
古生物学数据库现状与数据驱动下的科学研究
2020-08-24 12:05:16邓怡颖樊隽轩史宇坤鲁铮博
高校地质学报 2020年4期
邓怡颖,樊隽轩,王 玥,史宇坤,杨 娇,鲁铮博
1. 中国科学院 南京地质古生物研究所,南京 210008;2. 中国科学技术大学,合肥 230026;3. 内生金属矿床成矿机制研究国家重点实验室,南京大学 地球科学与工程学院,南京 210023;4. 美国佐治亚理工学院,亚特兰大 30332;5. 南京大学 地球科学与工程学院,南京 210023;6. 大陆动力学国家重点实验室,西北大学 地质学系,西安 710069
1 前言
古生物学是了解地球和生命历史的基础学科,古生物化石是地质历史中地球表层的生物及环境信息的重要载体,也是深时数字地球(Deeptime Digital Earth,DDE)大数据建设的重要组成部分之一。进入信息时代后,如何整合海量古生物学数据,并借助高速发展的计算机技术进行数据的深度挖掘和分析,开展数据驱动下的古生物学研究逐渐成为了热点(Miller and Foote,2003;Alroy et al.,2008;Miller et al.,2009;Darroch and Wagner,2015;Fan et al.,2020)。一些核心数据库的建立与重要研究成果的发表,促使各国学者愈发重视古生物学数据的收集、整理、分析与共享,并依此建立了不同类型、不同功能或针对不同门类的古生物专业数据库。
古生物学数据,广义上包括了化石数据以及与之关联的地层学、古生态学、古地理学等信息。从数据来源来看,则主要是以化石为核心的野外标本采集数据、实验测试数据、解释数据等。其数据类型丰富,获取方式差异显著,保存形式多样。其中,野外标本采集数据主要包括化石标本、化石分类单元初步鉴定信息、剖面名称、地理位置、采集层、标本号等。实验测试数据通常以常规实验手段,如化石拍照、标本度量、光片和薄片磨制等获取的数据为主,近年来随着一些新的实验技术手段的出现,通过Micro CT、3D扫描等成像技术获取的数据也开始快速增长。此外,基于野外观察和室内分析,还可进一步获取古生态、古地理、古气候等方面的解释数据。此外,还有一类非常重要的信息,即文献信息和数据贡献者等。这类信息,即数据来源信息,为数据库管理者或用户进行数据质量控制,如判断数据可靠性,对数据做进一步加工以提升其数据质量等,提供了重要的参考信息。
古生物学数据库是古生物工作者基于计算机技术和网络技术,将古生物学数据数字化后以特定的方式整合、集成而得到的专业数据系统。古生物学数据库的发展历史可以大致分为3个阶段,即思想萌芽阶段、数据奠基阶段和高速发展阶段。(1)思想萌芽阶段(19世纪末):Phillips(1860)基于英国的化石数据集绘制出第一条种级多样性曲线,是可追溯的最早的古生物学数据库思想与分析实例。(2)数据奠基阶段(19世纪末至20世纪80、90年代):此阶段发展起来了一批具有系统编目性质的无脊椎、脊椎动物化石名录资料,例如,美国古生物学家J. J. Sepkoski建立了全球显生宙海洋动物科级化石纲要,收集了全球4000余个科级化石的数据(Sepkoski,1982,1992);The Bibliography of Fossil Vertebrates一书中系统整理了北美洲脊椎动物化石目录(Hay,1902);The Fossil Record数据库致力于生命史研究,系统整理了原生动物、植物和动物的大量化石记录(Harland,1967;Benton,1993)。(3)高速发展阶段(20世纪末至今):随着计算机技术的发展,同时在前期基于编目数据库获得的重要进展的推动下,在多个国家开始涌现出了大量优秀的古生物学数据库,百花齐放,典型的例子就是美国的Paleobiology Database。这些功能强大的数据库的出现,为系统分类学、生物宏演化、形态演化和古生态学等领域的科研突破和学科变革贡献了不可磨灭的力量。可以预见,在不远的将来,随着计算机、互联网技术的进一步发展,加上各种大数据分析、人工智能等技术手段的快速普及和应用,古生物学数据库的建设将进入一个新的阶段,个别大型数据库的影响力日益增长,其他技术实力较弱、经费不稳定、高端成果匮乏的数据库将被合并或自然消失,因此如何整合或协同已有数据库,建设开放、共享的古生物大数据平台将成为古生物学领域的重要议题之一。
数据库通常是基于计算机的一种数据管理方式。由于研究目的的不同,科学数据库存在明显的多源异构的特点,数据来源复杂,类型多样,结构各异,规模不等。前人提出古生物学领域的数据库可分为四种类型:古生物学各门类系统分类学数据库,生物事件地层数据库,生物古地理、古生态、古气候信息数据库,以及古生物学文献数据库(尚庆华,2004)。笔者认为前两类数据库可归为一个大类,本质上都是基于野外数据和实验数据而设计的古生物学数据库,或侧重于化石系统分类学特征,或侧重于生物地层学信息。专门针对生物古地理、古生态、古气候等解释性数据建设的数据库比较少,多依附于具体项目或者科学计划,不以在线或公开的方式存在,通常随着项目结束而终止,仅存储在科学家的电脑中。20世纪80、90年代,各学科还存在一些具备较大影响力的文献数据库甚至定期出版物,如中科院南京地质古生物研究所出版的《古生物学文献》,但随着最近二十年互联网技术尤其是搜索引擎的迅速发展,在线文献资源快速增长,一些大型的跨领域甚至全领域文献数据库和相关共享技术的涌现,如Elsevier、PubMed、谷歌学术以及针对数字资源共享的数字对象标识符(DOI)等,各学科领域通常不再建设单独的文献数据库或文摘,文献信息多作为附属信息,以基础描述信息为主,用以指示数据来源。
古生物学数据库处于全新的发展阶段,计算机技术、互联网技术以及大数据驱动下衍生的多种古生物学分析方法的不断发展,促使古生物学数据库具有更加广泛的科研辅助潜力,应用规模不断增长,并创造更多的科学和应用价值。有鉴于当前古生物数据库快速发展的需求,本文将全面介绍国内、外古生物学数据库建设情况,包括其数据组织和管理方式,主要在线功能尤其是一些强大高效的数据可视化和分析工具,数据共享特点等,并简要介绍数据驱动下古生物学领域的典型科学研究案例,希望能为建设多学科融合、数据开放与共享的古生物学大数据平台提供参考。国内、外针对古脊椎动物建设的数据库或数据资源也较为丰富,依托其开展的科学成果颇丰,具体可参见潘朝晖、朱敏(本刊),因此本文不再赘述。
2 古生物学数据库建设情况
笔者调研了全球上百个古生物学数据库,从中遴选出最具代表性、相对活跃的十余个进行介绍,重点关注其建库目的、发展历史、现有数据量、数据类目、数据表结构设计以及主要功能模块等信息。根据这些数据库的性质,将现有数据库划分为国际大型数据库、国家主导或区域为主体的中型数据库和小型数据库三类,其中小型数据库还可以进一步细分为科学问题导向的数据库、面向单个化石类群的数据库以及专用型数据库。
2.1 国际大型数据库
此类数据库通常由国际组织或国际性大科学计划支持,具有相对比较稳定的持续资金支持和团队支撑,具有数据规模大、数据涵盖面广、数据质量高、知名度高、科研成果产出丰富等特点。
2.1.1 PBDB古生物学数据库
古生物学数据库PBDB(Paleobiology Database,https://paleobiodb.org/)是最具代表性的古生物领域的科学数据库之一,该数据库启动早、数据量大、数据质量把控严格、应用广泛,目前已经产出365篇标注科研成果。PBDB最早的建设思路源于Sepkoski建设的面向显生宙生物多样性分析的海洋动物数据库,基于该数据库,Sepkoski等人初步建立了地质历史中生命演化的宏观规律,并识别出五大灭绝事件(Sepkoski,1979,1984)。由于Sepkoski数据库的信息非常简单,仅包含了化石分类名(科和属)及其延限(首现和末现),可支持的分析非常有限,因此,为了进一步探索生命演化的详细过程与机制,以John Alroy、Arnie Miller、Steven Holland等人为首的国际团队,于1998年创建了PBDB数据库,并获得了美国国家生态分析与综合研究中心(National Center for Ecological Analysis and Synthesis,NCEAS)资助的“显生宙海洋古动物学数据库计划”,从1998年8月持续支持到2000年8月。此后,PBDB主要依靠美国国家科学基金会(US National Science Foundation)、澳大利亚研究委员会(Australian Research Council)以及分散在全球的研究团队或个人的项目资助进行维护和持续更新。
该数据库致力于为研究者提供基于采集记录(collection-based)的各门类化石的全球产出记录和分类学信息,以最终促成数据驱动下大尺度的古生物学重要科学问题的解决。但是,由于该数据库在设计之初未重视地层学信息的重要性和完整性,仅聚焦在古生物、古地理与古生态领域,因此导致其数据的应用存在一定的局限性。PBDB的核心模块是化石产出记录(occurrences)和分类学数据(taxonomy)这两部分(图1a),参考文献(references)和贡献者(contributors)各具有独立的数据表,并与其他数据表建立关联,作为数据来源或贡献来源。化石产出记录基于采集记录整理,因此一个露头剖面或钻井中如果有十个采集层均采集到某个化石,则对应到数据库里就是十条化石产出记录。化石产出记录中包含了产地与层位信息、地质年代信息、化石埋藏特征、古环境信息和基于化石的度量信息等,但是不包含直接的系统分类关系,系统分类信息动态存储于分类学数据模块中。PBDB中分类学数据模块包括两个组成部分:权威分类命名(authorities)和观点(opinions)。通过特定工作流实现系统分类关系的动态构建,使得每位贡献者添加的观点可以客观地、动态地反映在数据库中(Peters and McClennen,2016)。在发展过程中,PBDB也整合了一些较老的数据库如Sepkoski海洋动物数据库等。截止2020年4月,PBDB数据库已集成了415423个分类单元,72012篇专业文献,收集了来自208753条采集记录的1463833条化石产出记录,包含772486条观点信息,共410位研究者参与了数据贡献。PBDB网站上开发了PBDB Navigator这一网络应用界面(https://paleobiodb.org/navigator),提供数据可视化、古今地理投点、多样性曲线绘制和数据下载等功能(图1b)。
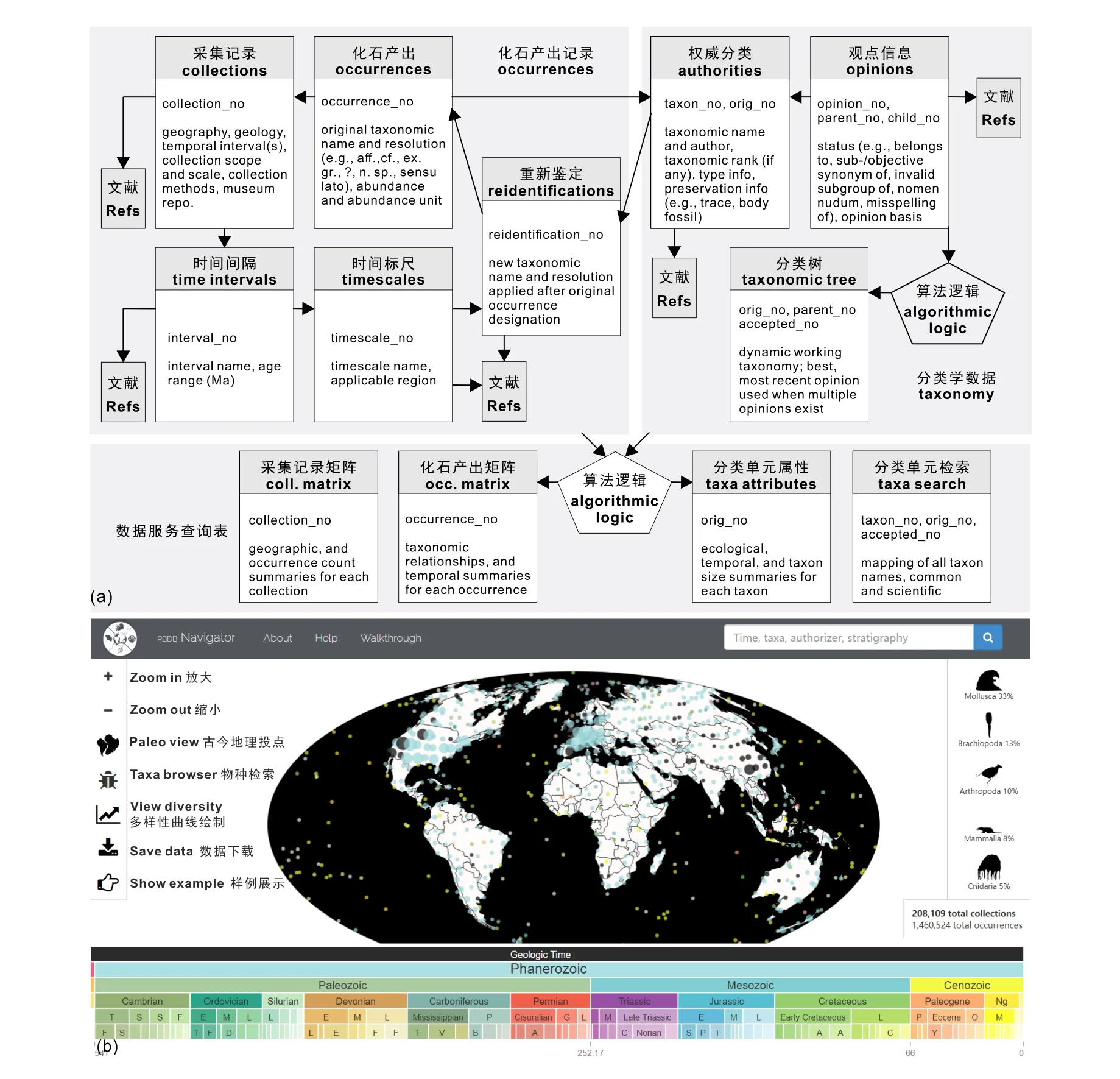
图1 PBDB数据表结构(a)(改自Peters and McClennen,2016)和PBDB Navigator网络应用界面(b)Fig. 1 The architecture of PBDB(a)(revised after Peters and McClennen,2016)and interface of PBDB Navigator web application(b)
2.1.2 Neptune(NSB)微体化石数据库
Neptune是基于深海钻探计划(Deep Sea Drilling Project,简称DSDP)和大洋钻探计划(Ocean Drilling Program,简称ODP)所取得的成果建设而成的数据库,其中收录了DSDP和ODP相关出版物中的所有微体化石产出记录,后期也逐步集成了综合大洋钻探计划(Integrated Ocean Drilling Program,简称IODP)和国际大洋发现计划(International Ocean Discovery Program, 简 称IODP)的古生物学数据,涵盖了硅藻、有孔虫、钙质超微化石、放射虫和沟鞭藻等主要化石类群。目 前Neptune Sandbox Berlin( 简 称NSB,http://www.nsb-mfn-berlin.de/)是该数据库的门户网站,提供数据访问服务。截止2019年底,NSB已集成了61139个微体化石样品的768057条化石产出记录(图2a),包含了18915个分类单元名称,同时囊括了458个钻孔的659个年龄模型(Renaudie et al.,2020)。得益于大洋钻探项目的影响力,加上其先进的数据模块设计,蕴含了更多可深度挖掘的数据信息,建立了庞大的数据关联性,因此NSB的数据使用率高,成果产出丰富。迄今为止,该平台已发表115篇科研成果,其中有6篇成果在Nature和Science期刊发表。
NSB数据库包含了5个主要数据模块(Renaudie et al.,2020),分别为古生物学数据、地层学数据、样品数据、分类学架构和数据子集元数据。基于以上模块,NSB支持用户根据化石产出记录、分类信息、年龄模型(age model)、地层事件(stratigraphic events)和事件标定(event calibrations)进行检索和数据下载。NSB数据关系由17张数据表构成,核心为古生物化石记录表(neptune_sample_taxa,图2b),通过该表建立了分类单元、样品之间的联系,并且包含两个属性值(分类单元丰富度和数据质量)用于描述数据情况。样品详细信息保存在样品表(neptune_sample)中,建立了与岩芯数据的关联关系。岩芯表(neptune_core)记录了每个岩芯的名称、顶部深度和长度信息。钻孔数据表(neptune_hole_summary)中记录了航次、钻孔编号、钻孔水深、经纬度等相关的钻孔元数据。除了生物地理数据之外,NSB还创建了古地理数据表(neptune_paleogeography),用于储存样本的古经纬度坐标。分类学数据表(neptune_taxonomy)基于2008~2010年执行的分类学名录计划(The IODP Taxonomic Name List Project,简称TNL)设计,构建了海洋微体古生物的分类学框架。数据子集模块实现了样品表和具体化石产出数据表(neptune_sod)之间的链接,后者包含了出版物中的文献信息和基于SOD格式的各种元数据(Lazarus et al.,2018)。地层学数据模块包括年龄模型和地层事件两个部分,前者记录了年龄模型及其相关信息,后者以事件定义表(neptune_event_def)为基础,衍生出了事件数据表(neptune_event)、事件校准数据表(neptune_event_calibration)、站点校准数据表(neptune_calibration_sites)和地磁数据表(neptune_gpts)等。
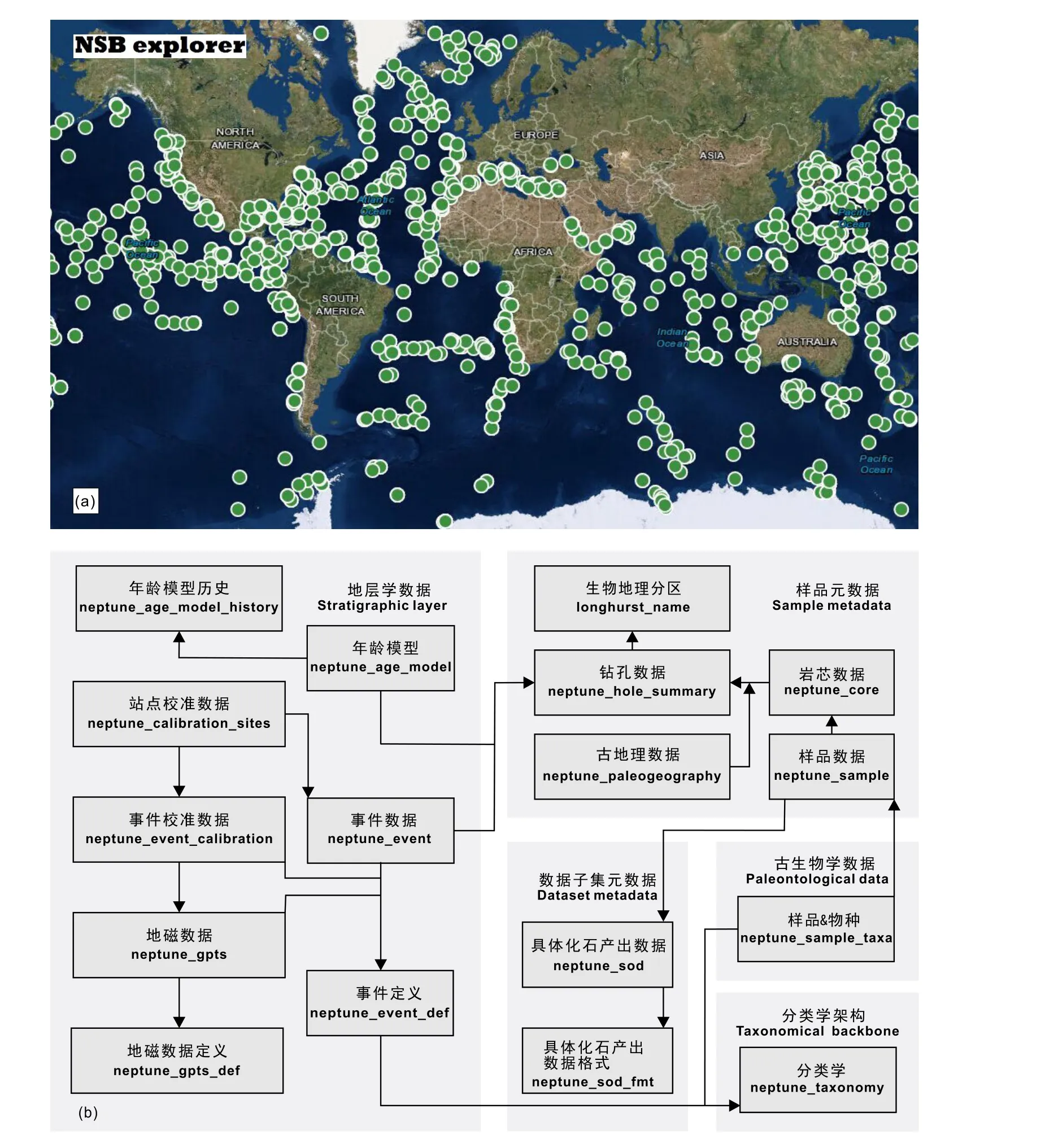
图2 NSB数据分布图(a)和NSB数据表结构(b)(改自Renaudie et al.,2020)Fig. 2 Data distribution of NSB database(a)and its architecture(b)(revised after Renaudie et al.,2020)
NSB作为古生物学领域的代表性科学数据库之一,最为核心的是其数据本身的独特性和唯一性,其所包含的丰富的微体化石数据来源于1966年起至今的国际科学大洋钻探项目,提供了相对完整的浮游生物的生物地理和深海沉积记录,丰富了现今大洋范围内地层记录中的微体古生物数据。其次,NSB针对其核心的化石分类和地层框架,通过古生物门类专家的积极参与,实行了严格的专家审核制度,致力于发布最为权威的数据资源。最后,最为独特的一点是,NSB提供了基于年龄—深度模型(Age-Depth Model)建立的动态的、数值化的、高分辨率的年龄标定系统(即年龄模型),可随着研究者对于各岩芯的地层学认识的不断深化而持续优化和更新。但是,该数据库仍存在一些不足之处。首先,在数据质量方面,由于数据庞大加上人力有限,大洋钻探所产生的古生物数据尚未全部被研究和发表,数据贡献者(研究人员)会倾向于优先开展其所处领域的化石分析工作,因此会造成部分信息的闲置和自然流失。其次,由于缺乏长期稳定的经费支持,而主要依赖于个别科学家的科研项目支撑,因此团队的开发和维护能力较为薄弱,体现在数据库设计方面,则是界面较单一、功能简单、可视化程度低、安全性较差等。
2.1.3 GBDB地质历史时期生物多样性数据库
GBDB在线数据库(Geobiodiversity Database,www.geobiodiversity.com)于2006年开始建设,2007年正式提供线上服务,是一个以剖面为核心、基于互联网、数据库和GIS技术搭建的古生物学和地层学融合为一体的综合性数据库(樊隽轩等,2011,2013)。其以剖面为核心,强化了地层学信息的角色,促成了古生物学与地层学两个相关学科的交叉与信息融合,不仅适合古生物研究的常见分析手段,也支持多种地层学研究方法,适合开展剖面有关的全球地层对比、定量地层学研究、生物演化模式分析和定量古地理等方面的科学探索和研究(Fan et al.,2013 ;Zhang et al.,2014)。GBDB致力于促进区域和全球科学合作,并先后成为了国际地层学委员会(ICS)和国际古生物学协会(IPA)的官方数据库,为全球古生物学和地层学研究者提供高质量的数据服务。2017年初起,GBDB团队与英国地质调查局建立合作,承担其地层古生物资料的数字化工作,超过14000条文献数据和4000余个英国及周边地区的露头和钻井剖面数据已收录入GBDB。截止2020年6月,GBDB数据库共数字化全球25201条剖面,575724条化石产出记录的综合地层学数据,以及58008个岩石地层单位和93659条文献索引数据。超过85%的中国古生物学文献已完成数字化工作,并可在线访问。
GBDB具备强大的检索功能,可基于文献、分类学信息、剖面和化石产出记录等多个维度进行高级检索,同时可结合研究目标在线创建数据子集(dataset),基于数据子集下载符合CONOP 9、SinoCor 4等定量分析软件所需格式的专业数据,从而开展相关研究。GBDB数据主要来源于期刊论文、会议论文、地质报告以及学科专著等,是已发表数据的客观承载,此外,也支持科学家未发表或待发表资料的数字化和在线共享。研究者可以根据个人观点添加观点数据(opinion),例如,化石厘定观点、年代地层和生物地层划分观点等。数据类别包括古生物学数据、地层学数据以及其他辅助数据(图3),其中古生物学模块涵盖了生物分类数据、化石描述数据以及厘定校正数据,地层学模块则以岩石地层、生物地层、年代地层和化学地层等地层学分支学科信息为主,以剖面为核心将地层学数据和古生物学数据有机地融为一体。
2.2 国家主导或区域为主体的中型数据库
近几十年来,地质数据呈现海量形式的增长,已经成为国家和区域重要的战略性资源,全球相应涌现出一大批国家主导或区域为主体的古生物学数据库,以收集、管理、挖掘和提炼深层次数据价值,有效地促进科技资源的合理保护、科学管理和高效共享为核心目标。
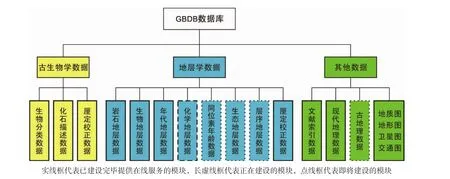
图3 GBDB数据库的主要数据结构与数据内容(樊隽轩等,2013)Fig. 3 Major data sources of the GBDB database(Fan et al.,2013)
英国地质调查局(British Geological Survey,简称BGS)是最早建立在线数据库、数字化程度最高、数据覆盖面最广的国家地调局之一。BGS成立于1835年,是世界上最早成立的国家地质调查局,目前隶属于英国自然环境研究理事会(Natural Environment Research Council, 简 称 NERC), 已发展成为世界一流的地球科学信息与技术中心。BGS保存了海量的纸质资料,化石藏品丰富,超过500万件,涵盖了从新元古代至今的漫长地质历史。在信息时代下BGS已经全面转型为大数据型的发展模式,累计建设了超过400个不同的数据集和众多数据产品。BGS的古生物学数据库包括古生物标本数据库PalaeoSaurus(PalaeoSaurus Online Collection Database,https://www.bgs.ac.uk/palaeosaurus/home.cfm)和模式化石数据库GB3D Type Fossils(http://www.3d-fossils.ac.uk/)。 前 者创建较早,数据表结构简单,仅包括标本入库编号、是否为模式标本、鉴定名称、产地、所在的地理图幅编号、地层和地质时代信息等。目前PalaeoSaurus已收录了大约15万件标本的信息,其中,寒武系至下白垩统的重要模式标本已悉数入库。GB3D Type Fossils数据库于2013年8月正式上线,由BGS和联合信息系统委员会(Joint Information Systems Committee,简称JISC)共同开发,致力于建设高质量的模式标本数据库,主要收录英国馆藏与产出的化石模式标本。GB3D Type Fossils提供化石标本的高分辨率照片、体视相片、3D数字模型以及元数据(产地、地质年代、分类鉴定、注册号等)在内的众多类型数据。通过简单搜索和高级搜索功能,研究者可以根据分类信息、标本类型、地质年代、岩石地层单位、产地等字段进行数据查询,进而在线浏览和下载。
为了实现全美生物收藏品的全面数字化,在美国国家科学基金会(National Science Foundation,简称NSF)项目“推进生物多样性馆藏数字化”(Advancing Digitization of Biodiversity Collections,简称ADBC)的支持下,美国的众多相关博物馆和机构联合建立了iDigBio数据库(Integrated Digitized Biocollections,https://www.idigbio.org/)。该数据库中已经收录了上百家自然历史博物馆或收藏机构的藏品,并提供各收藏机构的相关资料和交互式藏品分布展示(图4)。 iDigBio基于标本实体或以图片等多媒体为单位进行数据收集,藏品贯穿古今,既有化石资料又有现生物种数据。其数据海量、参与机构多,截止2020年2月已整合了121428342个样品信息以及31871863条多媒体记录,其中样品以植物、动物标本为主,真菌标本次之,分别占比47%、46.5%和5.6%,媒体数据则主要为植物,占比82.5%。iDigBio检索功能强大,支持通过关键字进行检索,也可以基于多个字段进行个性化的组合检索和可视化展示。
日本地质调查局(Geological Survey of Japan,简称GSJ,https://www.gsj.jp/)自1882年成立以来一直从事各种地质调查和研究,致力于为日本国家和公众提供全面而优质的地学数据。其旗下已建设开发了28个数据库产品,包括2个古生物学标本数据库,分别是20世纪日本化石模式标本数据库(The database of Japanese fossil type specimens described during the 20th Century,https://gbank.gsj.jp/FossilType/),以及化石、岩石和矿物地球科学数据库(The Geoscientific Database of Fossil, Rocks and Minerals,https://gbank.gsj.jp/DFORM/)。 前 者为日本古生物学会2001~2004年间出版的四卷“20世纪日本化石模式标本数据库”专著的网络版本,提供了包括标本类型、产地、文献等18个字段在内的信息,同时支持用户提交厘定意见表单,以优化数据质量。后者为化石、岩石和矿物标本的综合地学数据库,支持以标本名称、产地等字段进行检索,提供化石标本详情、文献等信息,并提供高清照片下载和使用。
除了上述由日本地质调查局建设的两个古生物学数据库,另一个有较大影响力的数据库是由日本众多的高等院校、博物馆、资料馆和古生物专业团体共同打造的日本古生物学数据库jPaleoDB(Japan Paleobiology Database,http://jpaleodb.org/)。该数据库本质上是一个门户网站,链接了日本境内大量的分散的古生物学数据库,查明每个数据库的数字资源情况,完善其数据保存和管理方式,最终以统一的用户界面提供给研究者(图5)。多源异构数据的有效融合与跨平台的综合检索是jPaleoDB的亮点,用户可以在jPaleoDB平台上实现对所有数据的检索,也可以通过链接访问各个数据库的首页进行信息查询。目前,已有70所高等院校、博物馆、资料馆和古生物专业团体加入了这一体系,包括东京大学、京都大学、东北大学、北海道大学、国立科学博物馆以及多个县市的博物馆等,如前文介绍的20世纪日本化石模式标本数据库以及较为知名的古脊椎动物化石数 据 库 JASOV(Japanese Fossil Vertebrate,http://jafov.jpaleodb.org/)等均已链接至jPaleoDB。目前jPaleoDB已经整合了62个数据库的391925块标本数据,以及16582篇相关的文献,近期还将有8个数据库加入这一平台。jPaleoDB的最终目标是构建一个系统整合了日本的古生物标本数据资源的综合平台,实现所有日本古生物标本的跨数据库、跨平台统一检索。
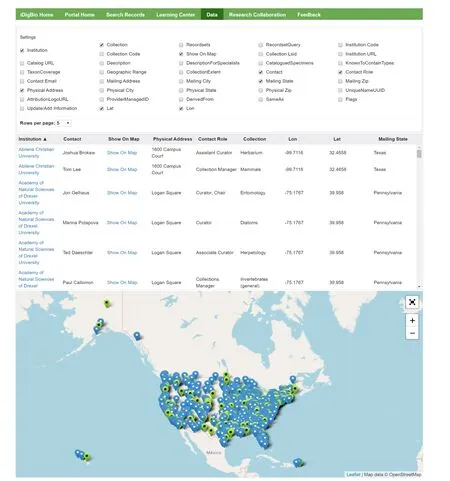
图4 iDigBio的参与机构及其分布Fig. 4 Institutions participating in the iDigBio project and their distribution
Fossiilid.info(https://fossiilid.info/) 是 爱 沙 尼亚地学收藏中心(Geoscience Collections of Estonia,http://geocollections.info/)下属的古生物学数据库,由塔林科技大学地质学院、塔尔图大学自然历史博物馆和爱沙尼亚自然历史博物馆共同建设。Fossiilid.info聚焦标本,其数据主要涵盖爱沙尼亚及其邻近的欧洲地区,此外也包含了部分北美东部的古生物标本数据。Fossiilid.info具有三个重要的特点:(1)提供高质量的标本图像:该数据库以标本为核心进行建设,针对每个标本提供了不同角度、不同图幅的高清化石图集,并按照植物、双壳类、头足类等24个化石大类进行数据展示。由于该数据库对大量老标本进行了重新数字化,采集了大量高清照片,因此弥补了早期文献中化石图版缺失或图像分辨率过低的缺陷。(2)可挖掘信息多:不同于一般的收藏型数据库,Fossiilid.info中除了提供样品号、采集信息等基础信息外,同时还提供系统分类树和同异名录等重要信息,大大提高了数据的质量和使用价值。(3)数据互联程度高:在Fossiilid.info内部,各个模块之间无缝链接,标本信息、分类树、同异名录等均可互相跳转访问,最大程度实现了数据互联,而非简单的浏览与展示。

图5 jPaleoDB的平台架构Fig. 5 System structure of jPaleoDB
FRED(The Fossil Record Electronic Database,https://fred.org.nz)是新西兰化石记录档案(New Zealand Fossil Record File,简称FRF)的在线版本,由新西兰地球科学学会(Geoscience Society of New Zealand)和地质与核科学研究所(GNS Science)联合管理。FRF早期是纸质版本,由新西兰地质调查局于1946年创建,提供权威的新西兰化石产地、地质背景和化石采集等信息。此后,于1970年在FRF的基础上建立了电子数据库FRED,逐步实现纸质资料的数字化。2003年,通过GNS Science网站发布了FRED的交互式访问界面,开始为公众提供在线的开放数据服务。自2005年起,注册用户可以直接在线录入新的数据。经过超过半个世纪的持续更新和迭代,FRED已经发展成为一个数据资源丰富、功能全面、有代表性的国家层次的古生物学数据库。FRED以新西兰的化石记录为主,也收录了少量太平洋东南海岛和南极洲罗斯海区域的数据。在结构方面,以化石产地(location)为核心构建,这也是FRED有别于其他数据库的一大特点,提供了包括地理坐标、采集详情、地质背景、化石标本库等详细信息,部分记录还会提供化石分类学、地层年代、古环境分析等信息。每条化石产地数据均保存为独立的记录,如果后期重新对该产地进行采样,则重新采样的数据将存储为新的记录。FRED中设计了丰富的检索功能,用户可以通过主菜单、简单查询、高级查询和交互式地图等方式进行数据检索。截止2020年2月,FRED中收集了自1946年以来在新西兰各地区记录中心登记注册的101911个化石产地记录,超过65%的相关纸质文档已经完成了数字化工作并纳入数据库中。
2.3 小型数据库
此类数据库往往具有科研问题导向或者面向相对局限的研究对象和功能建立的特点,相较于前文介绍的多门类、多领域的综合数据库而言,此类数据库在一定程度上可定位为小型数据库,但是其中不乏影响力显著、数据质量高、数据体量大和在特定领域具有权威地位的重要数据库。
2.3.1 科学问题导向的数据库
依托具体科学问题建设的古生物学数据库数量庞大,限于篇幅,此处仅挑选其中具代表性的数据库进行介绍。
2.3.1.1 Sepkoski在线属级数据库
Sepkoski在线属级数据库(Sepkoski's Online Genus Database,http://strata.geology.wisc.edu/jack/)由美国威斯康星大学麦迪逊分校的Shanan Peters于2003年开发并一直维护至今。20世纪70年代起,芝加哥大学的J. J. Sepkoski耗费数十年时间,先是收集整理了海洋动物化石科级纲要(Sepkoski,1982,1992),然后在此基础上进一步细化,编撰完成了海洋动物化石属级纲要(Sepkoski,2002)。这两个纸质版的数据库,对象为无脊椎动物、脊椎动物和原生生物,建设目的是探索显生宙海洋生物演化的基本规律。Sepkoski及其同事基于这两个数据库,开展了显生宙海洋生物演化与灭绝事件的研究,获得了一系列重要研究成果,开辟了古生物多样性研究的全新领域与研究手段,后来的PBDB、Neptune和GBDB等国际大型数据库均受其启发而建立。Sepkoski在线属级数据库实质上是海洋动物化石属级纲要(Sepkoski,2002)一书的网络数字化版本,其中提供37000余个全球显生宙海洋动物属级分类名称及其地质延限的查询。
2.3.1.2 Neotoma古环境数据库
Neotoma古环境数据库(Neotoma Paleoecology Database,http://www.neotomadb.org) 创 建于 2009年,致力于为古生态学、古环境学、生物地理学、考古学和生态学研究提供开放的、系统的、可持续的、高质量的数据资源。该数据库主要收集全球范围内中新世至今的化石数据,并以第四纪数据为主。Neotoma所收集的数据类别包括但不限于孢粉、碳屑、硅藻、介形虫、变形虫、脊椎动物化石、无脊椎动物化石、昆虫化石,以及年代学数据、稳定同位素数据和生物标志化合物等。
Neotoma为开放的数据平台,其早期使用Microsoft SQL Server作为数据库管理系统,其服务器位于宾夕法尼亚州立大学,目前正在逐步迁移到PostgreSQL。Neotoma主要包括5张核心数据表,针对不同类别数据的结构共性特征设计了统一的数据录入格式(图6a)。Neotoma拥有强大的数字化和数据管理团队,由来自各领域的科研工作者组成。其数据来源主要是已发表的文献,由科研人员通过Tilia软件进行数据审核、录入和管理。Neotoma团队还开发了集搜索、可视化和下载等功能为一体的网络应用程序——Neotoma Explorer(https://apps.neotomadb.org/explorer/),帮助用户更好地分析和使用Neotoma的数据。
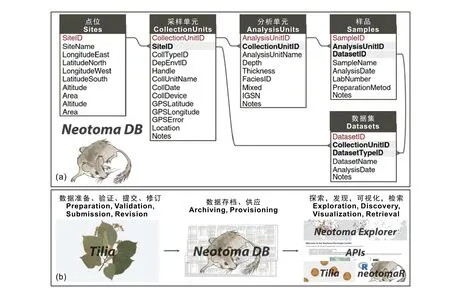
图6 Neotoma数据表结构(改自Williams et al., 2018)Fig. 6 The architecture of Neotoma database(revised after Williams et al., 2018)
Neotoma是具有代表性的科学数据库之一,具体表现在五个方面:(1)数据类型的丰富性:在包含古生物学和古生态学数据的同时,纳入了地球化学、生物标志化合物等具有衍生意义的数据。(2)分布式治理结构:Neotoma通过合作,整合了一大批相关的古生物学数据库,实现了数据量的快速增长。截止2016年,Neotoma已融合了包括北美孢粉数据库North American Pollen Database和古哺乳动物数据库FAUNMAP等在内的20个数据库的17275个数据子集,总计超过380万个化石样品(Williams et al.,2018)。(3)数据高度开放、共享:用户可使用Neotoma Explorer或Tilia检索和下载所需数据,或通过应用程序接口(Application Programming Interface,简称API)获取数据进行分析,也可以使用R语言包“neotoma”进行数据分析。并且,用户可以将搜索结果保存为JSON格式文件进行存档,或者共享给其他用户在Neotoma Explorer中直接打开使用。(4)严格的审核机制:所有上传到Neotoma的数据均需要由专家进行审核,以确保数据质量的可靠性。(5)完整的生态链体系:经过多年的开发,Neotoma平台中已经初步实现了从数据收集、标准化、存储到数据挖掘、可视化和分析的完整流程(图6b)。
除了上述两个典型的科学问题导向的数据库之外,还有一些具备学科特殊性的小型数据库。例如,美国史密森尼国家自然历史博物馆主持的陆地生态系统演化项目(Evolution of Terrestrial Ecosystems Program),建立了相应的ETE数据库(https://naturalhistory2.si.edu/ete/ETE_Database.html),致力于研究4亿年以来陆地生态群落的特征和生态系统的动态变化;芝加哥大学主导的古地理图项目(Paleogeographic Atlas Project,简称 PGAP,https://www.uchicago.edu/research/center/paleogeographic_atlas_project/)根据植物对气候的敏感性特征建立了PGAP全球二叠纪、三叠纪和侏罗纪陆相植物数据库,用于辅助全球古地理重建的工作;Morphobank(https://morphobank.org/)聚焦化石图像数据以及与系统发育矩阵相关联的形态数据,致力于构建生命之树,分析现存和灭绝物种的谱系关系;TimeTree(http://www.timetree.org/)和 Fossil Calibration Database(https://fossilcalibrations.org/)同样也关注生命树和谱系演化研究,前者是关于生命之树及其演化时间尺度的信息的公共知识库,数据主要来源于已发表文献,后者提供经过筛选的化石年龄标定数据,供分子系统学家进行分化年代测定(divergence dating analyses)。
2.3.2 面向单个化石类群的古生物学数据库
在古生物学数据库中,还存在一定数量的针对单个化石类群或者某一化石大类而建立的数据库,此类数据库体量相对较小,针对性强,数据表结构简单,多由单个或个别科学家设计并维护。例如,NOW古哺乳动物数据库(New and Old Worlds:Database of Fossil Mammals,http://www.helsinki.fi/science/now/)重点关注新生代陆地哺乳动物的分类和产地信息;塔林理工大学地质研究所Olle Hints建立的虫牙化石数据库(Scolecodonts,http://scolecodonts.net/)重点关注虫牙化石的系统演化研究;美国华盛顿大学Michael Mortimer为了开展兽脚类恐龙的系统演化研究而建立的兽脚恐龙数据库(The Theropod Database,https://theropoddatabase.com/),Mikrotax主要收集微体化石的高分辨率图像数据和分类学信息等等。受篇幅所限,以Mikrotax为代表进行介绍。
Mikrotax(http://www.mikrotax.org/) 是 微 体化石分类群的在线数据库集成系统,目前已经开发了两大核心数据库,分别是Nannotax和Pforams@mikrotax,针对疑源类(Acritax)和放射虫(Radiolaria@mikrotax)的两个数据库正在逐步整合与建设中。Mikrotax的数据结构表比较简单,主要包括化石分类数据表和对应的高质量化石图像数据,同时提供丰富的分类学、地层学等信息(图7)。考虑到微体化石分类学正处于不断修订与完善的阶段,Mikrotax设计了两个平行数据库:主数据库(main database)和物种原始描述名录数据库(catalog),前者集成了该分类单元的最新分类学鉴定信息、高质量图件、地质延限和化石产出分布等详情,而后者重点关注分类单元的原始描述和注释,模式标本的原始插图等首次发表信息。同时,该数据库还融合了NSB的产出数据,提供了分类单元分布及其随时间变化的定量数据与可视化展示(图7;Young et al.,2019)。基于图像的展示方式、直观友好的用户界面,以及双数据库架构是Mikrotax有别于其他数据库的重要特征。
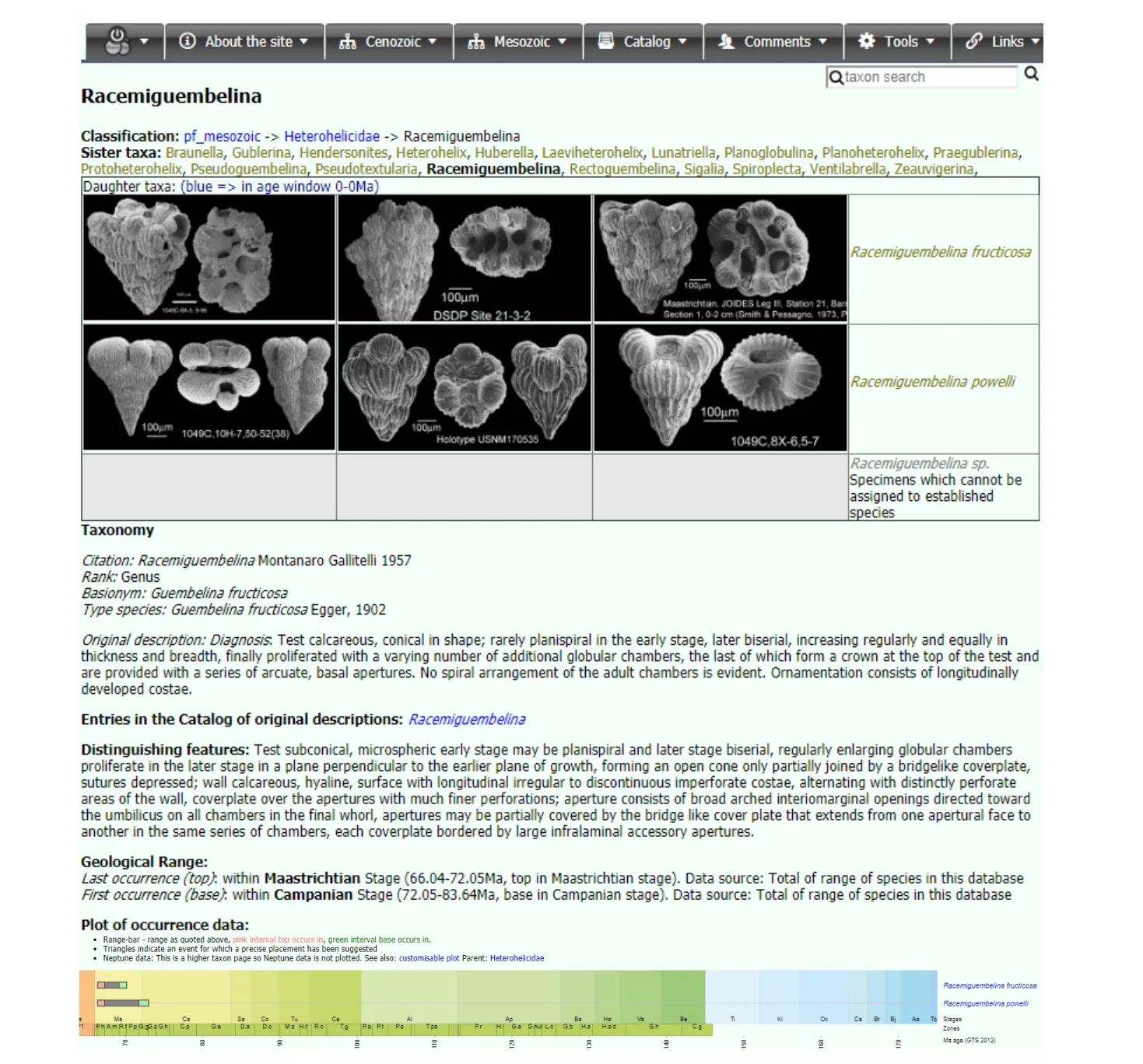
图7 Mikrotax的分类学信息样例Fig. 7 An example of the taxon table in Mikrotax
Nannotax于2003年由Jeremy Young等人着手建设,旨在提供颗石藻的生物多样性和分类学的权威指南,Nannotax收录了以下数据:现生颗石藻及其新生代祖先(1500个页面,13500幅图件),中生代颗石藻(1300个页面,9700幅图件),Farinacci钙质超微化石名录(Catalogue of Calcareous Nannofossils, 由Anna Farinacci在1969~1989年编纂,Richard Howe在 2000~2016年更新,包含4500个物种的详细描述)以及未钙化定鞭金藻、钙质鞭毛藻类化石信息(500个页面,800幅图件)等。
2015年,Bridget Wade和Brian Huber主导建立了浮游有孔虫数据库Pforams@mikrotax(Huber et al.,2017),其前身是2005年建设的CHRONOS在线分类学数据库,但由于CHRONOS数据库整体消亡,其中的分类学数据和化石图集被融合到Mikrotax数据系统中,并已逐渐发展成为浮游有孔虫分类学数据的重要参考资料。pforams@mikrotax包括三部分:新生代子集(600个物种,2600幅图件),中生代子集(600个物种,1200幅图件)和化石名录(主要来源于CHRONOS数据库的模式标本描述数据,2600个物种,4900幅图件)。
此外,Acritax由Brian Pedder和Jeremy Young创建,重点关注寒武纪疑源类化石,包括John Williams古孢粉学索引(John Williams Index of Palaeopalynology,简称JWIP)中描述的疑源类化石和平行建设的寒武纪疑源类化石数据库两部分。Radiolaria@mikrotax由David Lazarus主导建设,致力于为放射虫分类学提供有效指南,其主数据库基本采用了NSB的新生代放射虫分类体系(Lazarus et al.,2015)。
2.3.3 专用型数据库
除了前文所介绍的各种类型的数据库外,古生物领域还存在一类专用型数据库,这类数据库往往不关注某个科学问题,也不单纯服务于某个化石类群,而是针对特定的功能(如模式标本、化石3D模型、古生物学文献等),为科学研究提供基础资料的永久保存和在线查询。BioLib(Biological library,https://www.biolib.cz/)是典型的专用型数据库之一,它提供详尽的生物(也包括古生物)分类单元名录及其分类关系,致力于收集生物信息,包括物种数据、生物术语数据、与自然相关的文献和链接列表、物种语言词典等数据,是一本关于植物、真菌和动物的百科工具书。类似的,ZooBank(http://www.zoobank.org)由国际动物命名法委员会认证,提供权威、在线并且开放访问的动物命名注册表,用于记录所有已发表的动物科学名称。众所周知,根据国际动物命名法和国际植物、藻类、真菌命名法的要求,每个物种必须有模式标本,所以建立一个权威的模式标本数据库就十分重要。前文提及的英国地质调查局建设的GB3D Type Fossils就是一个较为独特的模式标本数据库,其中不仅提供了英国化石模式标本的原始描述和高质量图像数据,还提供了三维模型数据。此外,随着一些新技术的应用,一些新型数据库也应运而生。例如,随着micro-CT技术在古生物学领域的应用,一些化石CT三维模型数据库逐渐发展起来。生物演化三维形态数据库(Archives of Digital Morph,http://www.admorph.org/, 简 称 ADMorph)便是其一,它由中国科学院古脊椎动物与古人类研究所朱敏团队开发并维护,提供化石CT三维模型的免费存储、共享和在线发表(通过DOI的方式)。古生物学文献数据库则是另一种比较独特的专用型数据库,其中以脊椎动物化石文献库(The Bibliography of Fossil Vertebrates, 简 称 BFV Online,http://www.bfvol.org/)较为经典,其中收录了1509~1968年和1981~1993年间的131190篇文献资料,用户使用时,不仅可以对常用的文献字段,如作者名、出版时间、出版杂志等进行组合检索,还可以对文献中包含或不包含的脊椎动物分类名进行检索。但遗憾的是,这一数据库在2003年之后就不再更新。
3 古生物学数据库结构与数据共享
3.1 数据整理方式
由于数据库建设理念、功能需求的差异,各种数据库在建设过程中通常采用了不同的数据整理方式,具体可归纳为以下四种:(1)收藏管理型数据库:基于化石标本或化石图像进行建设;(2)综合研究型数据库:基于化石产出记录、产地或地质剖面等研究对象进行建设;(3)专著或者化石名录在线数据库;(4)数据库集成平台。
收藏管理型数据库最为常见,该类数据库基于化石标本或化石图像进行建设,核心目的是提供馆藏化石标本的编目、查询、在线浏览和实体借阅服务。许多博物馆、标本馆所建设的在线数据库基本都属于这一类,如中国科学院旗下的古脊椎动物与古人类研究所标本馆和南京地质古生物研究所标本馆的在线数据库,以及前文介绍的jPaleoDB旗下的日本各个博物馆的标本数据库等。而典型的基于化石图像建设的数据库一般而言会拥有较高的图片质量,如iDigBio和Fossiilid.info等。
综合研究型数据库活跃于科研一线,提供了科研生产力的数据基础。此类数据库的数据整理方式多样,数据库架构相对复杂且各异(图1a,2b,6a),其数据主要来源于已发表的论文或专著,少量来自于科学家未发表数据,因此数据通常已经过同行评议,具有高可靠性。PBDB基于化石产出记录建设而成,提供系统分类信息的动态构建,目前已广泛应用于生物多样性、古生态和古环境等研究领域。NSB基于深海钻孔构建数据库,广泛收录了过去半个世纪的大洋钻探的微体古生物化石数据。GBDB数据库则基于剖面进行数据收集,将古生物学和地层学数据有机融为一体。Neotoma以样品数据为核心,结合化石信息开展古生态与古环境研究。
第三类数据库是基于领域内的经典专著或者化石名录进行直接数字化而建成的,典型代表为Sepkoski在线属级数据库,其数据来源于Sepkoski(2002)发表的海洋动物化石属级纲要。同样,20世纪日本化石模式标本数据库也属于这一类型。
第四类数据库本质上是依托多个数据库打造的门户网站或集成平台,主要目的是为了整合多源异构的化石数据库,因此其数据整理方式最为特殊。为了尽可能整合分散的数据库,此类系统往往会制定共性描述规范,通过开发API接口,在不改变原有数据表结构的情况下使用统一的门户网站进行数据整合,允许用户同时访问和查询其旗下的多个数据库,从而实现跨数据库的无缝检索和数据挖掘。iDigBio、jPaleoDB便是通过此种方式实现了全美和全日本的古生物数据的整合,打破了各个博物馆、标本馆的数据库之间的沟通壁垒。Mikrotax在一定程度上也可以归为此类,其本质上也是一个在线数据库集成系统,但与前两个平台不同的是,Mikrotax旗下的子数据库是直接在Mikrotax系统上建设的,而非通过API等方式调用原始数据库数据。
3.2 主要在线功能
古生物学数据库的基础在线功能包括数据检索、数据录入和数据下载等。数据检索是最为基础的在线功能,也是决定数据库可用性、易用性的关键。数据库根据其数据字段表提供关键词检索,通过各个数据表之间的关联关系实现数据访问、调用和展示。一般而言,检索可分为简单检索和高级检索,简单检索通常仅针对化石名称、产地等个别字段进行检索,高级检索则支持基于多个检索字段的组合查询。数据录入和下载功能视情况而定,一般而言,以博物馆、标本馆等为代表的收藏管理型数据库通常有专门的数字化团队进行日常的样品整理、编目和数字化工作,其在线数据库主要支持数据检索和浏览,不提供外部的数据录入和批量下载功能。综合研究型数据库则与之不同,通常具备完整的数据录入和下载功能,PBDB、GBDB、FRED等数据库均支持注册用户基于文献进行数据录入,数据在审核后即可在线发表;Morphobank、Fossil Calibration Database和ADMorph等数据库还支持在线导入图像矩阵等数据。数据下载功能与数据共享机制密切相关,详见3.3。
综合研究型数据库在不断更新换代的过程中会逐步开发服务于研究的高级在线功能,主要包括各种可视化与在线分析工具等。其中,在线的地图投点功能最为常见,PBDB、Fossiilid.info、Mikrotax、GBDB等均实现了基于数据集的化石在线投点展示。其中,iDigBio的展示方式较为独特,当数据结果包含超过100000个数据点时,结果将显示为基于GeoHash的热力图(geohashed heat map,图8a),当结果小于或等于100000时,结果将显示为常规的数据投点(图8b),使用不同颜色进行标记以区分不同的分类单元。在PBDB中,根据查询结果可以实时生成多样性曲线图(图8c),便于用户查看所关注对象随时间的多样性变化规律。值得一提的是,由澳大利亚麦考瑞大学的John Alroy独立开发的PBDB的门户网站Fossilworks(http://fossilworks.org/),它与 PBDB 共用同一套数据,但集成了更加丰富的在线分析工具,包括古地理成图、数据汇总表(data summary tables)、常见分类单元列表(lists of common taxa)、首现记录(first appearances)、多样性曲线(diversity curves)、生态统计(ecological statistics)、时间尺度置信区间(time scale confidence intervals)、地层置信区间(stratigraphic confidence intervals)等。Fossiilid.info、BioLib可以在线展示化石分类树并支持点击查看词条详情。GBDB提供Geo Visual 1.0、TS Creator等在线可视化和分析工具(Fan et al.,2013,2014),前者支持基于地理信息系统(GIS)的空间数据显示(图8d),并且可以手动圈定研究区域,形成可发表的高质量图件,后者实现了选定剖面的综合地层数据的可视化(图8e)。同时,GBDB基于PaleoGIS等技术可实现古地理投图,以便开展基于古地理重建的相关研究。Mikrotax提供了丰富的在线工具,包括术语表(glossary)、时间筛选(time-control)等,基于查询结果可以进一步生成生物分带图、延限图和时空分布点图(space-time spots,图8f)等。
3.3 数据共享特点
不同数据库具有不同的数据共享机制,按照开放程度,从高到低可以划分为以下几个层级:(1)提供开放的应用程序接口;(2)支持在线浏览和批量下载数据;(3)仅可在线浏览,不支持批量下载;(4)内网数据库;(5)离线数据集。
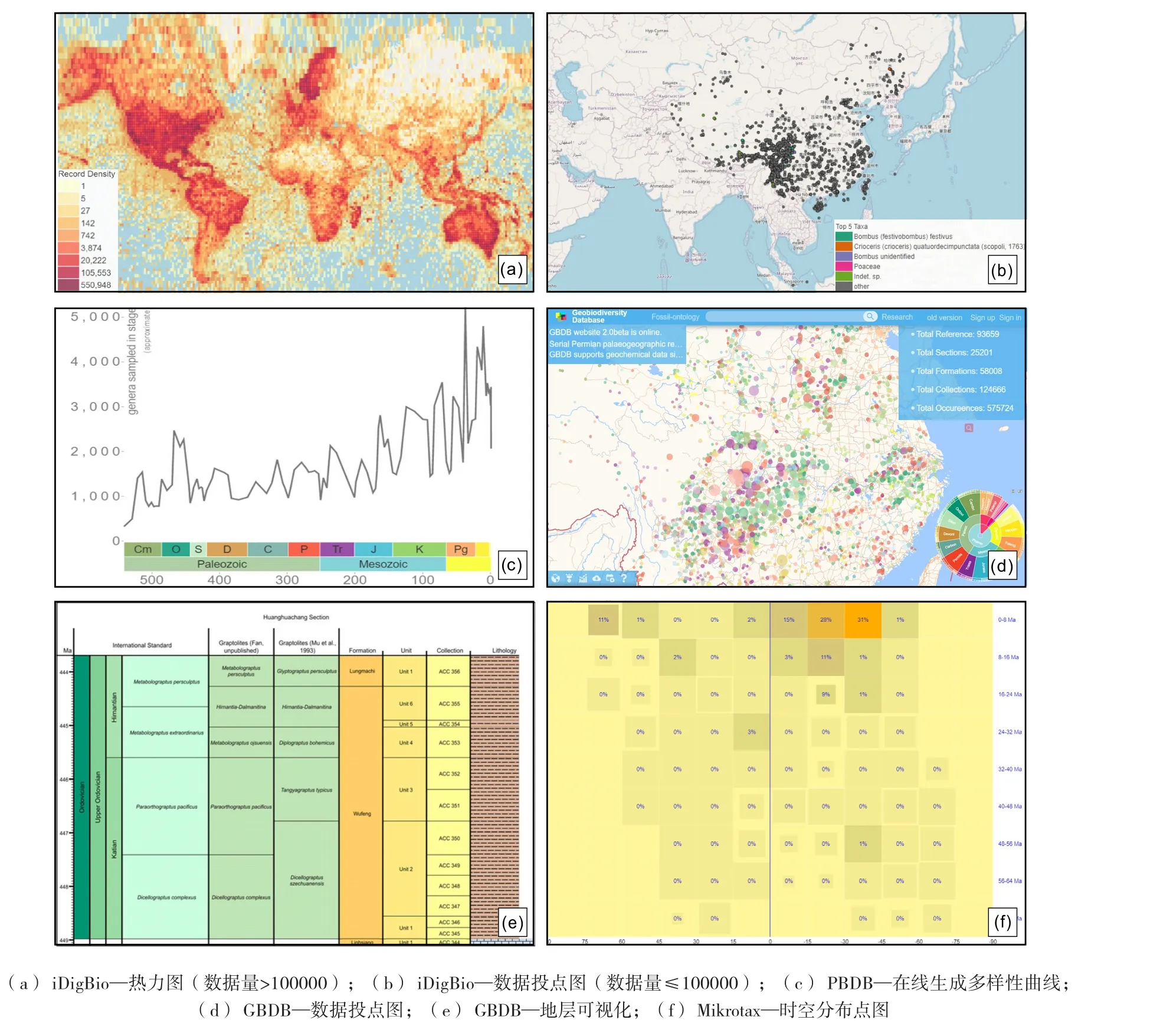
图8 不同综合研究型古生物学数据库高级在线功能展示Fig. 8 Advanced online tools of different integrated research paleontological databases
数据库环境中,应用程序接口(Application Programming Interface,简称API)提供了一组用于构建软件的协议和工具,便于用户远程访问数据并返回不特定于具体终端使用的格式化的数据。PBDB、Neptune、FRED、Mikrotax、MorphoBank、Neotoma等数据库均提供了API接口,研究者可以通过接口快速获取和分析数据。以PBDB为例,其数据资源由统一资源定位符(uniform resource locators,简称URL)进行唯一标识,表1总结了PBDB 开放的API接口列表(Peters and McClennen,2016)。用户可通过调用API接口获取数据,构建定制化的网页或者使用R、 Python等语言进一步进行数据处理与分析。PBDB Navigator网络应用便是PBDB API的复杂应用实例。基于API调用,任何人都可以编写与之交互的Web应用,完成数据的深度挖掘与利用。
综合研究型数据库一般均支持在线浏览和批量下载数据。例如,PBDB进行数据检索与筛选后,可以直接在线导出所需数据;GBDB可建立数据子集,基于数据子集进行批量下载;NSB支持批量下载数据,已下载的数据可在线保存一个月;Neotoma支持多平台数据下载,用户可以通过Neotoma Explorer和Tilia进行数据检索和下载。一般而言,提供API接口的数据库通常也支持在线浏览和批量下载数据,用户可以基于查找条件生成数据子集,然后批量下载。

表1 PBDB API类型列表(改自Peters and McClennen,2016)Table 1 Summary of operation types provided by PBDB API(revised after Peters and McClennen,2016)
此外,还有一批数据库仅提供在线浏览,不支持批量下载,部分可以基于单个检索结果逐一下载数据。基于化石标本的收藏管理型数据库大多属于此类,因此其数据访问的开放程度通常较低。
最后两类,包括内网数据库和离线数据集,这两者通常见于相对封闭保守的科研院所或相关单位、不具备网络数据库开发能力或需求的科学家个人或一些大型实验分析仪器的工作站上等。这两类数据库的共享程度低甚至不具备共享意义,主要服务于单位内部人员或仅供个人研究者使用。
3.4 数据质量控制
分类学数据是古生物学数据的核心内容,包括化石鉴定和分类等级关系的确认等,其准确性直接影响到生物地层划分、时间框架构建、区域地层对比和生物演化等结论的可靠性。分类单元及其层级关系是建设古生物学专业数据库的重要环节,现有的古生物学数据库采用了几种不同的方式来处理分类单元及其层级关系、控制数据质量与生成分类树。PBDB通过特定工作流实时生成分类体系;Mikrotax设置有评论专区,用户提交的厘定意见由数据库团队统一收集与分析,制定统一的标准,然后再通过在线系统对外发布;GBDB中每个化石门类均由国内权威专家领衔的工作团队进行厘定和录入,保证了化石分类数据质量,分类学模块不支持生成分类树,但是支持用户针对分类单元添加厘定意见,优化数据质量;20世纪日本化石模式标本数据库支持用户在线提交厘定意见表单;NSB设置有专家工作组,不定期更新分类学和地层学数据,上传优化后的年龄模型。
4 数据驱动下的科学研究案例
数据驱动下的科学研究往往与数据库和大数据分析方法相结合。古生物学领域的数据驱动下的科学研究主要包括生物宏演化模式与机制探讨,生物古地理研究,以及古生态与形态演化分析等。前文所介绍的一些代表性的数据库,如PBDB、NSB和Neotoma等,已经产出了一批优秀的科研成果,在其数据库网站上通常有专门的网页列举已发表的科研成果清单。
4.1 大数据揭示生物宏演化模式与机制
生物宏演化(Macroevolution)是指在物种及更高层面上所发生的生物演化过程(Mayr,1982),重点关注大尺度的生物演化趋势、规律和生物演化事件等。19世纪中期,基于英国的海相化石记录,Philips(1860)首次识别出显生宙海洋生物宏演化的粗略模式。20世纪80年代,Sepkoski和Raup通过对超过2800个科级化石纪录的统计分析,建立了全球显生宙海洋无脊椎动物多样性数据纲要(Sepkoski,1982,1992),以阶或统为单位,绘制了显生宙海洋生物多样性曲线(Sepkoski,1979,1984;Raup and Sepkoski,1982),其研究的时间跨度达650 Ma,平均时间精度约为8.1 Ma。在此基础上,他们识别出地质历史中的“五大”灭绝事件(“Big Five” mass extinctions;图9),区分出寒武纪至今的三大演化动物群(Sepkoski,1981),认为三大演化动物群的起源、壮大与灭绝主导了整个显生宙海洋生物多样性演化的模式(图9)。
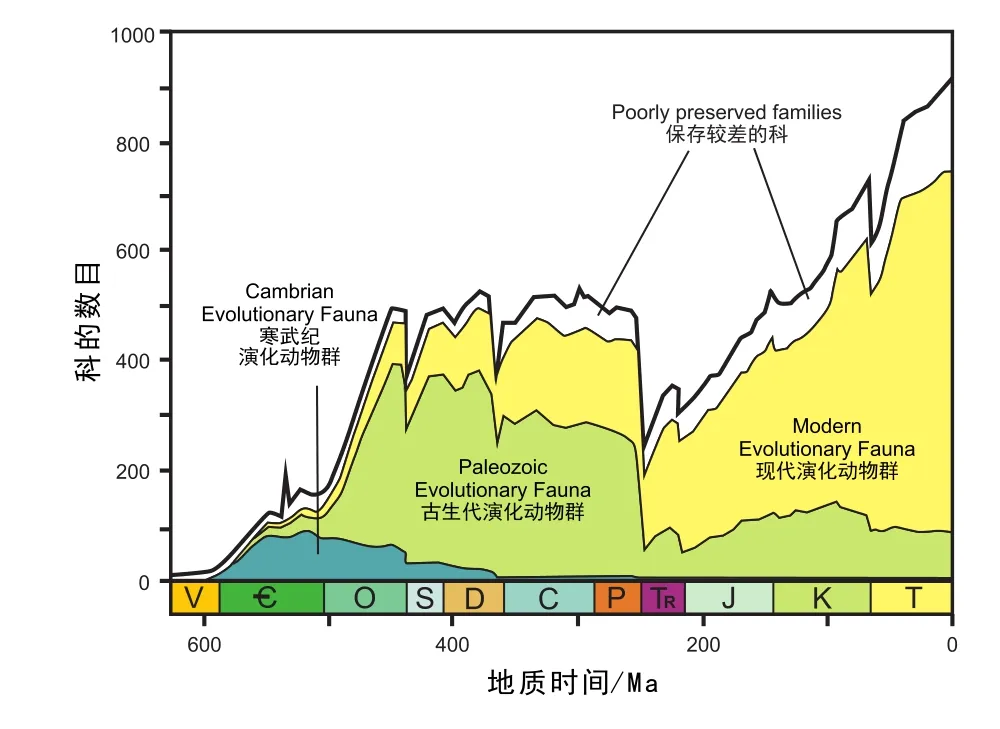
图9 Sepkoski史前海洋生物多样性曲线(Sepkoski,1984)Fig. 9 Biodiversity curves of marine animal families through geological history(Sepkoski,1984)
依托于PBDB高质量的古生物学数据,基于大数据开展的生物多样性研究不断涌现(如Miller and Foote,2003;Alroy et al.,2008;Darroch and Wagner,2015等),其中Alroy等的显生宙海洋无脊椎动物多样性研究成果最具代表性(Alroy et al.,2008)。该项研究利用PBDB检索和下载了19107个化石属的284816个化石产出记录,基于抽样标准化(sampling standardization)和进样计数方法(sampled-in-bin counting method)统计并绘制了显生宙以来海洋无脊椎动物的生物多样性演化曲线,其时间跨度为520 Ma,细分为48个近似时长的时间段,平均时间精度约为11 Ma。
美国加州大学河滨分校的Peter Sadler等人则尝试依托大数据并结合定量地层学的约束最优化方法,通过提高时间分辨率来对生物多样性的变化过程进行精细刻画(Sadler and Cooper,2003;Sadler,2004)。Sadler耗时多年建立了全球奥陶纪—志留纪笔石化石的单机版数据库,包括了582个地质剖面的2114个笔石物种,以及139个同位素年龄数据和沉积标志层数据,通过计算,采用无时间段划分的方式(un-binned)统计生物多样性,绘制得到了奥陶纪—志留纪高分辨率的笔石多样性曲线(图10;Sadler et al.,2009,2011),其时间分辨率高达33 Ka,从而可以精细刻画笔石动物群的演化过程与模式。
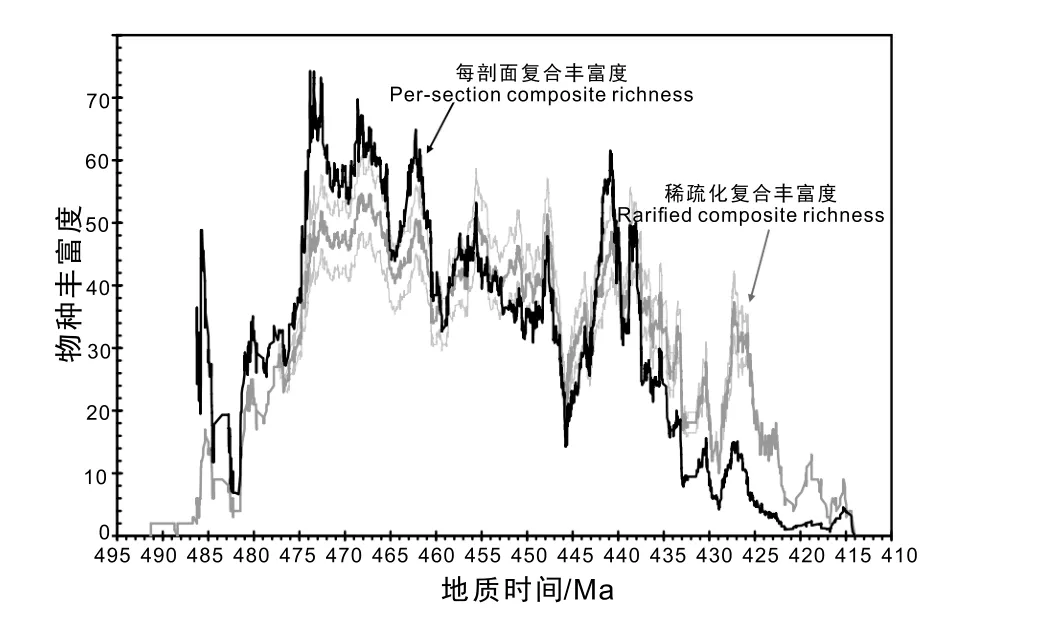
图10 高分辨率笔石物种丰富度曲线(Sadler et al.,2011)Fig. 10 High resolution species richness curve revealing the diversity trajectory of the graptoloid clade(Sadler et al.,2011)
樊隽轩等耗时多年,通过GBDB对中国显生宙的地层剖面进行长期、持续性的数据录入、整理和标准化工作。根据从中遴选出的3766个已发表剖面的45318个物种的266110个生物事件,通过进一步的数据质量控制,选定待计算的数据集,并基于约束最优化法自主开发了CONOP的并行版程序,利用“天河二号”超级计算机进行计算,绘制得到了寒武纪—早三叠世海洋无脊椎生物多样性的高分辨率曲线(图11;Fan et al.,2020),其时间分辨率达到26 Ka,较国际同行(如Alroy et al.,2008)的研究精度提高了400倍。这一研究,通过GBDB平台将古生物学数据和地层学数据有机融合,极大地推动了古生物多样性研究的发展。
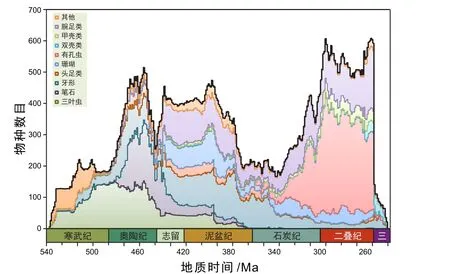
图11 古生代主要类群的种级多样性曲线(Fan et al.,2020)Fig. 11 General trajectories of Paleozoic species diversity and species diversity for major fossil groups(Fan et al.,2020)
此外,各国学者还在生物多样性分析的基础之上开展了一系列独创性的引申研究。围绕Sadler等(2009)发表的奥陶纪—志留纪高分辨率笔石多样性曲线,Cooper等(2014)对新生率、灭绝率等进行分析,认为奥陶纪—志留纪的全球气候变化与该时期的笔石演化速率密切相关。Crampton等(2016)进一步根据笔石灭绝率曲线和组群幸存曲线识别出晚奥陶世温室-冰室的转变,标志着海洋浮游生物灭绝的一个阶段性变化(Crampton et al.,2016)。随后,Crampton等(2016)对笔石的物种演替率曲线进行旋回分析,并与主要天文旋回周期进行比较,发现奥陶纪—志留纪笔石多样性的周期性变化规律可以用米兰科维奇旋回进行解释,并识别出与之相关的地球轨道偏心率周期(2.6 Ma)和斜率周期(1.3 Ma;图12)。
同样的,樊隽轩等尝试分析了生物演化与环境因素之间的耦合性,重点关注锶同位素、碳同位素、氧同位素、大气二氧化碳分压等地内环境指标,发现二氧化碳分压似乎是唯一一个表现出与生物多样性具有相似长期变化格局的环境因素(Fan et al.,2020)。
回顾古生物宏演化的研究历史,基本就是一个数据库、大数据分析方法和计算能力交互攀迭、逐步推进的过程。在古生物数据库出现之前,全球或区域大尺度的生物宏演化研究是难以实现的。此后,从单个科学家纯手工整理得到古生物学数据库,到科学家群体通过互联网协作构建在线数据库从而实现海量数据的快速集成,再到专用算法的引入和计算能力的不断提升,实现对海量数据的高效分析,古生物宏演化的研究从半定量到定量,从时间粗分辨率到高分辨率,研究精度不断提高,新的研究方向不断出现,研究的深度也在不断向跨学科的领域拓展。从中可以窥见数据驱动下的古生物学研究的几个显著特征:(1)与专业数据库的发展紧密联系:从Sepkoski离线数据库到PBDB、GBDB等在线数据平台的发展壮大,不断催生出相对于当时科学界而言的突破性原创成果。(2)数据分析的新方法不断涌现,从PBDB广泛采用的多样性统计分析方法如抽样标准化、稀疏化等方法,到Peter Sadler等采用的约束最优化方法等,这些新方法的出现,通常也会产生新的研究领域或方向,推动学科的不断发展。(3)对数据计算能力的需求不断加大,大数据量通常意味着较大的计算量,算法优化、并行计算乃至人工智能或许是未来古生物学研究的重要手段。
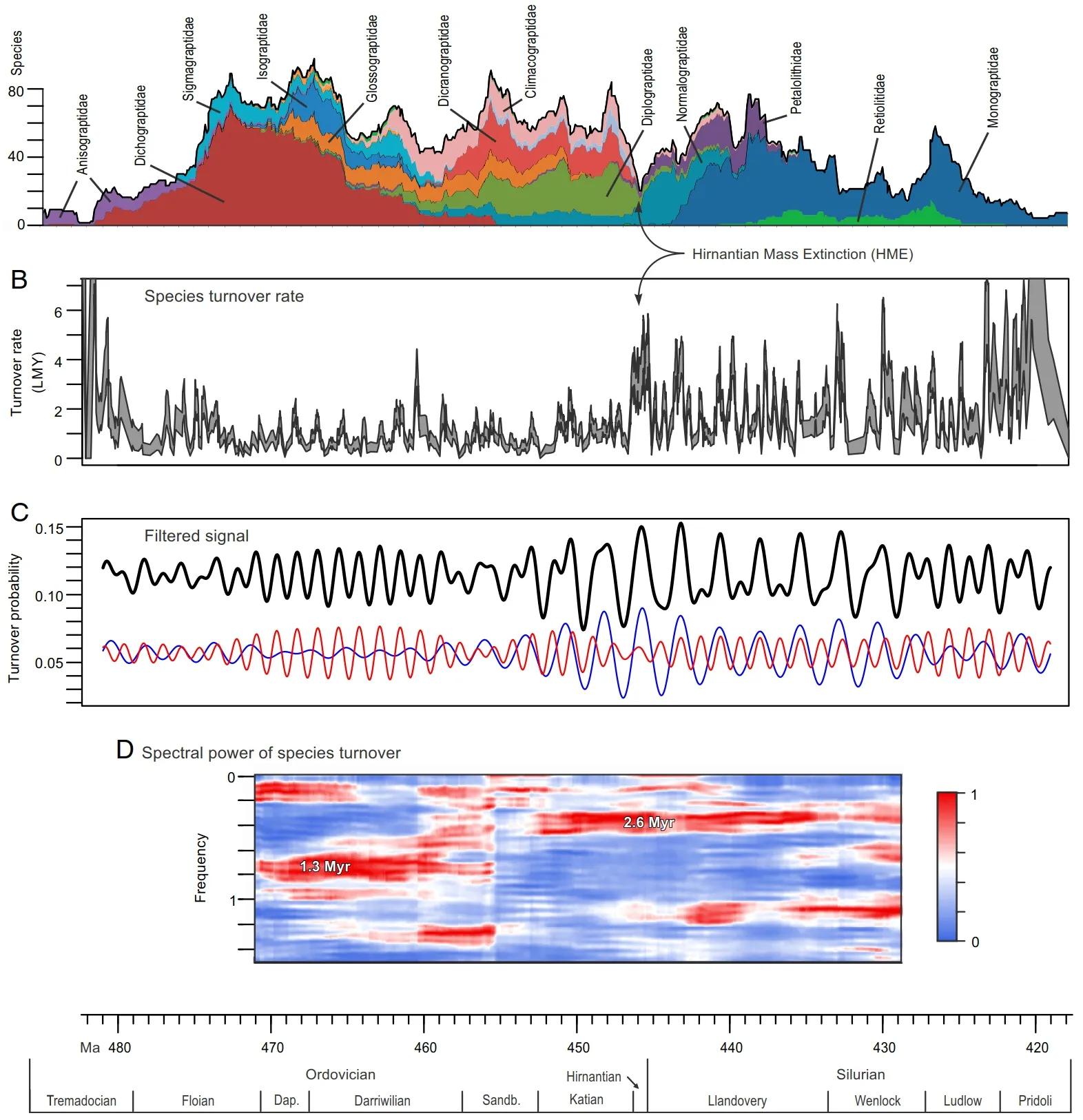
图12 笔石多样性、演替率和演替率的频谱分析(Crampton et al.,2018)Fig. 12 Graptoloid diversity, turnover, and spectral analysis of turnover(Crampton et al.,2018)
4.2 数据驱动下的生物古地理研究
生物古地理学是一个跨学科的研究领域,融合并利用了古生物学和古地理学的数据和理论,根据一定地理区域内的化石生物群的面貌,探讨化石生物群在空间和时间框架内的分布规律,从而辅助生物区系划分、古地理重建和判断古板块位置等研究(胡滨,2009)。随着信息时代的到来,数据库在生物古地理研究中的驱动作用愈加明显。
沈树忠等人使用Filemaker Pro建立了单机版的全球腕足化石数据库(Shen et al.,2009,2013),用于开展生物古地理演化研究。其数据库中包含了腕足化石的原始鉴定信息以及最新厘定意见、详细的生物地层信息、地理位置信息、岩相、构造特征等在内的三十余个字段。在该数据库收集的1425个产地的483属共计2459种的腕足数据基础上,Ke等(2016)对二、三叠纪之交全球腕足类生物古地理进行了定量分析。他们将1425个产地依据构造边界或地理分区划分至110个站点(station)中,使用二进制/丰度系数(binary/abundance coefficients)构建属级化石产出记录的数据矩阵,选择Jaccard和Ochiai相似系数计算各站点之间的动物群组成的相似性,基于得到的相似性矩阵进行聚类分析(cluster analysis,简称CA),模拟得到腕足化石产地的聚类分析分支图(图13a),同时利用PaleoMAP的成图功能绘制得到了二叠纪长兴期到三叠纪瑞替期九个时间段的腕足地理分区图(图13b),据此对该时期腕足动物的全球地理分布特征和控制因素开展了深入研究。
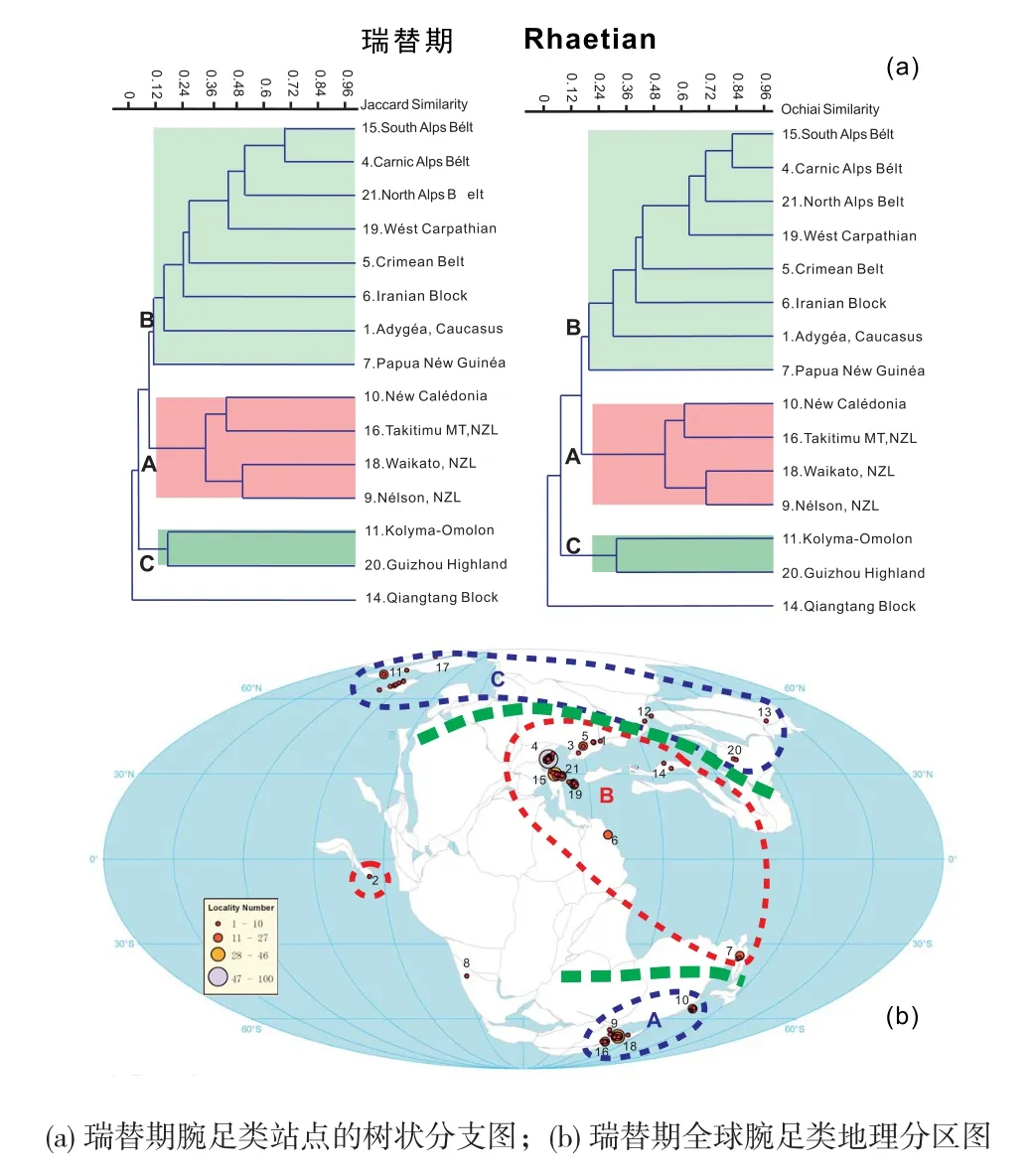
图13 腕足动物的生物古地理演化研究(Ke et al.,2016)Fig. 13 Global brachiopod palaeobiogeographical evolution in Rhaetian(Ke et al.,2016)
除此之外,美国辛辛那提大学的Arnie Miller等人依托PBDB开展的显生宙全球海洋动物的地理分异研究(Miller et al.,2009),也是典型的数据驱动下生物古地理学研究案例。PBDB的发展壮大与数据密度的不断提高,使得分析全球动物群的地理分异性及其在整个海洋动物生命历史中的变化历程成为可能。Miller等(2009)将全球划分为5°×5°的单元格,然后从PBDB中批量下载了属级别的三叶虫、腕足类、头足类和双壳类化石的产出记录,合并每个单元格里的数据,得到该单元格所代表的区域内的化石产出列表。随后,计算任意两个单元格之间动物群的相似性,绘制相似性—距离曲线,发现,古生代和新生代的相似性-距离图的变化趋势相似,单元格之间的动物群相似性与其距离成反比关系,随着距离增加,单元格之间的差异性显著增大;但是,中生代并未识别出明显的负相关关系(图14a,b)。同时,为了比较不同时间段的生物地理变化,Miller等(2009)用实线连接不同的单元格,并依据单元格之间的相似性程度设置不同颜色,颜色深代表相似性高。研究表明(图14c,d),奥陶纪时间段4表现为全球生物地理显著分异、各地动物群组成差异明显的模式,仅劳伦大陆、阿瓦隆尼亚、波罗的地区等显示了短距离的动物群相似的特点。与之相比,新生代显示了截然不同的特点,相隔数千公里的单元格之间也显示了明显的动物群相似的特点,且出现了大量沿经向分布的深色连线,表明当时生物群的分布很可能受到经向洋流的控制。
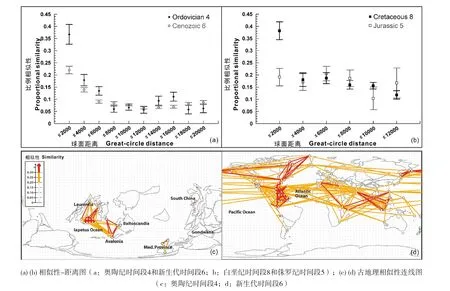
图14 显生宙全球海洋动物地理分异的演变趋势研究(Miller et al.,2009)Fig. 14 Phanerozoic trends in the global geographic disparity of marine biotas(Miller et al.,2009)
上述两项定量古地理研究亦是数据驱动下科学研究的典型案例。对于小区域、小时间尺度的古地理研究,可以通过科学家个人的努力得以实现。但正是PBDB等大型数据库的建立,加上有效的数据共享机制以及先进的大数据可视化和分析方法的引入,使得全球尺度的定量古生物地理研究成为可能。
5 一站式全生态链古生物学数据平台构想
5.1 一站式全生态链
随着古生物学及其相关学科数据的快速积累,古生物学数据库面临新的挑战:如何整合已有的多源异构数据库的数据,如何实现跨学科数据的交融,如何通过大数据的手段发现隐藏的非传统认知,如何高效地进行海量数据的快速分析、处理和成果展示、分享,等等。以上种种,亟需通过建立具有统一数据标准的开放型古生物学一站式全生态链数据平台来实现。“一站式”意味着这个数据平台需要融合大数据工作中的所有流程,包括数据收集、存储、处理、运算、分析、可视化、发表、共享等。基于这个设想,该平台需要包括但不限于以下模块:数据收集与存储模块,数据在线处理模块,数据可视化模块,在线分析工具集成模块等。并且,数据平台应支持数据的在线发表,提供DOI等以保护数据的知识产权。
数据的收集是建设该平台最为基础的一环。对于单个数据库而言,数据的产生和收集往往是一个漫长而艰辛的过程,GBDB十余人的专业录入团队耗时十年才实现中国古生物学文献数据85%的数字化,PBDB集成了410名贡献者二十余年的心血,NSB等更是执行了几十年的大洋钻探任务才获取到如今海量、珍贵的洋底数据。如果每新建一个平台便得重新收集和录入所有的数据,那么这无疑是一个耗时、费力并且无意义的举措。当前,海量的优质数据分散在全球的各个数据库中,应当采取全新的思路进行数据的集成。受到前述多个数据库集成平台的启发,我们可以考虑在各个数据库中开放API接口,简化和规范从不同数据源获取数据的过程,实现国际同类数据库间的数据共享、集成与交互,促成不同数据库的数据实现无缝链接,而不是重新构建一个新的数据门户网站。研究者可以通过任一平台实现对所有数据的统一查询并打包返回所需的结果数据。基于一站式平台进行新数据收集的过程中,应当制定统一的数据标准,设立严格的数据审核和上传制度,从而保障数据质量。
数据的在线处理、多种分析方法的集成将是数据平台建设的一大亮点,也是实现一站式全生态链的核心环节。但是,古生物学旗下分支学科众多,且各分支学科专业性强,笔者认为应当凝练关键科学问题,建立典型应用案例,通过众包的方式交由不同团队进行建设,平台提供软、硬件技术支撑,最终开发、部署一系列常用的可视化和分析功能。对于难以在线构建的数据处理和分析功能,如对计算力有较高要求的高性能计算应用,一方面可以针对性开发数据导出功能,GBDB支持CONOP9等多格式导出数据的功能便具有借鉴意义;另一方面可以开发配套软件辅助分析,例如,NSB团队根据实际需求开发了年龄模型制作软件(NSB_ADP_wx),辅助构建钻孔年龄值,Neotoma团队开发建设了Neotoma Explorer,提供数据检索、可视化和下载等功能。
数据成果保存与展示将是平台生态链中的最后一环。数据库应当提供针对数据成果的保护政策,例如为在线发表的化石3D模型或数据分析论文的原始数据集提供DOI等。提供全面、详实、易懂的数据平台操作指南也是平台不可忽略的一点,这方面可以借鉴PBDB和Neotoma提供的新手指南服务:PBDB Navigator录制了全流程视频操作介绍;Neotoma Explorer针对用户设计了详细的软件在线使用手册。
5.2 科普与科研的有机结合
科学家的一个重要社会职责是科学普及,科技的进步可以为科普不断提供新的生长点。但是,通过此次调研可以发现,目前大多数的古生物数据库只聚焦科研或科普,很少两者兼顾。基于化石的收藏型数据库,比如各类博物馆设计的数据库,更多地服务于科普,科研职能较弱;而综合研究型的古生物学数据库通常重点关注科研工作者的需求,对科普职能的考虑极少,导致其科普功能非常薄弱。在构建古生物数据平台时应当考虑科普与科研的有机结合,研究者既可以通过平台开展科研工作,也可以基于平台进行科普活动,让最新的科学问题、研究手段走入社会。多媒体、虚拟现实/增强现实、人工智能等先进技术的集成与应用有望成为重要切入点,比如,可以考虑添加剖面全景可视化模块,让大众“走入”古生物工作的现场;可以考虑提供优质的化石照片或者3D模型供大众观赏;可以围绕大众热点开展线上线下科普活动,让科学家走入课堂,让化石爱好者参与数据采集和加工等。
致谢:感谢南京大学沈树忠院士对论文提出的修改意见和建议。本文系“深时数字地球”(Deep-time Digital Earth)大科学计划的系列成果之一。
猜你喜欢
青少年科技博览(中学版)(2023年9期)2023-11-30 03:41:56
学苑创造·A版(2023年5期)2023-06-04 13:17:45
青少年科技博览(中学版)(2023年1期)2023-03-17 00:44:34
黄河·黄土·黄种人(华夏文明)(2021年6期)2021-09-28 02:14:08
现代仪器与医疗(2021年1期)2021-06-09 05:53:54
科学(2020年1期)2020-01-06 12:21:34
生物进化(2019年3期)2019-02-16 04:26:33
小学科学(2015年2期)2015-03-11 21:52:45
小学科学(2015年1期)2015-03-11 14:17:16
小猕猴智力画刊(2012年11期)2012-04-29 00:44:03
