
基于Hadoop 的源相机识别方法研究
2020-08-07 14:43:24朱新龙王佳斌
现代计算机 2020年18期
朱新龙,王佳斌
(工业智能化与系统福建省高校工程研究中心,泉州362021)
0 引言
计算机的普及和网络的便捷,使得数字化信息已经成为人们日常工作和生活中不可或缺的重要角色。但凡事必有两面性,人们在享受数字化信息带来的种种便利的同时,也在面临和承担着其带来的安全问题。信息安全问题小至个人信息安全,大至社会、经济、政治、军事和文化安全。数字信息具有易获取、易编辑、易修改等特性,这是一把双刃剑:一方面给人们获得和处理信息提供了极大的便利;另一方面也为无意或者恶意的篡改伪造信息提供了可能。由此引发的对于数字信息完整性和真实性的关注,而在数字化信息安全中的数字图像的来源真实性问题备受人们关注。
图像真实性能够通过各种方法进行验证,从比较EXIF 元数据方法等简单的方法到跟踪图像数字指纹等复杂方法,而EXIF 中的信息可以通过ExifTool 16 等软件轻松编辑,所以使用图像数字指纹的方法显得似乎更加可靠,并引起了图像取证研究人员越来越大的兴趣[3]。图像的数字指纹提供了图像的显著特征。随着各种技术的研究,使用图像的数字指纹进行源摄像机识别一直是最近研究的焦点。
该领域最值得注意的贡献之一是Lukas 等人[1]提出的算法。该算法的工作原理是,从待识别的图像中提取数字指纹,并将其与一组之前已知的相机指纹相关联,以识别该图像的源相机。因为它们涉及到对包含数百万个像素的图像进行处理,所以该类别算法对计算机的性能要求是非常高的,且在大数据集上提取大量数字指纹时受制于单台计算机的计算能力,算法的处理时间非常长。分布式计算环境使通过网络连接的多台远程计算机能够并发地执行特定任务,与在单台计算机上运行任务相比,多台计算机的处理能力合并,能够大大缩短处理时间。本文研究了在Hadoop 分布式下使用Lukas 等人[1]的算法进行源相机识别的可能性,实验结果显示,与单台计算机相比,分布式处理能够有效缩短任务的处理时间。
1 Hadoop框架
Hadoop 是一个由Apache 基金会所开发的开源分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。解决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的可靠存储和处理。适合处理非结构化数据,Hadoop 包括HDFS、MapReduce 等基本组件。
HDFS 主要支持流数据读取和处理超大规模文件,结构模型为主从结构(Master/Slave),一个HDFS 集群由一个命名结点和若干个数据结点组成。命名结点作为中心服务器,主要工作是管理整个文件系统。数据节点作为工作结点,主要任务为处理文件系统客户端的读/写请求,并向命名结点传输存储信息。实现原理是当如果有文件提交给Master 节点,Master 会将其切分成N 个块,并为每个块拷贝多个副本,然后将这些块分散地存储在不同的Slave 节点上。Master 负责维护整个NameSpace,NameSpace 中记录着输入文件的切割情况,以及每个块的存储信息。Slave 是实际的工作站,负责存储块。
MapReduce 主要处理存储在分布式文件系统中的数据,它的核心是Map 函数与Reduce 函数,输入输出方式都以中间
2 源相机识别问题
通过分析数字图像中由成像设备引入的特性,确定图像来源即成像设备的取证技术称为数字图像来源取证,也叫源相机检测,是图像取证技术的一个重要分支。其采用的方法主要是提取相机的参考模式噪声,并检测待测图像中是否含有此模式噪声。在数字图像中,噪声可定义为像素相对于所描绘的原始视图的颜色失真。这些失真可能是由于散粒噪声,一个随机的组成部分,或模式噪声,确定性的组成部分。模式噪声又可以分成两个主要部分:固定模式噪声(FP)和光响应非均匀性噪声(PRNU)。FP 噪声是由暗电流引起的,暗电流是当数字传感器不暴露在光下时像素检测器返回的信息。PRNU 噪声主要由像素非均匀性噪声(PNU)引起,这是由于数字传感器的像素检测器对光的灵敏度不同所致。这种差异是由硅片的不均匀性和传感器制造过程中产生的缺陷造成的。PNU 与拍摄场景无关,只与成像传感器有关,因此不同的数码相机,即使品牌型号相同,其PNU 也不相同。源相机检测中用到的模式噪声主要指PNU[2]。
3 源相机识别算法简介
本文中的源相机识别算法参考了Lukas 等人[1]提出的方法,首先对Lukas 等人[1]提出的算法进行简单的介绍,算法关键步骤如下:
(1)提取模式噪声。使用滤波器F 对图像I 进行滤波,可得图像I 的模式噪声为:

(2)计算相机参考模式噪声。相机的模式噪声无法直接获得,Lukas 等人[1]提出可以用多幅参考相机拍摄的图像作为参考图像。采用步骤(1)的方法,对每幅图像提取模式噪声,记为RPC,叠加求平均后,作为相机C 的参考模式噪声的近似值:

式中N 为用于提取相机参考模式噪声的图像个数。
(3)计算相关系数。按步骤(1)对待测图像T 提取模式噪声,记为RPC,按步骤(2)对参考相机C 提取相机参考模式噪声,记为RPC,则RPT和RPC的相关系数为:

若相关系数超过给定的阈值,则认为图像T 是由相机C 拍摄的[4]。
4 实验步骤
4.1 加载图像
在此步骤中,算法执行期间使用的图像需要加载到HDFS 存储中。管理大量的小文件并不是Hadoop的强项,本次实验的解决方案是只维护两个非常大的文件,这两个文件已被编写为Hadoop SequenceFile 对象,分别是:EnrSeq(用于存储图像列表)和TTSeq(用于存储训练和测试的图像列表)。在这两个文件中,图像是根据它们的原始相机id 排序的。然后,使用SequenceFile 对象的输入拆分功能在不同的计算节点之间划分这两个文件,以使数据可以在本地执行。
4.2 计算参考模式噪声
该步骤通过分析使用相机C 拍摄的具有相同分辨率的一组输入图像来计算相机C 的参考模式噪声。
在map 阶段,每个处理节点接收一组图像,提取其相应的模式噪声并输出。在reduce 阶段,每个函数(每个相机C 对应的函数)将map 任务中产生的相机C 的模式噪声集作为输入,并将它们组合在一起,并返回RPc。对每台准备被提取模式噪声的相机重复此操作。
在Hadoop 中每个map 输入记录均被构造为
在reduce 阶段,reduce 函数接收格式为
4.3 计算相关系数
在这一步骤中,算法提取每个训练图像的RN,然后计算与所有输入设备RPs 的相关系数。对所有待测试图像重复相同的操作。
在map 阶段,每个处理节点接收一个以
4.4 分类器训练和测试
在此步骤中,使用上一步中计算的相关系数和CORRs 文件对基于SVM 的分类器进行训练和测试。计算过程发生在主节点上。该步骤结束时,分类器已经训练完成,可用于识别步骤。此外,本步骤向用户返回测试准确度的估计值,表示为测试源图像与其相应参考摄像机之间的成功匹配度(RR)。
4.5 源摄像机识别
本步骤的目的是确定图像I 是被哪个相机捕获的。Hadoop 作业的输入文件是存储RPs 的目录。此阶段的输出是用于采集输入图像的预测相机。对于每个输入RP,调用一个新的map 函数。该函数首先使用图像I 的副本提取模式噪声RN,然后计算该RN 与输入RP 之间的相关性。最后,作业返回到主节点一个包含相关值列表的文件,以使用上一步中训练完成的SVM 来执行识别阶段。
5 初步实验
5.1 实验设置
所有实验是在一个由4 个配备8 GB RAM、Intel Xeon CPU E5-2407@2.20GHz×2、CentOS7 操作系统、100Mbps 以太网卡和931GB 硬盘的PC 集群上进行的。
Hadoop 集群配置包括3 个从节点和一个主节点。Hadoop 版本为2.9.1。为了节省内存,群集中所有节点的操作系统均已配置为不运行图形用户界面。
5.2 数据集
本次实验使用的数据集为4 台手机拍摄的共1032幅图像,每种相机拍摄的图像分为130 张输入图像,64张训练图像,64 张测试图像,关于相机的具体信息如表1。
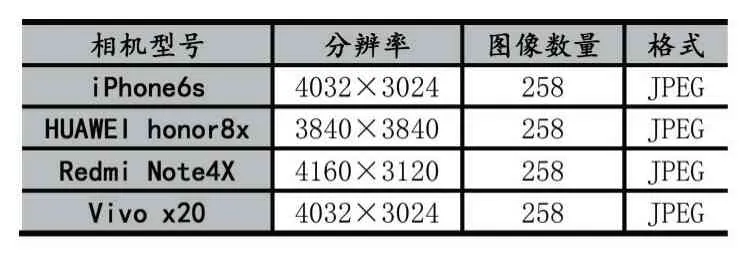
表1 四部手机相机参数及图像数量和格式
在本次实验所有的测试中,分类器能够正确识别用于拍摄948 张图像的源相机,从而达到92.0%的识别率。
5.3 实验结果
初步试验结果显示,在使用上文中提到的数据集时原始版本算法的处理时间为1192 秒,而分布式版本的算法的处理时间为627 秒,分布式实现相对于原始版本算法表现出大约1.9 倍的加速比。
6 结语
本次实验的目标是尝试使用基于Hadoop 平台的MapReduce 编程模型的分布式方法解决数字图像取证中的关键问题——源相机识别问题。本次实验选择Lukas 等人的源相机识别算法,将其改写为MapReduce算法,使用Hadoop 框架实现了它,并与原始版本的性能进行了比较。
根据测试,当算法运行在4 个计算节点的集群上时,分布式实现的版本比原始版本的总体处理时间有大幅度减少,但是在分布式环境中,加速比仍有接近两倍的差距,这种性能损失主要是由于传输图像和数据文件时的开销产生的。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
数学年刊A辑(中文版)(2020年3期)2020-10-27 02:44:16
中学生数理化·八年级物理人教版(2017年9期)2017-12-20 08:11:30
能源(2017年10期)2017-12-20 05:54:07
能源(2017年5期)2017-07-06 09:25:54
雷达与对抗(2015年3期)2015-12-09 02:38:50
中国卫生(2015年12期)2015-11-10 05:13:34
噪声与振动控制(2015年4期)2015-01-01 07:08:05
