
基于改进果蝇算法和长短期记忆神经网络的油田产量预测模型
2020-08-06 00:21任燕龙谷建伟崔文富张以根
科学技术与工程 2020年18期
任燕龙, 谷建伟*, 崔文富, 张以根
(1.中国石油大学(华东)石油工程学院,青岛 266580;2.中国石化胜利油田分公司勘探开发研究院,东营 257015;3.中国石化胜利油田分公司胜利采油厂,东营 257015)
油田的产量预测是油田开发方案的重要内容,在很大程度上决定着油田的整体开发水平与开发效果[1]。现阶段,中国东部油田大多进入了生产开发后期,传统的产量预测方法,如水驱曲线法、产量递减法等对于油田的产量预测出现了不适应的状况。而产量预测是一个时序性的问题,对于时间序列的预测问题,长短期记忆神经网络[2](long-short term memory,LSTM)已广泛应用于语音识别[3]、网络流量预测[4]、钻前测井曲线预测[5]、电力预测[6-8]、有毒气体规律预测[9]等领域中。因此,选用LSTM神经网络对油田产量进行预测,但是由于油田产量具有很强的阶段性,在油藏工程中分为产量上升期、产量稳定期、产量递减期,简单地直接应用LSTM神经网络会出现网络泛化性差的问题,预测精度很低,预测产量甚至会出现负值,偏差很大。
针对LSTM神经网络泛化性差的问题,对深度学习网络的架构进行优化。毛焱颖[10]提出一种基于注意力双层LSTM的长文本情感倾向性分析方法;Peng等[11]使用双LSTM层来调整参数以提高语句生成的准确性。双LSTM层较单LSTM层可以进行更加深度的学习,能够捕捉长期依赖性,记录更久的时序特征,预测更加准确。因此,建立了基于双层LSTM的深度学习网络,在深度学习网络之中还加入了随机失活层,消除了神经元之间的依赖,进一步提高了神经网络的泛化能力。除优化网络架构外,还通过果蝇优化算法[12](fruit fly optimization algorithm,FOA)在全局空间上搜寻最优解,避免神经网络陷入局部最优解。目前,果蝇算法已经广泛应用于科学与工程领域[13-16],同时对于果蝇算法的优化研究也在不断开展,陈明扬等[17]自适应调整果蝇种群数量和搜索步长,同时优化初始迭代位置;李梅红[18]对果蝇种群进行划分,利用了优势种群与弱势种群的协同配合;Hassan等[19]提出了离散果蝇算法。这些方法都提高了果蝇优化算法的全局寻优能力和局部收敛速度。
基于此,提出一种新的果蝇群体聚集思路,并结合优势群体和动态搜索半径的方法对传统的果蝇优化算法进行改进,基于改进的果蝇算法对所建立的深度学习神经网络产量预测模型进行优化,建立基于改进果蝇算法的深度学习神经网络油田产量预测模型,以期可以较为准确地预测变化波动幅度大的油田产量时序序列。
1 深度学习神经网络模型
建立深层学习神经网络模型,其核心部分是双LSTM层,另外加入随机失活层极大提高了神经网络泛化能力。
1.1 长短期记忆(LSTM)层
长短期记忆神经网络是循环神经网络的一种特殊形式,而循环神经网络模型[20](recurrent neural networks,RNN)是在普通多层前馈网络(back propagation neuron network,BPNN)的基础上,增加了隐藏层各单元间的横向联系,通过一个权重矩阵,可以将上一个时间序列的神经单元的值传递至当前的神经单元,从而使神经网络具备了记忆功能,如图1所示。

x为输入;h为隐含层;o为网络预测输出;y为真实输出;L为预测输出与真实输出之间的损失;W为隐含层的权重矩阵,记忆时间序列的变化规律图1 RNN结构图Fig.1 RNN structure diagram
但是RNN神经网络存在梯度弥散和梯度指数上升的问题,这是因为其训练算法使用的是反向传播算法(back propagation trough time,BPTT),当时间比较长时,回传的残差将指数下降,导致网络权重更新缓慢,无法体现出长期记忆的效果,需要一个存储单元来存储记忆,因此LSTM模型被提出。LSTM是循环神经网络模型的一种变体,LSTM之所以可以进行长期记忆,主要是由于其独特的细胞结构。传统的RNN中都具有一种重复神经网络模块的链式的形式。在标准的RNN中,这个重复的模块只有一个非常简单的结构,例如一个tanh层,而LSTM的细胞结构比较独特,如图2所示。
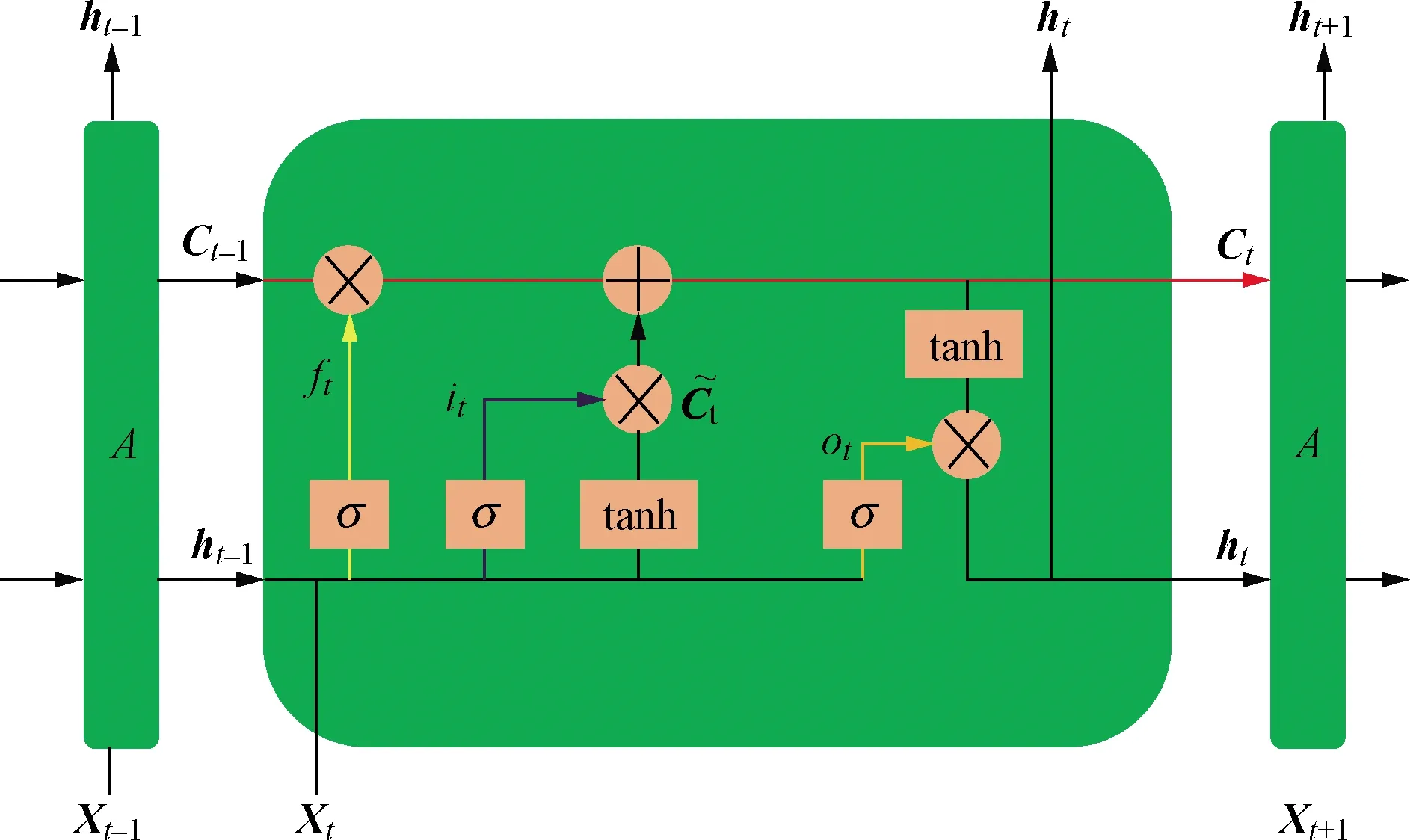
图2 LSTM细胞结构示意图Fig.2 LSTM cell structure diagram
如图2所示,A代表某一时刻的细胞单元,Xt-1、Xt、Xt+1分别为上一时刻、当前时刻、下一时刻细胞单元的输入特征向量;ht-1、ht、ht+1分别为上一时刻、当前时刻、下一时刻细胞单元的输出信息;σ为激活函数,决定着信息保留,一般是sigmod函数;tanh层创建并更新候选信息,从而实现对变量随时间变化规律的长期记忆;ft为遗忘门输出信息;it为输入门输出信息;ot为输出门输出信息;为候选细胞状态;Ct-1为上一时刻的细胞状态;Ct为当前时刻的细胞状态。
LSTM的细胞结构包括一个记忆链(红线)、遗忘门(黄线)、输入门(蓝线)、输出门(橙线)。通过记忆链Ct记录和更新当前的细胞状态,并向下一个时间步传递。通过三个门来保护和控制细胞状态,对信息进行筛选和更新。
遗忘门:作用于细胞状态,选择性遗忘记忆细胞中的信息。
ft=σ[Wf(ht-1,xt)+bf]
(1)
输入门:作用于细胞状态,将新的信息选择性的记录到新的细胞状态中。
it=σ[Wi(ht-1,xt)+bi]
(2)
(3)
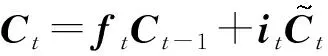
(4)
输出门:作用于输入和隐含层输出,使得最后输出既包括细胞状态又包括输入,将其结果更新到下一个隐层。
ot=σ[Wo(ht-1,xt)+bo]
(5)
ht=ottanhCt
(6)
式中:xt为当前时刻的输入信息;Wf为遗忘门的连接权重;bf为遗忘门的偏置系数;Wi为输入门的连接权重;bi为输入门的偏置系数;Wc为记忆单元的连接权重;bc为记忆单元的偏置系数;Wo为输出门的连接权重;bo为输出门的偏置系数。
图2可看作LSTM层内部上一时刻与当前时刻的单节点信息传递。图3表示多节点的信息传递。输入层的节点数由输入数据的特征个数决定;隐含层节点数通常根据需要或者经验公式给出,一般基于训练与预测结果进行调整;由于是多层神经网络相连,输出层的个数由下一层的节点数确定,通常由所预测的指标个数确定。在隐含层中,上一时刻所有节点的输出均输入到下一时刻的所有节点。
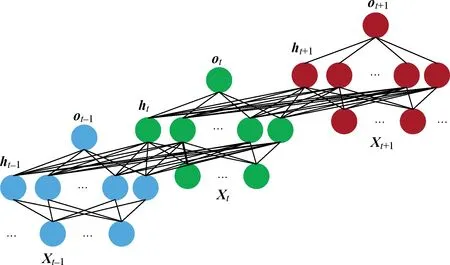
图3 LSTM信息传递图Fig.3 LSTM information transfer diagram
1.2 随机失活层与全连接层
具有大量参数的深层学习网络通常会出现过拟合问题,导致神经网络的泛化能力很低。Srivastava等[21]提出了随机失活的方法:在训练过程中,随机丢弃(按照伯努利概率使得部分节点在训练过程中不进行更新)深度学习网络中的部分节点,使得网络结构简单化,但是在测试过程中依然用全部的神经节点进行测试。由于是随机丢弃,这就相当于在每一个最小步长中训练的都是不同的神经网络,假设某一层有n个节点,那么就有2n种组合(子网络)。所以最后训练所得的神经网络具有一种网络种群平均化,即集成学习的概念,可以提高网络的泛化能力。全连接层的每一个节点与上一层所有节点均相互连接,可以将上一层所提取的特征综合起来。
2 果蝇优化算法
标准果蝇优化算法(fruit fly optimization algorithm,FOA)采用基于种群的全局随机寻优优化算法,通过跟踪当前最优解的信息来指导种群的下一步搜索,使得种群能够以当前最优解为中心开展局部随机搜索,并朝着更优的方向搜索前进。首先,给出果蝇种群的中心位置,众多果蝇个体从中心出发,赋予其随机的飞行方向与距离,使其随机分布在空间上,然后找出当前种群中距离食物最近的个体,此时,其他果蝇通过视觉效果向最优个体靠近,重复上面的步骤,使得果蝇种群逐步向食物靠近。
建立了改进果蝇优化算法(improved fruit fly optimization algorithm,IFOA),主要从三方面对果蝇算法进行改进。首先,在果蝇进行位置更新时挑选出上一代个体总数k%的优势个体作为下一代种群的产生基础,保留优势个体的位置,即权重矩阵和阈值矩阵,剩下的(100-k)%的个体向优势个体位置的附近聚集。因为当前的最优个体附近并不一定在全局最优的附近,如果只向最优个体附近聚集,极易陷入局部最优解,因此向优势群体聚集可以减小陷入局部最优的概率;考虑到优势个体附近劣势个体的聚集比例问题,提出了两种聚集方法:等比例聚集,即每一个优势个体附近都聚集比原来多(100-k)/k倍的个体数;按味道浓度的大小比例聚集,先将优势群体的味道浓度求和,计算出每一个优势个体味道浓度占优势群体味道浓度和的比重,劣势群体按照此比重进行分配聚集;最后,在种群局部寻优时,采用动态改变果蝇算法搜索半径的方法对果蝇算法进行改进,使得搜索半径逐代减小,因为在迭代初期,迭代步长过长有利于全局寻优,不易陷入局部最优解,但是在迭代后期,迭代步长过长会使得局部寻优能力下降,有可能跳出最优解,因此需要动态变化搜索半径。
考虑到优化深度学习神经网络的要求,主要是通过改进的果蝇优化算法对神经网络层的权值和阈值矩阵进行优化,寻找最优的神经网络层的初始值,因为神经网络的初始位置对训练结果有很大的影响。对寻优过程做了如下的特殊化处理。
Step 1初始化种群。
设置种群的最大规模p,最大迭代步数g,种群个体的位置即为各神经网络层的权值与阈值矩阵,考虑到神经网络预测模型的训练结果受权值与阈值矩阵的影响很大,因此将位置范围R设置在-1~1,初始位置由式(7)、式(8)确定:
R(i)_L(j)·W(m,n)=rand(-1,1)
(7)
R(i)_L(j)·B(k,l)=rand(-1,1)
(8)
式中:R(i)为第i个个体的位置,i=1,2,…,p;L(j)为第j层神经网络,j=2,3,4,6;W(m,n)为该层权重矩阵的第m行、第n列的数据;B(k,l)为该层权重矩阵的第k行、第l列的数据。
记R(i)_L(j)W(m,n)为RLW,记R(i)_L(j)B(k,l)为RLB。
Step 2嗅觉搜索过程。
每一个个体都会朝着不同的方向飞行不同的距离,设置最大的搜索半径Rmax为0.001,使其随着迭代步数的增加逐渐减小,则R由式(9)确定,果蝇个体的位置更新由式(10)、式(11)确定:
(9)
(10)
(11)
式中:I为当前迭代步数;RI为第I次迭代的搜索半径。
Step 3计算味道浓度。
将深度学习网络训练所得的均方误差作为味道浓度判定函数:
(12)
Step 4优选个体
通过式(12)计算出的种群个体的味道浓度,选出前k%优势个体,假设有T个优势个体,按味道浓度的大小比例P聚集:
(13)
则第I代第h个优势个体附近聚集的劣势个体数目G由式(14)确定。
G(I,h)=P(I,h)p(1-k)%
(14)
Step 5迭代求解。
重复Step2~Step4,优选个体、更新种群,直到迭代步数达到g,最后以最优个体的位置作为深度学习网络的网络层权重和阈值矩阵。
3 实例验证
实例油田选自胜利油区的胜坨油田,该油田从1966年投入开发,截至目前开发周期已达53年。由于该油田开发过程中层系、井网相对稳定,中间数据记录比较完整,因此选为研究对象。总共录取了该油田1974年1月—2018年12月,共540月的月度生产数据。该油田的产量变化有明显的阶段性特征,油田刚开始投入生产时,产量很高,并且变化幅度剧烈,处于不稳定期,而后经过开发调整进行稳产期,产量略有下降,一段时间之后产量又开始降低,开始进入下一个稳产期。稳产—递减两个阶段交替进行,总体来看产量的波动变化很大,如图4所示。
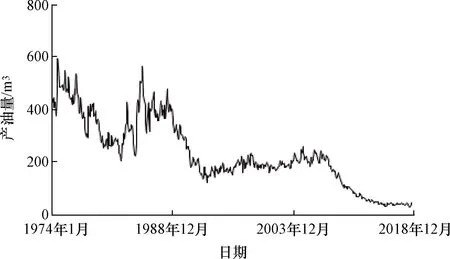
图4 油田产量变化Fig.4 Oilfield production change
由油藏工程方法选出11个与产油量相关的属性,其中,油水井数比可以反映油田的布井方式,部分数据如表1所示。
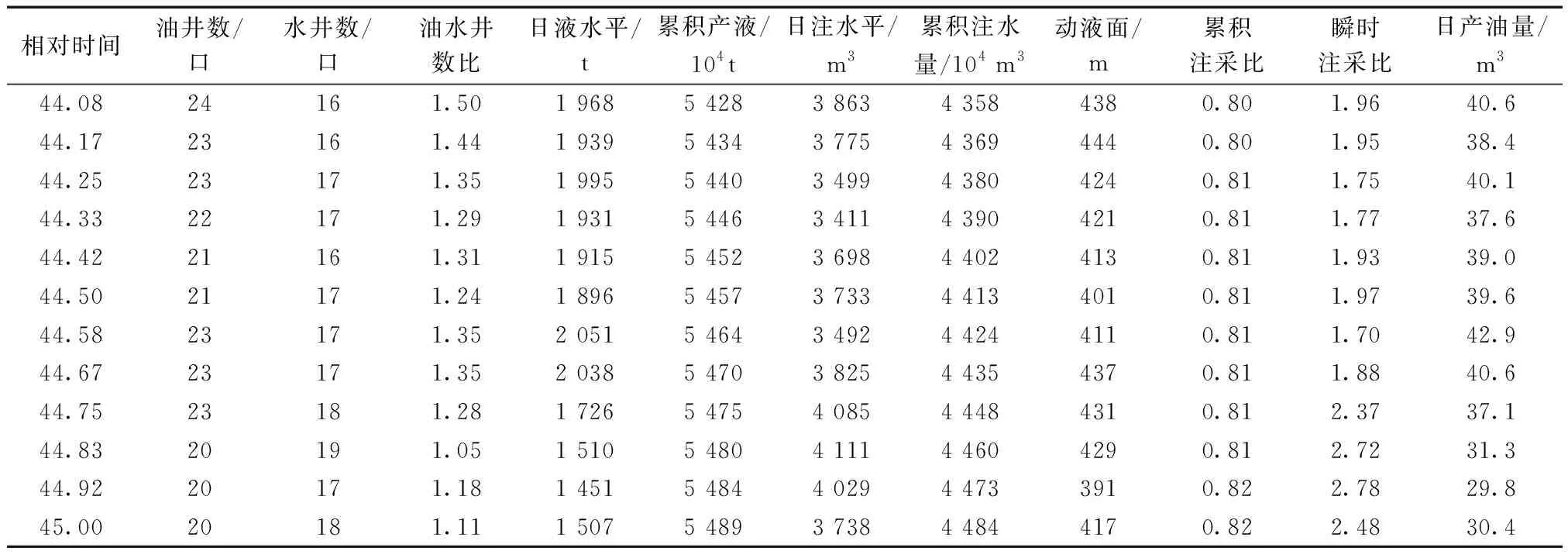
表1 部分原始数据(2018年)Table 1 Partial raw data(2018)
3.1 数据归一化
由于原始数据的单位不同,存在着数量级差异,数量级差异会导致量级较大的属性占据主导地位,使产油量仅依赖于某一属性;还会导致训练的收敛速度减慢,因此需要对原始数据进行归一化处理。油田数据是不断变化的,且与开发阶段和调整方式有很大关系,某一属性最大值与最小值未知,因此选用z-score标准化 (zero-mean normalization),对于每一个属性,x(j),j=1,2,…,12,根据式(15)、式(16)计算出该属性下的均值μ和标准差σ′。
(15)
(16)
然后根据式(17)、式(18)计算标准化后的属性值:
(17)
(18)
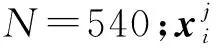
3.2 评价指标
实例验证选择平均相对误差(mean relative error,MRE)和归一化均方根误差(normalized root mean square error,nRMSE)作为评价标准,具体计算公式如式(19)、式(20)所示:
(19)
(20)
式中:y′为神经网络预测值;y为实际数据值;ymax为测试数据的最大值;ymin为测试数据的最小值。
3.3 多层LSTM神经网络架构优选
现通过单层LSTM、双层LSTM、三层LSTM、四层LSTM的四种不同的网络层架构对油田现场数据进行训练测试,将数据集的前486月的归一化生产数据作为训练集,后54个月作为测试集进行验证。将每一种神经网络架构训练并验证100次,取100次的平均值,预测情况对比如图5所示。
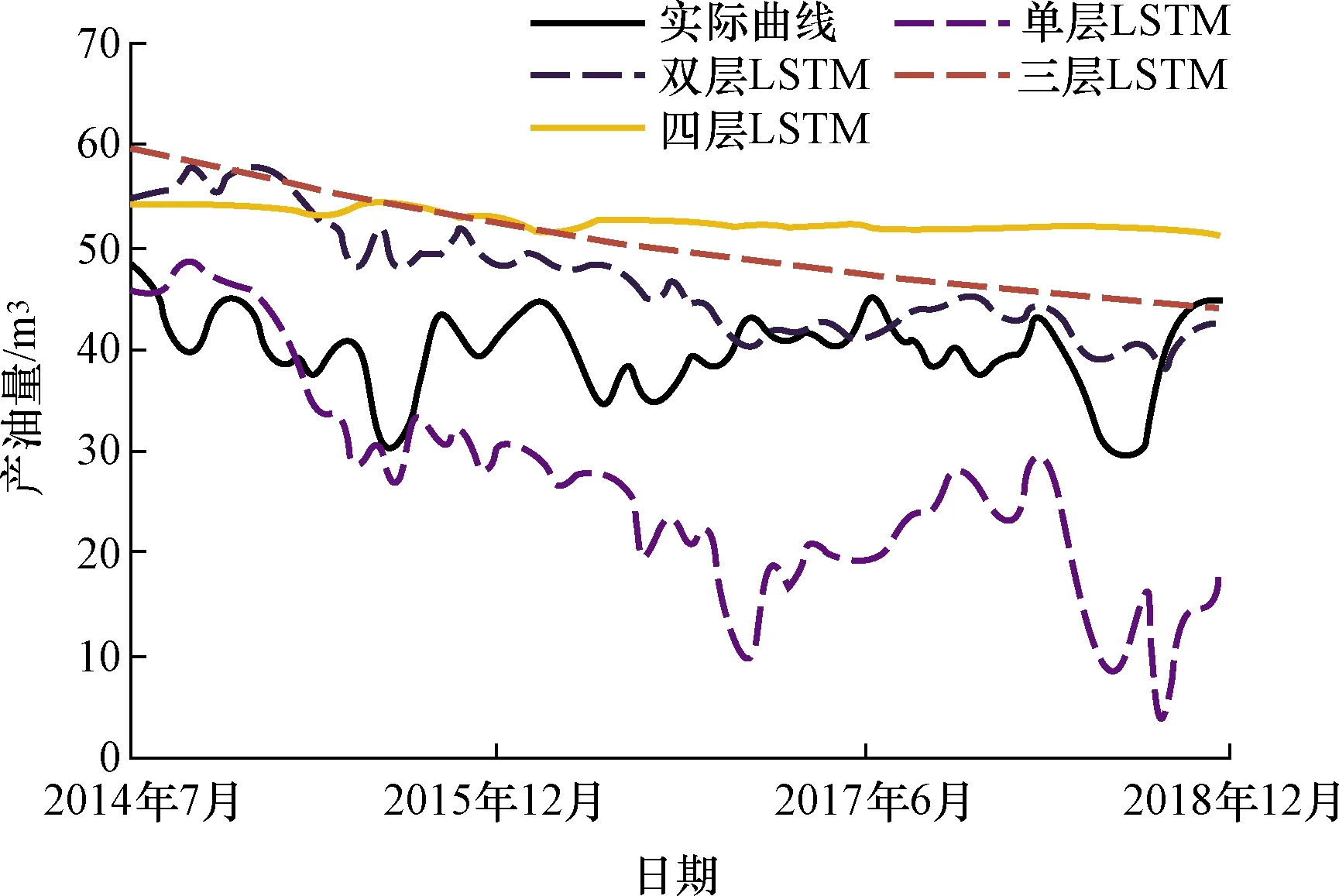
图5 多层LSTM模型产油量预测对比Fig.5 Multi-layer LSTM model oil production forecast comparison
如图5所示,实际产油量处于一个波动变化但是相对平稳的状态,单层LSTM的预测产油量偏低,预测误差较大,这是由于单层LSTM不能较好地记忆长期的变化规律;三层LSTM和四层LSTM的预测产油量偏高,误差比较大,所预测的产油量没有随油田生产参数的变化波动情况,这是由于LSTM层数增多,导致神经网络模型过拟合,泛化性能力较差。相比较而言,双层LSTM的预测产油量比较接近实际。
四种神经网络架构的预测误差如表2所示。由表2可以看出,双层LSTM架构的MRE和nRMSE最小,预测精度最高,因此在双层LSTM的基础上进行优化。

表2 预测误差对比表Table 2 Comparison error forecast table
3.4 结果分析与讨论
采用双层LSTM、深层学习网络架构(deep learning network,DLN)、经过改进果蝇算法优化的双层LSTM、DLN四种模型分别进行训练和预测,对比情况如图6所示。

黑色实线为实际产油量;虚线为未优化的神经网络的预测产油量;另外两条实线为优化后的神经网络的预测产油量图6 优化效果图Fig.6 Optimized comparison chart
由图6可知,双层LSTM的预测产油量偏高,DLN的预测产油量偏低,DLN比双层LSTM神经网络的双层LSTM更加接近实际曲线,误差更小,经过改进的果蝇算法优化之后的两种神经网络架构中依然是DLN架构的误差更小,即IFOA-DLN预测精度更高,可以很好地拟合实际产油量曲线。另外,DLN与IFOA-双层LSTM相比较而言,DLN是优化了神经网络架构,IFOA-双层LSTM是通过改进的果蝇算法进行寻优,结果表明IFOA-双层LSTM的预测效果更好,说明通过改进的果蝇算法寻优比优化架构更能提高预测精度。
四种神经网络的预测误差,如表3所示。

表3 预测误差对比Table 3 Comparison error forecast
种群的最优值和平均值随迭代步数的变化情况,如图7所示。

图7 误差迭代变化Fig.7 Error iteration change
由图7可以看出,随着迭代步数的增加,种群的平均的MRE与nRMSE和最优的MRE与nRMSE都在逐渐降低,说明通过改进的果蝇优化算法寻找最优的深度学习网络的网络权值和阈值是切实可行的,较大提高了神经网络的泛化能力,提高了预测精度。
4 结论
(1)经过长期开发的油田,其生产数据波动性较为剧烈,直接应用单层LSTM神经网络模型具有泛化性很差的问题。首先对多层LSTM神经网络进行优选,结果表明双层LSTM的预测精度较高,且可以反映产油量随其他生产指标变化的波动性,说明泛化性较好,所以选择双层神经网络作为研究基础。
(2)通过添加全连接层以及随机失活层进一步增加了神经网络的泛化能力。最后,利用果蝇优化算法,通过优势群体的多目标寻优、按味道浓度比例聚集的方式以及搜索半径的动态变化对果蝇优化算法进行改进。
(3)基于改进的果蝇优化算法,寻找最优的DLN网络参数,建立了IFOA-DLN油田产量预测模型,预测精度进一步提高。结果表明,IFOA-DLN神经网络模型泛化能力强,可以克服油田生产数据随时间变化幅度大的问题,对于时序序列数据具有较高的适应性,预测精度可以满足矿场需要,对于油田的生产开发调整具有一定的意义。
猜你喜欢
学苑创造·A版(2022年6期)2022-06-20
学苑创造·A版(2022年3期)2022-03-29
作物研究(2021年4期)2021-09-05
烟台果树(2021年2期)2021-07-21
现代装饰(2019年11期)2019-12-20
学苑创造·A版(2019年6期)2019-07-11
福建基础教育研究(2019年2期)2019-05-28
动漫界·幼教365(小班)(2018年3期)2018-05-14
热带农业科学(2017年9期)2017-10-23
江苏农业科学(2017年1期)2017-02-27
