
基于共性假设的零样本生成模型
2020-09-02 02:27:38许世斌高子淑
计算机应用与软件 2020年8期
许世斌 高子淑
1(西安电子科技大学计算机科学与技术学院 陕西 西安 710071)2(北京化工大学信息科学与技术学院 北京 100029)
0 引 言
传统的分类模型只能识别与训练样本相同类别的数据,而无法识别无训练样本的数据。在分类任务的实际应用场景中,往往会遇到缺乏训练样本以及样本标签丢失等传统分类模型无法处理的问题。人类能够将经验与事物的形状、色彩的语言描述相结合,轻易地识别出从未见过的事物,受此启发,零样本学习(Zero Shot Learning,ZSL)通过学习数据在可见类别上的分布,结合未见类别的辅助语义信息以识别未见类别数据,为部分类别缺乏图像数据的分类问题提供了解决方案。
零样本学习在训练阶段仅使用可见类别样本与未见类别的文本描述进行训练,而测试阶段则仅对未见类别的测试数据进行分类。在实际应用中,未见类的数据通常需要与可见类的数据共同进行分类,即在零样本学习的训练阶段对可见类别与未见类别测试数据的并集进行分类,这样的分类任务被称为泛零样本学习(Generalized Zero Shot Learning,GZSL)任务。
目前主流零样本学习方法通常将从可见类样本中学习到的视觉语义映射关系迁移到未见类上,将分类数据的语义特征与视觉特征投影到一个公共空间上进行处理。Lampert等[1]提出了以属性向量作为零样本学习的辅助语义信息,通过最大后验概率法,基于图像视觉特征数据对未见类的形状、颜色等各项属性进行预测,将视觉特征转义为语义特征,使用支持向量机对所预测的属性特征进行分类。由于辅助语义信息中存在一词多义、多词同义等情况,容易引发枢纽点问题。为解决这一问题,Zhang等[2]提出使用将语义特征映射为视觉特征进行零样本分类的方法,并提出多模态学习机制,基于多种语义特征学习视觉语义映射关系。Kodirov等[3]提出基于语义自编码(Semantic Autor Encoder)的零样本学习方法,为视觉语义映射关系增加重构性约束,增加具体语义信息约束,实现有监督下的映射关系学习。吴凡等[5]提出了一种基于权重衰减的端到端的零样本学习框架,通过权重衰减约束限制模型在强关联属性的大小。Elhoseiny等[5]提出使用更贴近实际应用的含噪文本描述作为语义特征,进行零样本学习的方法。
基于语义关系映射的零样本学习方法在零样本学习任务上取得了良好的表现,然而,这类方法存在可见类真实数据与基于语义关系映射得到的未见类数据数量不平衡的问题在泛零样本学习任务中的表现不尽理想。近年来,随着生成对抗网络(generative Adversarial Networks,GAN)的发展,基于生成模型的零样本学习方法逐渐兴起。Xian等[6]使用对抗生成网络基于语义特征与高斯噪声生成未见类的视觉特征进行分类,使零样本学习问题转化为监督分类问题。Zhu等[7]提出了可见类视轴中心约束方法,提高了基于生成对抗网络的零样本学习算法的分类精度。
基于对抗生成网络的方法为零样本学习提供了新的思路,然而,对抗生成网络存在模型训练难度大、生成数据可分性与稳定性较差等问题。为了克服这些问题,本文提出了一种基于共性假设的生成模型(Common Hypothesis-Based Generative Model,CHBGM)。针对对抗生成网络训练难度较大的问题,提出了一种基于条件变分自编码器的零样本生成模型;针对生成模型生成数据的可分性与稳定性较差的问题,提出了未见类别与可见类别的数据分布可分但具有一定的相似性的假设,并提出一种共性正则项,在生成模型的训练阶段进行约束。在主流零样本学习数据集的零样本学习与泛化零样本学习任务上进行实验,验证了本文方法的有效性。
1 模型设计
1.1 问题定义
在零样本学习任务中,训练阶段使用可见类数据集合S={(x,y,cs)|x∈Xs,y∈Y,cs∈Cs}作为训练集,其中:x为基于深度卷积神经网络所提取的图像视觉特征;y为可见类图像的辅助语义信息;cs为x与y对应的类别。在训练阶段,未见类辅助语义信息集U={(u,cu)|u∈U,cu∈Cu}对模型可见,其中:u为未见类的辅助语义信息;cu为u对应的类别;Cu∩Cs=Ø。
用Xu表示未见类的视觉特征集合,则零样本学习任务的目标是训练一个分类器fzsl:Xu→Yu;泛零样本学习任务的目标是训练一个分类器fgzsl:Xu∩Xs→Yu∪Ys。
1.2 条件变分自编码器
变分自编码器(Variational Autoencoder,VAE)[8]是一种基于变分贝叶斯估计实现的生成模型,由一个编码器与一个解码器组成。变分自编码器假设生成数据的分布可以由一个规整分布p(z)经过一定的变换得到,p(z)通常取标准高斯分布。在变分自编码器的训练阶段,首先将原始数据通过一个编码器qθ(z|x)编码为隐变量z,再基于编码的隐变量z使用一个解码器pθ(x|z)重构为接近原始数据的新数据。在测试阶段,使用高斯噪声作为隐变量z输入解码器,生成新的数据。变分自编码器的损失函数如下:
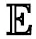
(1)
变分自编码器无法控制生成数据的类别,为了解决这一问题,文献[9]提出了条件变分自编码器(Conditional Variational Autoencoder,CVAE)模型。在条件变分自编码器中引入了条件变量c,以p(x|c)作为变分下界,使模型能够生成具备某些特性的数据。条件变分自编码器的损失函数为:
LCVAE=-KL(qθ(z|x,c)‖p(z|c))+
(2)
本文训练了一个条件变分自编码器作为未见类的生成模型。在模型训练阶段,以可见类视觉特征数据作为自编码器的输入数据,使用所生成类别的辅助语义信息作为条件变量。训练完成后,使用高斯噪声作为条件变分自编码器中解码器的输入数据,以未见类别的辅助语义信息作为条件变量生成未见类的视觉特征,用于进行零样本学习任务或泛零样本学习任务。
1.3 共性假设约束
基于条件变分自编码器可以生成与真实数据分布接近的数据,但是条件变分自编码器在零样本学习任务中生成未见类数据时,由于没有未见类样本且所生成的未见类数据的分布仅依赖于辅助语义信息,容易导致所生成的未见类数据分布与真实数据分布差异较大,从而影响使用生成数据进行零样本学习与泛零样本学习任务的结果。本文假设零样本学习任务中,未见类数据与至少一种可见类的数据分布具有一定的相似性。例如:斑马与马之间具有较强的相似性,若斑马为未见类,马为可见类,则此二类数据分布之间的距离应相对较小。依据该假设,条件变分自编码器所生成的未见类别数据分布至少与一种可见类别数据分布之间具有较小的距离。本文使用欧式距离度量分布之间的距离,并提出了共性约束正则项:
(3)
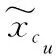
(4)
式中:xcs∈Xcs为可见类别cs中的数据。
为了防止共性约束降低未见类生成数据与可见类真实数据之间的可分性,从而影响模型在泛零样本学习任务中的表现,本文使用了辅助分类正则项对未见类生成数据以及可见类的真实数据进行区分。使用一个fc层与Softmax函数组合,作为分类器,为未见类的生成数据与可见类的真实数据计算辅助分类损失。辅助分类正则项为:
(5)
式中:n为样本类别总数;xi为各类别视觉特征(可见类使用真实视觉特征,未见类使用生成视觉特征);f(xi)为分类器分类结果;ci为xi所对应的数据标签。
最终,共性假设约束损失LR计算如下:
LR=Llike+λLcla
(6)
式中:λ为辅助分类正则项对应的超参数。
1.4 CHBGM
CHBGM整体结构如图1所示。其中,条件变分自编码器由编码器与解码器两部分组成。
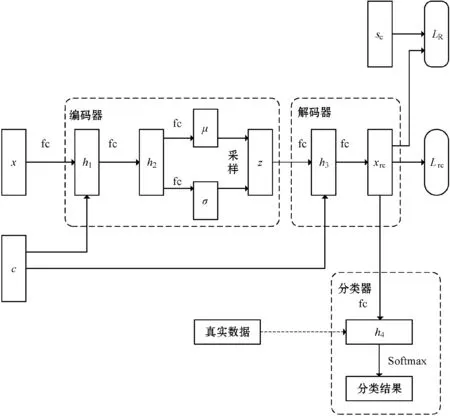
图1 基于共性假设的零样本生成模型CHBGM
模型训练阶段,在编码器中,图像视觉特征数据x与图像辅助语义信息y共同通过两层全连接层后,再分别经过两个不同的全连接层,计算出μ与σ,随后从随机分布N(μ,σ)中采样出与μ和σ同维的隐变量z。在获得由真实数据通过编码器采样的隐变量z后,使用z与y经过解码器中的两层全连接层解码为重构特征xrc,根据式(2)计算条件变分自编码器的损失LCVAE,根据式(6)结合可见类样本的视轴中心sc计算共性约束损失LR,并基于LCVAE与LR对条件变分自编码器模型进行优化。
当生成模型训练完成后,使用高斯噪声作为解码器的输入,结合辅助语义信息y生成各类别视觉特征数据,并将所生成的视觉特征数据与真实数据一同送入一个分类器中进行训练。
测试阶段,使用训练完成的分类器模型其对测试数据进行验证。本文分类器由一个神经网络隐含层与Softmax函数组成。
2 实验与分析
本文基于Pytorch框架实现了CHBGM,并将可见类视觉特征与该模型生成的未见类视觉特征送入含有一个隐藏层的分类神经网络中进行训练,得到零样本分类模型。本文实验的软硬件环境为:Windows 10(64位),Python 3.7,NVIDIA 2080ti,RAM 8 GB及i7- 9750H。
2.1 数据集配置
对于零样本学习任务与泛零样本学习任务,本文参考文献[10]的规范,选取了AWA2、SUN、CUB三个主流零样本学习数据集作为实验数据集,各数据集的详细参数如表1所示。各数据集的特点是:SUN类别数较多,AWA2单类别图片多,CUB属性个数多。
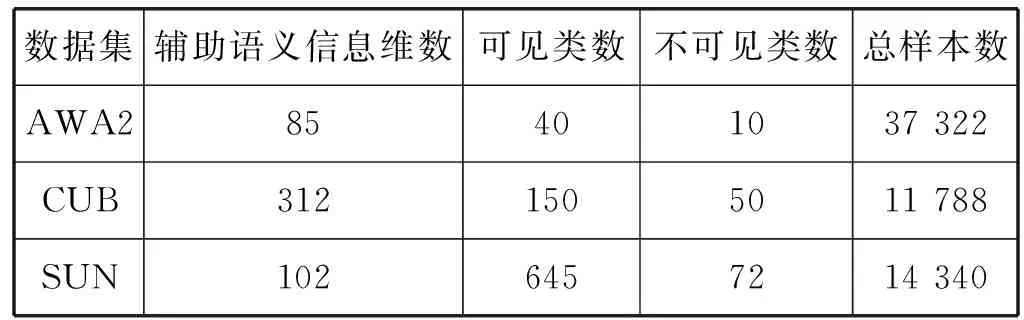
表1 数据集配置表
2.2 实验配置
本文的神经网络学习率取10-3,优化算法使用Adam优化算法[11],训练周期数为200个,每个训练周期中,每次迭代时的批大小为64。实验中,所有数据集的图像都由GoogleNet提取视觉特征,所提取的视觉特征维数均为1 024,数据集中的辅助语义信息均为属性向量[1],超参数λ取值为0.001。
在零样本学习任务中,由于数据集中各类内数据数量不均衡,本文参考文献[10]使用各类识别准确率均值作为评价指标。其定义如下:
(7)

在泛零样本学习任务中,参考文献[10]的规范,对于可见类别数据集,使用80%的数据作为训练数据,20%的数据作为测试数据。对于未见类数据使用本文所提出的生成模型生成数据作为训练数据,以真实数据作为测试数据。在泛零样本学习任务中,使用可见类识别准确率与未见类识别准确率的调和平均数H作为评价指标。
2.3 实验结果
本文模型应用于零样本学习任务的识别准确率均值随迭代次数变化的曲线如图2所示。随着迭代次数的增加,识别准确率均值尽管在小范围内有所波动,但整体上逐渐提升并趋向于稳定,证明了本文模型具有较好的收敛性。
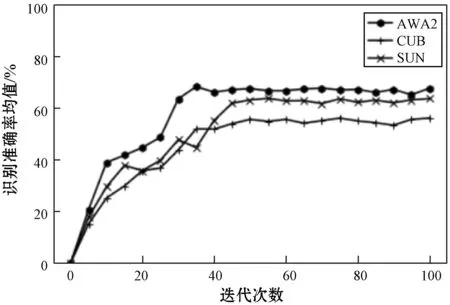
图2 训练过程中零样本学习评价指标的变化
在泛零样本学习任务中,评价指标H随时间变化曲线如图3所示。H随着迭代次数的增加逐渐趋于稳定,证明了该模型在泛零样本学习任务中同在零样本学习任务中一样,具有较好的收敛性。
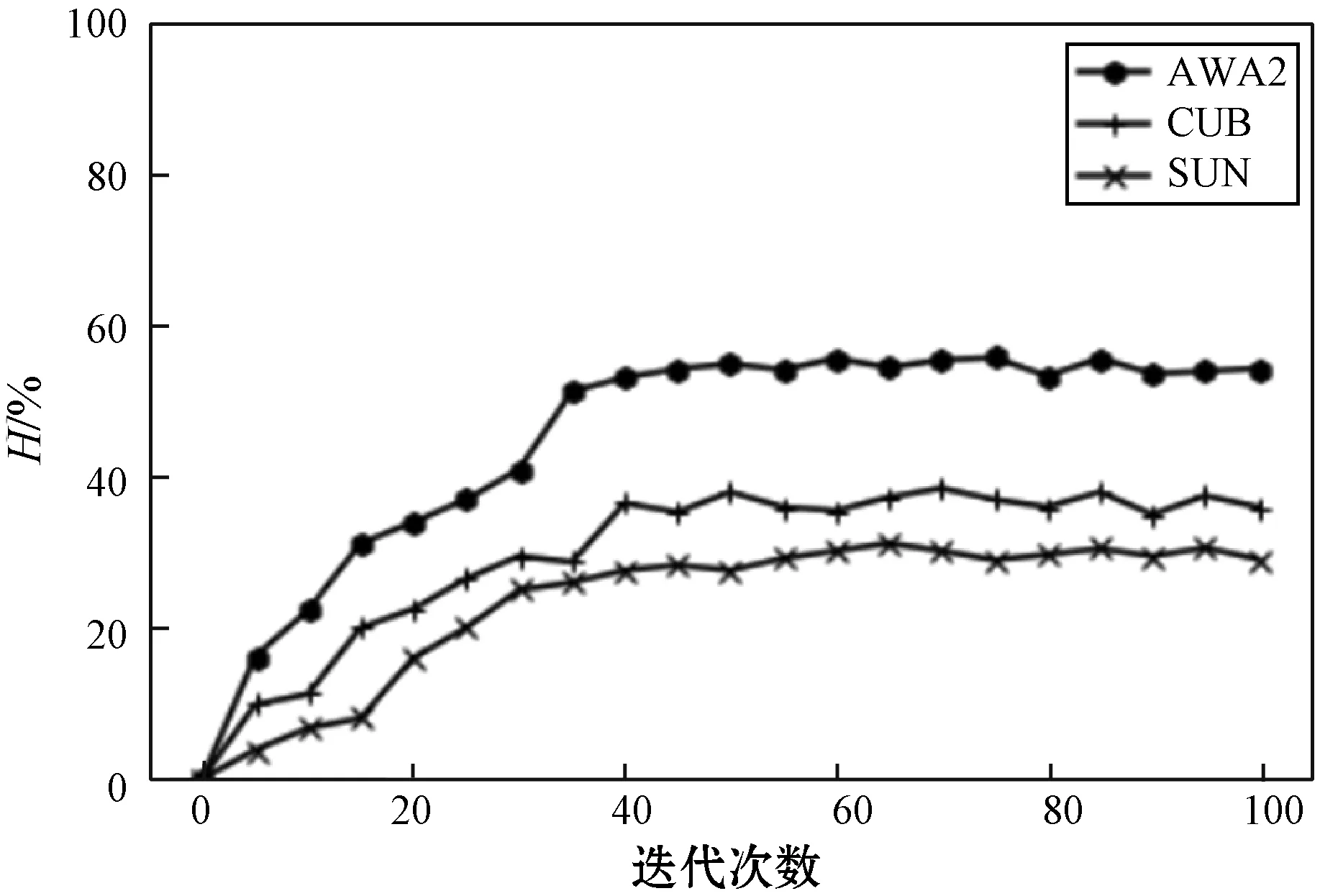
图3 训练过程中泛零样本学习评价指标的变化
将CHBGM模型与表2中所示的六种零样本识别方法进行比较,使用各类准确率均值作为评价指标。为了对比的合理性,本文对GAZSL进行了复现,使用属性向量作为其辅助语义特征。可以看出,本文模型在零样本学习任务上的表现相比于所比较算法更具优势。
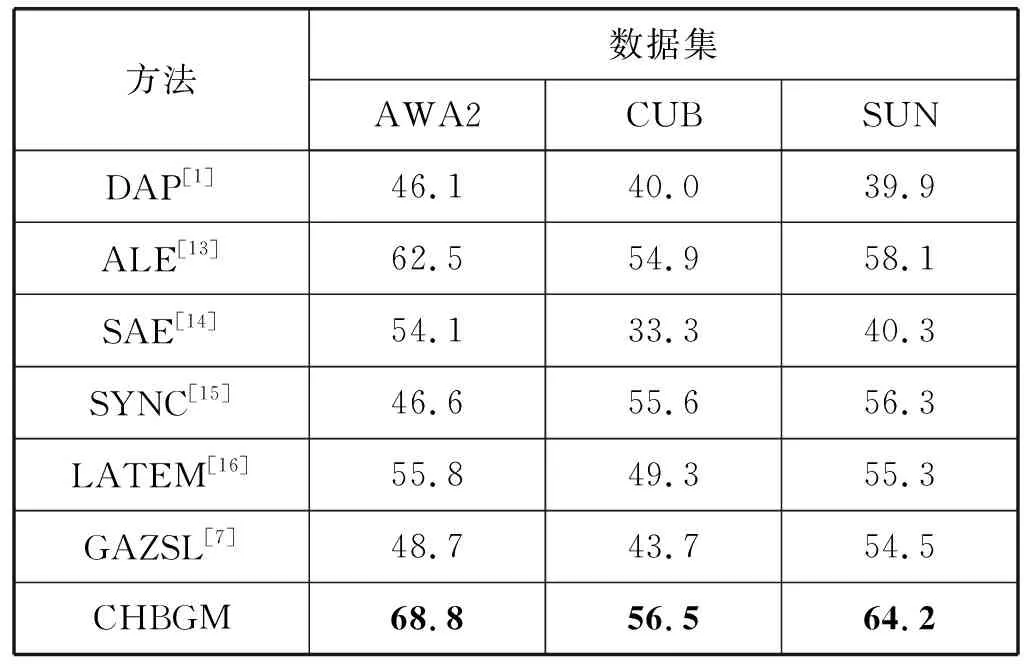
表2 不同方法在各数据集上的零样本学习表现对比
对于泛零样本学习任务,本文使用可见类与未见类识别率的调和平均数H作为衡量指标,对比结果如表3所示。可见,本文模型优于所比较方法。DAP、ALE、SJE等方法是基于视觉语义映射迁移的方法,在泛零样本学习任务中各未见类样本只有一个视觉特征数据,难以实现均衡的分类器训练。GAZSL为基于对抗生成网络的零样本生成模型,该模型仅对模型生成的可见类数据进行约束,而未对未见类数据进行约束,其在零样本学习与泛零样本学习任务上的表现从侧面证明了本文所提出的共性假设约束的有效性。
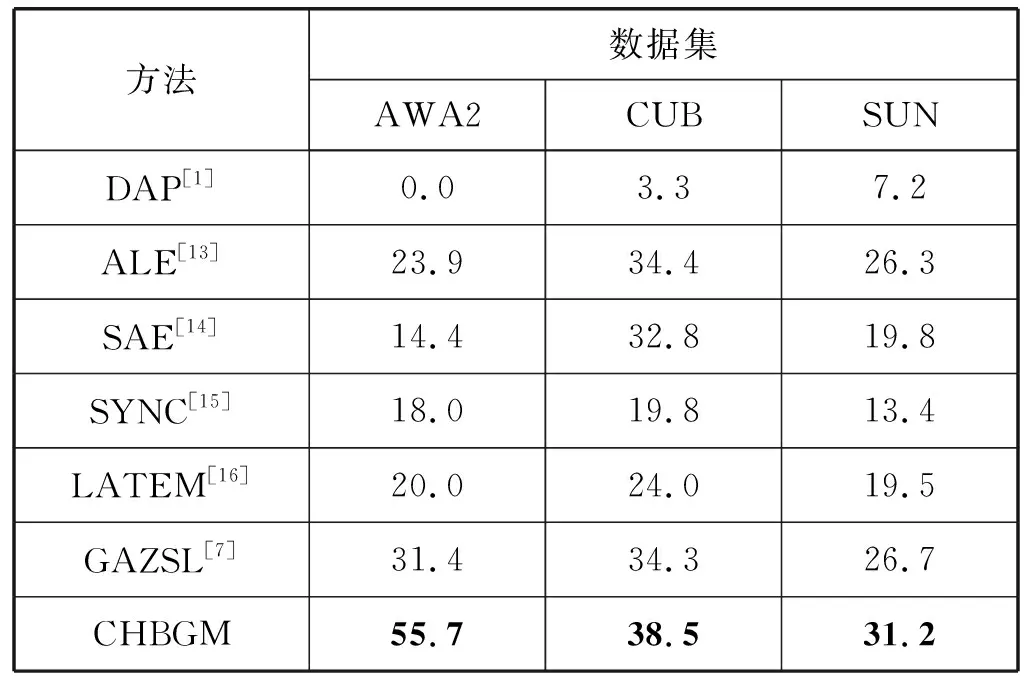
表3 不同方法在各数据集上的泛零样本学习表现对比
尽管本文模型在零样本学习任务中的表现优于对比算法,但在泛零样本学习上的表现并不理想,其原因是泛零样本学习任务中,未见类的数据需要与可见类进行比较,而生成模型通过可见类的视觉特征数据学习生成未见类的特征数据。虽然本文使用了式(5)的分类正则项进行约束,对可见类数据与未见类生成数据进行区分,但是在泛零样本学习任务中,可见类数据与未见类数据依然存在较高的混淆比率,依然有待改进。
3 结 语
本文提出了一种基于变分自编码器的零样本学习方法,使用变分自编码器结合属性向量生成未见类样本以用于分类任务,同时提出了一种共性假设正则项,对生成的未见类样本进行约束。实验证明:本文方法优于对比方法。
本文使用的辅助语义信息为不含噪的属性向量,未来将引入更符合实际应用的含噪文本作为辅助语义信息,并进一步提高识别精度,使零样本学习方法能更好地应用于实际应用当中。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
现代语文(2016年21期)2016-05-25 13:13:44
新校长(2016年8期)2016-01-10 06:43:59
电子器件(2015年5期)2015-12-29 08:42:24
大连民族大学学报(2015年2期)2015-02-27 08:28:11
商事法论集(2014年1期)2014-06-27 01:20:42
电测与仪表(2014年13期)2014-04-04 12:04:18
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
