
极端低光情况下的图像增强方法
2020-09-01 15:03刘惠义
图学学报 2020年4期
杨 勇,刘惠义
极端低光情况下的图像增强方法
杨 勇,刘惠义
(河海大学计算机与信息学院,江苏 南京 211100)
针对极端低光情况下的图像增强问题,提出一种基于编码解码网络和残差网络的端到端的全卷积网络模型。设计一个包括编码解码网络和精细网络2部分的端到端的全卷积网络模型作为转换网络,直接处理短曝光图像的光传感器数据得到RGB格式的输出图像。该网络包含对抗思想、残差结构和感知损失,先通过对极低光图像编码解码重构图像的低频信息,之后将重构的低频信息输入残差网络中进而重构出图像的高频信息。在SID数据集上进行实验验证,结果表明,该方法有效地提高了极端低光情况下拍摄得到的图像进行低光增强之后的视觉效果,增加了细节表达,使得图像中物体的纹理更加清楚和边缘更加分明。
深度学习;卷积神经网络;极低光图像;生成对抗网络;图像增强
在光线昏暗的环境下,摄影师拍摄出正常成像非常困难。在更极端的黑暗情况下,如光照严重受限(月光)或短时间的曝光,成像就更为困难。低光下拍摄的图像和极低光下拍摄的图像对比如图1所示,明显看出极低光下拍摄的图像相比低光下拍摄的图像被隐藏的信息更多。

图1 低光下拍摄的图像(左)与极低光拍摄的图像(右)对比
在图像拍摄过程中可以通过提高感光度(ISO)增加亮度,但不可避免地会放大噪音。采用缩放或直方图拉伸等一系列后期处理方法可以减弱噪音的影响,但并不能有效解决低信噪比的问题。在拍摄过程中采用打开光圈、延长曝光时间、使用闪光灯等物理方法虽然能达到在低光环境下增加信噪比的效果,但图像会因为相机的抖动或物体的移动而变得模糊。因此,低光图像的增强一直是计算机视觉领域极具挑战性的研究方向,极低光情况作为低光情况中的特例,也受到国内外学者的广泛关注。
目前研究人员主要通过降噪、去模糊、低光图像增强等一系列技术用于处理低光环境下的图像。早期的传统方法主要围绕着直方图均衡化(histogram equalization,HE)和伽马修正。HE方法直接利用图像的直方图来增加图像的全局对比度,经典的伽马修正方法则通过加大图像的明暗区域的差值达到图像增强的目的。
结合图像去雾去噪算法的传统方法包括:DONG等[1]提出一种结合图像去雾算法的低光视频增强方法;YING等[2]提出一种基于融合的低光增强方法;REN等[3]提出一种结合图像去噪的低光增强方法。结合暗通道先验、Retinex等先验理论的传统方法包括:GUO等[4]提出一种反转低光图像再增强的低光增强方法;JOBSON等[5]提出一种带色彩恢复的多尺度Retinex增强方法(multi-scalewith color restoration,MSRCR)。相比于未使用先验知识的传统方法,这些方法可以对处于低光情况下的图片进行更有效的增强处理,但处理更极端低光情况下的图像的效果不甚理想。
随着机器学习和深度学习技术发展,有些学者提出了基于机器学习或深度学习的端到端方法和结合先验知识的深度学习方法。端到端的方法包括:YAN等[6]提出一种基于机器学习排序的自动增强图像方法;LORE等[7]提出一种基于堆叠自编码器的增强图像方法;YAN等[8]提出一种基于卷积网络的自动增强图像方法;GHARBI等[9]提出一种双边仿射学习方法(high-dynamic range-net);PARK等[10]提出了基于深度强化学习的图像增强方法;IGNATOV等[11]提出一种弱监督的图像增强方法;CAI等[12]提出了通过学习图像对比度实现图像增强的方法;HU等[13]提出一种将图像处理操作建模成与分辨率无关的可微分滤波器实现低光增强的方法等。结合先验知识的深度学习方法包括:PARK等[14]提出了基于空间自适应的L2范数和Retinex理论的低光图像增强方法;SHEN等[15]提出一种基于卷积神经网络的多尺度Retinex方法(multi-scale Retinex-net,MSR net);WEI等[16]提出一种结合Retinex理论和卷积网络理论的低光增强方法(Retinex-net)。相比传统方法,这些方法在处理低光图像上,可以得到更好的视觉效果。但在处理极端低光情况下拍摄的图像时,仍然会产生严重的噪音干扰。
CHEN等[17]在2018年首次采用SID (see in the dark)数据集,基于数据驱动方法训练一个端到端的网络,实现了极端低光情况下图像的增强,取得了良好的效果,但该方法设计的网络对物体细节的还原仍然有着很大的不足,增强之后的图像中物体的边缘存在模糊现象。
本文在文献[17]基础上,对其编码解码网络进行了改进,引入残差网络提升对图像细节的还原效果,使得增强后图像中物体的纹理和边缘均更加清晰,有着更好的视觉效果。
1 极低光图像增强模型构建
图像的频率是表征图像中灰度变化剧烈程度的指标,一张图像所包含的信息可以分为:低频信息、高频信息2类,低频信息即图像在光滑部位的整体灰度信息,高频信息即图像的边缘轮廓信息。在超分辨率(super resolution)问题上,残差结构已经被证明可以很好地生成图像的高频信息即边缘轮廓及纹理信息[18]。
本文构建的极低光图像增强网络模型的基本思想是让网络的前半部分生成图像的低频信息,后半部分对低频信息进行加强得到图像的高频信息。最终输出拥有更多细节的图像。假设训练数据集为{low,I,I},low为输入的短曝光极低光图像的原始光传感器数据,大小为´´1,其为拜尔阵列,每个像素点16位,范围0~65 535,可通过插值算法转换成大小为´´3的RGB格式的图片。I为极低光对应的正常曝光图像经高斯滤波得到的低分辨率图像,大小为(/4)´(/4)´3。I为短曝光图片对应的正常曝光、正常分辨率的图片,大小为´´3。
在对极低光图像进行增强前需将图片原始光传感器数据进行预处理,过程如图2所示。高度、宽度、通道数1的原始传感器数据减去黑色背景数据,然后乘以亮度放大因子,得到高度/2、宽度/2、通道数4的RGB格式输入数据。其中亮度放大因子在训练阶段由I与low的曝光时间的比值确定,通常取值为100、250、300,在测试阶段也由I与low的曝光时间的比值确定,在实际应用过程中可任意取值。相比平常使用RGB图片,从图片中的原始传感器数据会得到额外的G通道数据。

图2 输入数据预处理
1.1 对抗网络架构
采用对抗网络架构实现极低光图像的增强,分为转换网络T和辨别网络D2部分。转换网络模型结构如图3所示。
卷积层为一层卷积加一层激活。转换网络T由前半部分U-Net架构的编码解码网络和后半部分由残差模块和上采样层组成的精细网络组成,其中为卷积核大小;为卷积核数量;为卷积步长。转换网络T输入原始传感器数据,输出增强之后的RGB格式的图像。其中编码解码网络中的编码解码块结构如图4所示,输入特征图经过2次卷积和Leaky-ReLU激活得到输出特征图。精细网络中残差块结构如图5所示,输入特征图依次经过卷积、Batch-Normal、PRelU、卷积、Batch-Normal得到特征图,再加上输入特征图得到最终的输出特征图。精细网络中上采样层结构如图6所示,输入特征图依次经过卷积、2倍放大倍数的PixelShuffle、PReLU、卷积、2倍放大倍数的PixelShuffle、PReLU、卷积得到输出特征图。
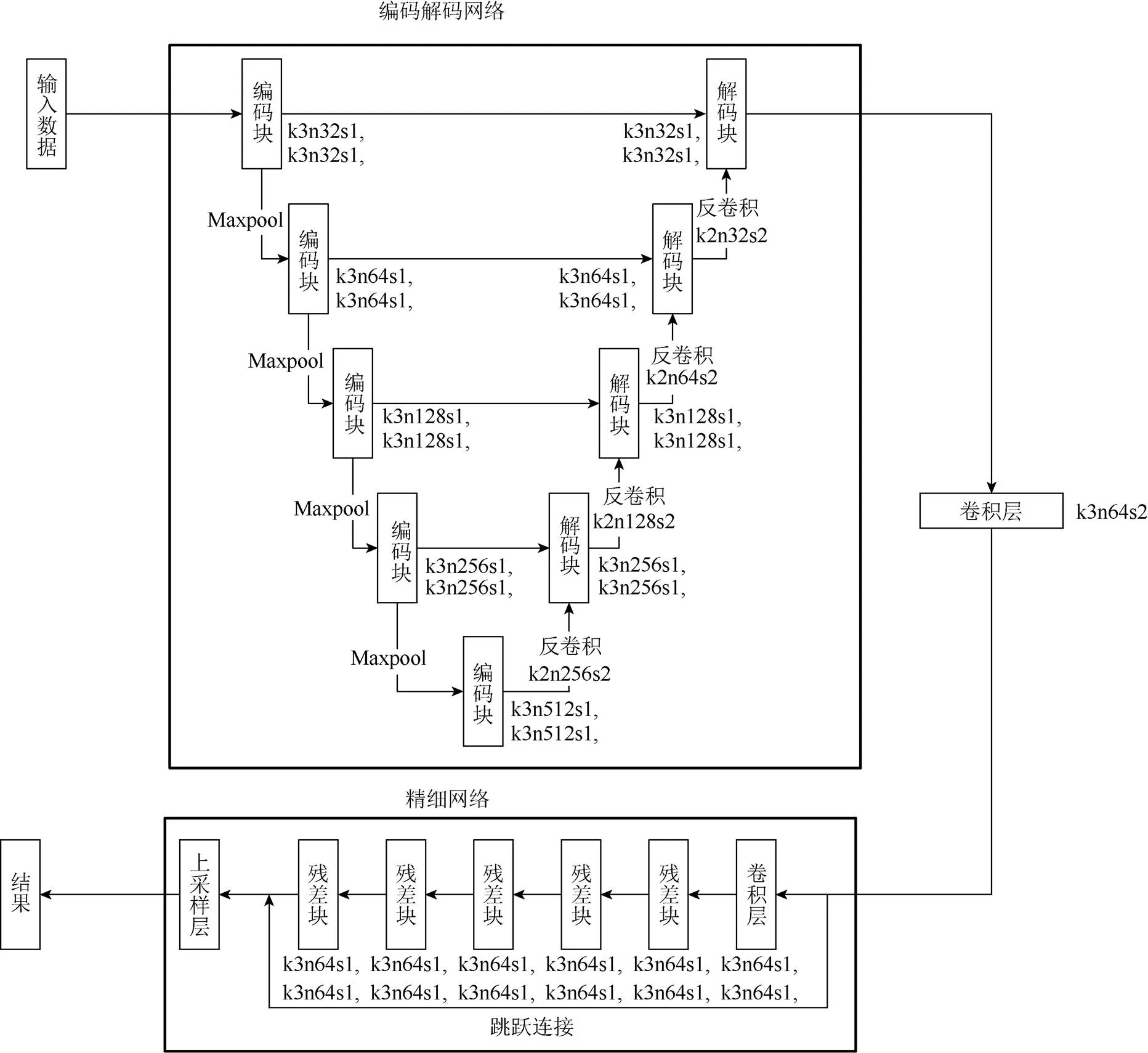
图3 转换网络T模型结构

图4 编码解码块示意图

图5 残差块示意图

图6 上采样层示意图
辨别网络D的网络结构如图7所示,卷积层也为1层卷积加1层激活。由9层卷积层和1层全连接层构成,其中为卷积核大小;为卷积核数量;为卷积步长。辨别网络D输入一张图片,输出其真伪。
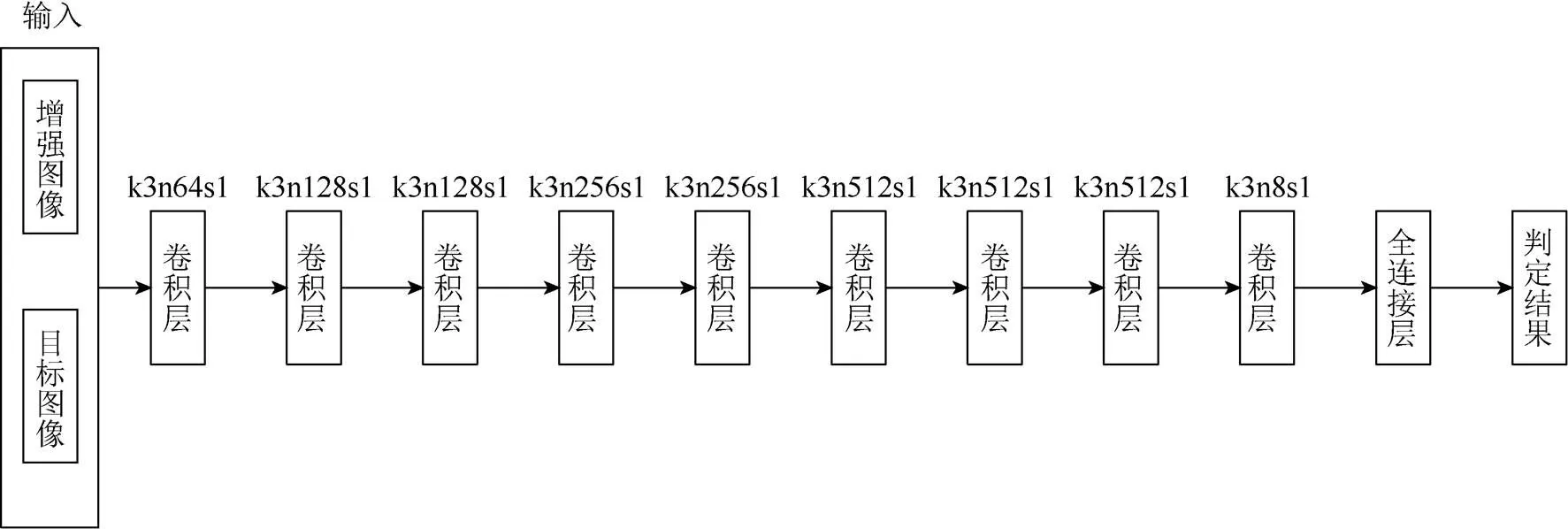
图7 辨别网络D模型结构
转换网络T的功能是输入极低光图像的光传感器数据low增强得到正常曝光的RGB图像result,其转换见式(1)。辨别网络D的功能是辨别输入图像为真实图像I,还是通过转换网络得到的增强图像result,如式(2)所示

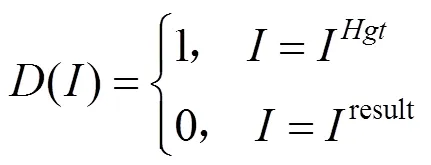
在训练过程中,同时训练一个转换网络T和一个辨别网络D。对抗网络极大极小优化过程计算见式(3)

1.2 模型损失函数构建
转换网络T通过损失函数L学习极低光图像的原始传感器数据到正常曝光的RGB图片的映射,转换网络的损失函数L由3部分构成,见式(4)
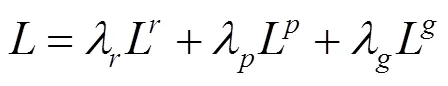
其中,L为MSE均方损失;L为图片感知损失;L为对抗损失。,,分别为MSE均方损失系数、感知损失系数、对抗损失系数。
采用MSE均方损失函数计算转换网络增强之后的图像和正常曝光的图像像素级上的差异,具体见式(5)
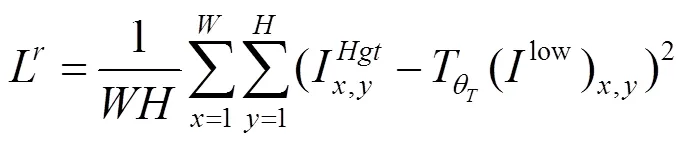
其中,为增强之后图像的宽;为增强之后图像的高。
优化MSE均方损失函数会导致出现生成图像缺乏高频信息及图像过于平滑的问题。文献[19]针对超分辨率问题提出了感知损失。感知损失是比较生成图像和目标图像分别通过在ImageNet数据上预训练的VGG16网络卷积得到的激活前的特征图之间的差异,优化感知损失可以使生成图像和目标图像的高频信息接近,从而有效地重构生成图像的高频信息部分,使得生成图像拥有更多地细节信息。具体计算如式(6)
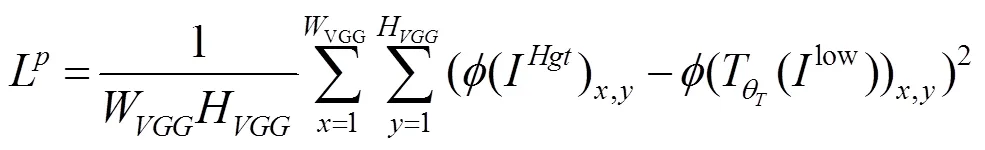
在重构内容损失和感知损失之外,为了使转换网络得到更自然的图像,还增加了生成对抗损失,如式(7)
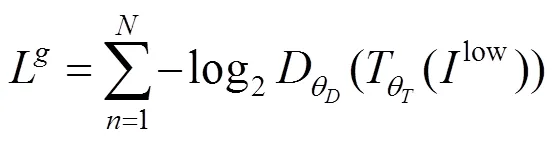
1.3 阶段训练
由于图3转换网络T有较深的深度,所以采用“阶段训练整体优化”的策略优化转换网络T。依次优化转换网络T中编码解码网络部分、转换网络T中精细网络部分和转换网络T。编码解码网络和精细网络的优化分别通过训练2个子网络T-1和T-2实现。子网络T-1和T-2的结构分别如图8和图9所示,其中为卷积核大小;为卷积核数量;为卷积步长,图中的编码块、解码块、残差块均与图3转换网络T对应位置保持一致。
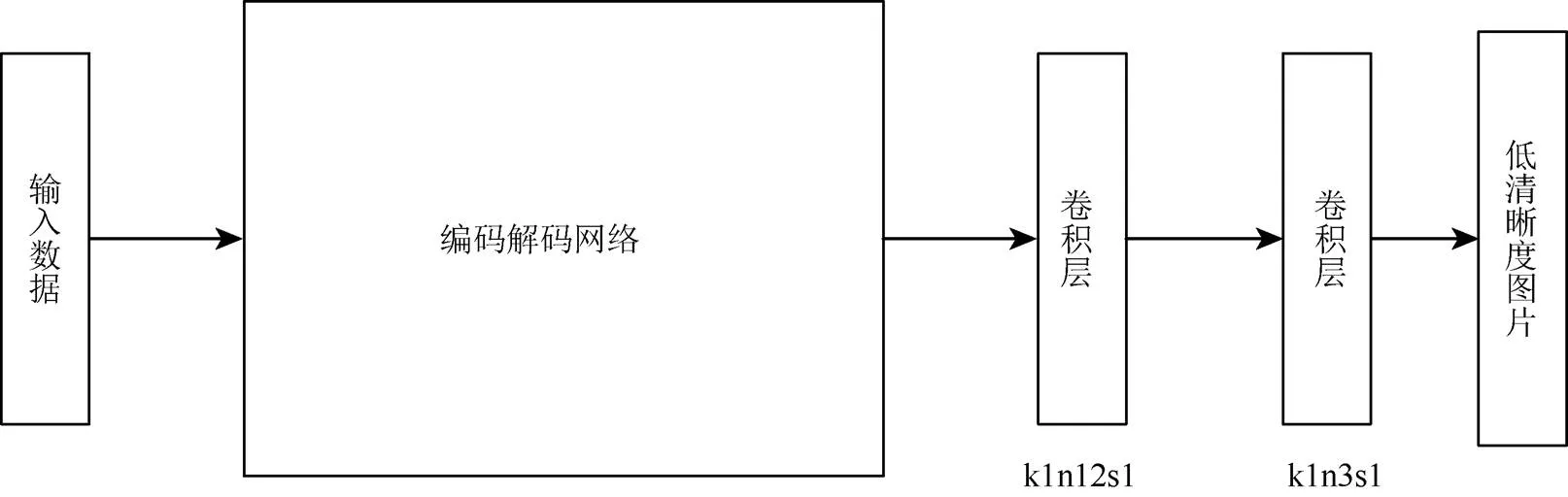
图8 转换网络T-1模型结构

图9 转换网络T-2模型结构
子网络T-1输入原始传感器数据low,得到一张低分辨率正常光图片I,其损失函数只包含像素级的均方损失。子网络T-2输入一张低分辨率图片I得到对应的高分辨率图片I,其损失函数包含像素级的均方损失、感知损失和对抗损失。
2 实验与结果分析
2.1 实验条件及参数设置
本实验使用pytorch深度学习框架实现网络,在显存为16 G的Tesla P100 GPU上训练。使用的SID数据集包含5 094个原始的短曝光极低光图像,每个极低光图像均有对应的长曝光参考图像。长曝光参考图像I高斯滤波缩小4倍得到低分辨率图像I,图像宽度和高度均为512,每批次输入1张图片。预训练中,转换子网络T-1采用Adam优化算法,beta1设为0.900,beta2设为0.999,训练总批次为4 000,学习率为10–4,在批次大于2 000后,学习率为10–5。转换子网络T-2采用Adam优化算法,beta1设为0.500,beta2设为0.999,损失函数中λ设为1.000,λ设为0.006,λ设为0.001。训练总批次为2´104,学习率为10–4,在104批次后将学习率慢慢衰减致10–6。转换网络T采用Adam优化算法,beta1设为0.500,beta2设为0.999,损失函数中λ设为1.000,λ设为0.006,λ设为0.001。训练总批次为2´104,学习率为10–4,在前100个批次将学习率线性衰减到10–5,在104批次内将学习率线性衰减到10–6,之后再以学习率10–6训练104次。
2.2 实验结果
为了验证本文方法的有效性,分别与LIME方法[4]、Retinex-Net方法[16]、文献[17]所提极端低光增强方法对比。LIME方法的结果如图10所示,
其中1和4为输入极低光图像,2和5为增强之后的结果,3和6为极低光图像对应的长曝光图像。Retinex-Net方法的结果如图11所示,其中1和4为输入极低光图像,2和5为分解网络得到的反射图,3和6为分解网络得到的光照图。文献[17]方法与本文方法的对比如图12所示,其中1为极低光环境下短曝光未经过任何处理的图像,2为短曝光对应的长曝光参考图像,3为文献[17]方法得到的结果,4为本文方法得到的结果,5为长曝光参考图像的细节,6为文献[17]的图像细节,7为本文方法图像细节。通过图10和图11可以看出,LIME,Retinex-Net这些低光增强方法无法处理极端低光的图像。从图12可以看出,通过本文方法得到的图像细节被更进一步地还原,物体的纹理更为细致、轮廓更加分明。
通过峰值信噪比(peak signalto noise ratio,PSNR)和结构相似性(structural similarity index,SSIM)指标与文献[17]、LIME、Retinex-Net方法进行定量对比。PSNR是一种基于误差敏感的图像质量评价指标,SSIM是一种从图片组成角度分析图片相似度的评价指标。但是因人眼视觉特性的因素,PSNR或SSIM值高的图片,其视觉上可能并不清楚,但PSNR和SSIM依然是衡量图像质量的重要参考标准。定量对比实验结果见表1。从表1结果可以看出,本文方法在PSNR与SSIM指标数值上与LIME方法和Retinex-Net方法相比有大幅提升,与文献[17]相比有微小提升。对图12中2张对比图分别编号图像1和2,计算图像1和2的PSNR和SSIM值与文献[17]方法进行对比,其结果见表2。从表2可以看出,虽然图像2在细节上提升明显,但是其PSNR和SSIM值相比文献[17]却下降了。为了更加准确地衡量模型增强效果,另从数据集的测试集中随机选择200张极端低光图像经由不同模型进行增强处理,计算这200张图片的PSNR和SSIM的平均值进行对比实验,随机抽取图像的实验结果见表3。从表3可以看出,本文方法对大部分极低光增强所得图像的PSNR值和SSIM值优于其他方法。表4为本文方法的消融实验。从表4可以看出,预处理策略、残差网络和感知损失均可有效提升增强之后图像的PSNR和SSIM指标值。

图10 LIME实验结果

图11 Retinex-Net实验结果

图12 文献[17]方法结果与本文方法结果对比图
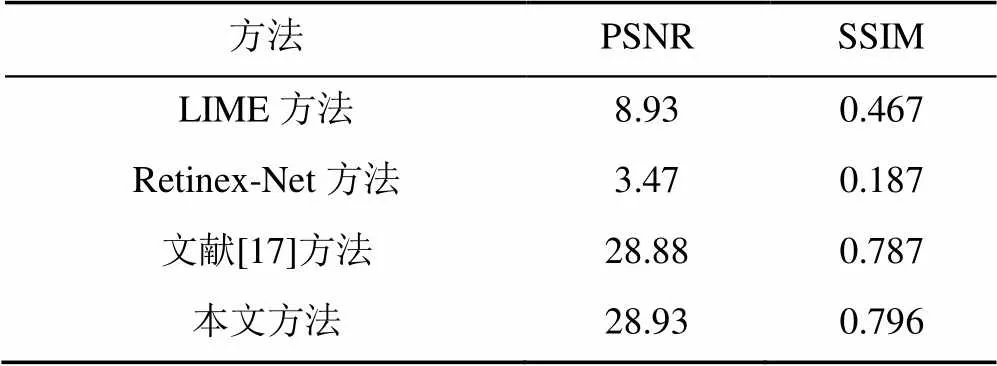
表1 定量实验结果

表2 图12中2组对比图的PSNR值和SSIM值
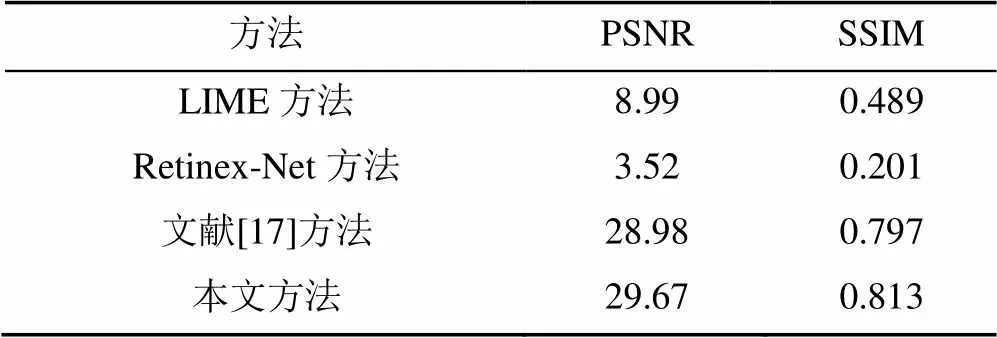
表3 随机抽取图像的实验结果

表4 消融实验结果
3 结 论
本文针对极端低光情况下的图像增强问题,提出一种新的增强模型,引入残差网络和感知损失重构图片的高频信息,更好地还原了图像的细节,得到了更好的视觉效果,在PSNR和SSIM这2个定量指标上也有所提升。另一方面目前亮度放大倍数为人为输入,未来可以根据极低光图像的信息估算出亮度放大倍数。如何在进一步地提升增强后图像视觉效果的同时提高PSNR和SSIM定量指标的值,以及如何估算光度放大倍数,将是未来研究的方向。
[1] DONG X, WANG G, PANG Y, et al. Fast efficient algorithm for enhancement of low lighting video[C]// 2011 IEEE International Conference on Multimedia and Expo. New York: IEEE Press, 2011: 1-6.
[2] YING Z Q, LI G, REN Y R, et al. A new image contrast enhancement algorithm using exposure fusion framework[M]//Computer Analysis of Images and Patterns. Cham: Springer International Publishing, 2017: 36-46.
[3] REN X, LI M, CHENG W H, et al. Joint enhancement and denoising method via sequential decomposition[C]// 2018 IEEE International Symposium on Circuits and Systems (ISCAS). New York: IEEE Press, 2018: 1-5.
[4] GUO X J, LI Y, LING H B. LIME: low-light image enhancement via illumination map estimation[J]. IEEE Transactions on Image Processing, 2017, 26(2): 982-993.
[5] JOBSON D J, RAHMAN Z, WOODELL G A. A multiscale retinex for bridging the gap between color images and the human observation of scenes[J]. IEEE Transactions on Image Processing, 1997, 6(7): 965-976.
[6] YAN J Z, LIN S, KANG S B, et al. A learning-to-rank approach for image color enhancement[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 2987-2994.
[7] LORE K G, AKINTAYO A, SARKAR S. LLNet: a deep autoencoder approach to natural low-light image enhancement[J]. Pattern Recognition, 2017, 61: 650-662.
[8] YAN Z C, ZHANG H, WANG B Y, et al. Automatic photo adjustment using deep neural networks[J]. ACM Transactions on Graphics, 2016, 35(2): 1-15.
[9] GHARBI M, CHEN J W, BARRON J, et al. Deep bilateral learning for real-time image enhancement[EB/OL]. [2019-12-03]. https://arxiv.org/ abs/1707.02880.
[10] PARK J, LEE J Y, YOO D, et al. Distort-and-recover: color enhancement using deep reinforcement learning[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 5928-5936.
[11] IGNATOV A, KOBYSHEV N, TIMOFTE R, et al. WESPE: weakly supervised photo enhancer for digital cameras[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). New York: IEEE Press, 2018: 691-700.
[12] CAI J R, GU S H, ZHANG L. Learning a deep single image contrast enhancer from multi-exposure images[J]. IEEE Transactions on Image Processing, 2018, 27(4): 2049-2062.
[13] HU Y, HE H, XU C, et al. Exposure: a white-box photo post-processing framework[J]. ACM Transactions on Graphics (TOG), 2018, 37(2): 1-17.
[14] PARK S, YU S, MOON B, et al. Low-light image enhancement using variational optimization-based retinex model[J]. IEEE Transactions on Consumer Electronics, 2017, 63(2): 178-184.
[15] SHEN L, YUE Z H, FENG F, et al. MSR-net: low-light image enhancement using deep convolutional network[EB/OL]. [2019-11-29]. https://arxiv.org/abs/ 1711.02488.
[16] WEI C, WANG W J, YANG W H, et al. Deep retinex decomposition for low-light enhancement[EB/OL]. [2019-12-04]. https://arxiv.org/abs/1808.04560.
[17] CHEN C, CHEN Q F, XU J, et al. Learning to see in the dark[EB/OL]. [2019-12-03]. https://arxiv.org/abs/1805. 01934.
[18] YAN Z C, ZHANG H, WANG B Y, et al. Automatic photo adjustment using deep neural networks[J]. ACM Transactions on Graphics, 2016, 35(2): 1-15.
[19] LEDIG C, THEIS L, HUSZAR F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 4681-4690.
The method of image enhancement under extremely low-light conditions
YANG Yong, LIU Hui-yi
(College of Computer and Information, Hohai University, Nanjing Jiangsu 211100, China)
The process of obtaining the image with normal exposure time from the image with short exposure time photographed in extreme low-light conditions is defined as the image enhancement under extreme low-light conditions. In this paper, we proposed a method for the enhancement of the extreme low-light image based on the encoding-and-decoding network architecture and residual block. We designed an end-to-end fully convolutional network as the translation model, which consists of two parts: the encoding-and-decoding network and refinement network. The input data of the translation model is the extreme low-light raw data captured with short exposure time in extreme low-light conditions, and the output data is the image in RGB format. Firstly, the low-frequency information of the image was reconstructed via U-net and then was input into the residual network to reconstruct the high-frequency information of the image. Through the experiments carried out on the SID data set and comparisons with previous research results, it is proved that the method described in this paper can effectively enhance the visual effect of the images captured under extreme low-light conditions and improved with low-light enhancement, and increase the expression of the image details.
deep learning; convolutional neural network; extremely low-light image; generative adversarial; image enhancement
TP 391
10.11996/JG.j.2095-302X.2020040520
A
2095-302X(2020)04-0520-09
2020-01-30;
2020-03-02
2 March,2020
30 January,2020;
杨 勇(1996-),男,河南信阳人,硕士研究生。主要研究方向为计算机视觉、深度学习。E-mail:775654398@qq.com
YONG Yong (1996-), male, master student. His main research interests cover computer vision, deep learning. E-mail:775654398@qq.com
刘惠义(1961-),男,江苏常州人,教授,博士。主要研究方向为计算机图像学、CAD/CAM、虚拟现实、科学计算可视化。E-mail:hyliu@hhu.edu.cn
LIU Hui-yi (1961-), male, professor, Ph.D. His main research interests cover computer graphics, CAD/CAM, virtual reality, visualization of scientific computation. E-mail:hyliu@hhu.edu.cn
猜你喜欢
农业工程学报(2022年13期)2022-10-09
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
航天返回与遥感(2022年2期)2022-05-12
燃气涡轮试验与研究(2021年6期)2021-08-01
数学小灵通·3-4年级(2021年5期)2021-07-16
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2017年3期)2017-11-23
