
优化初始聚类中心的K-means聚类算法
2020-08-03 10:05:48郭永坤章新友刘莉萍牛晓录
计算机工程与应用 2020年15期
郭永坤,章新友,刘莉萍,丁 亮,牛晓录
1.江西中医药大学 计算机学院,南昌 330004
2.江西中医药大学 药学院,南昌 330004
1 引言
聚类是根据数据不同特征,将其划分为不同的数据类,属于一种无监督学习方法。它的目的是使得属于同一类别个体之间的密度尽可能的高,而不同类别个体间的密度尽可能的低。传统的聚类算法[1-12]可分为:基于划分的聚类、基于密度的聚类、基于层次的聚类、基于网格的聚类等。K-means算法属于基于划分的聚类算法之一,也属于一种经典的分布式聚类算法。K-means算法作为一种基于样本间相似性度量的间接聚类方法[13],该算法以簇类数目K为参数,把n个数据对象按规则划分为K个簇,使得簇内的相似度较高,而簇间的相似度较低。虽然K-means算法具有算法简单、高效、易于理解的优点,但其仍存在一些不足,即一般只能处理球状或类球状的数据集、初始聚类中心不稳定、易陷入局部最优解等等。针对该算法的不足之处,许多学者进行了许多的改进,例如,文献[14-15]针对传统K-means算法随机选取初始聚类中心,容易导致聚类结果不稳定问题,分别选择方差最小(即紧密度最高)且相距一定距离的样本和最大化减少误差平方和的数据点作为聚类初始中心作为初始聚类中心,从而实现优化的K-means聚类;文献[16]针对现有基于密度优化的K-means算法存在聚类中心搜索范围大、消耗时间久及聚类结果对孤立点敏感等问题,提出了一种基于平均密度优化初始聚类中心的K-means算法adk-means;文献[17-18]针对传统K-means算法初始聚类中心选择的随机性可能导致迭代次数增加、陷入局部最优和聚类结果不稳定现象的缺陷,分别提出一种基于隐含狄利克雷分布(LDA)主题概率模型的初始聚类中心选择算法和基于样本密度的全局优化K均值聚类算法;文献[19]针对典型K-means算法随机选取初始中心点导致算法迭代次数过多的问题,采取数据分段方法,将数据点根据距离分成k段,在每段内选取一个中心作为初始中心,进行迭代运算,以减少迭代次数;文献[20-21]针对K-means算法易受初始聚类中心影响而陷入局部最优问题,运用萤火虫算法的全局搜索能力,提出了改进的K-means算法;文献[22]针对传统K-means算法由于初始聚类中心的随机选择,导致聚类结果不稳定问题,提出一种基于离散量改进K-means初始聚类中心选择的算法;文献[23]为了解决初始聚类中心敏感问题,本文采用分层凝聚聚类算法选取初始聚类中心,以保证中心点的高质量;文献[24]提出了一种改进的K-means算法,建立了一个高质量训练数据集,大大提高了分类器性能,缩短了分类器的训练时间,提高了效率;文献[25]针对K-means算法对初始聚类中心和离群点敏感的缺点,预先处理离群点,从而提出了一种优化初始聚类中心的改进K-means算法;文献[26]针对K-means算法易受聚类中心影响而陷入局部最优的问题,引入了衰减因子加快收敛速度,从而提出一种基于改进森林优化算法的K-means聚类算法;文献[27]针对簇类K值的选取问题,利用指数函数性质、权重调节、偏执项和手肘法基本思想,提出了一种改进K值选择算法ET-SSE算法;文献[28]针对现有的基于密度的聚类算法存在参数敏感,处理非球面数据和复杂流形数据聚类效果差问题,提出一种自然最近邻优化的密度峰值的聚类算法;文献[29]针对K-means算法易受初始中心影响的缺点,引入了混沌搜索思想,提出基于改进粒子群算法的K-means算法。尽管许多研究者对于初始聚类中心敏感问题做出了一些改进,但没有充分考虑到数据集的密度分布情况,对于密度差异较大的数据集处理效果并不是很好。
对于K-means算法初始聚类中心敏感和无法很好地处理密度差异较大的数据集问题,本文提出了一种改进的初始聚类中心选择算法,该算法引入了高密度优先聚类的思想,提高密度差异较大数据集的聚类效果,并增强算法的稳定性。实验表明,对于差异较大的数据集,本文的改进算法聚类结果更加稳定,聚类效果也较好,从而充分说明了本文改进算法是可行的、合理的和有效的。随着数据集的复杂化和多样化,致使数据集的密度差异越来越大,本文算法的提出为以后的研究提供了一个新的思路。
2 改进算法的基本思想
为了了解改进算法的基本思想,需先了解K-means算法基本思想[11]:首先在数据集上随机选取K个数据对象作为初始聚类中心,然后计算每个数据对象与中心点的欧式距离并划分给距离最小的中心点,形成K个簇类,重新计算更新后的簇类中心,重复以上步骤直到聚类中心不再变化或相邻两次簇内误差平方和的差值小于阈值为止。
为了降低随机选取初始聚类中心的敏感性所造成的不稳定性,结合密度块划分的思想,提出了基于初始聚类中心优化的K-means聚类算法。改进算法的基本思想:采用高密度对象更可能为聚类中心的思想,划分了密度集合区间,并在各个集合区间选取初始聚类中心,充分考虑到了数据集的密度分布情况且选取的中心一般都具有唯一性,大大地减少了随机性选取初始中心带来的影响。
设样本数据集合:D={x1,x2,…,xn},k个簇类:C={C1,C2,…,Ck},m个集合:M={M1,M2,…,Mm}。
定义1两个数据对象间的欧氏距离为:

其中,xi,xj为数据对象,xil为xi的l个特征属性,xjl为xj的第l个特征属性。
定义2类簇的中心(Centerk)为:

其中,Centerk表示第k个簇类的中心,Ck表示第k个簇类,xi∈Ck表示属于簇类Ck的数据对象。
定义3点与样本集合间的距离为点与集合内数据对象均值间的距离:

其中,M表示距离最短的两点组成的集合,D′表示删除集合M中数据后的样本数据集,centerMm表示第m个集合Mm的均值。
定义4目标函数即误差平方和为:

定义5某一数据对象与其他簇类内所有数据对象间的距离和为:
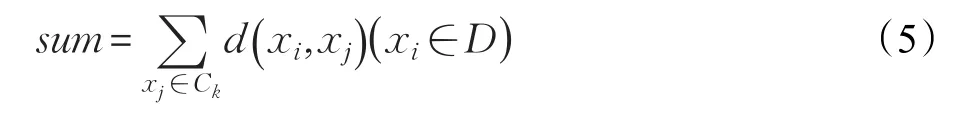
在K-means算法中,数据对象间的相似度是用欧氏距离来计算的,距离越小则相似度越高。对于密度不均匀的数据集密度越高越容易聚在一起,如果能够找到k个分别代表了相似程度较大数据集合的聚类中心,那么将会更加有利于目标函数的收敛。
根据上述的原理(可称为初始聚类中心选择原理)可知,在数据空间分布上找到不同密度内的k个点作为初始聚类中心,具体步骤如下:
(1)根据公式(1)计算数据对象两两间的欧式距离d(xi,xj)(i,j=1,2,…,n),找出距离最短的两个数据对象组成一个样本集合Mm(0≤m≤k),并将它们从总的数据集D中删除。
(2)计算样本集合Mm内所有数据对象的均值。
(3)根据公式(3)计算数据集D中每个对象与样本集合Mm间的距离,找到距离最近的点加入集合Mm,并将它从数据集D中删除。
(4)计算样本集合Mm内所有数据对象的均值。
(5)重复步骤(3)、(4)直到样本集合Mm内的数据对象大于等于α(n k) ,0<α≤1。
(6)如果m 例如有一个2维数据集D,数据大小为14,且它的数据分布如图1所示。 假设需要把它们划分成两类,按照上述的思想寻找初始聚类中心。由图1可知,a和b之间的距离最短,那么就选择a、b构成一个集合M1,并将它们从数据集D中删除;根据公式(3)计算D内对象点与集合M1的距离找出了相邻最短的点c,将c加入集合M1并将它从D中删除,如果规定每个样本集合数据对象最大个数为5,在通过上步思想找到了d、e添加到集合M1中并将它们从D中删除,然后再在D中找到距离最近的两个点l、m构成集合M2并将它们从D中删除,D中距离M2最近的点是j,将j加入集合M2并将它从D中删除,同理i、f也会加入集合M2并将它们从D中删除;最后分别计算集合M1、M2的算术平均作为两个簇类的初始聚类中心。 图1 数据分布图 若数据集N={x1,x2,…,xn}含有n个数据对象,每个数据对象有s维,则改进算法的详细描述如下(占比率P(0 输入:数据集N={x1,x2,…,xn},簇类数目K,占比率P(0 输出:聚类结果。 (1)按照上述初始聚类中心选择原理得到K个聚类中心作为初始中心。 (2)依据公式(1)计算每个数据对象与中心的距离,并把它划分给最近的聚类中心,得到K个簇类。 (3)根据公式(2)重新计算每个簇类的中心。 (4)重新划分簇并更新中心。 (5)直到聚类中心不再变化或连续两次E值的差值小于阈值。 (6)算法结束。 处理器是 Intel®Core™ i5-3470 CPU@3.20 GHz,内存为8.00 GB,Microsoft Windows10的操作系统,系统类型是64位操作系统,x64的处理器,算法编写和编译是在Python3.5环境下实现的。 为了验证本文改进算法对于聚类的有效性,在实验中选取了UCI数据库中的Wine、Hayes-Roth、Iris、Tae、Heart-stalog、Ionosphere、Haberman数据集来进行实验分析,这七个数据集的维度从几维到十几维不等,数据集的大小从几百到上千不等,从而反映出改进算法在不同数据维度和大小上的聚类效果,使得实验结果更具有说服力。数据集详细信息见表1。 表1 数据集基本信息 为了验证改进算法的有效性,实验过程中利用传统K-means算法、文献[14]算法与改进算法进行对比。实验中采用了精准率(precision)、召回率(recall)、F1值、轮廓系数(SC)对算法的聚类结果进行评价。精准率是指正确预测为正占全部预测为正的比例,其值一般在[0,1]区间上,值越大表示正确分类的数据越多;召回率是指正确预测为正与全部为正样本的比值,其值一般在[0,1]区间上;F1值是精准率和召回率的调和均值,其值一般也在[0,1]区间上;轮廓系数[30]是聚类效果好坏的一种评价方式,SC的值在[−1,1]区间上,值越大则表示聚类的结果与真实情况越相近。其中,数据对象的轮廓系数(SC)可通过下列公式得到: 其中,a(i)表示第i个数据对象到所它属于的簇中其他点距离的平均距离,b(i)表示第i个数据对象到所有非它本身所在簇的点的平均距离的最小值,S(i)表示任意一个数据对象的轮廓系数。 另外,精准率、召回率、F1值的计算公式为: 其中,P是精准率,R是召回率,Tp:样本为正,预测结果为正。Fp:样本为负,预测结果为正。Tn:样本为负,预测结果为负。Fn:样本为正,预测结果为负。 为了更好地调节参数,首先需了解参数对结果的影响并对其性能进行测试,测试结果如图2所示。 为了验证改进算法的聚类效果,采用UCI数据集中常见的七组数据集作为实验数据,每组数据分别测试5次,得到传统K-means算法、K-means++、文献[14]算法、本文改进算法聚类结果比较见表2~表4。 图2 参数的性能变化 表2 聚类结果稳定性和准确性比较 表3 各算法在UCI数据集上的SC和F1结果比较 表4 各算法在UCI数据集上的聚类时间比较 从表2中可以看出,在Wine、Hayes-Roth、Iris、Tae数据集中本文改进算法的聚类结果稳定性和准确率明显比K-means++、文献[14]算法、传统K-means算法的效果要好,在Heart-stalog、Ionosphere、Haberman数据集中,本文改进算法的聚类结果稳定性和准确率与K-means++、传统K-means算法相比效果要好,与文献[14]算法相比效果略低。另外,在表2中,改进算法初始聚类中心具有唯一性且敏感度更低,结合表1数据信息,Wine、Hayes-Roth、Iris、Tae数据集样本较小且密度差异较大,其他几个样本较大,因此可推断本文改进算法可能更加适用于小样本和密度差异较大的数据集。对于K-means算法,不同的初始聚类中心会有不同的结果,且结果浮动较大,效果也不明显,而本文算法的初始中心具有唯一性,且最终的聚类效果也较好。从表3可以看出,对于同一数据集本文改进算法聚类结果的轮廓系数都大于或等于传统K-means算法、K-means++、文献[14]算法的轮廓系数,而且对于F1值本文算法较其他三种算法效果更明显。最后,从表4中的数据可以看出,本文算法的时间复杂度较高,算法运行的时间长,不利于提高算法的运行效率。综上对表2和表3的分析,可以得出本文改进算法是可行、合理和有效的。 本文采用UCI数据集中常用的Iris、Wine、Hayes-Roth和Tae验证改进算法初始聚类中心的敏感性,分别将每个数据集聚为多类,每种情况分别生成20组初始聚类中心进行测试,与传统K-means算法、K-means++以及文献[14]算法相比较,实验结果采用最终的聚类结果有多少种以及每个簇类中心与其余点的均值之和(ASSE)评价算法的初始聚类中心的敏感性,分析该改进算法初始聚类中心对于聚类结果的影响情况。最终的敏感性分析情况见表5。从表5可看出,对于同一数据集改进算法的聚类结果更稳定,且效果也较好,说明改进算法的敏感性更低,抗干扰能力更强。 表5 算法敏感性分析 图3 各算法收敛性比较 改进算法的收敛速率主要取决于初始聚类中心的选取和聚类数目的多少。本文采用了四个真实UCI数据集:Iris、Wine、Hayes-Roth和Tae进行实验,当保持每一个数据集相同的簇类数目时,对不同算法在达到同一精度时的迭代次数和运行时间进行比较,每个数据集在不同算法下的迭代次数和的运行速率,如图3所示。从图3(a)可以看出,在每个数据集中改进算法的迭代次数比K-means、K-means++和文献[14]算法的迭代次数都较高一些,说明了改进算法达到同一精度时更晚收敛,由图3(b)可知,在每个数据中改进算法的运行时间比K-means、K-means++和文献[14]算法的运行时间都略长,说明了改进算法达到同一精度时运行时间更长。另外,从图3(a)和(b)可看出Iris、Wine和Tae三个数据集的运行速率比Hayes-Roth快,那是因为前三个数据集的数据量大;Iris、Wine和Tae三个数据集的迭代次数比Hayes-Roth多,那是因为前三个数据集的数据结构更加复杂。该实验说明算法的收敛速率受多个因素的影响。本文的改进算法主要是在初始聚类中心选取时增加了优化过程,因此其复杂度主要体现:一是改进算法的时间复杂度为O(n(k+s-1)-s2+k×m×d×n)与传统K-means算法的时间复杂度(O(n×m×d×k)相比更长,二是空间复杂度为O(s×m+n×m)与传统K-means算法的空间复杂度(O(n×m)相比更大,式中n为数据对象数目,k为簇类数,m为每个元素字段个数,d为迭代次数,s为集合空间的数据对象数目。 传统K-means聚类算法广泛运用于数据挖掘领域,随着大数据信息时代的到来,该算法已不能满足数据挖掘的需要,为了提高算法的聚类效果,本文提出一种改进K-means聚类算法。实验表明,改进算法的初始聚类中心稳定,消除了初始聚类中心的敏感性,且通过比较聚类评价指数的值得到改进算法的聚类效果更好。另外,本文算法的提出,为高密度差异数据集的处理提供了一个更加高效的方法。本文只对初始聚类中心的影响和样本数据的密度差异两方面进行了相关研究,还有许多的方面有待于去研究和思考,基于此本研究的下一步就是对该算法的收敛性和复杂度做出改进,探索一种更好的方式提高算法的效率。
3 改进算法的具体描述
4 实验结果与分析
4.1 实验环境
4.2 实验数据

4.3 实验结果






4.4 结果分析
5 改进算法敏感性分析


6 改进算法收敛性和复杂度分析
7 结束语
猜你喜欢
睿士(2023年2期)2023-03-02 02:01:09小学生导刊(2018年34期)2018-12-18 01:53:14意林(2018年3期)2018-03-02 15:17:24电子测试(2017年15期)2017-12-18 07:19:27厦门理工学院学报(2016年1期)2016-12-01 04:50:48山东青年(2016年3期)2016-02-28 14:25:55北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48智能系统学报(2015年4期)2015-12-27 09:38:39母子健康(2015年1期)2015-02-28 11:21:33电子设计工程(2015年6期)2015-02-27 12:04:53
