
基于卷积神经网络模型的多肉植物种类识别
2020-08-20 01:57:12李晓红吴仲华刘海秋马慧敏
贵州师范学院学报 2020年3期
李晓红,吴仲华,刘海秋,马慧敏
(安徽农业大学信息与计算机学院,安徽 合肥 230036)
0 引言
能够将多肉植物正确分类是研究多肉植物的基础和前提,对探索多肉植物系统进化规律和保护多肉植物多样性具有深远的意义和影响。基于机器视觉技术,利用传统的图像特征对植物叶片进行分类已有很多的研究,如2014年董红霞等人[1]利用形状与纹理特征对植物叶片进行分类;2017年吴笑鑫等人[2]以支持向量机(SVM)算法为基础构建分类器,基于多特征融合研究花卉种类识别。传统的分类方法比较复杂,大都依靠人为地选取特征,很难得出高精确度。
近几年,涌现出了许许多多图像识别效果非常好的深度神经网络模型,比如VGG Net[3]、GoogLeNet[4]、ResNet[5]等,它们在ILSVRC比赛中都具有超高的识别精度。卷积神经网络已广泛应用于手写汉字识别[6]、人脸识别[7]、语音识别[8]等领域。目前,随着机器学习技术不断成熟与完善,深度学习技术在图像识别方面得到了很好的应用,利用深度学习技术对植物和花卉的特征自动提取与分类已经逐步展开。刘德建[9]将深度学习技术引入花卉识别应用领域,针对收集的116类花卉图像,总共79544张图片,利用LeNet网络进行训练和测试,得到了约80%的Top5识别精度。傅弘等[10]利用神经网络准确地识别出叶脉图像。沈萍等[11]用含有多个隐层的深度卷积神经网络识别花卉,结果与传统神经网络和支持向量机相比提升了10%以上的准确率。深度学习技术在花卉与植物叶片识别方面已经有很好的效果,然而在多肉植物种类的识别方面缺少相关的研究。对于在外形上具有极大相似性的多肉植物,人眼区分尚且具有一定的难度,传统的分类方法更是不易。本文分别以莲科和具有高相似度的玉露科各4个品种为对象,研究基于卷积神经网络的多肉植物种类识别,以实现对多肉植物的快速准确分类。
1 材料与方法
1.1 图像采集
用相机在花卉市场、温室大棚以及室内三个场景对8类多肉植物进行图像采集,构建数据集。每种多肉植物采集200张图像,莲和玉露2个数据集分别为800张。部分多肉植物图像如图1所示 ,图像采集的条件包括不同的背景环境,不同的光照以及多肉植物的不同部位,使整个图像数据集更加充分完备,防止训练中过拟合现象的发生。

图1 8种多肉植物图像
1.2 图像增强
利用CNN模型对多肉植物进行类型识别,最大的优点就是可以自动提取特征,不需要人工手动提取。但是CNN模型需要大量的数据集进行特征的自动学习,所以需要进行图像增强,扩充数据集。数据集扩充有助于增加数据的多样性,增强CNN模型的鲁棒性,避免过拟合现象的发生。
图像增强的方法主要是分别对相机拍摄的800张图片随机进行上下翻转、左右翻转以及图像亮度的调整。首先使用tf.image.decode_jpeg()函数对原始图像进行解码操作,而后使用tf.image.random_flip_left_right()函数对上述解码图像随机左右翻转。因大量输出会产生过多相同图片,产生过拟合现象,影响测试精度,所以图像少量输出。使用tf.image.random_flip_up_down()函数对上述解码图像随机上下翻转,同样图像少量输出。使用tf.image.random_brightness()函数对解码图像以及上述翻转后的图像进行随机亮度调整,max_delta=0.4,输出图像。最终两数据集分别扩充为2400张图像,图2为选取的草玉露图像扩充过程。同时,为了增加计算机的计算速度,将图像大小进行归一化处理,作为CNN模型的输入。
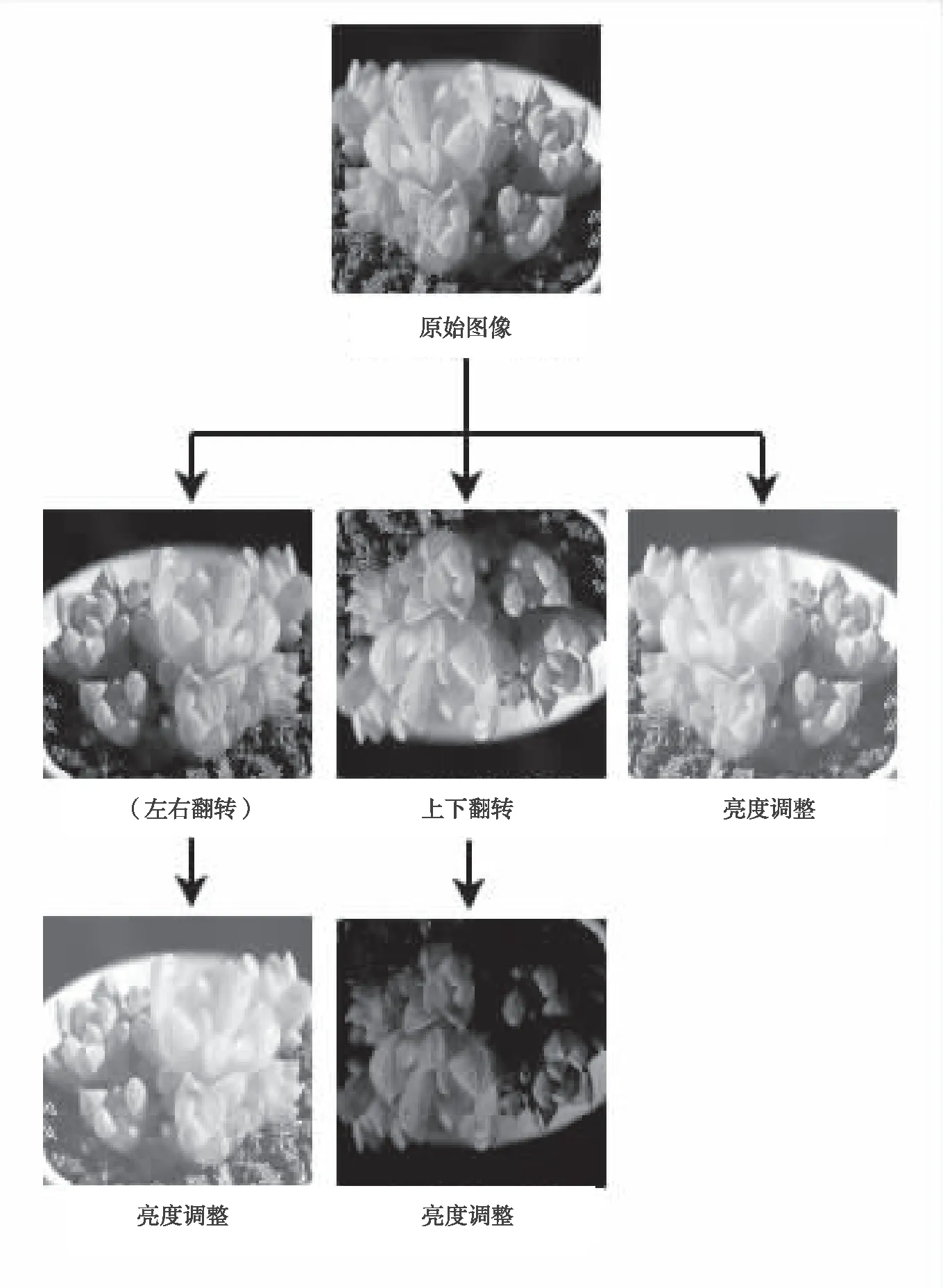
图2 草玉露图像扩充过程
2 CNN模型原理
2.1 CNN模型基本框架
本研究采用的CNN模型基本结构如图3所示。卷积神经网络结构由输入层、卷积层和池化层、全连接层及输出层组成。
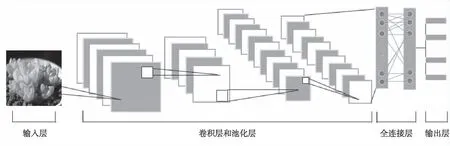
图3 CNN模型基本结构
2.1.1 输入层。本项目原始图像为3通道RGB图像,为了加快计算速度,将图像大小做归一化处理,输入到网络中。
2.1.2 卷积层。卷积操作是用预先设置好大小的卷积核与特征图进行卷积求和,达到特征提取的作用。卷积层的计算公式为[12]:
yl=f(wl⊗xl-1+bl)
(1)
其中yl为当前层输出特征图,f(·)表示激活函数,wl表示当前层与上一层输出特征图的卷积核;xl-1为上一层输出特征图;bl为当前层的偏置。试验中采用ReLu函数,可增加网络的稀疏性,加速网络收敛,其表达式为:
f(x)=max(0,x)
(2)
2.1.3 池化层。池化层分为平均池化与最大池化两种,池化操作的主要目的是降低整个区域中的参数,将某个区域内的统计特征作为该区域特征的代表,同时该参数还能够表示该区域的具体特征。池化过程计算公式为[12]:
al=f(βldown(yl-1)+bl)
(3)
al为当前层池化层输出,f(·)表示ReLu激活函数,βl为乘性偏置,down(·)表示下采样函数,yl-1为上一层卷积层输出,bl为加性偏置。
2.1.4 全连接层。将之前池化层的输出转化成一维数组,具有分类作用,便于后面的输出。全连接层每个神经元的输出为:
h(x)=f(wTx+b)
(4)
h(x)表示神经元的输出值,f(·)表示ReLu激活函数,w表示权值向量,x表示输入特征向量,b表示偏置。
2.1.5 输出层。在本实验中最终输出4个分类结果。
2.2 随机梯度下降算法
本实验在卷积神经网络模型的训练中采用随机梯度下降算法,通过不断降低损失函数的函数值来学习建立后的所述卷积神经网络的参数[12]。
其中损失函数表示为:
(1-yi)log(1-y_predictedi))
(5)
式中,yi为真实的标签值,y-predictedi为预测的标签值。
训练准确率表示为:
(6)
式中,n为正确的预测数,N为训练样本总数。
卷积神经网络模型训练时采用的随机梯度下降法是指每一次迭代中使用所述样本进行学习参数和更新,每一代的学习参数和更新可表示为:
Wt+1=Wt-ηtgt
(7)
gt=ΔJis(Wt;X(is);X(is)),is∈{1,2,…,n}
(8)
式中,t为迭代的次数,Wt为t时刻的模型参数,ηt为学习率,J(W)为代价函数,is表示随机选择的一个梯度方向。
3 CNN模型设计
本实验中设计了两种卷积神经网络模型:模型M1与模型M2,分别对两种数据集进行训练并且测试。
模型M1总体架构为(卷积层+最大池化层)×2+全连接层×2+分类输出。卷积层C1使用64个3×3×3的卷积核与64×64×3的原始图像进行卷积操作,卷积核步长为1,填充为“same”,激活函数ReLU(),产生64×64×64的图像,经过3×3最大池化,步长为2,填充为“same”,得到64×64×64的图像。卷积层C2使用16个3×3×64的卷积核与64×64×64的图像进行卷积操作,卷积核步长为1,填充为“same”,激活函数ReLU(),产生64×64×16的图像,经过3×3最大池化,步长为1,填充为“same”,得到64×64×16的图像。全连接层FC3,用128个神经元将池化层的输出转化成一行,并通过激活函数ReLU(),全连接层FC4也为128个神经元,最后Softmax回归输出4类。表1为模型M1的参数变化过程。

表1 M1参数变化过程
模型M2总体架构为(卷积层+最大池化层)×4+全连接层×3+分类输出。卷积层C1使用32个5×5×3的卷积核与100×100×3的原始图像进行卷积操作,卷积核步长为1,填充为“same”,激活函数ReLU(),产生100×100×32的图像,经过2×2最大池化,步长为2,填充为“valid”,得到50×50×32的图像。卷积层C2使用64个5×5×32的卷积核与50×50×32的图像进行卷积操作,卷积核步长为1,填充为“same”,激活函数ReLU(),产生50×50×64的图像,经过2×2最大池化,步长为2,填充为“valid”,得到25×25×64的图像。卷积层C3使用128个3×3×64的卷积核与25×25×64的图像进行卷积操作,卷积核步长为1,填充为“same”,激活函数ReLU(),产生25×25×128的图像,经过2×2最大池化,步长为2,填充为“valid”,得到12×12×128的图像。卷积层C4使用128个3×3×128的卷积核与12×12×128的图像进行卷积操作,卷积核步长为1,填充为“same”,激活函数ReLU(),产生12×12×128的图像,经过2×2最大池化,步长为2,填充为“valid”,得到6×6×128的图像。全连接层FC5用1024个神经元将池化层的输出转化成一行,全连接层FC6为512个神经元,全连接层FC7为4个神经元,最终分类输出4类。表2 为模型M2的参数变化过程。
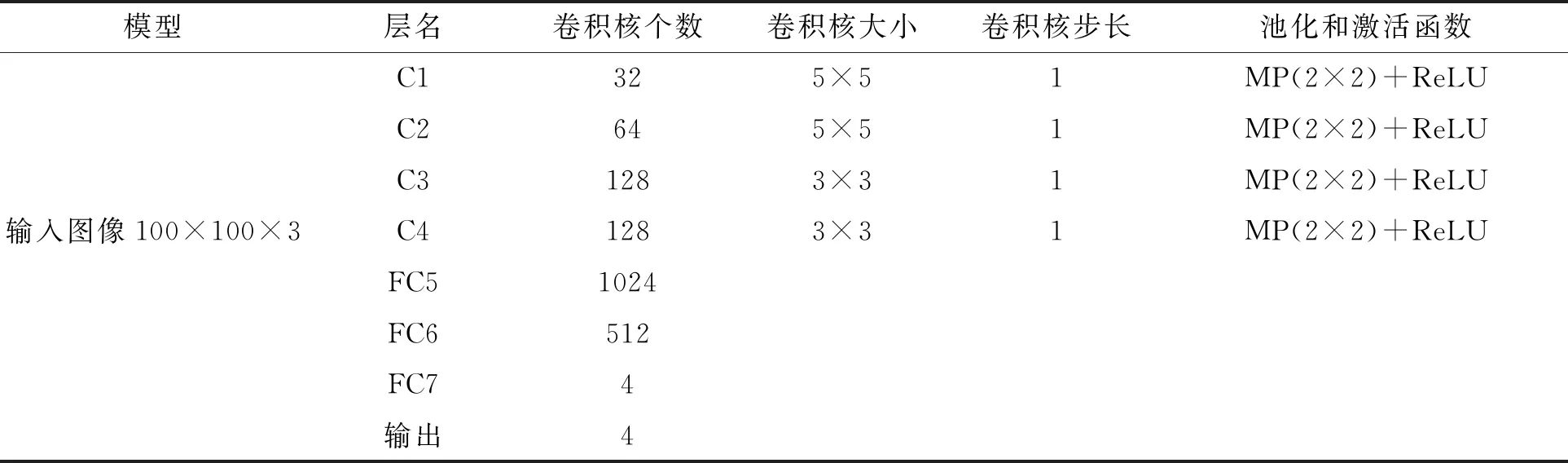
表2 M2参数变化过程
4 结果与讨论
4.1 数据集分布
实验中有两种数据集,分别为莲与玉露。经图像增强后,两种数据集各有4类,每类为600张图像,共2400张图像。实验过程中将数据集按4∶1分为训练集与测试集,表3与表4分别为两种数据集具体分布情况。

表3 莲数据集分布

表4 玉露数据集分布
4.2 模型训练精度
实验中设置两模型的最佳学习率,M1学习率为0.0001,M2学习率为0.001。用两模型分别对莲与玉露数据集训练2000步,每隔10步记录一次损失值与训练精度,CNN网络中具体计算为公式(5)、公式(6),将得到的数据用origin软件进行处理,图4为两模型训练损失值,图5为两模型训练精度曲线。
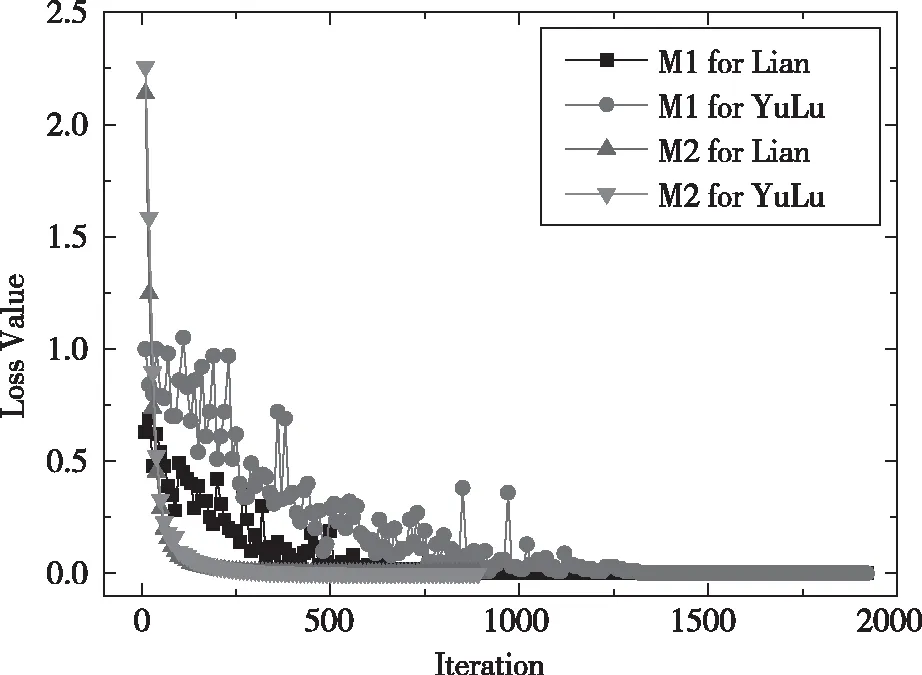
图4 训练损失值变化曲线
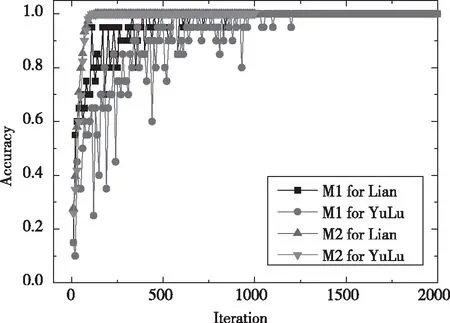
图5 训练精度变化曲线
从图4和图5可以看出,对于莲和玉露两个品种,在M1和M2模型中,莲的损失值比玉露更快衰减到0,莲的训练精度比玉露更快接近1。由于玉露品种具有更高的相似性,因此比莲品种更难达到稳定状态。对比M1和M2两个模型,由于M2比M1多了两层卷积层和一层全连接层,能够更好地提取图像特征,因此M2比M1具有更好的收敛性,且状态更稳定,不容易产生波动。
4.3 模型测试精度
实验中得出M1和M2在测试集上最终的测试精度如表5所示,由于玉露品种具有更高的相似性,因此在两模型中的测试精度要低于莲。同时,由于M2具有更深的卷积层数,能够更好地提取图像特征,因此在两数据集上的测试精度要高于M1。
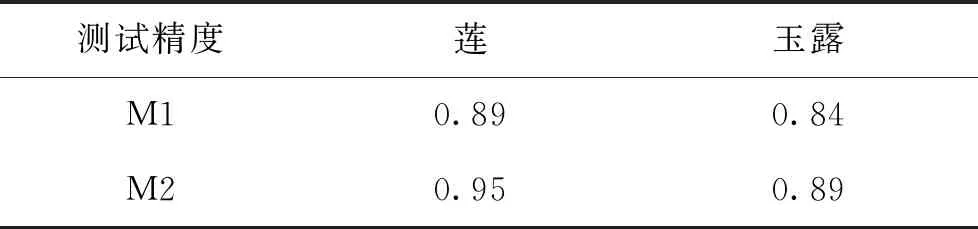
表5 测试精度
5 结论
本实验中设置了两种卷积神经网络模型M1与M2,对多肉植物莲与玉露的两种数据集,都具有较高的训练与测试精度,符合常规的图像识别要求。卷积神经网络自动识别图像特征,避免了传统手动标记复杂、耗时等缺点,具有较大的优越性。同时得出结论:对于多肉植物,较深的网络具有更好的图像识别效果。由于本实验中数据集数量的限制,测试精度依然有待提高。下一步笔者将采集更多的多肉植物图像,加快CNN模型训练速度,提高测试精度,同时实现更多多肉植物种类的识别。
猜你喜欢
无线电工程(2024年8期)2024-09-16 00:00:00
科学技术与工程(2023年3期)2023-03-15 10:34:12
今日农业(2022年16期)2022-09-22 05:38:22
软件导刊(2022年3期)2022-03-25 04:45:04
成都信息工程大学学报(2021年5期)2021-12-30 06:25:30
东坡赤壁诗词(2021年1期)2021-03-24 18:25:36
今日农业(2020年15期)2020-12-15 10:16:11
林业与生态(2019年2期)2019-04-12 02:28:22
计算机技术与发展(2019年1期)2019-01-21 00:56:38
河北科技大学学报(2015年5期)2015-03-11 16:16:37
