
地球科学知识体系编辑平台
2020-08-24 12:05:20石顺中闾海荣董少春唐小芳周成虎
高校地质学报 2020年4期
石顺中 ,闾海荣 *,董少春,李 艳,唐小芳,周成虎
1. 清华大学 自动化系,北京 100084;2. 福州数据技术研究院,福州 350207;3. 南京大学 地球科学与工程学院,南京 210023;4. 中国科学院 地理科学与资源研究所 资源与环境信息系统国家重点实验室,北京 100101
1 概述
进入21世纪以来,人类社会发展高速进行。以互联网的普及为代表的科技进步,带来了各行业前所未有的井喷式数据(武延军,2013)。而与之而来的海量数据也给存储和检索技术带来的新的挑战。不同于一般的数据,地球科学数据种类繁多、类型复杂、语义关系丰富,使得数据和知识的构建异常繁琐。为了解决上述问题,基于本体的知识图谱构建技术被引入到地球科学大数据的收集、处理和应用中。
1.1 本体
在计算机科学与信息科学领域,本体(ontology)是对概念进行建模的规范,是描述客观世界的抽象模型,并且通过形式化的方式对概念及其之间的联系给出明确定义。本体是同一领域内的不同主体之间进行交流的语义基础(Neches et al.,1991),表达了概念的结构、概念之间的关系等领域中实体的固有特征,即“共享概念化”(张德政等,2017)(例如人是一个本体,小明和小张是人这个本体对应的两个实体,人有性别属性,小明和小张同样也有性别属性)。
对于本体的描述,也需要通过特定的计算机语言来实现。使用标准化语言对本体进行描述,可以避免在不同Web应用程序之间进行转换。其中具有代表性的本体描述语言有:RDF、OIL、和OWL。RDF(Resource Description Framework) 是万维网联盟(The World Wide Web Consortium,W3C) 提出的一种知识表示方式,并用于支持网络上的知识共享与交换。1999年2月,RDF成为W3C 的正式建议模型①W3C, https://www.w3.org/TR/REC-rdf-syntax/。OIL(Ontology Inference Layer)是欧洲科研机构在对于描述逻辑的长期研究基础上建立起来的,其目标是提供对结构化信息的表达和推理支持(Fensel et al.,2001;McGuinness et al.,2002 ;Stevens et al.,2003)。OWL(Web Ontology Language)是W3C为了扩展RDF模式有限的表达能力定义了一种更具表达能力的Web本体语言(Antoniou and Van Harmelen,2004;McGuinness and Van Harmelen,2004)。
本体被广泛的应用于各种领域(Brank et al.,2005),如知识管理、信息提取、语义网和知识图谱等。在知识图谱中,本体规范了知识的概念、属性和关系,通过本体提高知识图谱准确性②Oliveira D, Sahay R, d’Aquin M. Building a Knowledge Graph for Products and Solutions in the Automation Industry. in: Proceedings of the 1st Workshop on Knowledge Graph Building. 2019.。
1.2 知识图谱
知识图谱(Knowledge Graph)是一种基于图的数据结构,由节点和线组成,通过语义关联把各种概念或实体关联起来。在知识图谱里,每个节点表示“概念或实体”,每条线为点与点之间的“关系”。就目前的计算机技术而言,知识图谱是关系的较为有效的表示方式之一(王云才和牛聚粉,2012;熊永兰等,2014)。知识图谱本质上就是一种语义网络(Popping,2003)。

图1 知识图谱发展的驱动Fig. 1 Driving forces for the development of knowledge graph
受数据增长和应用需求的双重驱动,语义网络不断融合了数据链接、文档链接等相关概念和技术,朝着数据知识化的方向不断发展成熟,确立了知识图谱的基本概念(图1),即对语义知识的一种形式化描述框架。2012年谷歌公司宣布它的搜索引擎中加入了知识图谱,旨在实现更智能、高效的搜索引擎(例如用户搜索比尔·盖茨,搜索引擎不仅返回含有比尔·盖茨字符的网页,还会返回图2所示和比尔·盖茨相关的信息)。谷歌的拥抱对知识图谱的兴起起了很大的作用,知识图谱开始被广泛关注。知识图谱从20世纪70年代开始出现在文献中(Ehrlinger and Wöß,2016)。本文通过谷歌学术按年统计了含有知识图谱的英文文献数量(从1970年到2019年),从统计结果可以看到最近10年知识图谱这一概念在各类文献中出现的频次急剧增长(图3),已成为人工智能和大数据等相关研究的重要基础。自2013 年后,知识图谱逐步开始在学术界和工业界普及,并已在智能问答、情报分析、反欺诈等领域中发挥重要作用,是知识服务的重要基础。
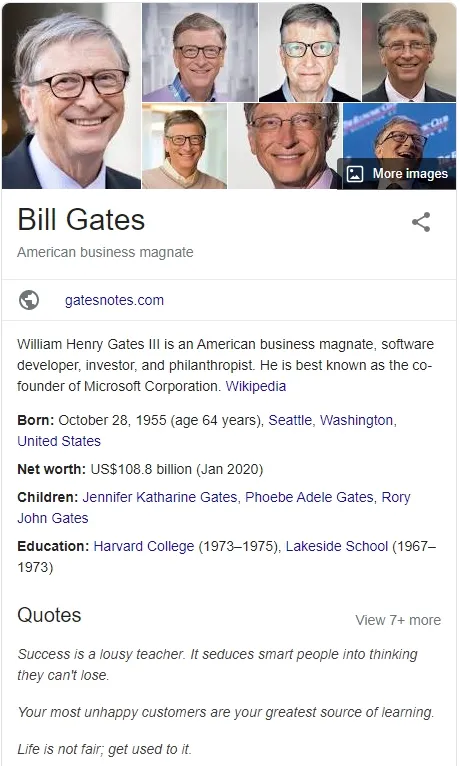
图2 谷歌搜索返回和比尔·盖茨相关的知识图谱数据Fig. 2 Knowledge graph data about Bill Gates displayed on google search
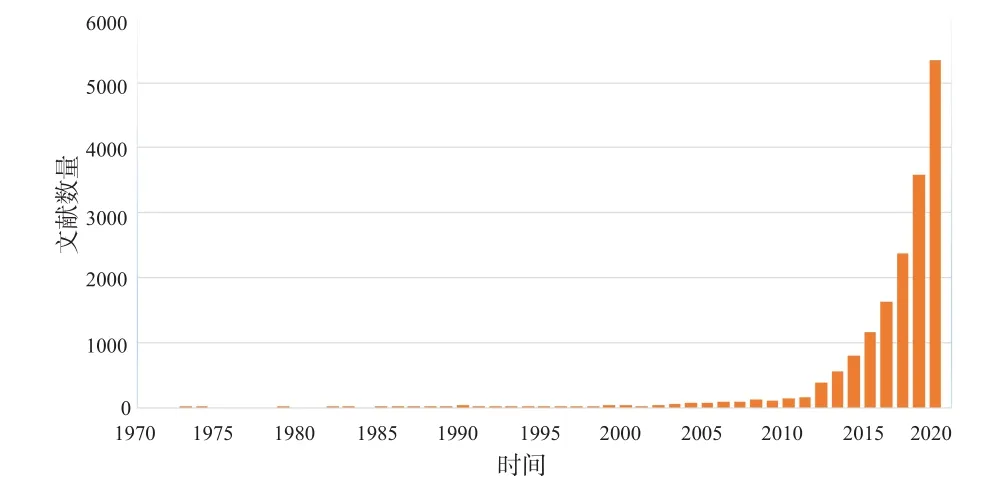
图3 1970~2019年含有知识图谱的英文文献Fig. 3 Number of english literatures containing knowledge graph, 1970-2019
就世界范围而言,目前实体数最多的知识库是Wolfram Alpha知识库,实体总数已超过10万亿条。谷歌第二,拥有5亿个实体和350亿条实体间的关系,并且仍在不断扩大规模。微软的 Probase包含的概念总量达到千万级,是当前包含概念数量最多的知识库。而我们熟知的Siri - Apple等智能助理,正是建立在Wolfram Alpha知识库基础之上的(Christian et al.,2009 ;Wong et al.,2012)。2017年以来,美国逐步将知识图谱的建设提升到新的战略高度,并作为美国一项国家科技战略予以重点推动。例如,美国自然科学基金会(National Science Foundation,NSF)在2019年资助学科融合加速先导项目一共43项(总预算3900万美元),以知识图谱为主题的项目就占到几乎50% (21项),并且表示美国自然科学基金后续还有更大的预算投入。
知识图谱通常可以分为开放知识图谱和领域知识图谱。地球科学知识图谱就是一种领域知识图谱,是对地球科学领域内知识的一种形式化描述框架。目前规模最大的地球科学知识图谱是由美国宇航局地球科学技术办公室(NASA Earth Science Technology Office)主导建设的SWEET(Semantic Web for Earth and Environmental Terminology), 包括7000多个基本概念,涵盖了地球科学的主要研究领域。但该知识图谱仅完成了框架的建设,尚缺乏对主体概念和语义关系的进一步描述。
1.3 基于本体的知识图谱
基于本体的知识图谱是在本体的基础上进行丰富和扩充的(图4),扩充主要体现在实体层面(张德政等,2017)。知识图谱包含本体层和事实层,本体层突出和强调了概念以及概念之间的关联关系,事实层则增加了更加丰富的关于实体的信息。事实层和本体层之间通过语义关系进行映射和链接,使得实体对象以及实体对象之间也能拥有规范的、形式化的语义描述。这种双层结构使得知识图谱能够在基于真实数据(例如大数据)的知识发现中发挥语义翻译和推理的作用,建立了现实世界与机器形式化表达之间的桥梁,成为机器理解的基础。因此,它在很多领域知识图谱的构建中被采纳,比如基于本体的中医知识图谱的构建(张德政等,2017),基于领域本体和自然语言处理技术的非物质文化领域知识图谱建设等(Dou et al.,2018)。
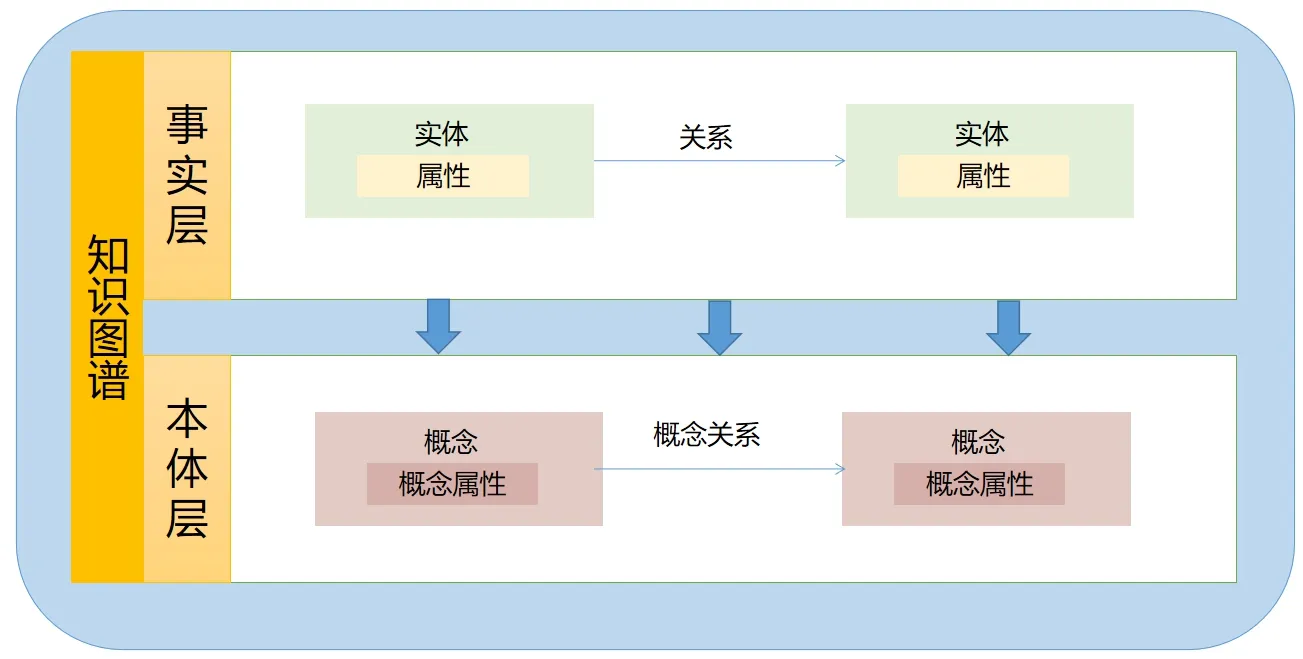
图4 知识图谱和本体关系Fig. 4 The relationship between knowledge graph and ontology
知识图谱的构建大体有两种方式:自顶向下和自底向上。开放知识图谱的本体构建通常用自底向上的方法,自动地从各文本数据中抽取概念或实体,以及它们之间的关系,典型的如Google的Knowledge Vault。专业领域知识图谱多采用自顶向下的方法,即事先规划好需要构建的本体和实体,以保证专业知识的高精确。两种方式也可以混合使用。例如,地球科学知识图谱提供了地球科学领域内最全面的知识描述,涵盖的学科范围包括岩石学、古生物学、矿物学、构造、古地磁、地质年代学、地球化学、石油地质学、地热学等。为保证概念和相互关系表达的准确性、系统性和完整性,地球科学知识图谱的构建前期采用自顶向下的专家主导建设为主,后期采用文本自动提取、知识融合等技术补全。
2 已有知识体系编辑工具调研
随着本体在知识工程、知识图谱等领域的广泛应用,构建实用本体的重要性愈加突出。而本体的构建离不开本体编辑工具的支持(张欢欢等,2005),本体编辑工具主要是用于本体的创建、存储和重用等,目前有很多本体编辑工具:Ontolingua、OntoSaurus、Protégé、WebODE、OntoEdit、OilEd、WebOnto、TopBraid Composer 等(Lambrix et al.,2003;Roche,2003;Morbach et al.,2007)。这些工具既有商业版本,也有开源免费版本。本文把本体编辑工具也叫做知识体系编辑工具。下面分别对其中几种系统进行介绍。
2.1 Protégé
Protégé是斯坦福大学医学院生物信息研究中心开发的一款开源免费的本体编辑工具(Noy et al.,2001;Eriksson,2003;Gennari et al.,2003;Jain and Singh,2013 ;Musen,2015)。Protégé得到学术团体、政府和企业用户社区的支持,这些用户使用Protégé在生物医学、电子商务和组织建模等领域构建了基于知识的解决方案。
Protégé是一个桌面软件,包含 Mac、windows和Linux三个版本,到目前为止,最新版本为v5.5.0,界面风格如图5所示。Protégé支持概念类、属性和实例创建,支持多重继承。用户不用关心本体描述语言,只需在概念层次上进行领域本体模型的构建,系统可以自动生成RDF格式文件。
Protégé是 桌 面 软 件, 不 利 于 多 人 协 作。WebProtégé是其网页版本,主要功能和 Protégé相似,可以在站点(https://webprotege.stanford.edu/)体验使用。WebProtégé也是开源,可以下载编译部署到私有机器上。
2.2 TopBraid Composer
TopBraid Composer是TopQuadrant公司开发的商业应用程序,用于构建本体和开发语义应用程序(Horrocks,2007 ;García-Peñalvo et al.,2012 ;Alatrish, 2013)。TopBraid Composer支持本体编辑、知识库的建立、管理以及测试,支持W3C规范,支持多种视图,支持不同格式数据导入。
TopBraid Composer支持W3C标准RDF、OWL Web本体语言、SPARQL查询语言和语义网规则语言(SWRL)。Composer可用于编辑各种格式的RDFS/OWL文件,还提供可伸缩的数据库后端(AllegroGraph、Jena、Oracle 11g和Sesame)以及多用户支持①https://franz.com/agraph/tbc/。
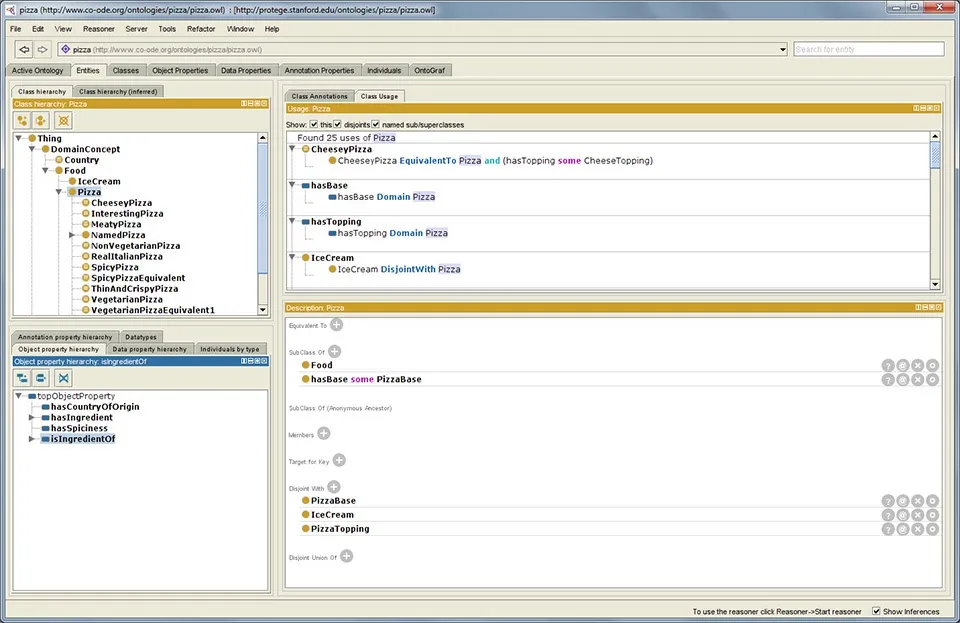
图5 Protégé软件截图① https://protege.stanford.edu/assets/img/screenshots/desktopprotege-screenshot-3.jpgFig. 5 The screenshot of Protégé
Composer提供了一组全面的特性,涵盖了语义应用程序开发的整个生命周期。除了作为一个完整的本体编辑器之外,Composer还可以作为运行时环境来执行规则、查询、推理程序。基于Eclipse,还可以使用定制的Java插件对Composer进行扩展,使得在单一平台上快速开发语义应用程序成为可能。TopBraid Composer的语义网应用程序集成开发环境如图6所示。
2.3 OilEd
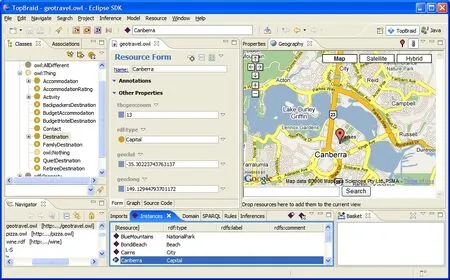
图6 TopBraid Composer的语义网应用程序集成开发环境② https://franz.com/agraph/tbc/TBC-Geography.pngFig. 6 Integrated development environment for semantic web applications in TopBraid Composer
OilEd是一个由曼彻斯特大学计算机科学系信息管理组构建的基于OIL的本体编辑工具,允许用户使用DAML+OIL构建本体(Bechhofer et al.,2001;Stevens et al.,2002a,b,2003 ;杜文华和董慧,2005)。OilEd是一个开源的项目,目前已停止维护和更新,不过用户还可以到站点(http://oiled.semanticweb.org/index.shtml)下载使用。
由于OilEd的最初意图仅仅是提供一个简单的编辑器,用于演示对OIL语言的使用,并激发了人们对OIL语言的兴趣。因此,OilEd的当前版本并没有提供一个完整的本体开发环境,即该编辑器无法支持大型本体的开发、本体的迁移集成和许多其他涉及本体构建的活动。相反,它是本体编辑器的“记事本”,提供了足够的功能来支持用户构建本体,并演示如何使用事实推理器来检查那些本体的一致性(孙瑾,2006)。OilEd软件界面如图7所示。
3 地球科学知识体系编辑工具的需求
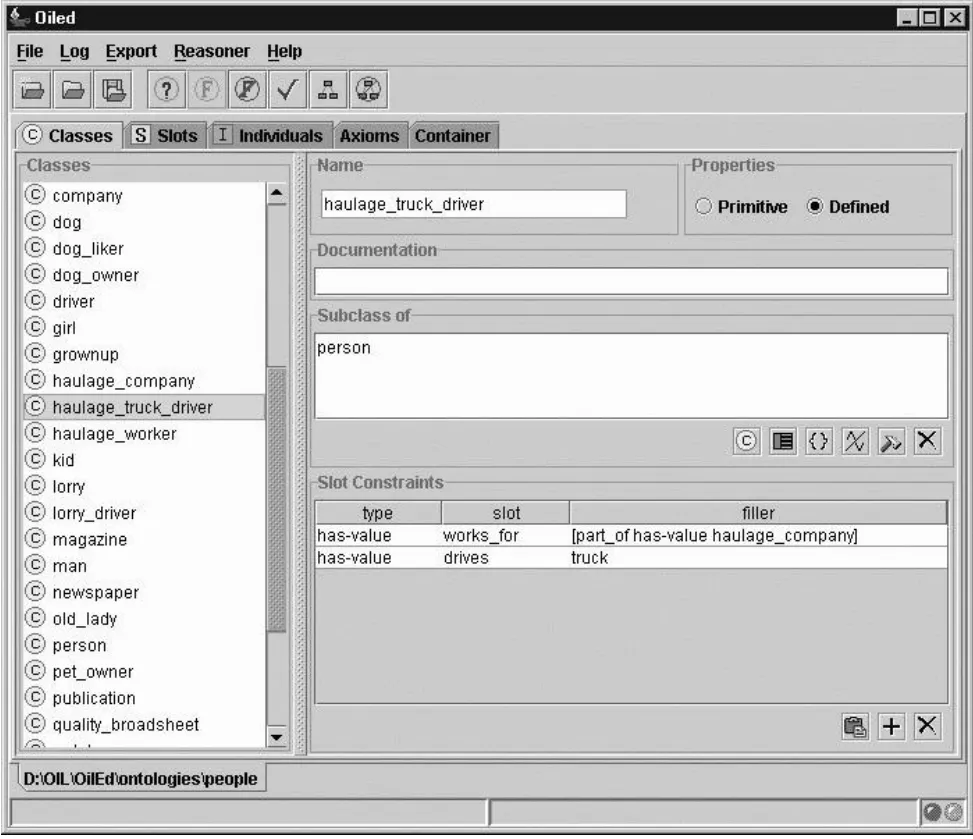
图7 OilEd软件界面(Bechhofer et al.,2001)Fig. 7 The screenshot of OilEd (Bechhofer et al.,2001)
尽管国内外覆盖整个地球科学领域的地学本体模型和知识图谱尚属空白,但地学领域本体模型的建设(如石油化工、地质年代学、水文地质、构造地质、地理空间等领域)已经积累了丰富的经验,形成了领域专家和机器自动识别方法相结合的建设思路。由于地球科学知识图谱涉及的学科门类多,内容广,知识点众多,学科内部知识点描述差异大,因此对知识体系编辑工具提出了更高的要求,除了必须具备描述标准化、存储结构化,操作简单化以及结果可视化之外,还需要满足以下几方面需求。
(1)在普适性和个性化需求之间达成平衡
地球科学知识图谱涉及的学科门类众多。这些学科的知识点既具有共性特征,又具备各自的特点。目前没有一套元数据标准规范能够适应地球科学所有分支,同时又能体现不同学科的特殊需求。因此需要建立一种灵活的描述方案,能够在普适性和个性化需求之间达成平衡,既满足地球科学各个分支学科的基本要求,同时又能兼顾各学科的不同需求。
(2)支持多用户同时在线编辑
由于地球科学知识图谱涉及的学科门类众多,仅仅依靠某个机构或个人的力量是难以完成这一庞大的建设工作的,需要多学科专家共同参与建设,因此编辑系统必须允许多用户协同编辑,才能支持知识图谱的高效建设。
(3)去专业化程度要求高
现有知识图谱建构工具对图谱建设人员要求较高,必须具备本体标准化语言的背景。然而大部分地球科学专业人员并不了解本体及其标准编码的基本要求,需要花大力气进行培训。而短时间培训无法使众多专业地球科学人员充分理解本体建模语言的要求,难免存在理解上的偏差,在分布式协同构建地球科学知识图谱时难以实现统一,为知识图谱的集成带来新的困难。因此地球科学知识图谱的建设工具必须满足去专业化的要求,即对地球科学专业人员屏蔽知识图谱建构的专业背景要求,使得建设人员在零培训或较少培训的基础上就能进行图谱的建设工作,最大限度的实现录入简单化,标准统一化,分布式协同工作高度可集成以及操作结果可视化等要求。
(4)具备特殊符号的在线显示和编辑功能
地球科学很多概念和过程涉及复杂的数学公式、化学结构式、同位素比值等内容。例如地球物理学、数学地质、水文地质学等学科有大量基础概念和知识点需要结合公式进行阐述。矿物学、地球化学等学科有大量分子式、同位素需要通过上下标表示(例如TiO2、87Sr/86Sr等)。此外,还有一些学科的知识点描述中对字体有特殊要求(例如有些古生物名称需要以斜体显示)。这些特殊的表示方式或显示需求在现存的知识体系构建工具中无法满足,使得概念的准确表达受到极大的限制,在录入、检索、可视化和存储等方面都造成了困难。
(5)支持多种可视化浏览和检索方式
地球科学知识图谱包含对地球科学领域知识及其相互关系的全面、清晰、明确的形式化描述,具有科学性、系统性和规范性,能够在不同层面上满足各类用户对地球科学知识的需求。除了为机器理解提供数字化、结构化的知识体系以外,也可以成为科普、教学和科研人员的知识库。目前的知识图谱建设工具大多以机器服务为主,为公众提供地球科学基本知识浏览和检索、为教学、科研提供专业术语解析等方面的功能较弱,需要提供灵活多样的可视化浏览和检索能力,使得不同需求的用户能够方便查阅知识图谱中的内容,充分发挥知识图谱满足不同层面需求的特点。
(6)在线审核功能
地球科学知识图谱要得到国际广泛认可,需要进行严格的同行审核,而审核过程最好也能在知识体系编辑工具内进行,以保证同行评议公开、透明,接收更多监督和意见,同时又方便知识图谱建设者根据审核结果在线协同修改,提高审核和修改的效率。
(7)对多角度建立的知识图谱进行融合和集成
由领域专家通过自顶向下方式建立的知识图谱奠定了知识图谱的整体框架和大部分概念,而知识图谱的完善还需要通过从大量文本、数据中自动提取,以自底向上的方式进行知识融合和补全。对两种不同视角和方式建立的知识图谱进行实体对齐、消除歧义、进行复杂语义关系的推理和演算,实现知识更新是建立健全知识图谱的重要功能。
目前通用的商业和开源知识体系构建工具均难以满足上述需求,因此需要定制开发适合地球科学知识图谱在线协同编辑、检索、存储、可视化和导出的一体化系统,并且具有灵活的可扩展能力,以适应地球科学知识图谱的建设以及更新维护的需求。
4 地球科学知识体系编辑平台
为了满足地球科学知识体系构建的需求,作者设计并实现了一种地球科学知识体系在线编辑平台——“地球科学知识体系编辑平台”(以下简称系统,图8)。系统不仅支持协同本体编辑、属性继承、多种显示和检索、Word/Excel/RDF导出等需求,还具有图文编辑、不同学科个性化逻辑处理、特殊符号处理、协同审核等定制功能。系统可为建设者、审核人员、普通用户和管理员分配不同的权限。建设者可在零培训或极少培训的基础上协同进行地球科学知识图谱建设,审核人员可以方便进行在线协同审核。平台支持中英文两个版本,可以在两种语言中自由切换。
4.1 总体框架
地球科学知识体系编辑平台以Web服务形式向用户提供服务,采用前后分离开发模式。系统从底到上大致分为4层:存储层、业务层、控制层、应用层,总体框架如图9所示。
存储层主要负责知识体系数据、用户信息、用户操作日志等信息存储,采用主从备份保证数据安全。业务层是系统核心部分,系统的主要逻辑都在这层实际,比如本体编辑、属性继承、数据检索、文档生成等。控制层主要是负责接入安全控制,知识产权保护,包含用户身份验证、权限控制、反爬虫控制。应用层是最上面一层,是系统直接面向用户的一层。
系统通过Docker容器化实现快速部署和扩展。根据实际情况,系统可以快速单机部署,也可以进行多点部署提高系统稳定性和安全性。
4.2 功能模块
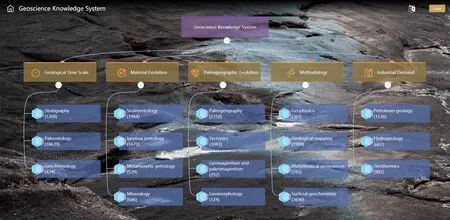
图8 系统主页面Fig. 8 System main surface
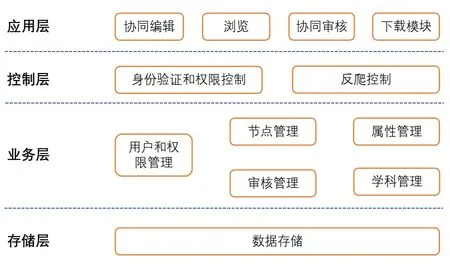
图9 系统总体框架Fig. 9 General framework
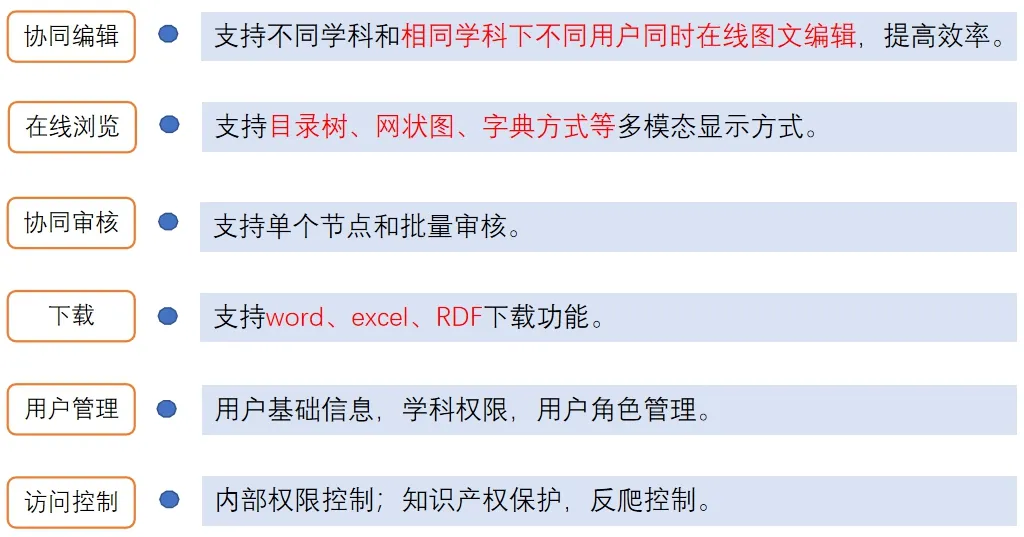
图10 系统主要功能Fig. 10 Main functions of the system
系统主要功能如图10所示,涵盖了知识点编辑(录入、删除和修改)、显示和导出(即下载)功能,在线审核、用户管理和访问控制四大核心功能。
系统除了基本知识编辑功能外,具有如下显著特点:
(1)定制核心元数据描述集和扩展属性描述
针对地球科学不同学科门类知识点描述的共性特征和个性化需求,参照都柏林核心元数据集和CGI制定的GeoSciML元数据标准,为地球科学知识图谱的知识点及其相互关系设计了核心元数据描述集,用于体现地球科学各学科的共性特点。同时为了满足不同学科的个性化特征,系统允许用户为不同学科的节点创建自定义属性,以体现各学科对知识节点描述的特殊需求。
(2)支持多用户同时在线编辑
本系统采用Web服务方式,服务端进行并发控制、特定操作的原子性控制、编辑目录异步加载控制等措施,支持不同学科和相同学科下不同用户同时在线图文编辑,方便分散在不同地区的专业人员协同工作,大大提高了工作效率,为快速、高效建立地球科学知识图谱提供了保障。
(3)操作简单易学,无专业背景要求
系统所有操作均采用所见即所得的方式,编辑和审核操作设计友好,简化和屏蔽了绝大多数知识图谱的专业概念。界面简洁清晰(图11),不管是建设者还是审核人员都可以在零培训基础上快速上手,具有很强的推广性和实用性。
(4)支持特殊符号的显示和编辑
系统统一采用Unicode字符编码,处理特殊字符。前端显示则采用html语法,方便特殊格式(例如上下标、斜体等)的显示。导出成Word或Excel格式时会通过API设置成相应格式,可以满足地球科学各学科对特殊符号的要求。
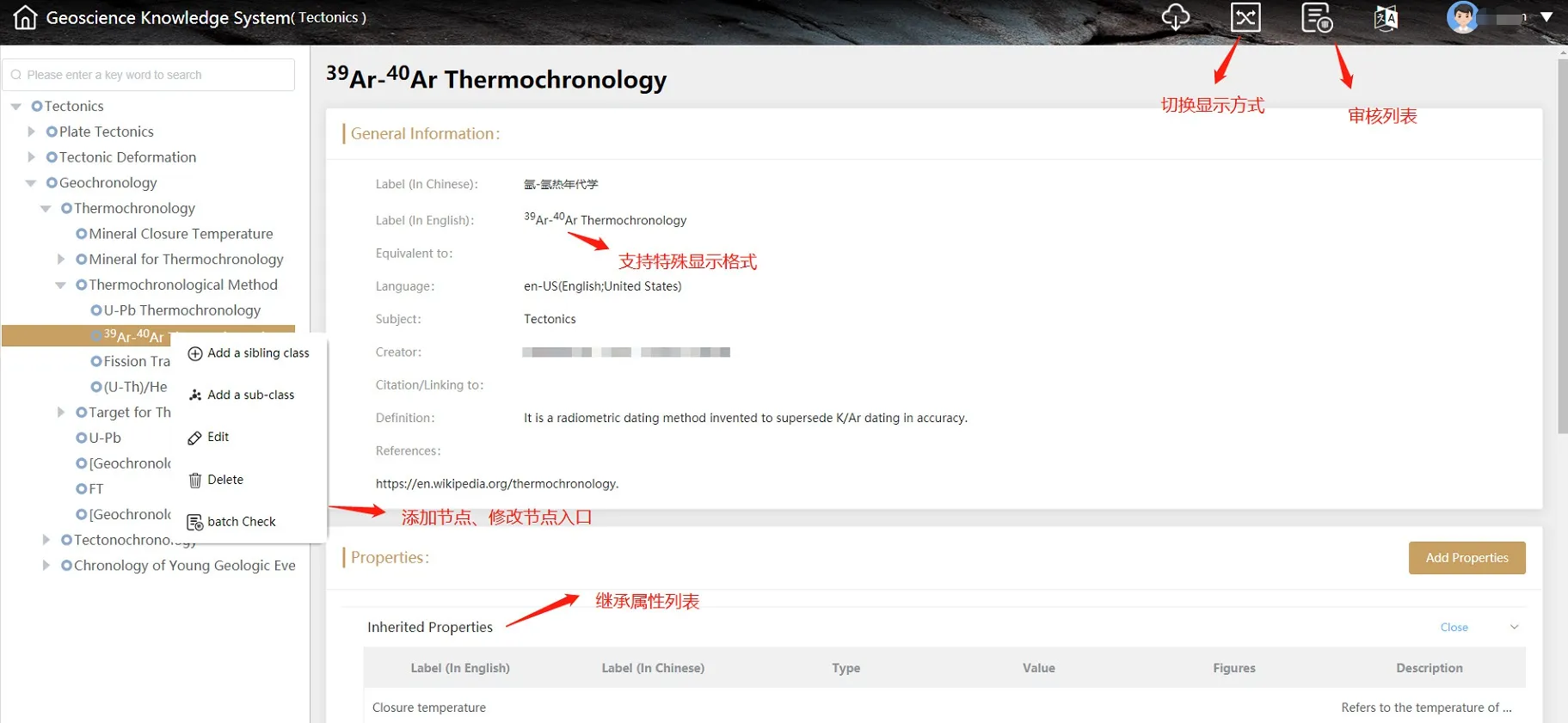
图11 系统录入界面Fig. 11 System input surface
目前支持特殊格式:Unicode所有字符(万国码,支持世界各个语种,例如阿拉伯语、法语等)、粗体、斜体、下划线、上标、下标、删除线、列表。特殊符号和格式示例:“A2+B2= (A+B)2-2AB”、“TiO2”、“Genus Rosobolus Havlíček, 1982”。这些示例,系统都可以支持。
(5)提供灵活多样的可视化浏览和检索方式
系统提供了目录树(图12)、字典(图13)和网状图(图14)三种可视化方式。在目录树浏览方式下,知识节点以树状结构显示,知识点之间的层级关系一目了然。在字典浏览方式下,所有知识点按首字母排序,交互简洁。在网状图浏览方式下,知识节点按照层级关系呈网状组织,显示时鼠标点击节点可以逐级展开子节点,双击可以查看节点详情,鼠标可以拖拽单个节点或整个网状图,鼠标滚轮可以放大缩小网状图。三种可视化浏览方式均提供了相应的检索功能。
(6)在线审核功能
审核用户登入系统后,可以对授权学科的知识点进行在线或离线审核。系统既支持逐个知识节点的审核,也可以批量对多个知识节点进行审核。建设者可以在系统上查看所有审核者的意见,并且对审核意见进行处理和回复。整个审核过程在系统中都有详细的记录,对审核人和建设者都是透明和公开的。审核意见和回复意见都提供了导出功能(例如导出成Word或Excel格式),以便形成正式的审核报告。
4.3 和已有工具对比
地球科学知识体系编辑平台和其他工具从下面几个方面对比(表1):文字的输入和符号的支持,多语言的支持,数据可视化,协同编辑,协同审核等方面。

图12 目录树显示方式Fig. 12 Browsing in the tree mode

图13 字典显示方式Fig. 13 Display in the dictionary mode
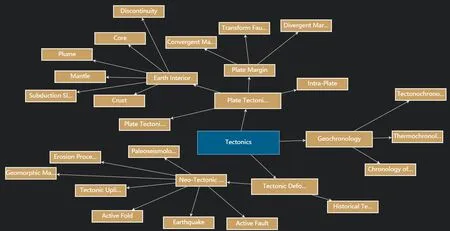
图14 网状显示模式Fig. 14 Display in the mesh mode

表1 各个工具对比Table 1 Comparison of various tools
4.4 使用效果
在系统上线之前,地球科学领域专业人员尝试使用其他工具来构建地球科学知识体系,但是这些工具存在这样或那样问题:各个学科没法集成,不支持图片和特殊符号,不支持协同审核,学习成本太高等。导致地球科学知识体系构建工作推进缓慢,甚至某些学科没法推进。
系统上线之后,地球科学领域专业人员借助系统进行地球科学知识体系构建。地球科学的18个分支学科专业人员进行在线协同编辑,在一个月之内就创建近4万个节点。目前规模最大的地球科学知识图谱SWEET才包含7000多个节点,而本系统在短时间内沉淀的节点数是SWEET的好几倍,本文系统极大提高了地球科学知识体系建设效率。
5 总结和展望
本文对知识图谱及知识体系构建工具进行了梳理,针对地球科学知识体系的需求设计并实现了定制化的专业编辑平台,提供了在线协同编辑、灵活多样的显示方式以及在线审核等定制功能,最大限度地满足了地球科学知识体系的建设需求。
地球科学知识体系编辑平台上线以来,共有包括岩石学、古生物学等18个地球科学分支学科的领域专家在线协同编辑,在很短的时间内就建立了近4万条知识节点和相互关联。这些内容初步形成了规范化和标准化的地球科学知识图谱描述框架,为机器理解打下了基础,为文本自动提取、知识融合等提供了可能。同时,系统支持多种友好的浏览和检索方式,可以成为科普、教学和科研人员的开放共享知识库。
地球科学知识图谱的建设是一项大工程,为进一步完善地球科学知识图谱,并充分利用知识图谱进行知识探索和发现,真正服务于地球科学相关领域的研究,地球科学知识体系编辑平台还需要从下面几个方面进行拓展和完善。
(1)实现知识融合和补全
地球科学知识图谱的前期建设主要通过领域专家主导的方式进行,领域专家借助地球科学知识体系编辑平台对领域内的主要知识点和简单语义关系进行了标准化描述。但是知识完善还需要加入知识自动提取方式,并且融合人工方式和自动方式两种方式生成的知识。因此系统需要支持排歧、去重、复杂语义关系的识别与描述、知识融合、推理和演化等,还有待OCR、自然语言处理、多模态融合等多项关键技术的参与,才能实现地球科学知识图谱的进一步完善。如何在系统中实现两种不同方式建立的知识图谱的融合是下一步工作的重点之一。
(2)完善多模态知识图谱建设的功能
编辑系统对于多模态知识图谱的建设还需要在数据组织、人机交互、可视化等方面进一步加强,以完善对于复杂科学公式、地质过程示意图等的支持,以增强地球科学基本概念和知识之间的逻辑和语义表达能力。
(3)分布式可信知识保护和安全共享
通过引入自主研发的数据共享平台SOLAR(Smart Online Limbic Architecture Renaissance),充分利用区块链、多方安全计算、同态加密等技术全程追踪知识生成、质量评估、贡献评估、知识产权保护和安全共享,对地球科学知识图谱的网络共享与安全保护提供服务。
(4)多方协同知识发现
随着平台的不断发展和完善,在分布式存储和计算系统的支持下,进一步融合协同学习、知识推理、联邦学习、链式学习等多项技术,通过多方协作机制进行知识发现,基于地球科学知识图谱和大数据对地球科学领域重大科学问题进行探索,必将深化地球科学的认识和研究。
猜你喜欢
哲学分析(2023年4期)2023-12-21 05:30:27
少先队活动(2020年12期)2021-01-14 01:47:40
中国音乐学(2020年4期)2020-12-25 02:58:06
开放教育研究(2020年2期)2020-03-31 01:54:14
中成药(2017年3期)2017-05-17 06:09:01
领导科学论坛(2016年9期)2016-06-05 14:59:58
现代语文(2016年21期)2016-05-25 13:13:44
文学教育(2016年27期)2016-02-28 02:35:15
大连民族大学学报(2015年2期)2015-02-27 08:28:11
卷宗(2013年6期)2013-10-21 21:07:52
