
基于深度强化学习的移动Ad Hoc网络路由选择*
2020-08-14 06:31朱凡芃姚昌华张海波
通信技术 2020年8期
朱凡芃,朱 磊,姚昌华,王 磊,张海波
(1.解放军陆军工程大学,江苏 南京 210007;2.陆军研究院系统工程研究所,北京 100072;3.南京信息工程大学,江苏 南京 210044)
0 引言
无线自组织网络[1]自提出以来就受到了广泛的关注,近些年研究热点多是放在与其他网络的结合,如无线自组网与车载局域网的结合VANET[2-4],与无人机驾驶器的结合FANET,与移动宽带多媒体的Mesh等。无线自组织网络的特性决定了路由问题是它的研究重点,当前基于无线自组织网路的路由选择算法方面还多停留在Q学习算法[5],基本没有研究结合当前热门的深度强化学习提出新的算法,而深度强化学习可采用非线性函数近似逼近强化学习中的值函数,用深度神经网络来完成函数拟合,能较好解决无线自组织网络的动态性难点。
1 基于深度强化学习的Ad Hoc网络路由选择的研究动机
1.1 Ad Hoc网络路由选择的特点
Ad Hoc网络路由选择[6]需综合考虑网络能力、状态信息、网络特点、网络环境、路由协议等多方因素[7]。与传统有线网络相比,Ad Hoc网络有以下特点:
(1)节点动态性,网络中节点移动性较强,可随时加入或离开网络,且不破坏其他节点通信;
(2)环境动态[8],网络拓扑结构动态变化,链路的通连关系不固定;
(3)路由计算能力有限,存储开销较大;
(4)可扩展性不强。
1.2 Ad Hoc网络路由选择算法的要求
理想的Ad Hoc网络路由算法应该包含以下特点:
(1)分布式路由[9]。Ad Hoc网络是一种无中心的分布式控制网络,所以分布式算法更适合。
(2)自适应性强,可适应快速变化的网络拓扑结构。
(3)路由维护开销少。
(4)具有可扩展性,适用于大规模网络。
特别地:
(1)收敛速度要快,现有路由算法在大规模的网络中存在收敛较慢的问题;
(2)动态环境适应性强,由于Ad Hoc网络节点的移动性,在节点之间创建的路由是不可持续的,且这种不可持续不仅增加了分组传送时间,而且浪费了能量资源[10-11];
(3)不确定信息适应性强,Ad Hoc网络节点、链路状态无法预测;
(4)对网络拓扑信息缺失、错误容忍度高,在无法准确获取网络全部信息的情况下,依旧可以选择合适路由。
1.3 Ad Hoc网络路由选择算法的现状
传统的路由算法是寻找从源端到目的端的固定路由[1],且需要知道网络的先验状态信息,如信道统计以及网络拓扑信息等,但这在Ad Hoc网络中是不可行的。此外,固定的路由选择策略无法满足Ad Hoc网络的动态性和不可预测性需求。可以说Ad Hoc网络中的大多难点问题都归因于网络的拓扑动态性[12]。目前提出的大多数算法都弱化考虑节点的动态性,或者对节点的动态移动轨迹或网络拓扑结构做了预先的假设。在移动自组网路由中,使用强化学习是一种相对新颖的思想和概念。目前,结合深度强化学习对Ad Hoc路由算法的研究存在空白与欠缺。
1.3 Ad Hoc网络路由选择算法面临的挑战
Ad Hoc网络拓扑不断变化,路由选择算法面临的主要难点之一就是链路中断后的寻路问题。
(1)现有的无线路由选择算法较为复杂,在大规模网络拓扑结构中收敛较慢;(2)现有算法对信息获取的准确性需求较高,但在实际网络中,信息数据较难获取;(3)Ad Hoc网络有是动态变化的,现有的强化学习方法进行路由选择时对网络的适应性不是很好;(4)在不断变化的环境中,无法提供较为稳定的Qos路由选择。
2 基于深度强化学习的Ad Hoc网络路由选择研究现状
2.1 Ad Hoc网络路由选择发展概述
Ad Hoc网络的路由选择算法不仅要考虑路由的短暂性,还需考虑路由的稳定性。由于不同环境中的可用因素具有特定的行为模式,结合链路稳定性和路由短暂性的参数,利用强化学习的自学习特性,提出一种依赖邻居节点状态信息,预测节点相对于目标节点的行为模式的算法。但强化学习的路由选择算法对网络状态信息的准确性要求较高。
人工神经网络算法使用神经网络来确定动作的值,其中估计基于先前的估计。然而,为每种可能的路由组合都建立神经网络需要训练大量的神经网络,大大增加了对计算资源的需求。此外,深度学习本质上是某些功能的近似值,不适用于决策问题,例如路由选择,能量分配等。
因此,研究人员尝试使用深度强化学习解决决策类型问题。与传统的强化学习方法相比,深度强化学习利用深度学习的函数逼近能力来解决具有较大状态和动作空间的实际问题。本文从三个较为经典的深度强化学习算法出发,对现有的路由选择算法做了总结,如下图1所示。

图1 深度强化学习路由选择研究现状
2.2 基于值函数的深度强化学习路由选择算法
Mnih等[13]在Q learning基础上结合深度神经网络提出的基于值函数逼近的强化学习方法,框架流程如图2所示,主要特点有:
(1)用深度卷积神经网络逼近行为值函数;
(2)利用经验回放(均匀采样)训练强化学习的学习过程;
(3)设置单独目标网络来处理时间差分算法中的TD偏差。
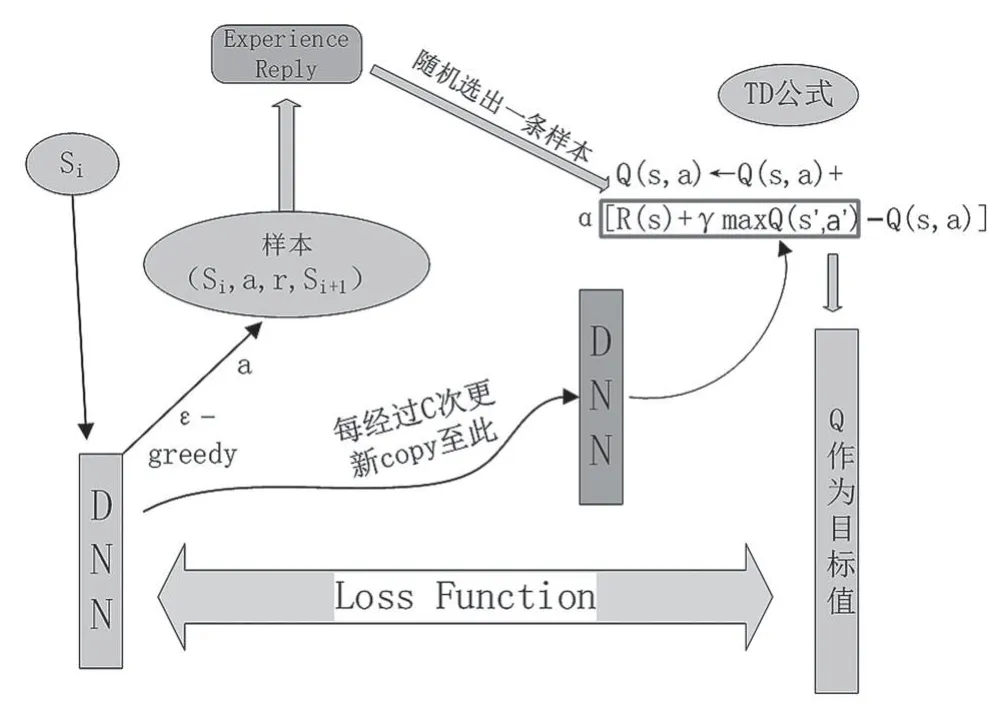
图2 DQN框架流程
2017年Stampa等[14]结合深度神经网络在强化学习中的最新研究[15-16],训练了一种能够根据预定义的目标指标(网络延迟)优化路由的深度强化学习(Deep Reinforcement Learning,DRL)智能体。所提算法将流量带宽作为状态,不考虑节点队列大小、链路质量等其他因素。使用OMNeT++[17-18]收集给定流量和路由参数的传输延迟[19]。随着路由变化,智能体可以通过更改奖励函数实现不同的策略选择,相较传统路由选择算法,优化了传输延迟。
Hu T[20]提出了基于强化学习QELAR的自适应、节能感知路由算法。在整个路由选择中考虑每个节点的剩余能量以及一组节点之间的能量分布以计算奖励函数,同时考虑重传和丢包对网络造成的负面影响。
Ghaffari等[21]提出了基于Q学习[22]的移动自组网算法。该算法无需对环境做出任何假设,仅依赖于从邻居获得的节点的局部信息。考虑到可持续性和路径短等参数,采用基于试错的强化学习方法,提出了一种在所有邻居中选择最佳方案向目标发送数据包的方法。实验证明,所提出的算发与最优蚁群路由算法[23-24]相比,随着节点数量的增加表现出更好的兼容性。在网络路由的变化与拥塞时所提算法相较[24],能更快地搜索到最新路由。在网络状态不变的情况下,所提出的算法比结合人工神经网络和蚁群算法所提出的算法[25]具有更高的效率,在传输延迟方面有较强的优势。
文献[26]提出了基于改进统计链路模型的Ad Hoc网络连续链路模型,并结合强化学习算法,将动作选择与连续链路模型相结合,提出了基于改进统计模型的Ad Hoc网络强化学习算法SNLQ,利用统计信息表示链路的质量,在拥塞网络环境下,可以有效解决拥塞频率和端到端延时。
2.3 基于策略梯度的深度强化学习路由选择算法
实际网络是状态不计其数的复杂的连续时间系统,而上面提到的所有研究都使用状态动作表来找到某种路由策略,而这种策略很难处理太多的状态。策略梯度(policy gradient)[27]是一种常用的策略优化方法,它使用逼近器来近似表示和优化策略,不断计算策略期望总奖赏关于策略参数的梯度来更新策略参数,以端对端的方式直接在策略空间中搜索最优策略,省去了繁琐的中间环节[28]。Lillicrap等[29]将DPG(deterministic policy gradient)算 法[30]与DQN (deep Q network)[31]相结合,提出了DDPG(deep deterministic policy gradient)算法,框架流程如图3所示。DDPG 在连续动作空间求解上有较好表现,且求得最优解所需的时间步也远低于DQN。
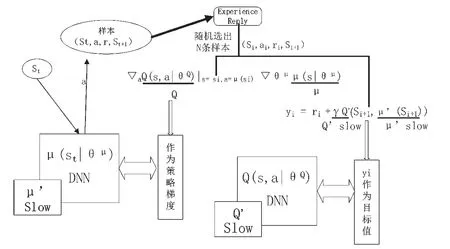
图3 DDPG框架流程
文献[32-33]使用DDPG和循环神经网络(Recurrent Neural Network,RNN)来进行流量工程(Traffic Engineering,TE)的策略选择。作为一种无模型方案,该算法可通过训练就可生成接近最佳的动态路由策略。该算法可随着网络中流量分布的变化而紧密地更新路由规则,而一旦在线部署则仅花费少量的计算和存储资源。实验证明,随着网络规模的扩大,与传统最短路径算法相比,所提出算法能更好减少传输延迟。但同时根据实验结果显示,该算法对流量强度大小要求较为严格,在流量强度较小时,与传统路由算法相比并无优势,在网络流量强度很高时,噪声流量的随机性又会削弱该算法的准确性。
C.Yu[34]等考虑到Q学习在用于网络路由优化时需要庞大的Q table,且不适用于动态变化的网络环境,结合DDPG提出了一种在连续时间内实现通用和可定制的路由选择算法DROM。所提出的算法相较现有的路由算法而言具有良好的收敛性和有效性,并节省了维护大规模Q表所导致的存储开销和表查找的时间成本,在网络中流量强度较大时可有效减少网络延迟,提高吞吐量。
2.4 结合Graph Neural Networks的深度强化学习路由选择算法
离散状态的强化学习问题中,不同的状态可以自然地表示为一个图的形式,GNN(Graph Neural Networks)是Franco[35]等引入的用于处理图结构信息的新型神经网络,以实现关系推理和组合泛化的目的,并已发展出许多变式[36-38],在网络建模和优化领域显示了空前的泛化能力[39-40]。
目前 GNN 所解决的问题中,图结构是一次性全部给出的;而在强化学习中,需要通过策略的探索来遇见相应的节点,当节点数目较多时,相应的图就会变得特别庞大,图4给出了GNN聚合示例。因此,如何一边探索并记录所遇到的状态,一边对于状态(节点)做聚合(aggregation)就成为了一个十分重要的问题[41]。
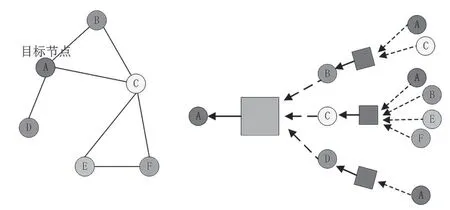
图4 GNN聚合示例
Paul A[42]等将GNN与DRL结合做网络的路由优化,用图神经网络对计算机网络场景进行建模,DRL Agent采用了DQN算法[13],其中q值函数由GNN得出。
在网络领域,从给定的流量矩阵中找到最佳路由配置是一个基本问题,研究人员提出了几个基于DRL的解决方案来解决路由优化[43-47]。然而,它们不能推广到看不见的场景。他们通常会预处理来自网络状态的数据,并以固定大小的矩阵形式呈现由传统的神经网络(例如,完全连接的卷积神经网络)处理。这些神经网络不适合学习和归纳那些固有地被构造成图形的数据。Paul A[42]所提出模型能够在训练中从未见过的网络中维持类似的精确度,能较好地推广至其他拓扑结构。
3 深度强化学习路由选择算法面临的机遇与挑战
3.1 深度强化学习路由选择算法的优势
相较于路由选择算法,深度强化学习路由选择算法有以下优点[14]:
(1)传统优化需要大量步骤才能产生新的配置。而DRL 智能体经过训练,可以达到快速收敛;
(2)DRL 智能体是无模型的(他们从经验,行为和奖励之间的动态中自主学习[48])、非线性、复杂多维系统,而无需进行简化;
(3)DRL 智能体可以使用不同的奖励函数来实现不同的目标策略,而无需设计新的算法。
3.2 深度强化学习路由选择算法的挑战
然而就现阶段的研究来看,深度强化学习路由选择算法的研究重心应放在:
(1)解决DRL 智能体的稳定性问题,就现阶段的研究来看,网络中的状态噪声会误导神经网络以输出不同的决策;
(2)移植性问题;当前很难将智能体移植到另一个网络拓扑中,或者当现有拓扑更改时,智能体无法很好地工作,后续仍然需要研究受过训练的智能体的增量部署;
(3)信息收集和处理问题,网络状态的时间和内容粒度也会影响智能体的性能,如何高效获取网络信息是未来研究的关键。同时,信息的收集与获取可能存在偏差,应加强对网络信息的处理的容错能力的进一步研究;
(4)规模问题,现有的算法研究都是在小规模节点网络上实验证明,在大规模网络中,节点环境更加复杂多变,还需提出更智能更稳定的算法同时,大规模的网络也给集中控制器带来了更多的通信开销。
4 结语
本文回顾了Ad Hoc网络路由选择算法的研究现状与成果,简要介绍了基于值函数的深度强化学习、基于策略梯度的深度强化学习以及结合Graph Neural Networks的深度强化学习从三个方面总结了深度强化学习路由选择算法的研究成果,讨论了结合深度强化学习的Ad Hoc网络路由选择算法研究趋势。
AdHoc网络其自身的独特性,赋予其广阔的发展前景。随着深度强化学习研究热潮的涌现,对路由选择又提出更高的要求,如:如何达到算法的快速收敛、如何更好地支持QoS路由、如何有效地收集网络的拓扑信息、如何处理动态的网络配置、如何扩展至大规模自组织网络等等。这些问题的解决在很大程度上依赖于Ad Hoc网络路由选择算法的研究,将深度强化学习应用于Ad Hoc网络路由选择在未来会有更大的发展。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
网络安全与数据管理(2022年2期)2022-05-23
移动通信(2021年5期)2021-10-25
铁道通信信号(2020年8期)2020-02-06
电子制作(2019年20期)2019-12-04
网络安全和信息化(2019年11期)2019-11-25
电子制作(2018年23期)2018-12-26
科技与创新(2018年1期)2018-12-23
汽车维修技师(2017年7期)2017-12-05
汽车维修技师(2017年10期)2017-03-17
