
改进SSD的安全帽佩戴检测方法
2020-09-02 13:43:12肖体刚蔡乐才汤科元张超洋
四川轻化工大学学报(自然科学版) 2020年4期
肖体刚, 蔡乐才, 汤科元, 高 祥, 张超洋
(1.四川轻化工大学自动化与信息工程学院, 四川 自贡 643000;2.宜宾学院三江人工智能与机器人研究院, 四川 宜宾 644000)
引 言
在施工、生产和煤矿作业中,安全帽是一种保护工作人员头部的工具[1],在作业过程中是必须要求所有人员佩戴。安全帽可以保护头部免受高处坠物对头部的冲击力,减轻头部在重压下受到的损伤,从而保护工作人员在危机时刻的生命安全[2]。根据权威机构的部分统计显示,施工场所造成的伤亡事故大部分都是因为没有佩戴安全帽造成的,为了降低施工人员因没有佩戴安全帽造成的事故率,有必要对人员进行安全帽佩戴检测[2]。另外,在准确检测出安全帽佩戴情况的前提下,快速检测出未佩戴安全帽人员,并及时给予预警和提醒,也会大大降低因未佩戴安全帽造成的生命和财产损失发生率[2]。因而,在工厂等需要佩戴安全帽的场所中,及时并准确地检测出安全帽佩戴情况是一个值得研究的问题。
近年来,卷积神经网络提取图像特征为分类等任务带来了很大的提升,这引起了很多计算机视觉方向学者的青睐,很多研究机构也是在此基础上进行了一系列的视觉任务研究,其中基于深度学习的目标检测尤为热门,产生了许多经典的目标检测算法。Girshick等[3]在2014年结合了卷积网络和候选区域框算法(selective search)提出了区域卷积神经网络(R-CNN)算法,揭开了深度特征的目标检测序幕。2015年,Girshick等[4]在R-CNN的基础上提出了Fast-RCNN算法,先进行全图的卷积特征提取后再进行候选框的提取,很大程度上提升了检测的速率。同年,Ren等[5]使用区域搜索网络(RPN)结合卷积网络提出Faster-RCNN算法,在保证检测精度的同时,提高了检测速率,达到17 fps。2016年,Redmon等[6]提出了端到端的目标检测算法YOLO,从此开启了一步法的深度学习目标检测时代。在同年的国际视觉会议上,中国学者Liu等[7]也提出了相同类型的目标检测算法SSD,SSD不仅在检测速度上很快,平均检测精准度也首次超过了两步检测法Faster R-CNN。但是从实验对比和分析上来看,在对较小目标和密集目标的检测上,端到端的目标检测算法仍需改进,基于此,Redmon[8]又相继提出了YOLOv2和YOLOv3检测算法。
随着深度目标检测的快速发展,很多研究者将这种技术应用到实际的工程实践中。吴天舒等[9]运用YOLO算法进行驾驶员安全带检测,实现了对驾驶员安全带的快速检测。沈新烽等[10]在SSD算法的基础上进行改进,运用到零部件检测中,实现了在生产线上对零件的精确实时检测。安全帽佩戴检测问题也是一类目标检测问题,国内外很多学者已经进行了相关的研究。刘晓慧等[11]通过肤色检测的方法定位到人脸,然后提取到安全帽的Hu矩,利用支持向量机完成对安全帽的检测。Park[12]等通过方向梯度直方图和颜色直方图检测安全帽。贾峻苏等[13]采用可变形部件模型,将梯度方向直方图、颜色特征和局部二值模式直方图进行组合,加上支持向量机对安全帽的佩戴进行检测。这些方法在安全帽检测上取得了一些效果,但是这些方法采用人工设计特征提取算法的方式进行检测,泛化能力比较差,人工设计特征提取算法需要花费大量时间,可能在复杂的环境因素干扰下,检测效果鲁棒性较差。为此,一些学者采用深度学习目标检测算法完成检测任务,采用卷积神经网络进行特征提取,在搭建的卷积网络下运用大量数据进行训练,使得最后的检测模型对各种检测环境有较强的适应性。李昕等[14]采用在深度目标检测算法YOLOv3的基础上进行改进,实现了对遥感图像中的油罐检测。徐守坤等[15]采用对两步目标检测算法Faster-RCNN进行改进,实现了对安全帽佩戴的检测。杜晨锡等[16]在YOLOv2的基础上进行改进,完成了对视频火焰的检测,达到对火灾进行预测的效果。这些研究都在深度目标检测算法的基础上改进,实现了对特定目标的检测任务,在检测精度和检测速率上取得了比较好的效果。而且,由于采用卷积网络提取特征,模型的泛化能力比传统检测算法较好,同时也证明了对于特定目标的检测,基于深度学习目标检测的改进算法具有可行性。
通过以上的分析,本文在SSD算法的基础上,提出一种改进SSD的安全帽佩戴检测算法,以实现对安全帽佩戴情况的快速准确检测。为了实现提高检测速率,替换SSD算法的卷积神经网络VGG-16为MobileNetV3-small,同时将输入图片尺寸从300×300减少为224×224。为提升改进算法的检测准确度,引入特征金字塔网络结构,融合不同分辨率的特征图。通过爬虫网络收集以及实际监控录像的方式获取数据并制作数据集,命名为HWear。实验表明,相比SSD算法,本文改进的算法提升了检测精度和检测速率,有助于将来在移动端现场部署。
1 经典的SSD模型
SSD目标检测算法是2016年ECCV会议上由Liu等[7]提出的算法,相对于two-stage方法有着更快的检测速率。SSD的主干特征提取网络是由VGG-16卷积网络组成,其在VGG-16的网络基础上添加了部分卷积层获取不同尺度的特征图用于位置和类别预测,实现多尺度特征图预测结构。SSD算法网络如图 1所示,其中多尺度预测提取的特征图尺寸分别是38×38、19×19、10×10、5×5、3×3、1×1。SSD算法的目标检测损失函数如式(1)表示,由位置损失和分类损失加权求和组成,本文实验过程中的训练和测试都是按照这个函数进行。

图1 SSD网络图
(1)
其中:M表示正样本的总和;x表示默认框和真实框的匹配结果,x=0表示失败,x=1表示成功;c是softmax函数分别对每一类别判断的置信度;Lloc(x,l,g)为位置损失函数,Lconf(x,c)分类损失函数,分别表示为:
(2)
(3)
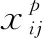
(4)
2 改进的SSD安全帽佩戴检测模型
2.1 MobileNetV3-small-SSD的网络结构
本文使用MobileNetV3-small作为改进SSD算法的特征提取主干网络。为了配合SSD算法,本文移除了MobileNetV3-small[17]的平均池化层和1×1卷积层,然后在简单处理后的MobileNetV3-small网络后面添加一系列卷积层,改进算法的整体网络模型如图2所示,其中蓝色框表示bottleneck结构得到的特征层,黄色框表示正常卷积的特征层,网络结构参数见表1。
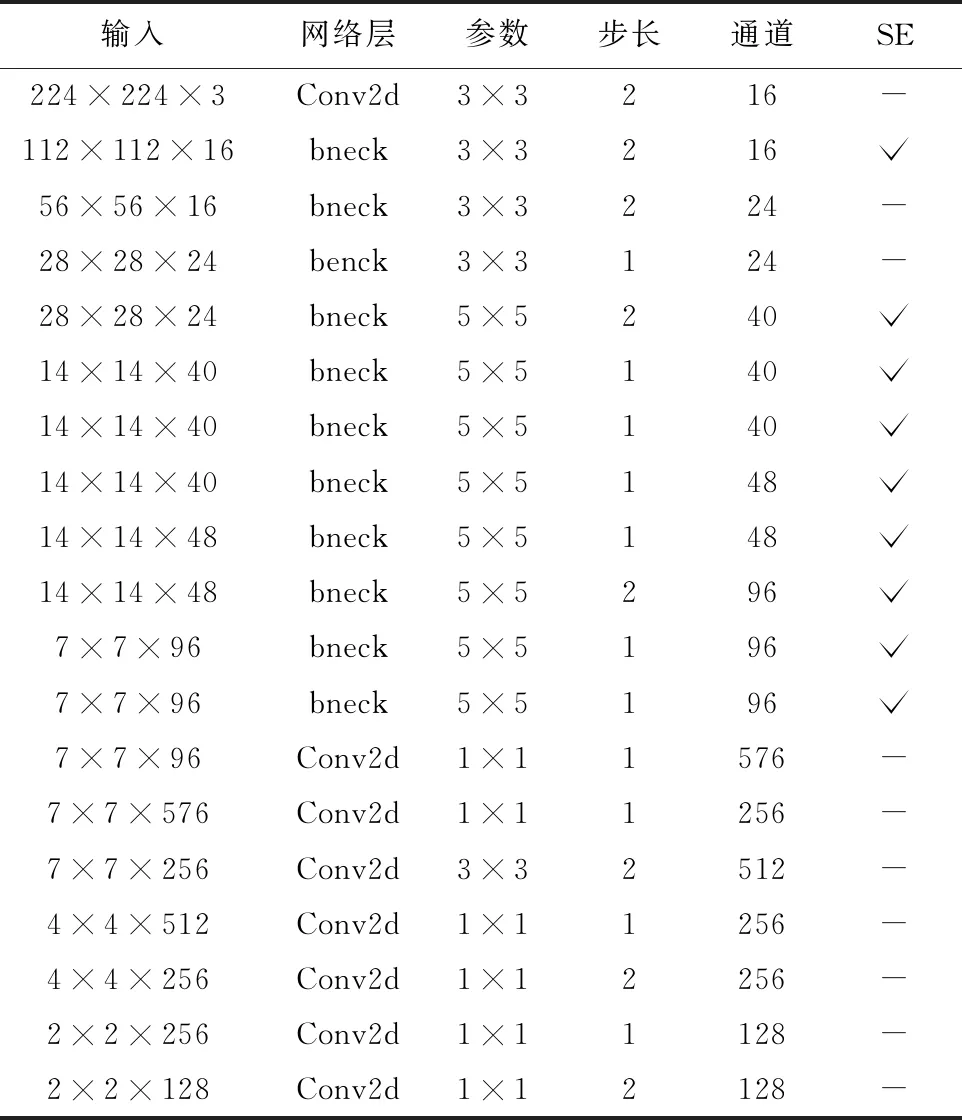
表1 MobileNetV3-small-SSD网络参数表
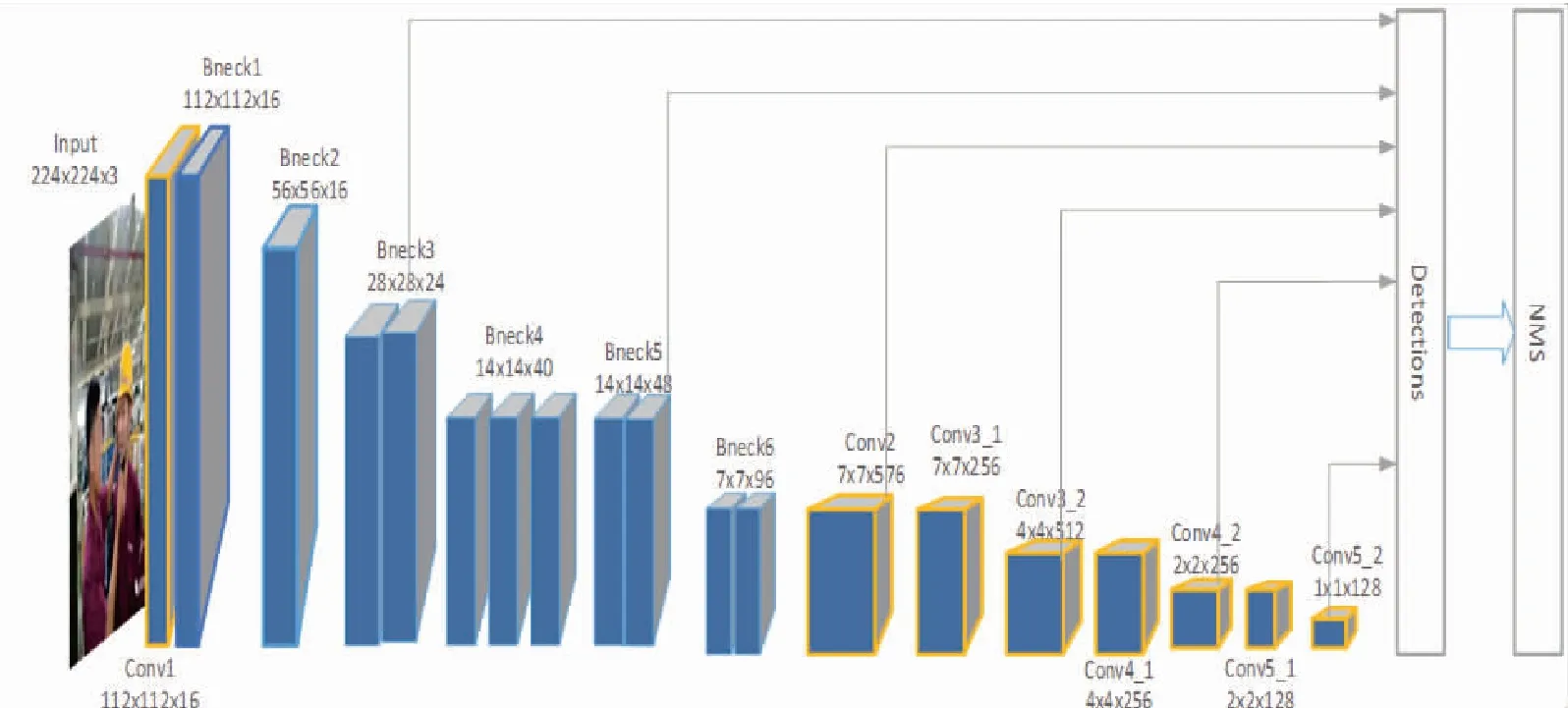
图2 MobileNetV3-small-SSD网络结构图
通过一些修改,本文的算法框架将原SSD算法输入尺寸300×300减少为224×224;原SSD算法获取38×38、19×19、10×10、5×5、3×3、1×1共6个尺寸的特征图实现多尺度特征图检测,6种特征层之间没有任何联系,本文算法选取28×28、14×14、7×7、4×4、2×2、1×1共6种尺寸特征图为特征金字塔结构做准备,实现层与层之间的信息融合,便于计算从特征图到原始图像的对应位置关系;将获取6种特征图自底向上构成特征金字塔结构,实现不同特征层的融合。
MobileNetV3[17]中主要的结构就是bottleneck,其主要由三部分组成:深度可分离卷积、反残差结构和SE块。反残差结构是在MobileNet V2中用ResNet的残差结构改进得到[18],在 bottleneck 结构中当卷积核步长为 1 时使用,用于减少梯度消失的出现。bottleneck结构先使用逐点卷积降维,再使用深度卷积,最后使用逐点卷积提升维度。MobileNetV3-small的bottleneck模块结构如图3所示。
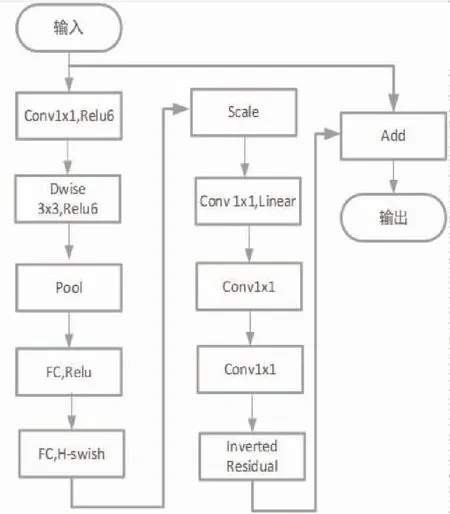
图3 bottleneck 结构
深度可分离卷积计算公式为:
(5)
其中:P表示输出特征图;G表示卷积核;K表示输入特征图;i和j为特征图像素位置;k、l表示输出特征图分辨率;m表示通道数[18]。
相较于标准卷积,深度可分离卷积分为深度卷积和点卷积两个阶段[18],如图4所示,一般来说标准的多通道卷积的计算如公式(6)所示,深度可分离卷积的计算如公式(7)所示。
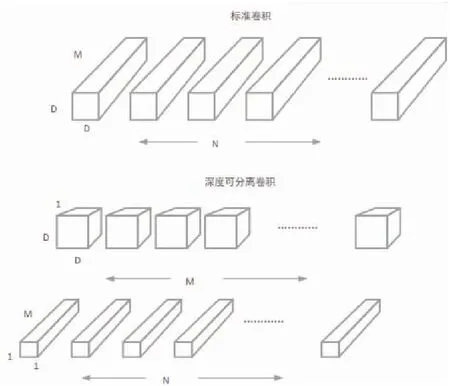
图4 标准卷积和深度可分离卷积对比图
DK×DK×M×N×DF×DF
(6)
DK×DK×M×DF×DF+M×N×DF×DF
(7)
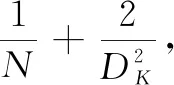
(8)
SE模块首先存在于SENet网络结构中[18],它将特征通道的相关性实现建模,增强重要的特征信息,提升网络模型的鲁棒性,这部分在网络模型中是可以选择的。本文所使用的bottleneck 结构的内部就是使用了这个SE模块。SE模块的h-swish激活函数是由swish演变而来,与swish函数类似,其公式为:
(9)
2.2 特征金字塔结构的引入
SSD模型的金字塔特征层检测结构如图5所示,其从不同层提取不同大小的特征图做预测,不同深度的特征图有着不同的语义信息,浅层的特征层分辨率高,包含的语义信息比较少,对于小目标的检测鲁棒性较好,深层的特征层学到更深的语义信息,但也丢失了特征信息,对小目标的检测效果较差。本文使用MobileNetV3-small轻量型卷积网络替换原来SSD的VGG-16网络,必然会导致特征信息的提取减少。为了减少这个缺陷带来的影响,本文引入特征金字塔网络结构融合特征,如图6所示。特征金字塔网络结构[19]是将高分辨率的浅层特征层和低分辨率深层特征层进行融合,使得最终用于预测的特征图同时具有浅层特征和深层特征的语义信息,使得整体的检测精度提升,从而提升改进算法在安全帽佩戴检测这一问题上的鲁棒性。
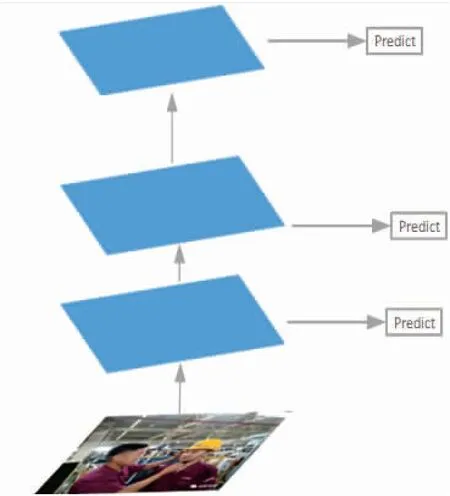
图5 金字塔特征层
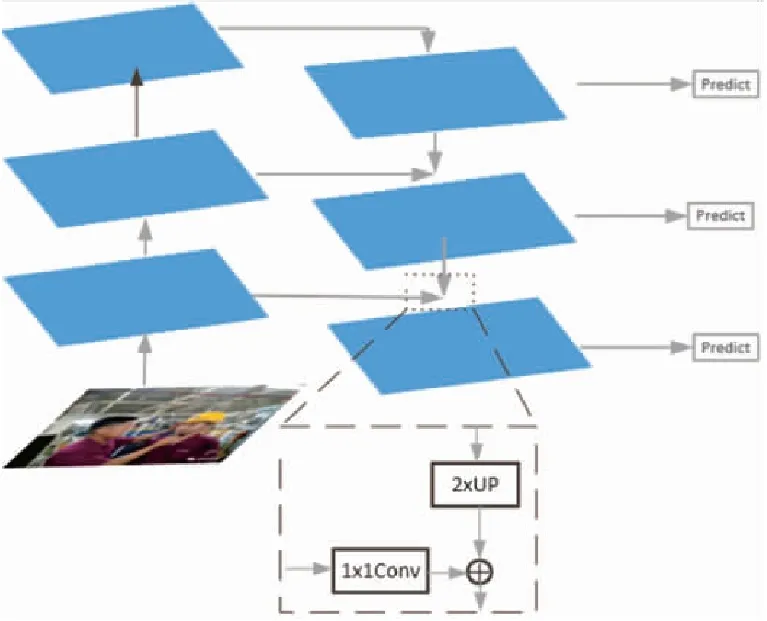
图6 特征金字塔网络
由图6可知,本文截取6种不同分辨率的特征层组成金字塔结构,然后自顶向下将深层更加抽象的特征层进行2倍的上采样,与前一层特征层的尺度一致,采用1×1卷积将通道数提升到512,提高最后的预测效果。本文特征金字塔网络会产生6类融合了不同尺度、不同语义信息的特征层,使用非极大值抑制(NMS)对所有预测的目标框进行筛选后获得最终的预测目标框。与SSD算法相比,本文算法将大大减少计算量,提升检测速率。
3 实验过程
3.1 数据集
通过爬虫收集和实际场景监控录像等方式收集7000张样本标注并制作数据集。获取的安全帽佩戴情况数据经过筛选后,基本都是施工现场的人员佩戴情况。样本的标注使用labelimg标注出目标区域以及类别,对佩戴安全帽的人员标注为hat(正样本),对未佩戴安全帽的人员标注为person(负样本),如图7所示。最后将收集的图片和标注的正负样本制作成Hwear数据集,最后标注的总数为64 862个,其中8562个佩戴安全帽正类,以及56 300个未佩戴安全帽的负类。其中5844张图作为训练样本,1156张图片作为测试样本。数据集的分配见表2。
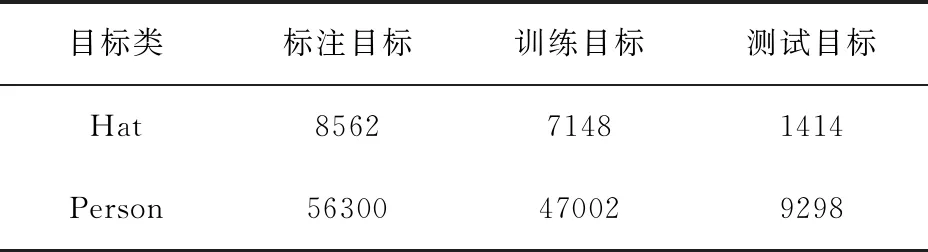
表2 数据集分配表

图7 样本标注
3.2 模型训练
本文的实验环境为:Intel(R) Core(TM) i7-9750 CPU @ 2.60G 2.59 GHz,32 G运行内存,Nvidia Gefo-rece Gtx1660ti,ubuntu16.04,64位操作系统,Tensorflow深度学习框架。实验采用自主收集制作的数据集HWear从零开始训练改进的MobileNetV3-small-SSD算法,最终得到该网络在安全帽佩戴检测这一目标检测问题上的模型。在训练阶段,参照文献[7]的超参数对本文算法的部分超参数进行调整,见表3。
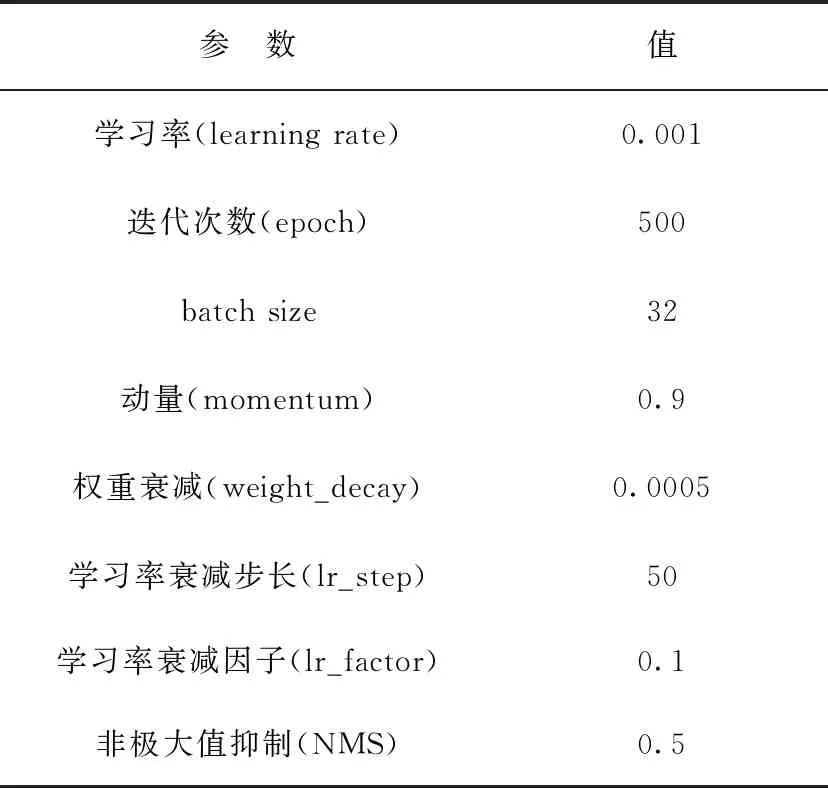
表3 本文算法的部分超参数设置
在训练阶段,采用数据增强技术提升网络模型的性能,对样本进行裁剪、平移、亮度改变、加噪声等,实现数据的扩增效果,如图8所示;训练采用多尺度策略,每5个训练周期就重新调整输入图像分辨率大小,增强对不同分辨率图像的适应性。本文改进SSD算法的训练过程损失曲线图如图9所示。从图9可以看到,模型在训练近40 000次后,损失值稳定在5~10之间,通过曲线的波动程度可以推断模型较好的鲁棒性。另外,在相同的实验环境下使用制作的数据集HWear分别对原SSD和YOLOv3进行训练,得到相应的最终模型,与本文算法进行对比分析。

图8 数据增强效果图
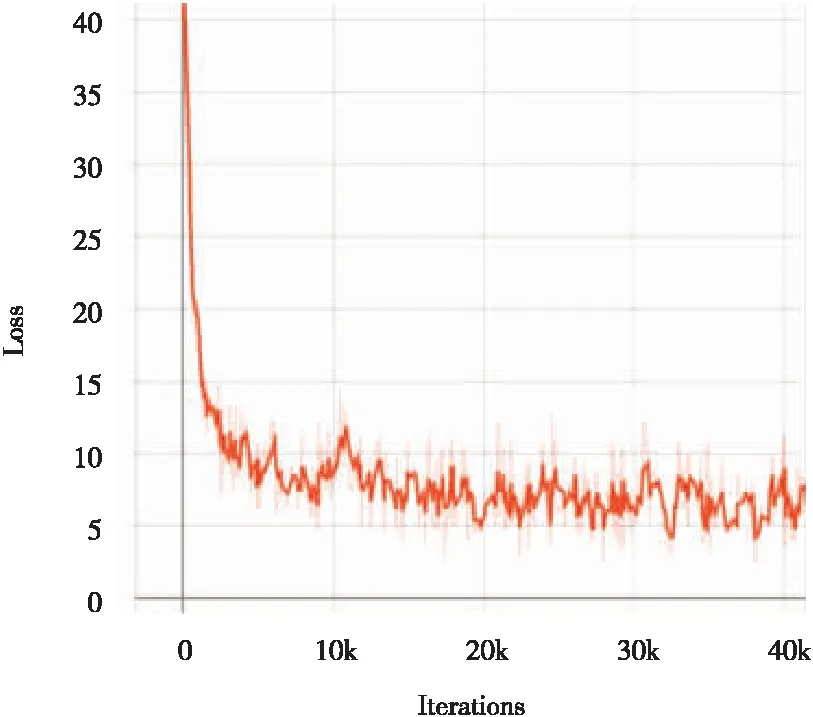
图9 损失曲线
3.3 实验结果分析
为了对比本文改进算法的有效性,本文使用制作的测试样本集对训练的SSD和YOLOv3等模型以及本文MobileNetV3-small-SSD模型进行性能测试,并统计测试的输出图像数据进行对比分析。图10是在测试样本中随机选择的5张图片进行对比分析。图10(a)是原始图像样本,从左往右,依次编号1、2、3、4、5;图10(b)是在SSD算法下的测试结果;图10(c)和图10(d)是分别在本文算法MobileNetV3-small-SSD和YOLOv3模型的测试结果。对应的输出结果中,红色框表示安全帽佩戴的人员hat,蓝色框表示未佩戴安全帽的人员person。从输出的结果中可以看到,3种模型在无遮挡环境且面对大目标的情况下检测结果都正确,准确检测到4个佩戴安全帽人员和一个未佩戴安全帽人员,如第2列图所示。在第1列和第3列样本中存在部分小目标的情况下,可以看到SSD在对于1个未佩戴安全帽的小目标检测效果不准确,而本文算法和YOLOv3准确地检测到了该目标。在第4列和第5列存在密集小目标且存在部分目标遮挡以及光线较暗等环境干扰情况下,SSD算法和本文算法存在漏检情况,但本文算法相比与SSD多检测成功一个小目标,YOLOv3算法检测效果较好,但仍存在部分漏检情况。通过对比分析可以发现,本文通过替换SSD算法的卷积网络以及添加特征金字塔结构,融合了高低分辨率特征图的语义信息,在一定的程度上提升了检测的准确度,尤其是对一些小目标的检测。通过图10的对比分析可知,本文算法在检测准确度上接近YOLOv3算法,优于SSD算法。

图10 部分样本对比检测结果
为了检验改进的SSD算法MobileNetV3-small-SSD对于人员安全帽佩戴检测的有效性和实时性,本文运用精准度(Precision)、召回率(Recall)和错误率(Error)来检验改进算法的有效性。对应指标分别表示为:
(10)
(11)
(12)
其中:TP(true positive)表示检测结果为正值的正样本[20],FP(false positive)表示被检测为负值的正样本;FN(false negative)表示被检测为负值的正样本。为了进一步对比算法改进的效果,获取现场摄像头某时段的监控视频,并针对视频流按照每秒提取1帧的频率获得200张测试样本,在对数据进行筛选和标注后,统计总共有355个佩戴安全帽人员和261个未佩戴安全帽人员。同训练样本一致,佩戴安全帽为正样本hat,未佩戴安全帽为负样本person。对比验证SSD算法和本文算法,统计结果见表4。
分析表4可以发现,在SSD基础上改进的算法MobileNetV3-small-SSD相比于SSD算法,对于正样本hat和负样本person的测试在精准度上平均提高了3.85%,在召回率上平均提高了7.6%,同时错误率平均减少了8.1%。由图10所示的对比实验也可以看出,改进算法相比与SSD算法是有效的,并且算法性能优于原算法。

表4 模型效果对比
使用本文制作的安全帽佩戴检测数据集HWear对本文改进算法、SSD以及YOLOv3等模型进行测试实验,整个过程在同一硬件环境下进行。测试实验分别在CPU和GPU下进行检测测试,记录各个模型的检测准确率和在不同运算环境下的检测速率,统计结果见表5。由表5可以看出,本文改进算法MobileNetV3-small-SSD在检测准确率上与SSD算法相近,mAP仅提高了0.5%,逊色于YOLOv3,但因为整个模型采用了轻量化模型MobileNetV3-small,所以相比与SSD和YOLOv3,模型的参数量减少了很多,可以减少90%以上的计算量。另外,从检测速率对比来看,本文采用轻量模型作为特征提取网络,大大提高了检测的速率,由表5可以看到,在本文的实验设备条件上,基于GPU的检测速度达到108 fps,基于CPU的检测速度也有62 fps,检测速率达到了实时性效果,有利于在实际现场部署。
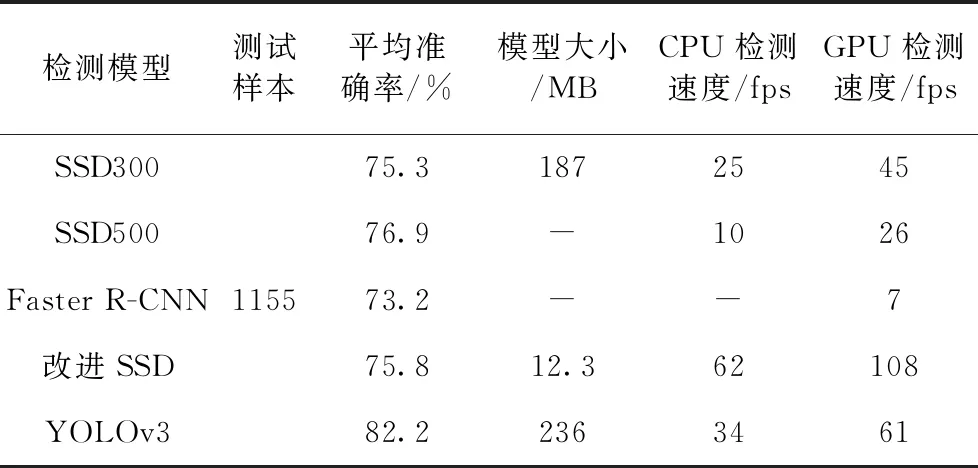
表5 测试结果对比
4 结束语
本文在SSD算法的基础上提出了一种改进的用于安全帽佩戴快速检测的算法MobileNetV3-small-SSD。改进算法主要使用MobileNetV3-small轻量型的卷积神经网络替换SSD算法的VGG-16卷积网络,采用特征金字塔网络结构增强语义信息的融合。实验采用本文制作数据集HWear的方式对模型进行训练和测试,在相同的HWear数据集上分别对SSD、YOLOv3等算法进行训练和测试。实验对比结果表明,本文改进算法的检测准确率稍优于SSD算法且接近YOLOv3,检测速度优于SSD和YOLOv3等算法,能够实现实时性检测,具有一定的实践和现实意义。另外,本文算法仍会出现错检漏检等情况,将在以后研究中进行改进。
猜你喜欢
星星·诗歌原创(2023年12期)2024-01-06 08:24:53
机电安全(2022年4期)2022-08-27 01:59:42
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
电子制作(2019年11期)2019-07-04 00:34:38
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电视技术(2014年19期)2014-03-11 15:38:20
