
基于K-means聚类分析的ShadowscoksR流量识别研究*
2020-08-14 06:32倪绿林
通信技术 2020年8期
赵 伟,倪绿林,李 枫
(国防科技保密通信重点实验室,四川 成都 610041)
0 引言
随着互联网、物联网以及云技术的快速发展,网络设备和网络用户的数量呈爆发式增长,随之而来的是爆发式增长的流量信息。据互联网知名商业公司Miniwatts的调查统计[1],截至2019年12月31日,全球互联网用户达到45亿,占目前全球人口的58%。可见,互联网已经成为人们生活的重要组成部分,网络管理面临着巨大挑战。图1给出了Miniwatts公司对全球互联网用户的统计信息。
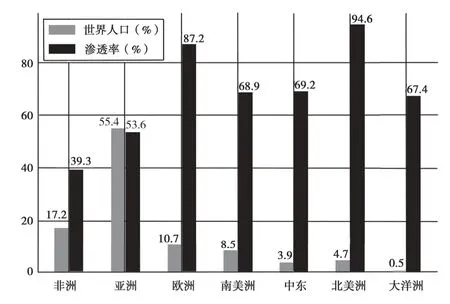
图1 2020年全球各大洲网络用户分布
为了管理和规划网络流量,网络服务公司经常使用流量识别技术对网络中的流量进行分类。但是,随着各种新的网络应用的加入和网络通信技术的发展,网络流量组成结构变得越来越复杂。流量识别技术成为相关部门管理和维护网络的重要手段。
1 相关研究
文献[2-4]介绍了近期流量识别技术发展的情况,其中大部分是针对非加密流量的介绍。目前,网络流量识别技术包含基于端口的识别技术、基于应用协议特征码识别技术、基于行为特征的识别技术和基于机器学习的识别技术4类。基于端口的识别技术部署简单,适用于传统的网络环境。它通过识别TCP/UDP包头中的目的端口号,找到对应于该端口的网络应用完成流量分类[5]。文献[6]采用端口映射的方法对p2p流量进行研究分类,简单易操作,容易实现,只需要简单的规则既可以完成流量识别,且效率和准确率很高。缺点是无法识别不使用默认端口的应用流量。为了解决上述问题,深度包检测技术(Deep Packet Inspection,DPI)应运而生。Dreger[7]等使用DPI技术检测包载荷中的特定字符串对流量进行分类。Grimaudo[8]等在DPI的基础上使用层次化分类结构,建立了一个对流量细化分类的层次自学习模型。DPI的优点是可以根据现有的特征库对流量数据分类且准确率高。但是,DPI的缺点也很明显:需要建立、维护特征库;只能检测未加密流量,无法识别加密流量。为了解决上述问题,研究者们将机器学习的概念引入加密流量识别中。一般将结合机器学习的流量识别技术称为深度流检测技术(Deep Flow Inspection,DFI)[9]。Moore等人[10]使用有监督的朴素贝叶斯机器学习方法实现对不同应用流量的分类,实验结果具有很高的准确率,但是没有解决占比很小的不均衡样本识别效果不好的问题。Bernaille等人[11]根据聚类的方法,通过K-means算法分类流量,只统计TCP的前几个数据包的特征来区分不同的流量。目前,公认对流量统计特征比较全面的是由剑桥大学的Moore[12]所在的小组总结的248维流量特征,包括了包维度、时间维度等不同统计特征。
本文的研究内容结合流载荷特征和流行为特征,通过K-means聚类分析,结合LightGBM方法,对ShadowscoksR(SSR)应用的HTTP伪装流量进行有监督学习。根据在加密流量伪装成普通HTTP流量下的有效识别规则,它的精度能够达到95%,召回率能达到100%,准确率能达到99%。
2 ShadowscoksR通信原理
SS是一款基于Socks5协议的可翻墙软件,原理如图2所示。它使用python、C#、C++等语言开发,开源代码目前挂载一些公开网站,由志愿者维护。SS的运行原理与代理匿名通信软件的运行原理相同,都是通过搭建好的特定服务器作为中转服务器来完成数据传输。通过在本地和远程服务器之间配置相同的加密密码、加密方式等参数,可以访问国外资源。当本地访问国外某网站时,客户端会将访问请求发送给远程服务器。远程服务器将访问该网站,并将访问到该网站的数据通过加密的方式反馈给本地客户端,再由客户端解密成可视资源。
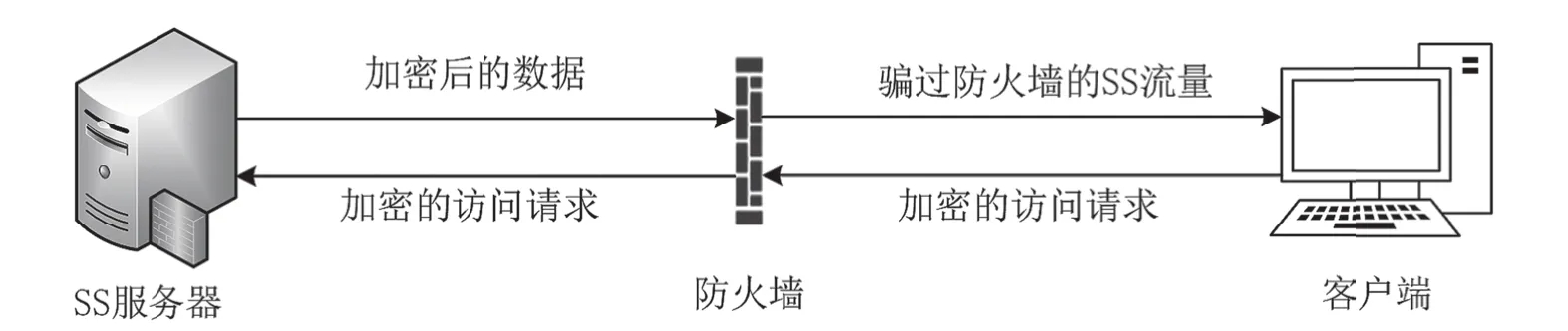
图2 Shadowscoks通信原理
而SSR是SS的升级版,也是增强版。如图3所示,SSR的整个运行原理与SS的运行原理大致相同,只是为了保证数据的安全性和抗检测性,SSR在SS的“加密”基础上增加了“协议”和“混淆”插件选项。“协议”插件的主要功能是在将网络应用数据“加密”前按照某种格式进行封装,增加数据的安全性;“混淆”插件的主要功能是将网络应用数据在“加密”后伪装成包括HTTP、HTTPS等标准的网络协议,增加数据的抗检测性。目前,最新的SSR版本为5.15。该版本中“协议”插件支持13种可选项,“混淆”支持6种选项,“加密”支持AES系列、IDEA、RC4等十几种加密算法。SSR与SS一样,代码都是开源的,目前由志愿者维护。
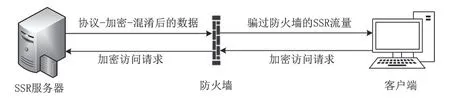
图3 ShadowscoksR通信原理
3 聚类算法和LightGBM
3.1 K-means聚类算法
K-means聚类算法是一种简单的迭代型聚类算法,采用距离[13]作为相似性度量,从而将给定数据集分为k个类,具体过程如下:
(1)随机选取k个样本作为初始聚类中心;
(2)计算各样本与聚类中心的距离;
(3)将各样本回归与距离最近的聚类中心;
(4)求解各个类的均值作为新的聚类中心;
(5)如果聚类中心不变或者达到迭代次数,算法结束,否则回到第(2)步。
3.2 LightGBM及其原理
LightGBM是boosting集合模型的新进成员,由微软提供的开源机器学习模型,和XGBoost一样高效实现GBDT。原理上,它和GBDT和XGBoost一样,都是采用损失函数的负梯度作为当前决策树的残差近似值来拟合新的树。相对于XGBoost,LightGBM具有训练效率快、占用内存低、高准确率、支持并行学习以及支持大规模数据等更多优势。
LightGBM主要包括两个算法:单边梯度采样(Gradient-based One-Side Sampling,GOSS)和 互斥特征绑定(Exclusive Feature Bundling,EFB)。
GOSS保留所有梯度较大的实例,在梯度小的实例集合中进行随机采样。为了降低对数据分布的影响,在计算信息增益时,对小梯度实例加入常数乘量。GOSS首先根据数据的梯度绝对值进行排序,选取前x个实例,在剩余数据中选取y个实例;其次,在计算信息增益时将小梯度数据乘(1-x)/k,使模型更加关注训练不足的实例而不会改变数据集的分布。
EFB是一种通过捆绑特征的方式达到降维的技术,以此提高计算效率。只有互斥的特征(一个特征值为0,而另一个不为0)才能被捆绑,这样不会丢失特征信息。假如两个特征并不是完全互斥的(小部分数据两个特征都不为0),可以使用一个指标度量两个特征之间的互斥度,称之为冲突比率。如果两个特征的冲突比率较小,可以将这两个特征进行捆绑,而对结果的精度不会有太大影响。
LightGBM部分超参数如下。
boosting_type:训练模型选项,支持传统的梯度增强决策树(gbdt)、基于梯度的单边采样(goss)、随机森林(rf)等多种机器学习算法。
objective:学习目标选项,支持二分类、多分类、线性回归等多种学习目标。
learning_rate:学习率,使用较小的学习率可以提高准确率。
n_estimators:决策树的数量,给定该参数值整数k,从训练出来的k棵树中选择最优树作为训练结果。
max_depth:决策树的最大深度,选择合适的参数可以避免过拟合。
num_leaves:决策树的最大叶子数,使用较大的值可以获取更好的准确率,但是也可能引起过拟合。
min_data_in_leaf:叶子节点上的最小样本数量,合适的值可以缓解过拟合。
4 ShadowscoksR流量识别方法
4.1 特征选择
SSR流量伪装成HTTP协议流量后具有一些HTTP协议的特征,但是仍然保留了一部分加密流量特征。提取单条流的前4个包的载荷信息熵作为分类的特征来衡量SSR流量的随机程度。ShadowscoksR流量识别特征集,如表1所示。

表1 ShadowscoksR流量识别特征集
在计算载荷信息熵时,为了平均HTTP协议特征与加密流量特征之间的差异性,添加固定可打印字符将流量中的不可打印字符和控制字符进行平均化,降低同一种类型流量之间的载荷信息熵反差过大的可能性,有益于分类结果。
4.2 数据集
表2中的HTTP流量是SSR中使用HTTP模式翻墙访问国外网站资源,混淆成HTTP协议的加密流量。白流量是访问国内公众网站产生的普通流量,其中包含一些真正的HTTP协议流量。为了保证训练模型的准确性,将训练集的正样本(HTTP流量)和负样本(白流量)的占比平均化。表2中的采集时间是相对于2020年6月1日计算的时间。

表2 数据集分布信息
4.3 聚类分析
采用等宽分箱分析和K-means聚类分析算法两种分析方式。图4(a)是通过等宽分箱分析法分析训练集HTTP流量第一包的载荷信息熵,图4(b)是通过K-means聚类分析法分析训练集HTTP流量第一包载荷信息熵;图4(c)是通过等宽分箱分析法分析训练集HTTP流量第二包载荷信息熵;图4(d)是通过K-means聚类分析法分析训练集HTTP流量第二包载荷信息熵。采用上述画图表现方式的原因是为了查找数据集的离群点,估计数据的取值范围;通过排除离群点的分析并结合准确率的反馈值,确定第一包和第二包载荷信息熵的取值范围。
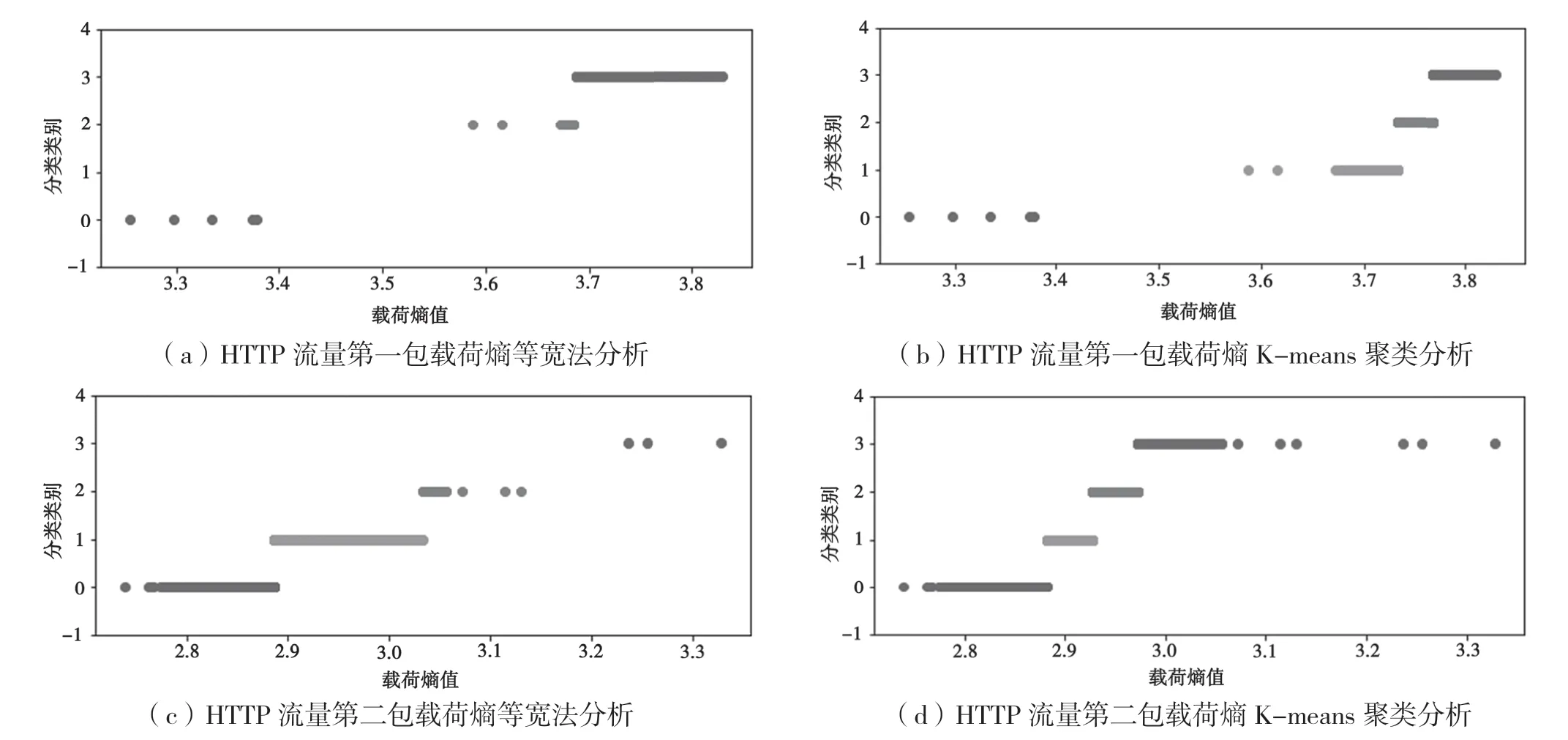
图4 采用等宽法和K-means聚类分析法对特征数据集4分类
5 实验与评估
将训练集的数据导入LightGBM训练模型中,调整好合适的超参数,对训练集进行二分类任务。图5描述的是各特征在训练过程中的重要程度,横坐标是特征的重要性,纵坐标是训练数据的特征维度。比如,第一维(图5中的0)的重要性是191。
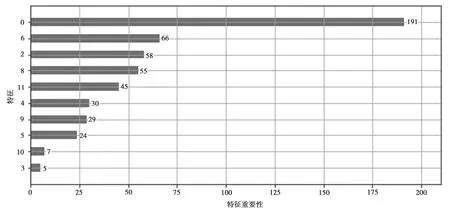
图5 训练模型特征重要性排列
表3描述的测试集在训练模型中的预测结果。
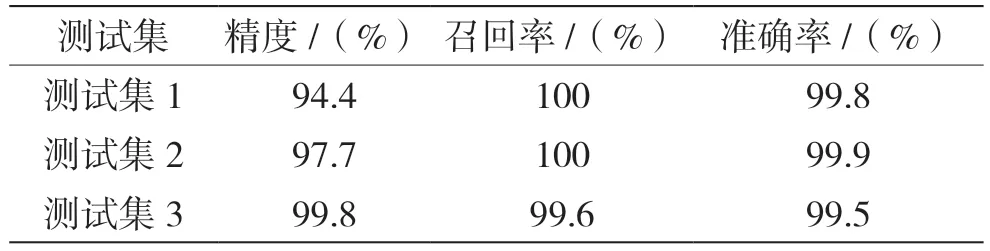
表3 测试集测试结果
由表3的预测结果可知,通过聚类分析将训练集中离群点数据清除,提高了训练模型的鲁棒性,在对远期数据(测试集1)和近期数据(测试集2)都有很高的精度、召回率和准确率。此外,在数据集中正样本的占比小的数据集(2.78%(测试集1)、3.3%(测试集2))和占比大的数据集(86.6%(测试集3))进行测试时,也具有很高的精度和召回率。
6 结语
本文主要针对ShadowscoksR中混淆成HTTP协议的流量进行识别。根据HTTP流量的特征采取等宽法和K-means聚类分析方法进行分析,提取HTTP流量的隐藏特征,清洗训练集的离散点流量,基于LightGBM对HTTP流量和白流量进行有监督机器学习分类。实验结果表明,训练模型鲁棒性较高,精度、召回率和准确率比较理想。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
湖南理工学院学报(自然科学版)(2022年1期)2022-03-16
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
课堂内外(小学版)(2017年5期)2017-06-07
雷达学报(2017年6期)2017-03-26
网络空间安全(2016年3期)2016-06-15
