
结合分层和ADMM 的高光谱图像解混方法
2020-08-31 01:39:40房森焦淑红
应用科技 2020年3期
房森,焦淑红
哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001
高光谱遥感成像技术是在多光谱遥感成像技术的基础上发展而来的,高光谱遥感的出现可以称得上是遥感技术的一场革命。高光谱成像传感器单位照射面积比较大,因此混合像元[1−2]现象在高光谱图像中普遍存在。混合像元的存在是影响遥感图像分类精度和目标探测效果的重要原因。光谱解混是处理混合像元的主要技术,目的就是了解混合像元内参与混合的成分以及它们各自所对应的比例,是一种更精确的分类技术。由于线性混合模型(linear mixing model, LMM)[3−5]具有物理意义明确且使用简便,在多数的光谱解混方法中均使用LMM 对高光谱数据进行建模。该模型潜在假设一种地物种类可以用一条单一的光谱曲线完全表示,对光谱变异(spectral variation, SV)[6−7]现象考虑不周。为了应对光谱变异,使用一种扩展 的 线 性 混 合 模 型(extended linear mixing model,ELMM)[8]对高光谱数据进行建模。
文献[9]提出了一种基于分层的高光谱解混技术,通过分层的思想,把复杂的问题分解成若干层计算,以此降低总的计算量。乘子交替方 向 法(alternating direction method of multipliers,ADMM)[10]是一种求解优化问题的计算框架,适用于求解分布式凸优化问题。ADMM 通过分解协调过程,将大的全局问题分解为多个较小、较容易求解的局部子问题、并通过协调子问题的解而得到大的全局问题的解。本文提出了一种将分层解混算法和ADMM 优化算法相结合的高光谱解混算法,该算法同时利用了分层算法和ADMM 的特点,并利用模拟数据和真实数据对该算法进行实验。
1 扩展的线性混合模型
ELMM 主要用于克服由光照条件以及地形变化引起的SV,而且同时保持了LMM 的特点,并证明了该模型的有效性。传统的线性混合模型表达式为
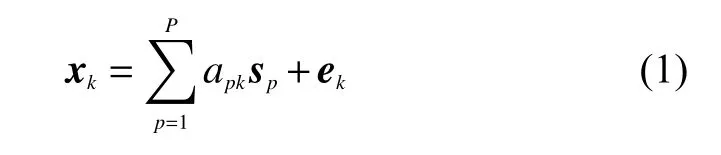
式中: xk表示第k 个像元,是一个向量,维度和光谱图像的波段数相等;P 表示高光谱图像中总的端元种类; sp表示第p 个端元,维度和像元的相同, apk表示第p 个端元在第k 个像元中所占的比例; ek表示噪声,维度也和像元相同。将式(1)运用到整幅图像则可以将其写成矩阵形式:
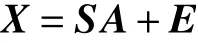
考虑到实际场景中存在SV,可以将一种映射关系作用到端元向量上,那么式(1)可以重新写为
这种映射关系表示成 fpk,作用到对应的端元上就表示端元产生了变异,传统的LMM 在描述高光谱数据时具有的特殊优点,同时考虑SV 和LMM时,令 fpk=ψksp,则式(2)可以重新写为
式(3)只是通过一系列不同的非负缩放因子ψk在像元层面上进行缩放以表示因光照条件或地形因素引起的SV。在实际情况下,通常需要考虑到每种物质所产生的变异。因此可以将式(3)写为
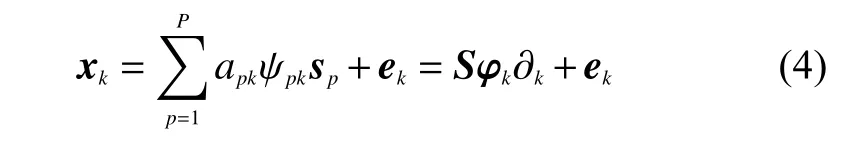
式中: ψpk是取决于具体地物种类和像元的缩放因子; φk∈RP×P是一个对角矩阵,对角线上的元素是P 个端元的缩放因子,其中缩放因子也可以用Ψ ∈RP×N表示,该矩阵与丰度矩阵大小相同。对于整幅图像来说,式(4)可以写成:
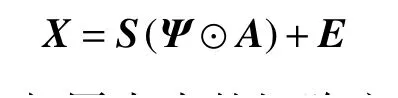
式中 ⊙表示2 个相同大小的矩阵之间逐项进行相乘。这就是ELMM 的矩阵表示,当所有的缩放因子 ψpk等于1 时,该模型将退化为传统的LMM。
2 分层解混算法和ADMM 算法
Roberts D 等[11−13]提出的多端元高光谱解混算法不是针对每个像元采用固定的端元集,而是为每个像元迭代生成与之最为匹配的端元集,该算法解混精度较高,但是需要穷尽列举光谱库中端元的所有组合,所需的计算量也非常大。基于分层的高光谱解混算法,是将复杂的问题化解成若干个层面进行计算,以此来降低计算的复杂度。ADMM 是一种求解优化问题的计算框架,适用于求解分布式凸优化问题。
2.1 基于分层的高光谱解混算法
分层的解混思想[1]是在第一层的计算中可以根据得到的丰度系数,确定该像元中所包含的地物种类以及所对应的地物种类中最佳的类内端元,并选择出丰度系数最大的那类地物所对应的端元。在接下来的计算中以该端元为基准进行多端元组合。
假设高光谱图像对应的地物种类为3 种,且每种地物所包含的类内端元分别为3 种、2 种、2种,记为 M1,1、 M1,2、 M1,3、 M2,1、 M2,2、 M3,1、 M3,2,则对应的端元集表示为E={M1,1,M1,2,M1,3,M2,1,M2,2,M3,1,M3,2}。
1)在第一层利用端元集E 对像元 ykpixel进行解混,选出每个地物种类所对应的最大非零系数,假设}确定的地物种类以及类内光谱为{M1,1,M2,1,M3,1,然后分别计算 M1,1、M2,1、 M3,1与之间的光谱角距离,假设光谱角距离最小的端元为 M1,1;
2)在第一层确定的端元集合的基础上分别与M1,1进行两端元组合,分别记为{M1,1,M2,1}和 {M1,1,M3,1},然后分别计算与之间的光谱角距离,选择出光谱角距离的最小值所对应的端元组合,在此处假设为 {M1,1,M2,1};
3)在{M1,1,M2,1}的基础上与不包含以上2种地物的其他端元进行组合,构造三端元组合,记为{M1,1,M2,1,M3,1}, 然后计算其与之间的光谱角距离;
4)对步骤1)~3)得到的光谱角距离进行排序,将光谱角距离最小所对应的端元组合作为该像元中实际的地物混合,以此端元组合对进行解混计算得到最终的丰度。
2.2 ADMM 寻优算法
ADMM[4]的核心思想是将一个复杂问题分解成一系列简单的子问题进行求解。ADMM 经常用于求解如下形式的非约束问题:
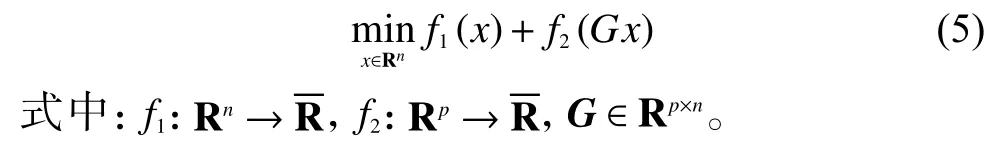
ADMM 方法解决式(5)的步骤如下所示:
1) 令 k=0 , 取 µ>0, u0和 d0;
2) 执行步骤3)~6),直到满足迭代终止条件;

3 合成数据实验
为了验证本文所提算法的有效性,分别对合成数据和真实数据进行实验。在合成数据实验中,从USGS 矿物光谱库中选择Actinolite、Antigorite和Chlorite 的光谱,考虑到光谱变异,分别从这3 种矿物所对应的端元光谱曲线中选取1 条、2 条、2 条,分别记为Actinolite、Antigorite(1)、Antigorite(2)、Chlorite(1)、Chlorite(2),具体的光谱曲线如图1 所示。

图1 各种地物对应的端元曲线
利用这5 条光谱曲线合成一幅100×100×224的高光谱图像,并加入40 dB 的高斯噪声,合成的高光谱图像如图2 所示。
为了使实验结果具有更强的解释性,对该高光谱数据做特殊安排,前1~8 列为Actinolite、9~16 列为Antigorite(1)、17~24 列为Antigorite(2)、25~32 列为Chlorite(1)、33~40 列为Chlorite(2)、40~45 列为Actinolite 和Antigorite(1)的随机组合、46~50 列为Actinolite 和Antigorite(2)的随机组合、51~55 列为Actinolite 和Chlorite(1)的 随 机 组 合、56~60 列 为Actinolite 和Chlorite(2)的 随 机 组 合、61~65 列 为Antigorite(1)和Chlorite(1)的随机组合、66~70 列为Antigorite(1)和Chlorite(2)的随机组合、71~75列为Antigorite(2)和Chlorite(1)的随机组合、76~80列为Antigorite(2)和Chlorite(2)的随机组合、81~85 列 为Actinolite、 Antigorite(1)和Chlorite(1)的随机组合、86~90 列为Actinolite、Antigorite(1)和Chlorite(2)的随机组合、91-95 列为Actinolite、Antigorite(2)和Chlorite(1)的随机组合、96~100 列为Actinolite、Antigorite(2)和Chlorite(2)的随机组合。将本次实验与部分约束最小二乘法(constrained least squares unmixing,CLSU)[14]、部分约束最小二乘法的的缩放版本(scaled version of CLSU,SCLSU)、全约束最小二乘法(fully constrained least squares unmixng,FCLSU)[15]、以及基于分层的高光谱解混算法结果的比较,本文提出的方法表示为H-ADMM。具体的实验结果如图3 所示,颜色深代表丰度值比较大,颜色浅代表丰度值较小。表1 为各种算法的均方根误差。
实验结果从丰度图来看,本文所提算法H-ADMM 在解混精度上最优,FCLSU 次之,CLSU和SCLSU 最差。从表1 中的均方根误差来看,HADMM 的结果最好,比分层解混算法要改善许多。由此可知本文提出算法的有效性。

图2 合成高光谱图像

图3 5 种算法解混丰度

表1 均方根误差
4 真实数据实验
为了更好地验证本文算法的性能,真实数据实验部分采用的是美国印第安纳州实验农田数据。该数据共有16 种地物,图像的空间尺寸大小为144×144,波段总数为100。由于真实数据地物种类繁杂,在本次实验中主要考虑图像中玉米、草和大豆并将其他地物全部作为背景。
考虑到端元变异,玉米、草和大豆中每种地物包含3 条光谱曲线,分别记为玉米1、玉米2、玉米3、草1、草2、草3、大豆1、大豆2、大豆3,背景中包含7 条光谱曲线,分别记为背景1、背景2、背景3、背景4、背景5、背景6 和背景7。鉴于实验篇幅较大,本文只给出实验结果如图4、5 所示。
为了更好地评价这2 种算法性能,还从数据层面对结果进行分析。采用整幅图像的均方根误差作为评价标准。所有像元的均方根误差直方图如图6 所示,整幅图像的均方根误差如表2 所示。
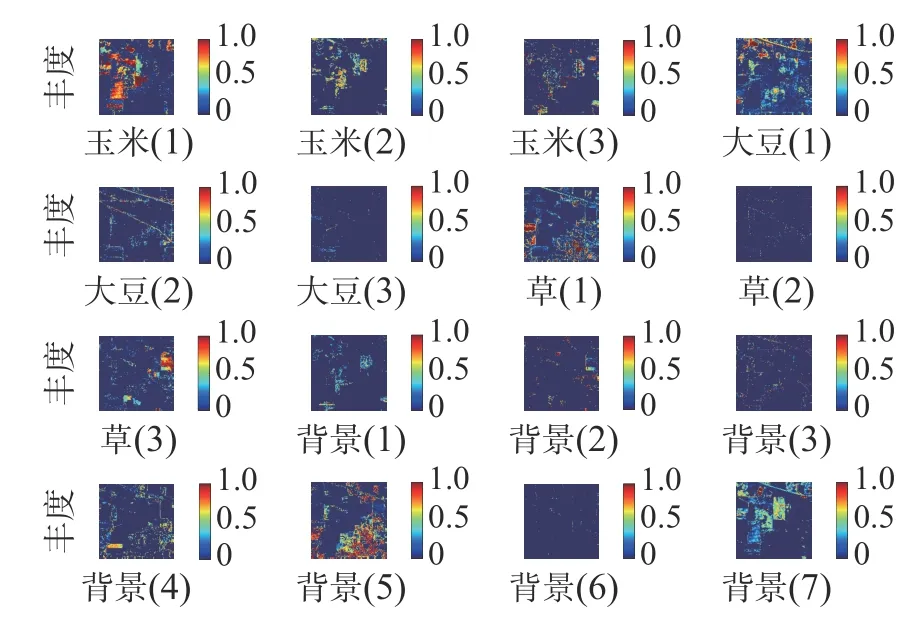
图4 分层解混丰度结果
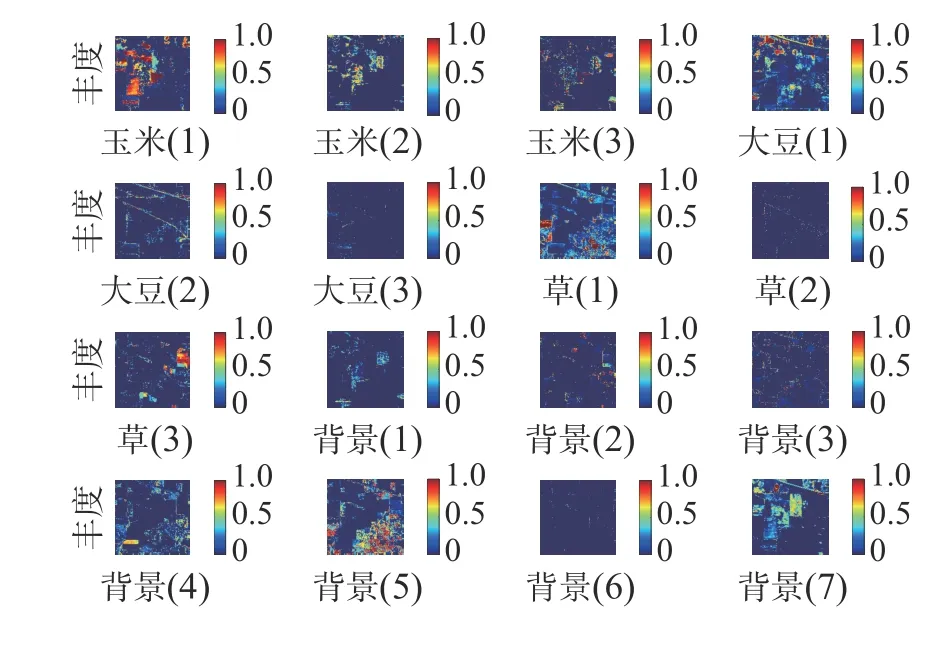
图5 H-ADMM 解混丰度图

图6 2 种算法的均方根误差直方图

表2 2 种算法的均方根误差
从图6 可以看出,通过H-ADMM 算法的解混结果所得到的所有像元的均方根误差分布较为集中,且误差范围分布较小。从2 种算法的均方根误差来看,H-ADMM 的均方根误差要远小于基于分层的高光谱解混算法,减小了约58.8%。
5 结论
无论从合成数据实验还是从真实数据实验中均可以看出,本文所提算法H-ADMM 均优于基于分层的高光谱解混算法。
1)在合成数据实验中,H-ADMM 在解混丰度图上明显好于其他几种经典的高光谱解混算法,解混后的丰度图边界清晰,背景噪声较小;
2)在真实数据实验部分,从解混丰度图上也可以看出H-ADMM 算法对于分层解混算法的优势,从数据结果上可以明显看出H-ADMM 要优于分层解混算法。
因此本文所提算法具有一定的优势。但在以后的研究中,应对H-ADMM 算法进行多种的真实数据实验,探索H-ADMM 算法中各个参数对解混结果的影响大小,使该算法适应于更多的真实场景。
猜你喜欢
中学生数理化·七年级数学人教版(2023年3期)2023-03-21 00:44:56
自然资源遥感(2022年3期)2022-09-20 08:04:22
北京航空航天大学学报(2022年8期)2022-08-31 08:58:58
安徽农业科学(2019年14期)2019-08-27 04:31:47
自动化学报(2017年2期)2017-04-04 05:14:28
西华师范大学学报(自然科学版)(2016年4期)2017-01-09 08:16:57
中学生数理化·七年级数学人教版(2016年2期)2016-05-30 21:20:57
无线电工程(2016年11期)2016-02-07 02:25:06
中国光学(2015年5期)2015-12-09 09:00:28
新高考·高二数学(2014年7期)2014-09-18 17:20:45
