
多维布隆算法在Redis指纹自动过期中的应用
2020-09-02 01:22贾小云杜晓旭
计算机应用与软件 2020年8期
贾小云 杜晓旭
(陕西科技大学电子信息与人工智能学院 陕西 西安 710021)
0 引 言
如果利用Scrapy-Redis框架进行亿级规模以上的数据爬取,且要满足重复出现的指纹在一段时间内二次遇到不采集、一段时间外二次遇到再采集的话,该框架本身是无法完成的。这不仅是因为框架本身占用空间严重,还因为Redis只能对去重集合设置过期时间,而不能对具体的某一指纹设置。如果对去重集合设置了过期时间,等过期后整个去重队列都会被删除,这显然无法满足我们的需求。因此,解决这些问题成为解决Scrapy-Redis指纹自动过期难题的重点,也是本文研究内容的关键。
1 Scrapy-Redis框架
单机模式的Scrapy框架是目前十分流行的爬虫框架,其融合Redis组件后的Scrapy-Redis框架摆脱了单机的限制,能够快速实现简单分布式爬虫的部署与运行。Scrapy-Redis中有共用的数据库用来存储去重集合与请求队列,并通过对它们的分享帮助分别部署在不同主机上的爬虫程序协调工作。
Scrapy-Redis指纹是指把请求体、请求方式和请求URL通过MD5加密结合在一起,然后再利用32进制转义字符进行转义后生成的字符串。指纹放入Redis数据库中作为请求的唯一标识。
当一个请求在Scrapy中被请求时,它会先在去重器中进行校验,校验过程可以简单概括如下:
Step1针对发起的请求,生成一个请求指纹。
Step2对该指纹是否已在指纹集合中进行判断。
Step3如果已经存在,则舍弃它;如果不存在,则在指纹集合中添加该指纹并在请求队列中添加该请求。
Scrapy-Redis为了实现爬虫的分布式部署,通过连接Redis数据库重写了Scrapy的去重器。该数据库可以存储每个爬虫的每个指纹并将其写入同一个键中,以此实现共享功能。
利用Scrapy-Redis的这种去重机制,只要设置爬虫不主动清空去重集合,就可以实现采集过的信息不再二次采集。而且,通过对Redis设置过期时间也可以在过期时间后重新爬取先前采集过的所有信息。但在解决某采集过的特定信息隔上固定时间后再次进行采集的问题上,Scrapy-Redis的去重机制却无法满足。
这是因为Redis中设置过期时间只是针对去重集合的,而不能针对里面某一具体的指纹。Redis将所有指纹写在同一个键中,当为Redis的键设置过期时间后,一旦键过期,整个库中的去重集合都会被删除,这时所有过期时间前的去重队列都会消失。
除此之外,因为指纹在Redis去重集合中的长度为40位的16进制,而每个16进制占用4 B空间,所以一亿规模的指纹就要占用2 GB的空间。而这并不包括存储请求种子到队列中所占用的空间,也不包括多个爬虫协调工作的情况,所以事实上爬虫中Redis的空间占比会更加严重。
2 算法原理
为了让Scrapy-Redis适应亿级规模爬取,本文使用Bloom算法。目前针对Bloom算法在爬虫上的应用研究很少,但也有一些对简单Bloom算法在Scarapy-Redis的去重效率优化方面的尝试,这对本文研究起到了一定的启发作用。在如何让请求指纹自动过期的问题上,可以通过使用Redis散列表保存指纹到其过期时间的映射,以及多维Bloom算法与Scrapy-Redis的对接两种方法进行实现。
2.1 Bloom算法
在判断元素是否在一个集合内时,链表、树等数据结构都采用将所有元素保存起来之后进行对比的方式,但这种方式会随着集合的扩增占用更多的存储空间和检索速度。哈希函数可以将位数组上的某一位作为某一元素的映射,以便利用位数组上该位置的值来判断该元素是否在判断集合中存在,很大程度上弥补了链表、树等结构的缺陷。Bloom算法便是利用哈希表来判断集合中是否存在某元素的,其过程如下:
声明一个初始条件下每一位都为0且长度大小为m的位数组,其结构如图1所示。

图1 Bloom过滤器位数组的初始设定
现假设有一个集合S,S={x1,x2,…,xn},使用k个相互独立且随机的哈希函数将S集合中每一个元素映射在{1,2,…,m}这一数组范围内。在映射时,位数组中哈希函数的映射值相同的位置会被置1,且在多次映射的情况下只有第一次的置1为有效设定。
举个例子,当k取3的时候,假设元素x1经过3个哈希函数映射的结果分别为1、4、8,而元素x2经过3个哈希函数映射的结果为4、6、10。那么位数组上将被置为1的位置是1、4、8、6、10这五位,位数组相应位置置1后的结构如图2所示。

图2 x1与x2映射后位数组的置1结果
图2中x1和x2成功加入了去重集合S中,此时如果要判断其他元素是否存在于S集合内,同样需要用k个哈希函数求映射结果并判断结果对应的位数组位置是否都已为1,若已都为1,则该元素属于集合S,否则,不属于集合S。现假设两个新元素y1、y2的映射结果如图3所示。

图3 y1和y2的映射结果
由图3可知y1对应位置有0,因此y1不属于S集合,y2对应位置全部为1,应该属于S集合。但这只是原则上的判断结果,事实上,Bloom算法虽然在不属于去重集合的元素的判断上能够保证百分之百的正确率,但对属于该集合的元素的判断却存在一定的误判率。
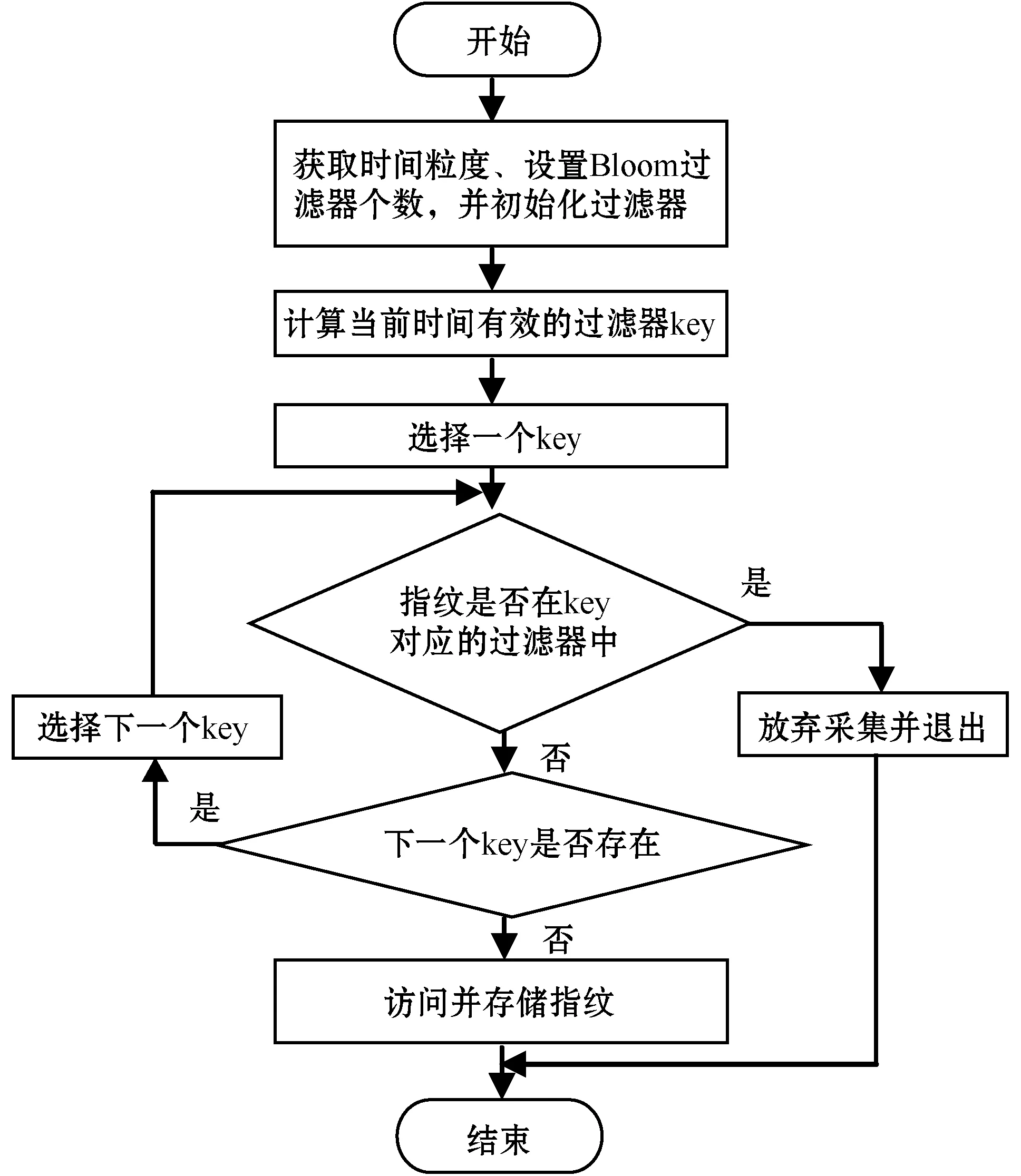
对于Bloom算法的误判率,仍然假设存在k个相互独立且随机的哈希函数,存在已有n个元素的待对比集合以及长度为m的位数组,且k、m和n之间满足kn (1) 式中:1/m为k个哈希函数中有任意一个选中位数组上该位置的概率,显然1-1/m就代表k个哈希函数都未选中这一位置的概率。 该位置在经过k次哈希映射后仍然没有被置为1的概率为: (2) 对于集合S={x1,x2,…,xn},需要做kn次散列运算才能将其所含元素全部映射到位数组中,此时位数组的该位置仍然没有被置为1的概率为: (3) 经过kn次散列运算后,位数组中某一位置成功被置为1的概率则为: (4) 当某元素经k次哈希映射后所得结果对应的位数组内位置全部为1时,会将该元素判定为属于集合S。因此,不在集合中的元素被检测为已存在于该集合的误判概率为: (5) 由式(5)可以看出,在n和m确定的情况下,最小误判率可以通过最优的k获得。而最优哈希函数个数的获取公式如下: (6) 显然,误判率与m/n的值以及k的值有关。当m/n保持不变时,k值越靠近Ki越能保证判断的准确性;而当k值保持不变的时候,m/n的值越大越能保证判断的正确性。虽然整体而言存在误判率,但由于误判率可以调节且很小,所以相较于其在空间占比和时间效率方面的优势,Bloom算法在能够容许误判的情况下是不错的选择。 多维Bloom算法由多个基本Bloom过滤器组成,且多个基本过滤器具有相同元素维数的位数组空间。每个基本过滤器负载待对比元素在某一维上的属性,进行对比判断时,需要对元素在每一维上的映射是否都存在于各自对应的过滤器位向量上进行判断,并最终给出元素是否已存在于集合中的判定结果。 将多维Bloom算法的维数设为L,则其误判概率为: (7) 由式(1)可知,多维Bloom算法的误判概率与其维数大小成负相关,当k、m和n一致的时候,误判率随维数的增加而减小。且多维过滤器的误判率始终低于基本过滤器的误判率,是其每一维过滤器误判率的乘积。 在解决实际问题时需要使用按时间排列的多个Bloom过滤器。首先,根据需求决定时间序列的粒度,然后在该粒度下选择相应的要使用的Bloom过滤器的数量。例如,当去重周期为7天时,比较合适的时间粒度为“天”,过滤器数量为7;当去重周期为7个月,比较合适的时间粒度为“月”,过滤器数量同样为7;当去重周期为一个月时,可以选择时间粒度为“天”也可以选择时间粒度为“月”,相应的过滤器数量为30和1。 在创建Bloom过滤器列表时,不会对数据库中原有的数据产生影响。若Redis中已存在该键,会创建过滤器列表的Python对象并连接到Redis对应的键上;如果不存在,创建该键后再创建对象并连接到对应键上。当然,创建Python对象时也会声明每个键的过期时间。比如,当粒度为“天”、过滤器数量为7、今天是2019年6月3日时,列表的结构如表1所示。 表1 创建Bloom过滤器列表的举例 采用这种方法,当去重周期到后,对应Bloom过滤器里的内容会被自动清空,不再需要手动删除以释放内存,也不会影响其他时间的过滤器。 每当有新请求需要发出时,首先要生成当前时间有效的过滤器列表,然后对过滤器列表中的每一个过滤器进行对比判断,只有全部过滤器都不包含此请求时,才能说明该请求没有在有效期内进行请求过,才能够将其放入请求队列等待请求,并将该指纹存入当前时间对应的过滤器中。 Redis中存在散列表数据结构,它保存了键到值的映射,因此可以利用它进行请求指纹的自动过期设置。步骤如下: Step1因为Redis的去重集合中只保存了指纹,所以为了保存从该指纹到其过期时间的映射,需要先将去重数据的集合结构转换为哈希表结构。 Step2判断每一个需要发起的请求是否在哈希表中存在。 Step3当该请求存在于哈希表中时,对比当前时间和已存在指纹的过期时间。如果当前时间大于过期时间,需要更新指纹的过期时间并将请求种子放入请求队列;反之,则说明该请求在有效期内已经被处理过,可以放弃访问。 Step4当该请求不存在于哈希表中时,将请求种子加入请求队列,将指纹和过期时间写入哈希表中。 需要注意的是,该算法在实现时需要在Scrapy-Redis的settings中设置过期时间,同时通过from_crawler方法进行获取。 使用这种方法来实现请求指纹的自动过期虽然简单灵活,也可以指定任意的过期时间,且保证相同的请求两次进行采集的时间间隔必定不小于指定的时间,但该方法存在很大的缺陷:其一,使用该方法后无法使用Bloom算法压缩内存;其二,如果有URL在第一次被请求后再也没有被请求或很长时间内再没有被请求,那么始终缓存在Redis中的这些请求指纹会逐渐堆积造成巨大的空间消耗。要处理这些占用空间的指纹需要额外编写脚本,这就代表不能直接依赖框架的去重机制来设置指纹,自然会消耗更多的计算和存储资源。 所有针对Scrapy-Redis框架的重构过程,不会影响到框架的其他功能,更不会对其进行破坏。同时,多维Bloom过滤器中位数组的实现和维护需要依赖Redis数据库,所以改造Redis数据库是对框架进行改造的基础。 (1) 算法流程图。该算法实现过程如图4所示。 图4 实现Redis指纹自动识别的算法流程图 (2) 获取时间粒度、设置Bloom过滤器个数,并初始化过滤器。选择时间粒度及设置过滤器个数的方法在2.2节中已有介绍。对每个过滤器key(键)的过期时间的设定,可以在settings中设置然后通过from_crawler方法获得,也可以在下一步“初始化过滤器”中进行设置。 初始化过滤器时,因为各个过滤器之间是独立的,所以主要设置的参数如下:需要的总bit位数、需要最少的哈希次数、需要多少MB内存、需要多少个512 MB的内存块(指纹的第一个字符必须为ASCII码,最多有256个内存块),以及seed值的选择、key的获取、最大指纹量和位数组长度的设置等。 关于总的bit位数和需要的最少哈希次数,因为要处理亿级之上的数据去重,所以指纹量n的值为1亿以上,此时哈希函数个数k的取值可以为10左右,这样位数组长度m至少要在10亿以上,因为数值较大,所以采用左移的位操作来实现,左移的位数设为bit。假设bit=30,就有m为1<<30,因为1<<30=1 073 741 824=230=128 MB,此时再设k取6,则能够处理的最大指纹量为230/k=178 956 970个。 在seed值的选择上为每个过滤器内置了100个随机种子;在能够处理的最大指纹量上,本文在初次编码中将其设为1亿,而位数组长度设为了231-1。 (3) 生成周期内有效的过滤器key列表。在生成针对当前时间的有效周期内过滤器key列表时,定义了get_bloomfilter_keys()方法,该方法能够根据当前时间、时间粒度和过滤器个数来返回有效的过滤器key列表。例如,假设当前时间为20190508,filter_granularity=′d′,filter_num=7,则返回的列表为[′xxx:20190502′,′xxx:20190503′,...,′xxx:20190508′],其中,′xxx′代表RFPDupeFilter的key。另外,在实现过滤器“判断指纹是否存在于当前key对应的过滤器中”时,定义了一个exists()方法。在该方法中,为了应对日期的变化,像从20190508到20190509的过渡之类的,需要每次都重新计算当前有效的过滤器的键名列表,然后再进行判断和处理。 (4) 判断指纹是否在key对应的过滤器中。需要实现一个关键方法:判定指纹是否重复的exists()方法。部分代码如下: if not value: return False exist=1 for map in self.maps: offset=map.hash(value) exist=exist & self.server.getbit(self.key,offset) return exist value为待判断的元素即一个新到来的指纹,定义变量exist为1后,将其与每一个哈希函数对value进行哈希运算后得到的映射结果进行循环与运算,利用Redis中getbit()方法取每一次映射结果对应位置的值。若每一次取到的值都为1,则结果为True,表示value在集合内已存在;相反,只要getbit()的结果有一次为0,则结果为False,表示value不在集合内。 另外,由于在实现多维Bloom过滤器时使用到的key和server是可变的,所以不同于单个的基本过滤器的实现,这里的exists()方法在传参时需要将key和server也一并传入。 (5) 将指纹写入当前时间的过滤器。同样需要实现另一个关键方法:添加指纹到集合中去的insert()方法。部分代码如下: for f in self.maps: offset=f.hash(value) self.server.setbit(self.key,offset,1) insert()方法同样遍历调用哈希函数以对元素进行运算并得到映射位置,然后利用Redis的setbit()方法将其位置置为1。同时,该方法的传参相较于简单的Bloom过滤器同样多了server和key。 要完成已经实现的多维Bloom算法与Scrapy-Redis的对接,还需要继续修改框架内源码,同时将它的组件Dupefilter去重类替换为多维Bloom过滤器的逻辑。替换过程主要通过更改RFPDupeFilter类中的request_seen()来实现: def request_seen(self,request): fp=self.request_fingerprint(request) if self.bf.exists(fp): return True else: self.bf.insert(fp) return False 获取请求指纹的方法是request_fingerprint()方法,判断该指纹是否已在任意过滤器的key中存在的方法是exists()方法。如果任何一个过滤器显示存在,则说明该Request是重复的,返回True,不再访问该请求。相反,如果全部过滤器显示不存在,则返回False并调用insert()方法添加指纹到当前过滤器,添加请求到请求队列。 重构后框架和Scrapy-Redis具有相似的使用方法,但还有几个关键的参数需要配置。 使用时需要替换掉DUPEFILTER_CLASS后使用,可以将其设置为:DUPEFILTER_CLASS="scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter"。 在初次代码编写中设置了最大指纹处理量为1亿,位数组选择了231-1,但在实际运用中,可以根据自己的需要在初始化过滤器时配置预处理的指纹量(capacity)、左移位数(bit)等参数。 同时为了控制误判率,在设置bit参数时,可以引入error_rate变量来表示误判率,然后使用math.ceil(capacity*math.log2(math.e)*math.log2(1/error_rate))来计算需要的总bit位数。这样,根据不同误判率的要求设置不同的误判率参数就可以获得不同的左移位数,但会影响到指纹自动过期的空间占用问题。 首先测试多维Bloom过滤器能否正确使用,因为在处理亿级规模指纹存储时难以寻找误判的URL,因此,此部分利用每小时爬取100个URL的方法对过滤器的功能进行了测试。将时间粒度设为小时,并以两个小时为过期时间创建两个Bloom过滤器,编写爬虫程序分别在相应的时间访问“https://www.baidu.com/s?wd=”并抓取100篇新闻的URL。结果显示,第一小时与第二小时内所存储的指纹中无重合,第三小时与第一小时的指纹有重合而与第二小时的指纹无重合,第四小时的指纹与前两小时的指纹都有重合而与第三小时的指纹无重合,由此可知重构后的框架可以实现指纹的自动过期功能。 在此基础上可以分析重构后框架在实现指纹自动过期时的误判率。编写爬虫程序,分三天爬取某博客网站的博文,三天内再次遇到某博文不进行访问和指纹的存储,三天后再遇到该博文进行访问并存储指纹。根据需求显然可知过期周期为3,因此将时间粒度选为天,需要创建3维Bloom过滤器,每个过滤器设置各自对应的key为20190603-20190605、过期时间分别为20190606-20190608。此外为了适应抓取规模、便于实验测试,每个过滤器的哈希函数个数k统一设置为6。此时根据抓取的数据量的不同,可以计算出最优的位数组长度,即最优的左移位数。表2为不同数据量需求下最佳左移位数及其最低误判率的展示。 表2 k固定时最佳左移位数及误判率 由表2可以看出,即使是在k固定的情况下,重构后框架的误判率也可以满足低于万分之一的条件,更不用说在最优k和最优m/n值之下了。 除了误判率外,另一项需要关注的点是重构后框架所占用空间。实验部署在内存总大小为175 GB的服务器上,虚拟机选用Centos7,分别以每天1亿爬取量和每天2亿爬取量的需求设置爬虫,所以三天内最高指纹存储需求可以达到6亿。通过对比使用Redis和使用重构后框架存储不同量指纹时所占用的空间,得到结果如图5所示。 图5 两种方式下的空间占用情况 Redis的占用空间既包括指纹所占空间也包括请求种子所占用的空间,重构后框架的占用空间为依据表2在k值固定情况下选择最优左移数之后,多维过滤器所开辟的位数组的总空间。综上可以看出,重构后的框架可以在极低的误判率下实现指纹的自动过期,且大大节省所需空间。 本文采用了多维Bloom算法对分布式爬虫所用的Scrapy-Redis框架进行了重构,将实现后的携带当前时间及过期时间信息的多维Bloom过滤器替换掉原框架内的去重类,从而达到了Redis键内所存指纹自动过期的要求。该方法可以用于类似“过期时间内再次遇到某URL不访问不存储,过期时间后再次遇到该URL访问并存储”的场景,且能够在误判率低于万分之一的情况下,大大缩减指纹存储所占用的空间。2.2 多维Bloom算法

2.3 Redis散列表设置指纹过期
3 重构Scripy-Redis框架
3.1 多维Bloom算法的实现
3.2 多维Bloom与Scrapy-Redis的对接
4 测 试


5 结 语
猜你喜欢
房地产导刊(2022年10期)2022-10-18
电脑报(2022年13期)2022-04-12
大数据(2021年6期)2021-11-22
现代信息科技(2021年21期)2021-05-07
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
电脑报(2020年24期)2020-07-15
智能计算机与应用(2018年5期)2018-10-20
电脑知识与技术·经验技巧(2018年1期)2018-05-30
电脑爱好者(2017年22期)2017-12-04
