
基于SVR的燃煤机组NOX含量的软测量模型
2020-09-02 09:36:30李雅晶辛妍丽
计算机测量与控制 2020年8期
李雅晶,辛妍丽
(华南理工大学 电力学院,广州 510640)
0 引言
煤炭燃烧是造成我国大气污染的主要原因,也是出现雾霾天气的主要原因[1],影响人体健康[2]。燃煤电厂是我国煤炭主要消耗源[3],因此对燃煤电厂进行除尘、脱硫、脱硝等控污方法很重要。火电厂脱硝主要用选择性催化还原(SCR)方式,即在催化剂催化下,用氨或其他还原剂将氮氧化物(NOX)还原为氮气和水。现场存在着因NOX测量不准确而导致还原剂用量不正确,造成脱硝不完全或还原剂浪费。需要的喷氨量根据反应器入口NOX含量与反应器出口NOX含量差值计算出,因此喷氨量大小需要及时并准确地测量。但是常规分析仪测量的NOX需要40~60 s的时间,并不能满足电厂脱硝的要求[4]。为解决上述问题,可以通过寻找测量量之间的相关关系,采用间接测量的方法,建立NOX排放量的预测模型。此方法为软测量技术的应用。
Brosillow在1978年首次提出了由估计器和控制器组成的推断控制思想[5]。而软测量技术就源于推断估计器[6]:即通过分析变量间数学关系来建立目标函数值的预测模型,实现对目标函数值的准确预测,进而有效控制系统。近些年随着软测量技术的迅速发展,在工业领域的应用逐渐广泛。软测量问题的解决过程主要分为3个步骤[7]:采集及处理数据、选取辅助变量、建立和校正模型。软测量建模是软测量的重要步骤,近几年主要的建模方法有机理建模[8-10]、回归分析建模[11]、状态分析建模[12]、神经网络建模[13-15]、支持向量机建模[16-17]等。
本文以火电厂燃煤锅炉NOX含量作为研究对象,建立了基于回归支持向量机(SVR)的软测量模型。不使用硬件检测,预测NOX排放浓度。首先通过对SCR反应器生成NOX的过程机理分析,并结合相关性分析、主成分分析等数据处理方法选取辅助变量,然后基于SVR算法建立软测量模型,最后通过电厂锅炉不同工况下的运行数据建模测试,运用BP神经网络对模型效果进行对比检验。
1 辅助变量的选择
1.1 机理分析
本模型的主导变量为脱硝SCR反应器入口的NOX含量,要确定影响此主导变量的辅助变量,首先分析电厂锅炉NOX生成过程的影响因素:
1) 燃料特性:燃料中氮的存在形式不同,NOX生成量也相应变化;煤挥发成分中的各种元素比也是一个重要影响因素。
2) 过量空气系数:当空气分级时,可降低NOX排放量,随着一次风量减少,二次风量增加,氮被氧化的速度降低,NOX排放量也随之下降。
3) 燃烧温度:炉内燃烧温度越高,NOX排放量越大。
4) 一次风率:为了有效控制NOX的含量,减弱NOX生成环境,二次风送入点上部应维持富氧区,下部应维持富燃料区。
5) 负荷率:负荷率越大,给煤量越大,燃烧室及尾部受热面处的烟温也相应提高,挥发分氮生成的NOX相应增加[18]。
6) 风煤比:即总风量与总煤量的比值,反映了送粉的效率。
7) A、B、C、D、E、F 磨的单台磨风煤比:即给煤机的瞬时流量和磨煤机的入口一次风流量,反映了单台磨的给煤效率。
8) 燃尽风门开度与所有风门开度总和比值:反映了空气在炉膛内的流动情况。
结合电厂现场的实际测量数据,挑选出相关变量作为备选的辅助变量。
1.2 数据的采集和处理
本文所用数据均采自某火电厂现场运行7日的数据。由于数据在火电厂分布式控制系统(DSC)中已经进行了滤波处理,因此在建模前不需要对其进行滤波。接下来,对数据进行标准化,在建模过程中,避免因数据大小对样本造成的影响,用以下公式对其进行标准化处理:
(1)
其中:
(2)
(3)

1.3 相关分析
首先对备选的辅助变量原始变量和主导变量进行相关分析。相关系数公式如下:
(4)
式中,x是备选辅助变量的测量值,y是该辅助变量对应的主导变量,即NOx含量的值。Cov(x,y)是两者的协方差。D(x),D(y)分别是两者的方差。
选取相关系数大于0.4的变量作为原始辅助变量,结果如表1所示。
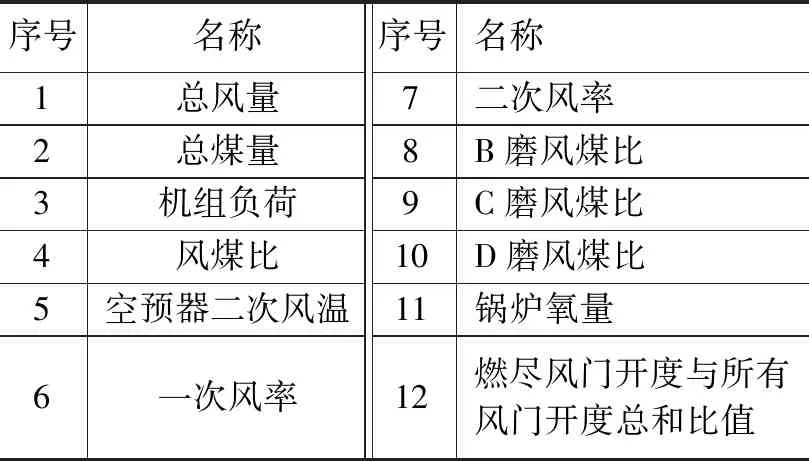
表1 原始辅助变量
由表1可看出,NOX的生成影响因素复杂,影响主导变量的原始辅助变量较多。
1.4 主成分分析
由于表1中筛选出的12个原始辅助变量之间的相关性很强,而且变量的个数较多。如果直接采用这些原始辅助变量作为软测量模型的辅助变量,不但会增加训练的成本,而且会造成信息的重叠,影响预测结果的客观性。为了将上述的相关性很高的变量转化成彼此互相独立或不相关的变量,并且减少变量个数降低训练成本,考虑对原始辅助变量进行主成分分析。
通过Matlab软件对12个原始辅助变量进行主成分分析,分析其相关系数矩阵,前几个特征根及其贡献率见表2。
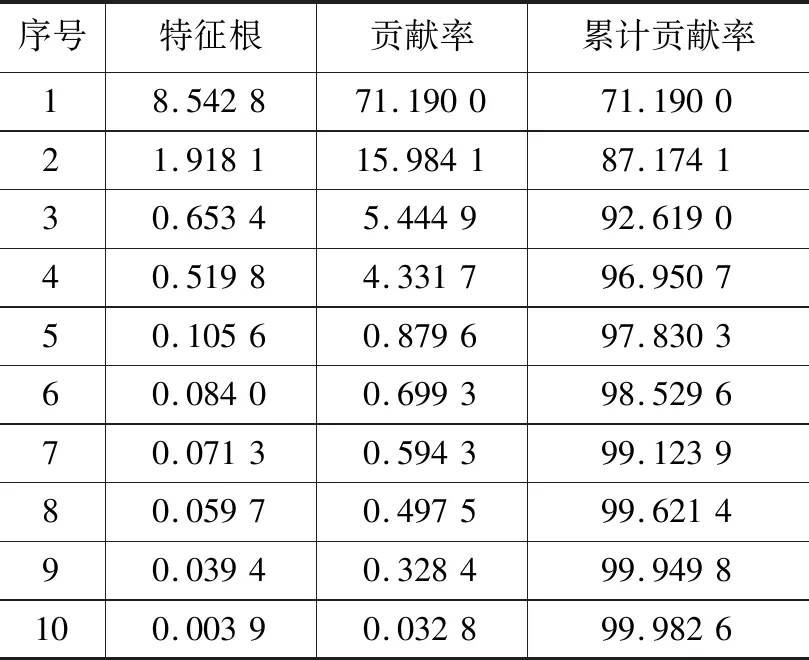
表2 原始辅助变量主成分分析结果
从表2可以看出,前3个特征根的累积贡献率超过90%,主成分分析的效果明显。前6个主成分的主成分达到98%以上,因此选取前6个主成分作为本文软测量模型的辅助变量。
1.5 辅助变量的确定
为具体说明选取的6个辅助变量与原始辅助变量的关系,表3列出了标准化变量的前6个特征根对应的特征向量。其中,x1,x2,...,x12表示表1中的12个原始变量标准化后的数值,p1,p2,...,p6表示选取的辅助变量,即前6个主成分。
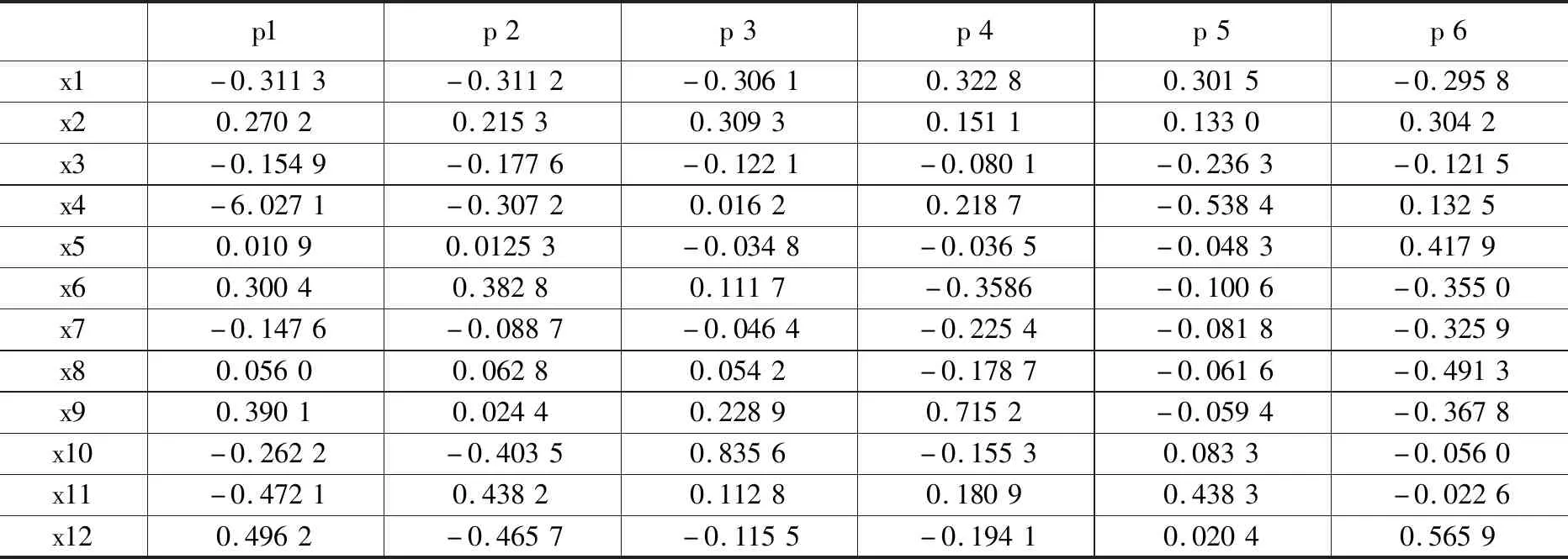
表3 前6个主成分(辅助变量)对应的特征向量
每个选取作为辅助变量的主成分pi是12个原始的辅助变量xj的线性组合,具体系数为对应的特征向量,如表3所示。可以看出,第1主成分主要反映了总风量、总煤量、燃尽风门开度与所有风门开度总和的比值和锅炉氧量,第2主成分主要反映了风煤比和燃净风门开度与所有风门开度总和的比值以及锅炉氧量,第3主成分主要反映了D磨风煤比,第4主成分主要反映了C磨风煤比,第5主成分主要反映了空预器二次风温、B磨风煤比以及一次风率和二次风率,第6主成分主要反映了机组负荷、风煤比、燃净风门开度与所有风门开度总和的比值以及锅炉氧量。
由此可得,选取的前6个主成分作为软测量模型的辅助变量,既全面的反映了原始的12个辅助变量,又消除了原始变量之间的相关性,而且减少了变量的个数节约了训练的成本。因此,本文NOX软测量模型辅助变量的选择恰当。
2 回归型支持向量机(SVR)的原理
SVR是在支持向量机分类的基础上,引入ε线性不敏感损失函数,其基本思想是寻找一个最优分面,使所有训练样本离这个分类面的误差最小。如图1所示。
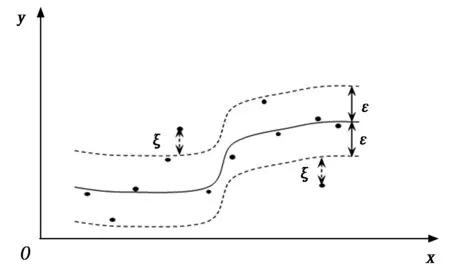
图1 回归型支持向量机(SVR)基本思想
通过非线性映射函数φ(·)将训练集样本{(xi,yi),i=1,2,…,l}的输入列向量x映射到高维特征空间Rd,建立SVR的线性回归函数:
f(x)=ωφ(x)+b
(5)
其中:ω为法向量,b是位移项,f(x)即为回归函数返回的预测值。
定义ε线性不敏感损失函数L(f(x),y,ε),如图2所示。表示如果预测值f(x)与真实值y的差不大于ε,则损失为0。

图2 ε线性不敏感损失函数
寻找最优的分类面转化为寻找最优的ω和b,引入松弛变量ξi、ξi*,可把优化的目标函数具体表示为:
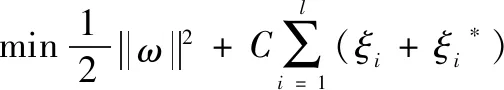
(6)
其中:C是惩罚因子,表示训练误差超过误差要求ε的惩罚系数;ω2是置信区间,与模型的复杂度有关;l是训练样本个数。
可引入拉格朗日函数并转化为对偶形式求解,最终得到最优的线性回归函数即为SVR预测函数:
因此,得到的回归函数即软测量模型为:
(7)
式中,只有部分参数(αi-αi*)不等于零,其对应的样本xi即为本模型中的支持向量。其中核函数K(xi,xj)=φ(xi)φ(xj)应满足Mercer条件,核函数不同,构造的支持向量机不同。常用核函数有多项式核函数、RBF核函数、线性核函数、Sigmoid核函数。
此外,由式(7)可以看出,SVR最终的函数形式的结构如图3所示。
在图3中,每个支持向量对应一个中间节点,中间节点的线性组合即为输出。

图3 回归型支持向量机(SVR)的结构
3 基于SVR的软测量模型
3.1 产生训练集/测试集
SCR反应器入口NOX含量的训练数据来源是火电厂现场DCS采集到每秒的数据,共201 600组。为减少软测量模型的训练成本和时间,以20 s为长度等间隔取值,构成10 080个新数组,使数据的变化更明显。然后对标准化后原始的辅助变量进行主成分分析,取前六个主成分作为最终的辅助变量,为不失一般性,选取前6 500组数据作为样本产生训练集,剩余的3 580组数据作为产生测试集的样本,来对模型的测试集进行评价。
3.2 构建/训练SVR模型
首先对于作为辅助变量的前6个主成分数据集,进行再次归一化。不同的核函数和模型参数对SVR模型的性能影响很大。因此,合适的核函数及参数组合的选择在SVR模型建立中极为重要。本模型需要选取的参数有两个,分别是惩罚因子C和RBF核函数中的方差g。惩罚因子C和RBF核函数中的方差g的取值对SVR软测量模型的性能有着重要影响,惩罚因子C用来控制样本偏差和机器泛化能力之间的关系,RBF核函数中的方差g太大或太小会造成对样本数据的过学习或欠学习。
对于核函数的选择,本文采用RBF核函数。对于选择最优的参数g(即RBF核函数中的方差),和参数C(即惩罚因子),本文采用交叉验证的方法。特别说明的是,因为惩罚因子参数C越大,最终得到的支持向量越多,计算量也就随之增大。因此,当模型的性能相同时,为了节约运算时间,优先选择惩罚因子参数C较小的参数组合。
3.3 仿真测试
本文选取的工具是Matlab中libsvm软件包,对SVR进行仿真测试,得到测试集和训练集的预测值,并且计算测试集的均方误差E和决定系数R2,具体计算的公式如式(8)、(9)所示:
(8)
(9)
式中,l是测试集的样本个数,yi表示第i个样本预测值,yi*表示第i个样本真实值
均方误差E表示测量的精密度,E越接近零测量的精度越高;决定系数R2表示模型的泛化能力,R2越接近1,表明模型对样本的依赖性越低,泛化能力越强。
此外,还要特别说明的是,在仿真测试时,对于直接得到的训练集和样本集的预测值,即主导变量NOX的预测量,因为之前对数据已经做过了归一化处理,所以这里最后的预测结果还要进行反归一化处理。
4 模型验证与检验
4.1 软测量模型的求解
因为随机产生训练集和测试集,所以每次运行的结果会略有差异。由于SVR算法最终转化为一个二次规划问题,理论上可以避免陷入局部最优,得到全局最优解。因此,每次运行的结果虽略有不同,但结果基本稳定。某一次运行的训练集、测试集结果分别如图4~图5所示。

图4 SVR模型训练集结果对比

图5 SVR模型测试集结果对比
训练集均方误差的计算结果是0.009 75,结合图4可知,训练过程中的精密度很高;训练集决定系数的计算结果是0.889 56,表明训练的结果对训练样本的依赖性很小,泛化能力很好。
测试集预测值和真实值具体对比结果如图5所示,测试集的均方误差是0.013 40,表示该软测量预测模型的精密度高;训练集的决定系数是0.857 95,表明模型的预测的结果对样本的依赖性很小,该模型的泛化能力理想。
4.2 与BP神经网络模型的性能对比
软测量模型的建模方法中,神经网络也是做回归拟合预测问题的选择之一,下面用BP神经网络的建模方法对该SVR软测量模型结果进行检验,并进行两种方法的性能对比。
建立的BP神经网络模型对测试集预测的结果如图6所示,与4.1节对应的结果为同一次运行所得。
经计算本次BP神经网络模型运行的均方根误差为0.025 72,结合图6可以看出精度较高,说明此次的运行结果没有陷入局部最优,结果有效。
对比图6和图5发现,SVR的均方根误差小于BP神经网络,说明在NOX软测量的问题中SVR的精度较高;SVR的决定系数大于BP神经网络的0.816 81,说明对于此问题,SVR的泛化能力优于BP神经网络。

图6 BP神经网络测试集结果对比
4.3 不同核函数对模型性能的影响
从SVR的原理可知,不同核函数性能对软测量模型性能的影响不同。本文之前的工作中,选取的是RBF核函数,为了检验核函数选择的准确性,这里用某次随机产生的测试机和训练集进行对比试验,具体结果如表4所示。

表4 不同核函数对软测量模型的性能影响
如表4所示,RBF核函数对应的模型泛化能力最好,和Sigmoid及线性核函数相比,虽然多项式对应的模型训练性能较好,但泛化能力较差。因此,本文选取的RBF核函数较为合适。
5 结束语
本文利用相关分析、机理分析和主成分分析选出影响电站锅炉NOX含量的辅助变量,使得辅助变量的选取更加具有统计意义。由于现场检测NOX含量分析仪具有一定的延时特性,在数据处理时增加时序变换,使建立的模型更加符合实际情况。仿真结果显示利用回归型支持向量机(SVR)建立的预测模型具有很好的精度和泛化能力。本文提出的软测量模型能够及时反映并预测NOX含量,为解决火电厂SCR反应器入口NOX含量难以实时在线测量的问题提供了参考,而且可以拓展应用到火电厂烟气含氧量、锅炉炉膛温度、排放烟气含湿量等问题,甚至可以应用到工业上,尤其是小样本数据的,很多难以实时在线测量数据的问题。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
河北理科教学研究(2021年3期)2022-01-18 05:34:24
发明与创新(2021年39期)2021-11-05 07:15:28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
电子制作(2018年17期)2018-09-28 01:56:44
通信电源技术(2018年5期)2018-08-23 01:15:36
材料科学与工程学报(2016年1期)2017-01-15 13:33:48
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
