
古文识别平台的设计与实现
2020-08-17 09:24冯力方吴芦婷刘敏王颖高荣
现代信息科技 2020年9期
冯力方 吴芦婷 刘敏 王颖 高荣


摘 要:为推动古文数字化,促进古文资源共享,需要借助现代技术进行古文识别的工作,但现阶段能提供古文识别功能的平台非常匮乏,并且这些平台能实现的功能有限,不能从根本上解决古文识别难、不准确、传播难等问题。针对这些情况设计了古文识别系统,该系统为用户提供古文资料识别和用户资源共享两种主要功能,能够有效满足古文研究工作者和古文爱好者的需求,也能够对古文资源进行有效保护和利用。
关键词:古文识别;深度学习;系统设计
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2020)09-0079-03
Design and Implementation of Ancient Prose Recognition Platform
FENG Lifang,WU Luting,LIU Min,WANG Ying,GAO Rong
(School of Information and Statistics,Guangxi University of Finance and Economics,Nanning 530003,China)
Abstract:In order to promote the digitization of ancient scripts and promote the sharing of ancient scripture resources,it is necessary to use modern technology to perform ancient script recognition. However,at this stage,platforms that provide ancient script recognition capabilities are very scarce,and the functions that these platforms can achieve are limited and cannot be fundamentally solved difficulties in identifying,inaccurate and difficult to disseminate in ancient texts. In response to these situations,an ancient text recognition system was designed. This system provides users with two main functions:ancient text data recognition and user resource sharing and exchange,which can effectively meet the needs of ancient text researchers and ancient text lovers,and can also effectively protect ancient text resources use.
Keywords:ancient text recognition;deep learning;system design
0 引 言
古文是數千年中华传统文化的重要载体之一,对古文资源进行保护和有效利用不仅有利于传承和发扬中华传统文化,也有利于研究人员对中华传统文化的研究。因此古文数字化具有重要意义。2017年,我国出台的“十三五规划”中明确指出需要加强古籍文档的数字化工作,推动古籍文档数字化,促进古籍资源共享[1]。实现古文数字化,能提高在大量的古文资源中进行检索和历史溯源等任务的效率,也为古文的深度加工提供了编辑基础。古文存在于古籍中,为了减少对古籍的损坏,古文数字化可以把古籍以图片的形式保存下来供人参考,但是图片中的文字存在不可编辑、不好查找、不方便检索的问题,而要将古籍通过人工录入的方式完成数字化又存在浪费人力物力的问题。为了有效解决古文数字化的问题,提高古文数字化的效率,需要利用现代互联网技术,构建包含古文资料识别和用户资源共享功能平台的智能工作系统。目前已有一些针对古文数字化的研究,黄伟国[2]设计了一种古籍文档图像智能标注系统,但功能比较单一,不支持基于整张图片的文字检查和识别功能。王春颖[3]设计了一种方书古籍数字化平台,但缺少在线交流平台,对古文资源共享和用户交流有较大影响。为了更好地解决这个问题,基于国家级大学生创新创业项目资金支持,本文设计实现了一个新的古文识别平台,该平台的主要用户是古文研究工作者和古文爱好者,能降低古文研究工作者的工作难度,促进古文资源开放化。
1 系统总体结构
古文识别系统采用B/S架构即浏览器和服务器架构模
式。系统前端页面结合采用HTML、CSS、AJAX、Bootstrap、jQuery等技术框架来构建,采用这些框架使得Web开发更加快捷,提升了前端开发的效率,降低了开发成本,缩短了开发周期。
平台后台架构由Python、Django 2.1、MySQL等技术框架实现,具有效率高、稳定性强、移植性好、便于维护等特点。在前期进行数据准备时,利用Python语言编写程序爬取网络上的古文资料,存入数据库中作为数据集,并对数据集进行数据清洗后用于后续卷积神经网络模型的训练。其中数据采集阶段使用Scrapy框架编写爬虫程序进行数据采集,Scrapy是一个成熟的爬虫框架,支持异步爬取,并发性强,性能较高。数据清洗则先采用OCR技术对数据集进行初步的识别后,再通过人工进行筛选与校验,完成数据集的标注。运用TensorFlow框架来进行模型的训练,TensorFlow框架被广泛应用于多种机器学习和深度学习领域,具有跨平台、接口丰富、易部署等优点。
系统总体架构图如图1所示,整个系统可分解为三层。应用层提供图片识别、PDF识别、古文论坛、识别任务区等应用功能。策略层中共享平台功能通过积分统计、用户管理的方式实现;识别模型为CNN模型,使用图像灰度化、图像二值化、OCR识别、倾斜矫正等图像处理技术处理后的古文图像数据和用户反馈数据来建立;基础数据处理通过Python提供的功能库来完成数据采集、数据清洗、数据标注、数据缓存等操作。数据层通过MySQL数据库对业务数据和日志数据进行缓存。
2 系统模块功能
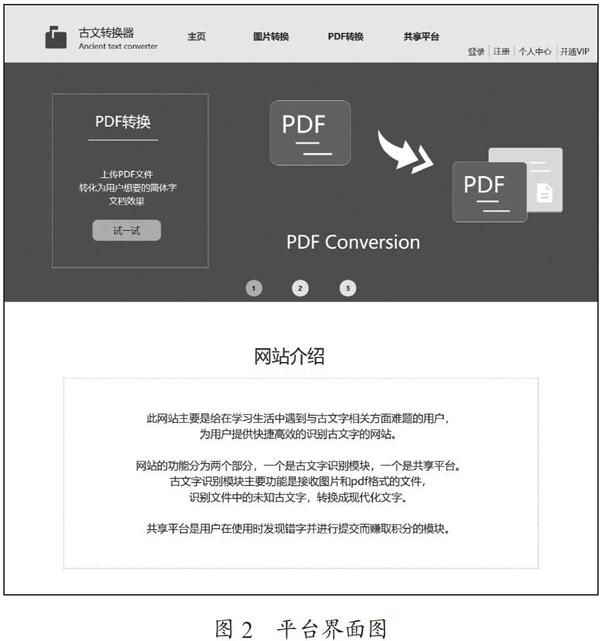
古文识别平台由两个子平台组成,分别为古文资料识别和用户资源共享功能平台,平台界面图如图2所示。
2.1 古文资料识别平台
古文资料识别平台的主要功能是接收用户上传的文件,可以是图片文件或PDF文件。平台将识别上传文件中的古文文本,将其转换成简体中文,并以现代阅读习惯重新排列展示。
該平台分为图片识别模块和PDF识别两大模块。图片识别模块用于上传一张或多张含有古文文本的图片,将图片文件中的古文文本转换为现代文本后进行展示,支持上传BMP、JPG、PNG、GIF等多种图片文件格式。PDF识别模块用于上传古文文本PDF文件,将PDF文件中的古文文本转换为现代文本后进行展示,一次仅支持上传一份PDF文件,支持的文件大小为最大200 MB。
两个识别模块都具有文件校验、修改识别结果、下载识别结果的功能。文件校验功能会在用户选择上传文件时对文件的格式进行校验,若用户上传的文件格式不正确,则触发弹窗提醒用户重新上传,此功能保证了后续识别文件格式的正确。修改识别结果功能是为了在识别完成后,用户能够对识别结果中不正确的文字进行修改,使识别结果更加准确,且用户修改的结果会被记录在数据库中用于修正未来的识别结果,提升识别的准确率。下载识别结果功能用于将识别的最终结果保存到用户指定格式的文件中,可选的文件格式有TXT、DOC、DOCX、PDF等,方便用户将识别结果用于后续所需的工作。
PDF识别界面如图3所示。
图片转换示例如图4所示。
2.2 用户资源共享功能平台
用户资源共享平台设置的主要目的是给用户之间提供更好的交流环境,同时通过人工识别的方式来识别平台无法正确识别的古文文本。
用户资源共享平台主要有“古文论坛”和“任务区”两个功能板块。“古文论坛”为用户之间的交流提供了一个交流论坛,同时也给古文爱好者和社科研究人员提供了一个古文交流平台,用户可以实时讨论在识别过程中遇到的古文文本问题。“古文论坛”内含有“签到处”“交流区”和“活跃排行”“论坛公告”四个模块。在“签到处”用户可进行每日签到获得用户积分;“交流区”分为“闲谈灌水”“经验分享”“古籍咨询”三大板块,用户可选择相应板块畅所欲言;而“活跃排行”则是根据日、月、年的时间段展示积极发帖的用户,鼓励用户积极进行讨论交流,增加网站的流量;“论坛公告”用来展示管理员发布的公告。
在“任务区”用户可接受其他用户发布或本平台发布的识别古文文本任务,通过完成这些平台未能成功识别的任务赚取用户积分,以此来兑换古文文本的识别次数。这样可以通过人工识别的方式提高平台识别的正确率,提高用户积极性。
3 结 论
古文识别平台以系统实用、结构合理、技术规范作为基本设计原则,规划了系统的整体架构,为用户提供了清晰简洁,智能友好的交互界面。操作简便灵活、便于管理和维护,实现了古文资料识别和用户资源共享功能平台的集成,且平台之间能够进行数据共享。平台初期通过爬虫程序采集古文资料,使用OCR技术与人工标注等方式来获得训练模型所需的数据集。在得到初步训练的模型后,数据集来源则主要为用户上传的古文资料,在用户进行识别后,修改识别结果并下载这一过程,相当于无形中完成的一次清洗标注。随着用户使用次数的增加,模型所获得的训练样本不断扩大,模型的识别率也逐渐提高。用户资源共享平台中每位普通用户用于进行古文识别的积分有限,在消耗完积分之后,可通过完成此平台中发布的识别古文任务来赚取积分,鼓励用户自发地进行古文的识别,增加了用户获取积分的途径来避免用户的流失,任务中用户所上传与识别的古文资料也是数据集的来源之一。
数千年的中华文明留下浩如烟海的古籍,这些古籍对现代人了解古代历史、社会和文化发展具有重要的价值。古文文献数字化是时代和社会的呼声,也是构建中国特色哲学社会科学的重要步骤。古文识别系统顺应古籍资料数字化、智能处理和相关人文计算研究的发展潮流,充分利用信息技术手段,将古文资源识别和用户资源共享功能模块一一实现,为古文研究人员和古文爱好者提供了一个技术支持和交流的平台。
参考文献:
[1] 中国政府网.文化部关于印发《“十三五”时期全国古籍保护工作规划》的通知 [EB/OL].(2017-09-06).http://www.gov.cn/xinwen/2017-09/06/content_5223039.htm.
[2] 黄伟国.古籍文档图像智能标注系统的设计与实现 [D].广州:华南理工大学,2019.
[3] 王春颖.方书古籍数字化实践研究 [D].哈尔滨:黑龙江中医药大学,2015.
作者简介:冯力方(1999.09—),女,汉族,海南琼海人,本科,研究方向:数据挖掘;吴芦婷(1998.11—),女,汉族,广西北海人,本科,研究方向:数据挖掘;刘敏(1999.01—),女,汉族,广西贺州人,本科,研究方向:数据挖掘;王颖(1999. 08—),女,汉族,广西桂林人,本科,研究方向:数据挖掘;通讯作者:高荣(1979.02—),男,汉族,山东潍坊人,讲师,硕士研究生,研究方向:数据挖掘。
猜你喜欢
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
数字技术与应用(2016年9期)2016-11-09
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
科技视界(2016年22期)2016-10-18
企业导报(2016年6期)2016-04-21
