
基于SSD网络模型改进的水稻害虫识别方法
2020-08-25 07:03单鲁泉
郑州大学学报(理学版) 2020年3期
佘 颢, 吴 伶, 单鲁泉
(湖南农业大学 信息与智能科学技术学院 湖南 长沙 410128)
0 引言
水稻是人类主要粮食作物之一,世界上约一半的人口都是以大米为食。虫害问题严重影响到水稻产量和质量,准确识别害虫种类可以有效揭示虫害灾情的规律,给科学防控措施提供基础数据。如今病虫害的检测基本依靠人工识别,但是虫群数量庞大、种类多,仅仅依靠少量的植保专家并不能有效及时实现对虫害的识别,而害虫通常繁殖周期短、发展迅速,有可能延误最佳的防治时间,导致一系列经济损失[1]。
随着互联网的迅猛发展,图像识别的精度在不断提升,将图像识别技术应用到病虫害的检测中,成为了最新的发展趋势[2]。文献[3]将图像识别中传统的支持向量机(support vector machine, SVM)分类器应用于粮储害虫的检测。魏杨等[4]使用基于候选区域提取的快速区域的卷积神经网络(fast region-based convolutional network method, fast R-CNN)模型对农业害虫进行识别,实现了在复杂背景下进行农业害虫识别,但是识别精度和速度都有待提高。Gassoumi等[5]使用模糊神经网络方法对12种危害棉花作物生长的常见害虫进行分类识别,实现了对害虫的高精度识别,其识别速度仍不能满足大范围的害虫识别。周清松等[6]采用图像识别中的边缘检测方法对粮虫进行目标检测,但该方法对小目标的识别精度较低。
以上研究表明,目前已有的目标检测算法在识别精度或检测速度上难以满足农田环境下农作物病虫识别的广泛性、精准性和时效性等需求。Huang等[7]指出单步多框检测(single shot multibox detector,SSD)在主流的检测算法中,检测速度最快。裴伟等[8]指出SSD在检测精度与检测速度中有很好的平衡性。对 SSD算法进行一些改进是一种较为便捷的方法。
因此,本文使用特征金字塔网络(feature pyramid networks,FPN)模型[9]对SSD算法进行了改进。该模型将最顶层的特征图与前层特征图进行多尺度特征融合,使模型获得更丰富的浅层语义信息,提升小目标的识别率,将批量归一化改为组归一化,减少误差,通过改进的ReLU激活函数提高对模型的拟合度,获取更快的检测速度。
1 改进的SSD算法
SSD算法是一种基于单个神经网络的目标检测算法,采用VGG16为基础模型,在此基础上添加辅助卷积、池化层,从不同层获取特征并进行预测,其中语义会随着层级的加深而更复杂。该算法采用的是faster R-CNN中候选框的方法,在特征提取中设置长宽比不同的4个先验框,相较于faster R-CNN的候选区域,SSD的先验框数量更少,其目标检测速度更快。但SSD算法识别率较低,并且对小目标的识别率不高,时常会出现对同一物体反复检测的现象。
本文在归一化方法、激活函数、SSD网络模型三个方面对SSD神经网络进行了研究和改进,得到一种新的水稻害虫识别方法。
1.1 归一化方法
在机器学习等领域中,需要将训练数据分批输入原始模型,然后不断对模型进行调整得到最终的结果。在这个过程中,每次输入的一批数据规模被称为批量规模(batchsize)。在水稻害虫识别的应用中,输入图像数据很大,选用较大批量规模时会对内存或显存有较高要求,使得应用难以在合理的成本下进行推广。因此,只能使用较小的批量规模实现模型训练。
传统的SSD模型中采用的批量归一化(batch normalization,BN)方法。该方法对较小的批量实行归一化时,由于数据量较少,通过批量归一化产生的估算数据会与实际情况产生较大的误差,并且随着批量的变小,其误差会迅速增大。为了达到减少训练误差的目的,本文采用组归一化(group normalization,GN)实现模型的训练。在模型训练时,数据的维度通常是[N,C,H,W]的格式,其中:N是批量规模;C是对应的通道数;H是特征图的高;W是特征图的宽[10]。使用BN进行归一化,将每个通道的数据单独拿出来进行处理。使用GN进行归一化,则是将信号通道分成多个组,分别将各个组的数据进行归一化,最后合并[11]。GN的数学表达式为
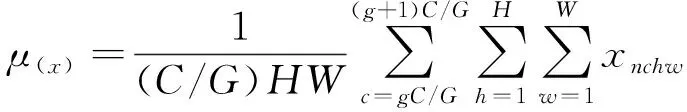
(1)
(2)
其中:G表示将每个特征图的通道分为G组;μ、σ分别表示为均值和标准差;ε是控制梯度下降速度的超参数;R表示特征图的数据维度。从公式可以看出使用GN进行归一化时,是在(H,W)轴上对属于同一个C/G通道的特征值进行均值和方差的计算,而不是沿着通道计算每一个批量的均值、方差。可见归一化的结果与批量规模无关,所以设置较小的批量规模时并不会对训练结果造成影响,而且在批量规模大幅变化时,精度依然稳定。
1.2 改进的激活函数
SSD函数模型采用线性整流函数(rectified linear unit,ReLU)作为激活函数,增加SSD模型的表达能力,使其可以在非线性网络模型中运行。ReLU函数在x≤0时梯度为0。因此,当设置了较大的学习率时,会导致负的梯度在这个ReLU上被置零,则可能出现这个神经元不能被任何数据激活的情况,这种现象被称为神经元死亡[12]。
为了避免神经元死亡现象的发生,不少学者使用参数修正线性单元(parametric rectified linear unit,PReLU)函数,PReLU的数学表达式为

(3)
公式(3)中的α是一个可以通过学习获得的参数。PReLU在x≤0时值不为0,避免了神经元坏死的现象。该函数不仅继承了ReLU激活函数更高效地梯度下降以及反向传播,同时还拥有高活跃度的分散性,使得神经网络整体计算成本降低,同时还避免了使用ReLU函数导致的神经元坏死现象,并且在训练时拥有更快的收敛速度[13]。
本文结合ReLU和PReLU的特点,提出了一种改进的激活函数(TReLU)。数学表达式为
(4)
TReLU函数在x≤0时,不为0,因此可以避免在x<0时出现神经元坏死现象,降低了计算网络参数所需的迭代次数,提高了目标检测的训练速度。同时,TReLU的函数图像在x≤0时是一个非线性曲线,相对于PReLU的线性曲线,非线性函数对输入变化或噪声拥有更棒的饱和性[14],能带来更好的泛化性。随着训练次数的不断增多,使用PReLU或ReLU激活函数的神经网络容易出现损失值不收敛的现象。因此TReLU在x>0的部分设置了一个阈值b。当到达该阈值时,模型不会进行过多的调整,避免出现过拟合的现象。
总的来说,使用TReLU作为激活函数,能使模型更快收敛,减少训练时间。同时,使用TReLU也使得模型的泛化能力更强,不容易出现过拟合现象。TReLU是大规模部署和推广水稻害虫识别方法的有力工具。
1.3 改进的SSD网络模型
传统的SSD算法采用的多尺度预测,虽然提升了识别速度,但没有将不同特征层的特征信息区分开来,不能充分结合上下文语义进行预测。而FPN模型不仅能将浅层细节与高层语义结合起来提高图像的识别率,而且补充的细节信息在一定程度上也能够提高模型的识别精准度,同时FPN对小目标会有更好的特征映射分辨率[15]。因此,本文在FPN模型的基础上对SSD网络模型进行了改进。
传统的FPN模型占用内存大且需要大量的运算,严重影响了计算机运算速度。本文采用SSD+FPN相结合,对网络模型进行了一定的修改:首先,将网络模型中的两个全连接层分别改为卷积核大小3×3和1×1的卷积层;然后,将最后一层池化层的卷积核大小改为3×3,并将步长设置为1;接着,添加了4个卷积层,同时把卷积层中Conv6_2的步长改为1;最后,采用TReLU作为卷积后的激活函数。改进的SSD模型示意图如图1所示。

图1 改进SSD深度学习模型结构Figure 1 Improved SSD deep learning model structure
使用改进的网络模型进行预测的处理过程是:① 卷积层中的Conv9_2直接作为预测层中1×1的特征图;② 依次对Conv9_2、Conv8_2、Conv7_2、Conv6_2、FC7使用1×1卷积降低特征图通道数,再使用双线性插值方法进行上采样处理,通过融合与组归一化得到预测层中3×3、5×5、10×10、19×19的特征图;③ 对FC7、Conv6_2采用双线性插值进行上采样操作,并与Conv4_3融合后进行组归一化,得到预测层中38×38的特征图;④ 使用前述步骤得到的6个特征图构建出一个特征金字塔,通过这个特征金字塔进行预测操作。
2 实验
2.1 实验环境
本次实验使用在Ubuntu16.04 64位操作系统下,使用Tensorflow框架构建改进的SSD神经网络,对测试数据进行验证。进行实验的计算机物理配置为:CPU是Intel Core i7 7700HQ @2.8 GHz;内存为16 GB;GPU是NVIDIA GTX1080Ti。
2.2 数据的采集与构建
数据图像的采集来自于湖南农业大学科研大田实验基地,采用人工方式,通过Sonya57相机在自然环境进行田间拍照,以及捕捉相关样本进行实地拍取,并且通过网络爬虫技术在互联网上获取更多的相关害虫图片。深度学习需要大量的数据集作为依托,为了在后期使模型更好地训练和区分,防止训练过程中因为数据量过少而造成的过拟合现象,采用数据增强的方式扩充了数据集。
本文对采集到的数据进行增加噪音、旋转剪切、改变色差、扭曲特征等操作,将实验数据集扩充至11 568幅图像。
2.3 实验过程
整个实验过程分为三步:数据集划分、模型训练和模型测试。
首先,对数据集进行划分。使用交叉验证方法,将数据集分成了训练集和测试集。其中,训练集包含约8 000幅图片,测试集包含3 568幅图片。我们使用训练集训练网络模型,然后使用测试集进行实验,并对实验结果进行对比。
然后,使用训练集对网络模型进行训练。将激活函数学习率设置为1e-4,正则化权值衰减系数设置为5e-4,学习率衰减因子设置为0.97,当训练完成时得到我们需要的模型。
最后,将测试集放入得到的模型中进行测试实验,并对实验结果进行测试分析。在对结果进行分析时,使用均值平均准确度(mean average precision,mAP)和平均准确度(average precision,AP)作为目标检测评估参数。AP是单个类别下的准确率,mAP是多个类别下的平均准确率。在单类害虫场景中,我们关注AP;在多类别害虫的复杂场景中,我们更加关注mAP。AP和mAP的计算公式为
AP=∑precision/N,mAP=∑AP/M,
其中:precison表示在被判断为准确的图片中,真正判断准确的图像比例;N表示该类别图片总数;M表示类别总数。
2.4 实验结果
使用训练得到的模型对测试集中的图片进行测试。部分识别结果如图2所示。为了验证本文对SSD神经网络模型进行改进后得到的效果,我们还使用传统的SSD对测试集进行了实验,得到了如图2(b)所示的结果。除此之外,为了使对比实验更具有说服力,使用常见的faster R-CNN方法对测试集进行了实验,如图2(a)。

图2 水稻害虫目标检测实验结果Figure 2 Experimental results of target detection of rice pests
从图中可以看出初步的结果,本文所采用的模型算法能更好地识别小目标。当图片中的害虫数目较少时,害虫被检测到的准确率较高;当害虫数目较多时,较大的害虫能够被检测出来,较小的害虫被检测出来的准确率稍微低一些。
2.5 结果分析
根据上述实验步骤与数据,得到SSD、faster R-CNN、改进SSD三种算法在5类常见稻田害虫的AP值,如图3所示。
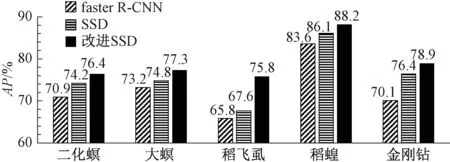
图3 水稻害虫的检测的AP值对比Figure 3 Comparison of AP value of rice pests
在图3中,主要通过AP值去衡量算法的准确性。可以看出,改进的SSD算法对大螟、稻飞虱、稻蝗、金刚钻四种害虫的AP值明显高于SSD算法、faster R-CNN算法,对二化螟的AP值也不低于其他算法。从整体上看,改进SSD算法的AP值为75%~88%,SSD算法的AP值为73%~85%,faster R-CNN算法的AP值为65%~83%。改进的SSD算法在小目标稻飞虱的识别中,AP值比原SSD算法提高约8%。因此,对这五类常见害虫的识别上本文的改进SSD算法完全优于其他两种算法。
表1主要是通过每秒传输帧数(frames per second,FPS)与mAP去综合衡量算法[16]。FPS指标越高,就意味着检测速度越快;mAP值越高就意味着目标检测准确度越高。从表1可以看出,算法经过训练后,改进的SSD模型mAP达到了79.3%,是所有参与测试的算法中表现最好的,且耗费训练时间也是最少的。与常用的faster R-CNN算法、SSD算法相比,改进的SSD算法的mAP值分别提高了6.6%、3.5%,FPS最大提升了8倍。改进的SSD算法在提升FPS值的同时,mAP的值也有一定的提升,在害虫识别上优于主流算法。

表1 不同网络结构下的水稻害虫识别结果Table 1 Recognition results of rice pests under different network structures
3 结论
本文提出的基于SSD网络模型的水稻害虫识别方法大幅度提高了害虫识别的检测速度,并在一定程度上提高了检测的精度,具备更好的性能。通过对水稻害虫检验结果进行分析,可得到以下结论。
1) 从对小目标检测的结果来看,将浅层细节与高层语义相结合,能大幅度提升对小目标识别的精确度,与原有的SSD网络模型相比,在单个种类上AP值的提升最高约为8%;
2) 改进后的SSD算法相对于faster R-CNN、传统SSD算法等在检测准确度上有所提升,测试集的实验结果显示,mAP值分别提高6.6%、3.5%;
3) 从目标检测的速度上看,改进后的SSD算法大幅度提高了检测速度,其每秒传输帧数相比于faster R-CNN增加了26.9帧/秒,相比于原SSD算法增加了9.1帧/秒。
改进后的SSD算法与传统的虫害识别算法相比更高效、更精确。从实验结果得出,该模型检测大目标效果较好,但是对小目标的识别效果还有较大提升空间,且训练网络并不是非常完善,精确度还有待提高,性能仍需改进,这是后期需要研究与改进的地方。
猜你喜欢
建材发展导向(2021年15期)2021-11-05
发明与创新(2021年39期)2021-11-05
北京航空航天大学学报(2021年9期)2021-11-02
好孩子画报(2021年9期)2021-09-26
云南画报(2021年6期)2021-07-28
科学家(2021年24期)2021-04-25
今日农业(2020年23期)2020-12-15
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
