、光照变换(Illumination Variation,IV)、运动模糊(Motion Blur,MB)、快速移动(Fast Motion,FM)、低分辨率(Low Resolution,LR),选取的评价指标为成功率。如表1 所示,加粗的为对比实验中该列的最大值,可以看出,在11 个属性中,本文算法SAMDNet 相较于MDNet 算法在8 个属性上均有不同程度的提升,相较于全部选择的对比算法SAMDNet在属性SV、DE、IPR、OPR 上达到了最佳表现,其他属性上也与各自最优值极其接近。
3.2 消融实验
基于卷积神经网络的视觉追踪中,传统网络模型中池化层的存在是为了压缩网络模型的参数量和降低过拟合,但同时也导致了大量数据损失,而且这种损失会随着网络模型层数的增加而逐渐叠加,虽然深度特征抽象度高、鲁棒性好,但深度特征的空间信息损失也越多,这不利于需要精确空间定位的追踪任务。基于此,本文所提算法中将空间注意力模块设置在CONV1 和CONV2 之间,在出现空间信息损失之前,最大限度地使相似的特征彼此相关,突出相似特征的空间信息。对于通道注意力模块而言,其注意力矩阵的计算方式和空间注意力类似,但是以每个通道的特征图之间的互相映射的角度来衡量彼此间的依赖关系,为了有选择地突出互相关联的通道的重要性的同时最大化通道注意力矩阵信息的丰富性,因此本文算法中通道注意力模块加载到卷积层通道数最多的CONV3之后。

图4 SAMDNet在OTB50的测试结果Fig.4 Test results of SAMDNet on OTB50
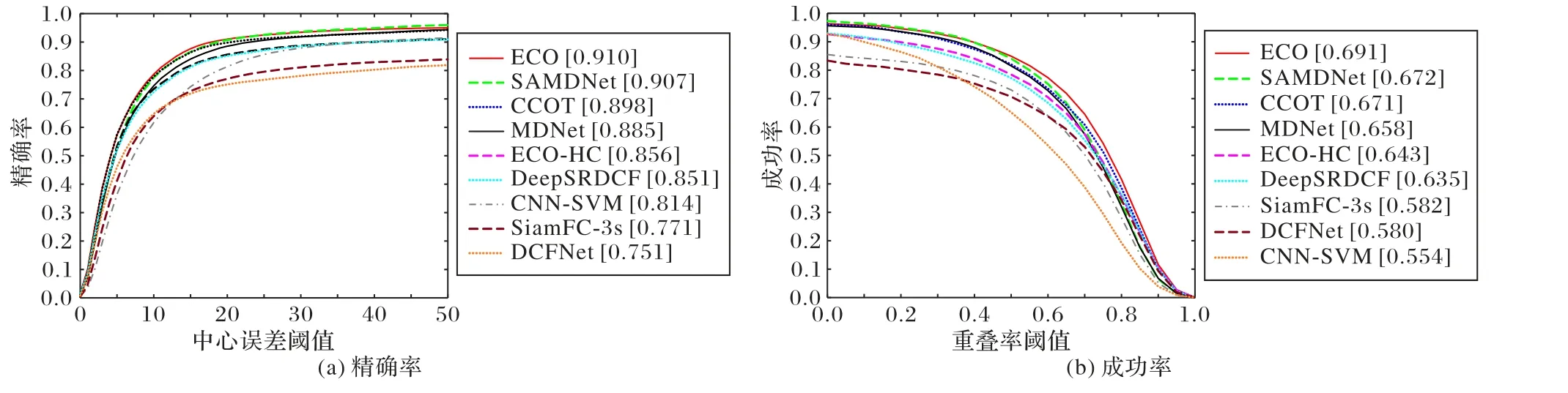
图5 SAMDNet在OTB2015的测试结果Fig.5 Test results of SAMDNet on OTB2015
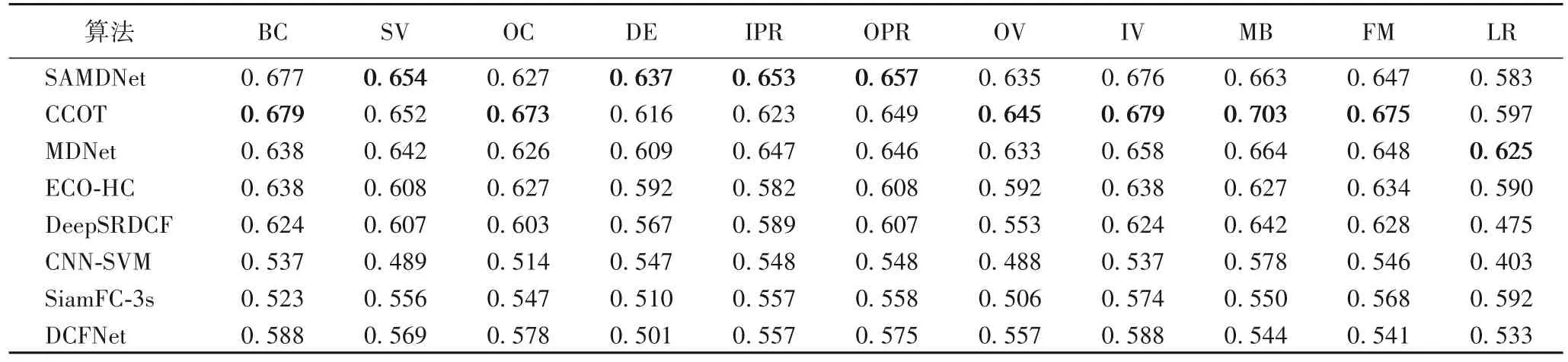
表1 不同追踪算法的11个属性的成功率对比Tab. 1 Success rate comparison of 11 attributes of different tracking algorithms
为了进一步验证本文算法SAMDNet 中各模块的有效性,设计了如表2、3 所示的消融实验:C1p 含义为在卷积层CONV1 之后设置了空间注意力模块,C3c 含义是在CONV3 之后设置了通道注意力模块;I含义为预训练模型是采用了包含实例判别函数的复合损失函数;15 指的是测试基准集为OTB2015。实验结果表明,各个模块对算法的性能提升都起着积极作用,最佳的表现来自于三个模块的共同作用。
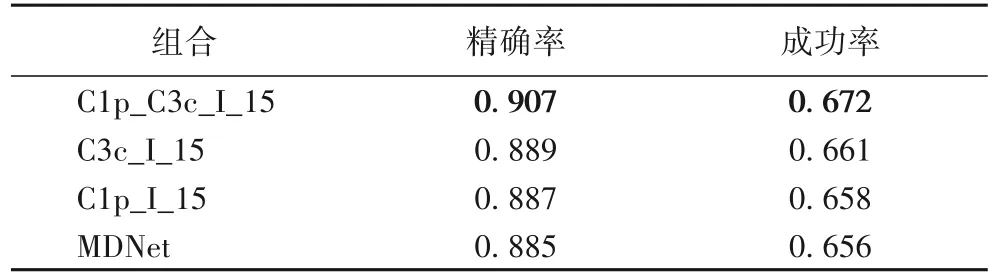
表2 SAMDNet的子模块组合实验的精确率和成功率对比Tab. 2 Comparison of SAMDNet’sub-module combinations on precision and success rate
表3 为注意力模块的组合实验,实验中通道注意力模块的位置是固定的,空间注意力模块的位置是变量。实验结果表明当空间注意模块处于CONV1后可以获得最佳性能,同时也验证了算法模型设计的合理性。
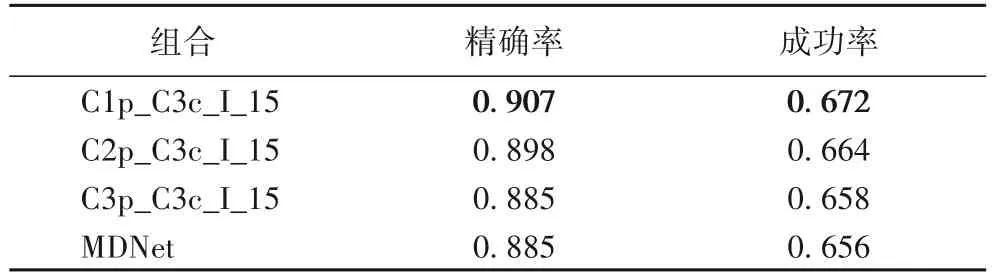
表3 不同注意力模块组合的精确率和成功率对比Tab. 3 Comparison of different attention module combinations on precision and success rate
4 结语
本文是基于多域卷积神经网络(MDNet)的算法改进,通过引入自注意力机制来解决原算法中模型漂移问题,此外通过实例判别函数提升了模型对包含相似语义信息目标的判别能力。由于基于卷积神经网络的深度追踪中目标位置信息容易随着网络深度的加深而逐渐损失,最后影响追踪目标的精确定位,而空间注意力和通道注意力的应用使模型获得了更鲁棒的位置表示,目标定位更加准确。本文算法在广泛使用的测试基准集OTB50 和OTB2015 上取得了优秀的表现,显著超越MDNet 算法的同时,也在两个测试基准集上全面超过了VOT2016 的冠军算法CCOT,同时在OTB50 精确率指标上也超过了2017年的ECO 算法。但是本文算法也存在一些不足,如实验过程中发现该算法在目标出现运动模糊、快速移动和低分辨率等情况时,追踪效果并不理想,所以未来将进一步研究克服该算法存在的不足。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
第二课堂(课外活动版)(2016年2期)2016-10-21
西南学林(2011年0期)2011-11-12
