
轻量化GAN超分辨率图像重构算法在实时人脸识别中的应用
2020-09-02 06:52:22曾凡智邱腾达陈嘉文
小型微型计算机系统 2020年9期
曾凡智,邹 磊,周 燕,邱腾达,陈嘉文
(佛山科学技术学院 计算机系,广东 佛山528000)
E-mail:coolhead@126.com
1 引 言
超分辨率[1]技术是指从一副或多幅低分辨率图像中重构出相应高分辨率图像的技术,该技术可以在现有硬件环境不改变的情况下,在低分辨率图像基础上,利用图像的先验信息重构出相对清晰的高分辨率图像,在刑事侦查、医学影像、天文观测[2]和影视娱乐等领域都具有十分重要的应用价值.
目前运用相对广泛的超分辨率图像重构的方法主要有以下三类:基于图像插值的方法、基于图像重建的方法以及基于学习[3,4]的方法.基于图像插值的方法,主要有双线性插值、最近邻插值和双三次插值,此类方法虽然处理速度快,同时能有效增加图像的分辨率,但是生成的图像过于模糊,细节丢失严重;基于图像重建的方法在恢复图像高频信息方面取得了良好进展,但是此类方法在处理一些复杂图像(例如人脸)时效果不佳[5];基于学习的方法能够利用训练样本所提供的先验信息推导从低分辨率图像重构出高分辨率图像时所需要的高频细节信息,例如局部线性嵌入、稀疏表达等,此类方法相较前面两类在图像重构的质量上有所提高.
随着2014年深度学习热潮的开始,基于深度学习的方法目前已经在众多领域都得到了广泛的应用,同时在超分辨率图像重构领域也越来越受到了人们的重视.在基于卷积神经网络的方法中,Dong等人[6]提出SRCNN(Super-Resolution Convolutional Neural Network)的方法,将基于深度学习的方法与超分辨率图像重构技术结合.SRCNN先用双三次插值将低分辨率图像放大成目标尺寸,再通过三层卷积层拟合非线性映射,最后输出高分辨率图像.Tong等人[7]参照DenseNet[8]高强度稠密连接的方式,对低分辨率图像进行超分辨率重构,使得网络复杂度大幅下降并提高了网络训练速度.Zhang等人[9]创新性地将残差块和稠密连接块结合,得到残差稠密块,加深了网络结构,增加了网络感受野并提升了性能.基于卷积神经网络的超分辨率图像重构方法所得的结果虽然有较高的信噪比,但图像缺少高频信息,在细节上缺乏真实感,所以会出现过度平滑的纹理.
近几年,生成对抗网络在图像修复领域取得了重大突破,由生成对抗网络产生的图像具有更加逼真的视觉效果.Ledig等人[10]提出SRGAN(Super-Resolution Generative Adversarial Network)方法,通过SRGAN生成的图像在感知质量方面较之前的方法有显著的提升.Lim等人[11]在SRGAN网络结构的基础上提出增强的深度残差超分辨率网络,同时该网络去除了批量归一化层,这不仅大幅减少了计算量,还使模型更加适用于超分辨率图像重构这类低层视觉任务;Yang等人[12]提出基于判别性增强的EDGAN(Enhanced Discriminative Generative Adversarial Network)网络,该网络使用一种改进感受损失,在激活函数之前使用特征,取得了不错的重构效果.
由于现有基于生成对抗神经网络的超分辨率图像重构算法存在计算量巨大,模型占用内存多,实时场景运行严重延时等问题,本文基于生成对抗网络框架,提出一种轻量化的GAN超分辨率图像重构算法,致力于解决超分辨率图像重构技术运用在实时人脸识别相关场景中,造成严重延时和模型占用空间大等问题.
2 超分辨率图像重构技术在人脸识别中的应用
随着深度学习技术的不断进步,人脸识别的准确率相比过去有了巨大的飞跃,然而当前众多人脸识别算法在面对复杂环境(如光照剧烈变化)时,其识别准确率不能令人满意.在人脸识别算法中,附加基于超分辨率图像重构的预处理模块是一种新的方法,它可以提高人脸识别算法在复杂环境中的准确率.
结合超分辨率图像重构技术的人脸识别算法运行流程如图1所示.首先,从视频中获取一帧人脸图像,将图像送入人脸检测模块得到人脸位置信息,裁剪出人脸并放大到一定尺寸,然后将放大后的模糊头像送入超分辨率重构模块进行图像重构获得高清头像,最后送入人脸识别模块进行特征提取和相似度计算并得到识别结果.模糊头像产生的原因是低分辨率图像向高分辨率图像转化的过程中,造成图像失真而显得模糊,人脸特征严重丢失.

图1 结合超分辨率图像重构技术的人脸识别算法运行流程图Fig.1 Operation flow chart of face recognition algorithm combined with super-resolution image reconstruction technology
3 算法结构及具体实现
本文基于生成对抗网络框架进行超分辨率图像重构算法设计,整体网络主要包含生成器网络和判别器网络,整体网络结构如图2所示.低分辨率图像从生成器网络输入层输入,首先经过一个标准卷积层,并将输出用非线性激活函数进行激活以增强模型的非线性表达能力,再将结果依次送入17个倒置残差块中提取特征,其中倒置残差块包含扩张卷积层(Expansion Convolution,EC)、深度可分离卷积层(Depthwise Separable Convolution,DSC)、压缩卷积层(Compressed Convolution,CC)、线性(Linear Activation,LA)和非线性激活层(Swish)及特征融合层(Add),最后将结果送入亚像素卷积层(Sub-Pixel Convolution,SPC),用于将多张低分辨率图像合成一张高分辨率图像;同时将生成器网络得到的图像作为负样本送入判别器中,而正样本是没有经过处理的高分辨率图像,本文使用的判别器是具有4个稠密连接块的DenseNet网络,最后网络输出为判别高分辨率图像的真假结果.
3.1 生成器网络
受到MobileNetV2[13]和ESPCN[14](Efficient Sub-Pixel Convolutional Neural)思想的启发,本文的生成器网络主要由MobileNetV2的具有线性瓶颈的倒置残差块和ESPCN的亚像素卷积层组成,如图2生成器网络部分所示,同时为进一步提升网络性能,本文对倒置残差块做了相应的修改:去除原倒置残差块中的批量归一化层(Batch Normalization,BN),修改激活函数为Swish函数,使其更加适用于超分辨率图像重构这种低层视觉任务.
3.1.1 激活函数
修正线性单元(Rectified Linear Unit,ReLU)具有运算简单,计算效率高和信号响应快等优势,因此它常被用于各类深度学习算法中.但它的优势仅仅在正向传播方面,并且ReLU函数对负值全部舍弃,因此很容易使模型输出全零而无法再进行训练.
基于上述情况,本文取Swish函数作为激活函数,其数学形式见式(1),相比ReLU函数,Swish函数可以将激活单元的输出均值往0推进,达到批量归一化的效果且减少计算量,即输出均值接近0可以减少偏移效应进而使梯度接近于自然状态.
(1)
3.1.2 倒置残差块
倒置残差块中所用的结构是扩张——卷积——压缩,相比原生的残差结构:压缩——卷积——扩张,前者可以提升梯度在卷积层之间的传播能力,有着更好的内存使用效率,部分结构如图3所示,该结构主要包含扩张卷积层、深度可分离卷积层和压缩卷积层.研究表明[15]BN层在一定程度上限制了网络的灵活性,同时增大了计算量,因此本文在原倒置残差块的基础上移除了BN层,并使用Swish函数作为激活函数,使得算法更加适用于超分辨率图像重构这种低层视觉任务.

图3 倒置残差块部分结构图Fig.3 Structure of inverted residual block
1)深度可分离卷积:将标准卷积拆分成两个分卷积,第一层为深度卷积,对每个输入通道应用单通道的轻量级滤波器;第二层为逐点卷积,即1×1卷积,负责计算输入通道的线性组合,构建新的特征.
标准卷积的输入张量Li为hi*wi*di,标准卷积核k∈Rk*k*di*dj产生输出张量Lj为hi*wi*dj,其中h,w,di,dj,k分别为特征图的长、宽、输入通道数、输出通道数以及卷积核边长.
1.标准卷积的计算消耗为:hi*wi*di*dj*k*k;
2.深度可分离卷积消耗为:hi*wi*di*(k2+dj);
参照MobileNetV2网络设计,本文使用的卷积核大小k=3,dj最小取64,与标准卷积相比计算量减少了8-9倍.
2)扩张卷积层与压缩卷积层:深度卷积本身不具备改变通道的能力,输入通道数等于输出通道数,如果输入通道很少的话,深度卷积只能在低维度上工作,这样所得的效果会很差,因此通过逐点卷积先进行升维(升维倍数为t,本文依据MobileNetV2实验结果,t取4),使深度卷积在一个更高维空间中进行特征提取,最后为了保证输入维数与输出维数相等,还需要加一个逐点卷积层进行降维操作.
3.1.3 亚像素卷积层
亚像素卷积可以很好地避免算法直接在高分辨率空间进行重构,相比SRCNN先对低分辨率图像进行预处理,然后在高分辨率空间重构的方法,亚像素卷积不仅节省了不必要的计算量,而且实现了较好的图像上采样效果.具体上采样过程如图4所示,将4个图片中的第一个像素取出成为重构图中的4个像素,以此类推,在重构图中的每个2×2区域都是由这4幅图对应位置的像素组成(重构后的图像尺寸是原来低分辨率图像尺寸的4倍).亚像素卷积的方法只在最后几层进行图像低分辨率到高分辨率的大小变换,保证了前面的卷积运算均在低分辨率图像上进行,从而得到更高的运算效率.
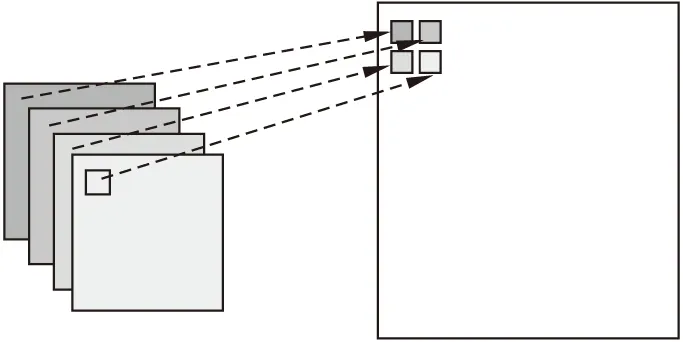
图4 亚像素卷积层上采样过程Fig.4 Sampling process on sub-pixel convolution layer
3.2 判别器网络
判别器网络使用具有稠密连接块的DenseNet网络训练,DenseNet通过稠密连接改善了网络中信息和梯度的流动,进而使网络易于训练,DenseNet在参数和计算成本更少的情形下实现比ResNet[16]更优的性能.DenseNet主要由多个稠密连接块组成,稠密连接块具体结构如图5所示.每一个连接块

图5 稠密连接块组成结构Fig.5 Structure of dense connection block
均有多个元素组成,每一个元素又有1×1卷积层、Swish激活函数、BN层、3×3卷积层组成,其中1×1卷积层的作用是对上层输出数据压缩、降维以减少计算量.
在将高分辨率图像送入判别器网络之前,对图像进行随机翻转、裁剪等数据增强方式充分增加训练样本量,以提高模型的稳定性.经过大量次数的迭代训练会使生成器尽可能模拟出以假乱真的样本,而判别器会有更加精准的鉴别真伪数据的能力,最终整个对抗神经网络会达到一个纳什均衡,即判别器对于生成器的数据鉴别结果为正确率和错误率各占50%.
3.3 生成器损失
本文将均方误差(Mean Square Error,MSE)与对抗损失的总和作为训练整个生成器网络的总体损失,生成器网络损失表达式(2)如下:
LG=Lmse+Ladv
(2)
其中LG表示生成器网络总体损失,Lmse表示均方误差损失,Ladv表示对抗损失.
3.3.1 均方误差损失
本文采用基于像素的均方误差作为生成器网络损失的一部分,在算法中采用均方误差用于计算生成器得到的图像与期望图像对应像素间的欧式距离.通过均方误差训练得到的模型,其生成的图像在细节上更接近真实图像.目前,均方误差被广泛运用在超分辨率图像重构模型的训练中.均方误差损失函数表达式(3)如下:
(3)
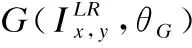
3.3.2 对抗损失
基于生成对抗网络相互对抗的机制,本文将加入了倒置残差块的网络作为生成器,使用具有稠密连接块的判别器网络在无监督学习下通过约束对抗损失迫使生成器获得更加清晰、逼真的高分辨率图像.对抗损失表达式(4)如下:
(4)
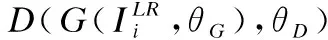
3.3.3 判别器损失
本文在判别器损失部分借鉴了生成器损失中基于像素的均方误差损失Lmse方法,所不同的是,在判别器部分所比较的对象是重构图像和原高清图像经过了4个稠密连接块计算后所得的特征图,判别器损失函数表达式(5)如下:
(5)
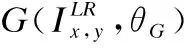
4 实验与结果分析
本文使用FEI(FEI Face Database)公共人脸数据集对本文算法进行实验验证,同时为提高验证结果的准确性以及可信度,本文额外加入了低复杂度单图像超分辨率数据集Set5和Set14进行测试.其中FEI数据集中全为彩色人脸图像,并且都在白色的均质背景下以直立的正面位置拍摄,轮廓旋转最多约180度,每个图像的原始尺寸为640×480像素.将样本送入生成器之前,先使用双三次插值下采样获得低分辨率图像,其中本文下采样因子为4,得到的低分辨率图像尺寸为160×120像素;而Set5,Set14 数据集是基于非负邻域嵌入的低复杂度单图像超分辨率的数据集,该数据集由法国贝尔实验室发布.
4.1 参数设置与训练损失分析
本文实验均在Window10操作系统上进行,使用的仿真软件为Anaconda下基于Python语言的PyCharm解释器,深度学习框架为PyTorch,计算机CPU为Intel Core i7-7700K,GPU使用的是NVIDIA RTX 2080Ti.本文网络总共训练800个周期,采用RMSProp算法优化器,本实验受GPU容量限制,训练时每一批次的图片数量为32张,权重衰减为0.0001,初始学习率为0.001,每经过200个周期,学习率下降90%有助于算法收敛,更容易接近最优解.具体训练过程如图6所示.
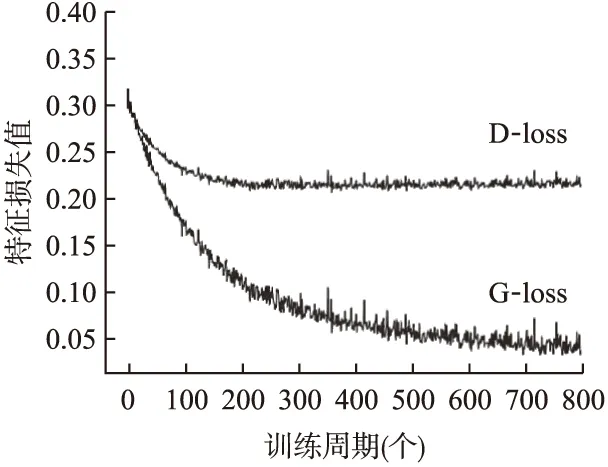
图6 训练损失变化曲线图Fig.6 Training loss curve
如图6所示,G_loss代表生成器损失,D_loss代表判别器损失,横轴代表本次实验总共训练周期,纵轴代表训练过程中生成器和判别器的特征损失值.由图6可知,判别器在大约第200个周期时开始准备收敛,到大约第350个周期基本已经收敛;生成器开始收敛时间相对较晚,大约在第600个周期开始收敛,直到大约第750个周期才完全收敛,这其中的原因是生成器损失有两部分构成,在反向传播时计算量更大相对更加耗时一些,而判别器损失本身只有一个损失函数组成,并且稠密连接块的参数量也比较少,所以更加容易收敛.同时如图6所示,生成器和判别器的损失曲线不够圆滑,带有些小幅波动,这主要的原因是训练时每一批次图片数量不够多,如果每批次的图片数量增加,曲线的波动会减小很多.
4.2 测试与对比
为验证本文提出的算法在超分辨率图像重构上的性能,实验通过FEI人脸数据集和Set5,Set14 非人脸数据集进行测试,采用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似性(Structural SIMilarity,SSIM)作为图像质量客观评估主要指标,PSNR和SSIM数值越高,表明重构图像质量越好.为保证对比结果的公平性,所有算法均在放大因子等于4的比例下进行对比测试.
测试主要包含以下三部分:
1)测试对比生成器部分使用普通标准卷积和深度可分离卷积之间的性能差异,测试对比判别器部分使用DenseNet的稠密连接块、ResNet的残差块和InceptionV3[17]的Inception块之间的性能差异;
2)测试对比本文算法与三双次插值(Bicubic)、SRCNN、SRGAN、ESRGAN[18](Enhanced Super-Resolution Generative Adversarial Networks)等先进算法在重构图像质量、重构速度和模型体积等上的差异;
3)测试对比加入了本文方法的人脸识别算法 SphereFace[19]、CosFace[20]和ArcFace[21]与未加入本文方法的上述人脸识别算法,在识别准确率上的差异.
4.2.1 对比实验1
本部分实验将对本文所使用的深度可分离卷积和稠密连接块,与其他深度学习经典的模块进行对比.为保证对比结果的准确性,当实验在生成器部分对比时,判别器部分均使用稠密连接块;当实验在判别器部分对比时,生成器部分均使用深度可分离卷积.同时本文中的参数数量均指生成器网络参数数量,因为判别器只在网络训练时使用,实际测试并不参与.本部分实验在FEI数据集上进行,具体各部分对比情况如表1所示.

表1 各模块在FEI数据集测试结果对比Table 1 Comparison of test results of each module in FEI dataset
如表1所示,使用了深度可分离卷积和稠密连接块的网络,与使用其他深度学习经典模块的网络相比,重构出的图像在客观评估指标PSNR和SSIM上均有不同程度的提高,并且生成器参数数量相比使用标准卷积也有近乎8倍的减少,这充分说明本文使用低计算量、高性能的深度可分离卷积和低参数量、高频率复用特征的稠密连接块作为网络关键部分,可以起到降参数量、提高重构图像质量的作用.
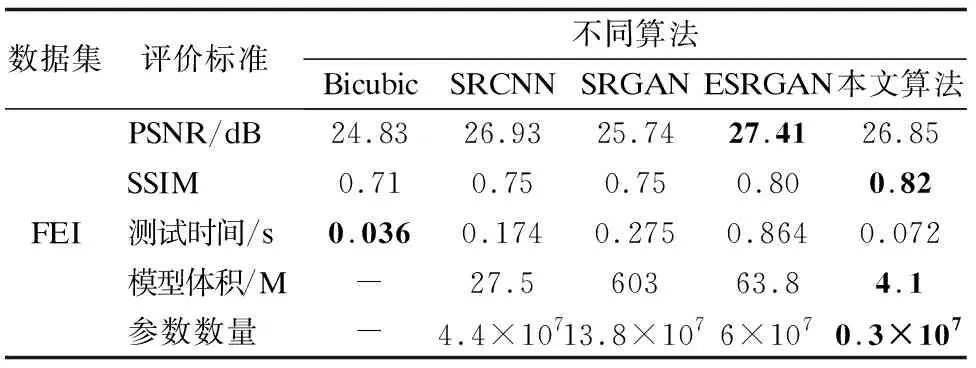
表2 不同算法在FEI数据集测试结果对比Table 2 Comparison of test results of different algorithms in FEI dataset
4.2.2 对比实验2
本部分实验对本文提出的算法与Bicubic、SRCNN、SRGAN、ESRGAN进行对比,这其中包括传统的插值方法,基于卷积神经网络的方法以及基于生成对抗神经网络的方法.
由表2可知,在SSIM的测试中,本文算法在FEI人脸数据集上获得了更高的得分,说明本文算法在图像结构恢复上效果更好;而在PSNR的测试上本文算法并没有显现出优势,说明通过本文算法生成的图像相比其他算法得到的图像,缺少了更多的高频信息,使图像出现了相对平滑的纹理;在测试时间方面,Bicubic算法对低分辨率图像进行图像重构的速度是最快的,因为Bicubic算法只是进行简单的插值操作,并没有额外的计算量,而SRCNN、SRGAN、ESRGAN等算法中包含较多的卷积层,使得模型在处理过程中需要进行大量的运算,本文算法虽然没有Bicubic算法快,但相比其他算法的测试时间减少了许多,基本不影响实时人脸识别算法的运行速度;在模型体积方面,本算法形成的模型体积较SRCNN、SRGAN和ESRGAN都有不同程度的减小,同时本文算法的参数数量较上述几种先进算法减少了1到2个数量级,从而真正达到了轻量化.由于使用了分步式的计算方法,深度可分离卷积可以在保持原有效果的基础上大大减少模型参数数量和计算量.
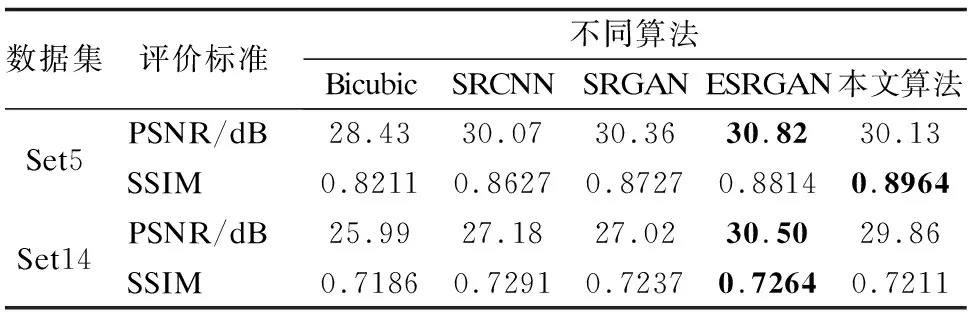
表3 不同算法在Set5,Set14数据集测试结果对比Table 3 Comparison of test results of different algorithms in Set5 and Set14 datasets
由表3可知,本文算法在非人脸数据集Set5,Set14上并没有大幅超越先进算法ESRGAN,只是在Set5上SSIM得分上略微高出一点,这其中一个原因是本文算法是基于人脸图像进行训练的,在非人脸数据集上测试难免不能发挥更多优势,但本文算跟先进算法ESRGAN差距不大,同时较SRCNN、SRGAN在PSNR和SSIM上都有不同程度的提高,这说明本文模型的泛化性较好.

图7 各算法实验效果图对比Fig.7 Comparison of experimental results of each algorithm
使用Bicubic、SRCNN、SRGAN、ESRGAN和本文算法在FEI数据集上进行超分辨率图像重构测试,各算法效果图如图7所示.
4.2.3 对比实验3
为验证加入了本文方法后的人脸识别算法在识别准确率上的表现,实验将加入了本文方法的SphereFace[19]、CosFace[20]和ArcFace[21]先进人脸识别算法与原生上述算法进行对比,整个实验在公共人脸数据集FEI上进行,具体对比如表4所示.
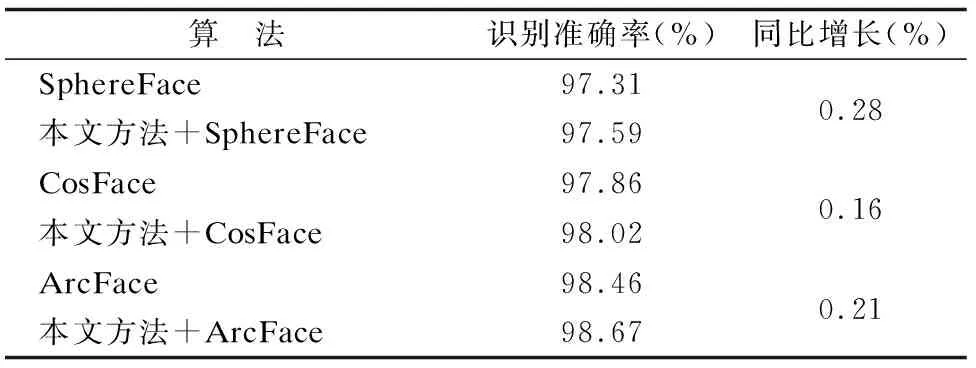
表4 不同人脸识别算法识别准确率对比Table 4 Comparison of recognition accuracy of different face recognition algorithms
由表4可知,加入了本文方法后的人脸识别算法在识别准确率上均有提升.因为通过超分辨率重构后的人脸图像去除了更多影响识别的噪声,使得特征提取算法提取出更加精确的人脸特征,从而提高识别准确率.但是由表4中同比增长部分可知,加入了本文方法后的人脸识别算法并没有出现识别准确率大幅增长的现象,说明本文方法只能对人脸识别的性能进行小范围的提高,并且由表2测试时间部分可知,本文方法重构图像的时间非常短,基本不影响原有算法图像处理时间.所以本文方法可以作为人脸识别中额外的图像预处理模块,对最终的识别准确率起到小幅增长的作用.
5 结 论
本文提出一种轻量化的生成对抗网络超分辨率图像重构算法,通过将含有低计算量、高性能的深度可分离卷积作为生成器网络主体卷积,将低参数量、高频率复用特征的稠密连接块作为判别器网络核心,并结合亚像素卷积进行上采样,大幅削减了不必要的计算量,使得在人脸识别算法中加入图像重构预处理过程所造成的严重延时等问题得以解决.实验结果表明,相较于现有几种流行算法,本文算法虽然在PSNR和SSIM上优势不明显,但是在单幅图像重建的速度上,明显更加迅速,快速的图像重建保证了在实时人脸识别中极低的延时.并且由于本文的模型较小,还可以植入到一些移动设备或者内存较小的机器上运行,具有更加广阔的应用价值.下一步工作,将考虑解决加入了超分辨率图像重构模块后,人脸识别算法的准确率提升不明显问题.
猜你喜欢
红外技术(2022年11期)2022-11-25 08:12:22
电子产品世界(2022年9期)2022-05-30 20:41:07
作文中学版(2022年1期)2022-04-14 08:00:34
学生天地(2020年31期)2020-06-01 02:32:06
数学物理学报(2019年3期)2019-07-23 01:15:40
家庭影院技术(2018年9期)2018-11-02 05:31:32
艺术科技(2018年2期)2018-07-23 06:35:17
自动化学报(2017年5期)2017-05-14 06:20:52
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
计算机工程(2015年8期)2015-07-03 12:19:07
