
基于长短期记忆神经网络模型的共享单车短时需求量预测
2020-08-03 04:15曹旦旦范书瑞夏克文
科学技术与工程 2020年20期
曹旦旦, 范书瑞, 张 艳, 夏克文
(河北工业大学电子息信工程学院, 天津 300401)
如何精确地预测短时间内某区域需要的共享单车数量从而合理地进行调度是一个亟待解决的问题。现如今已经有一些机器学习方法,比如随机森林、支持向量机等都已经在共享单车的研究中被广泛使用。文献[1]采用传统最小二乘法(ordinary least square,OLS)线性模型、二分类和多分类Logit模型等对单车需求量进行预测,但是需要大量观测数据,且具有明显的局域性,回归关系不能很好符合实际情况;Bacciu等[2]、Bajari等[3]采用支持向量机和随机森林模型预测,但是并没有详细介绍如何预测短时间内的单车使用量情况。
为了提高计算精度、准确预测每天每小时的纽约市共享单车需求量,其预测方法已由以往的机器学习模型,如随机森林(random forest,RF)、支持向量机(support vector machine,SVM)和人工神经网络(artificial neural network,ANN)等[4],向深度学习方法转变。BP神经网络具有良好的组织和适应性,其数据样本经过自己学习的过程,就能够解决非线性问题[5],但是不足之处就是在训练的过程中容易形成局部的最大值和最小值的现象;循环神经网络(recurrent neural network,RNN)擅长处理连续的时间序列数据,但运算中容易发生梯度消失、梯度爆炸等问题。针对RNN模型存在的不足来进行改进得到的模型就是长短期记忆(long short-term memory,LSTM)模型,直到现在该模型已经在很多时间序列研究领域被广泛使用并得到了较好的效果[6-8]。在爬取纽约共享单车数据的基础上对数据进行特征分析,分析影响单车需求量的主要因素;并提出基于LSTM循环神经网络方法对共享单车短时需求量进行预测,然后与传统的RNN和BP神经模型预测结果比较。预期LSTM模型在该数据集上能有一个较好的预测效果。
1 LSTM模型的网络结构和原理
LSTM最初是在1997年由Hochreiter等[9]提出,是在循环神经网络RNN的基础上改进而来的[10]。LSTM神经网络和RNN不同的地方是,它不仅增加了具有保存以往信息的记忆存储单元,通过反向传播算法[11]对数据进行训练,它还解决了RNN梯度消失和长期依赖性缺失的问题。LSTM广泛应用于各个方面,比如自然语言翻译和语音识别等,还可以应用于时间序列的预测[12],都具有较好的效果。
LSTM的网络结构是利用门的控制机制来工作的,包含一个记忆细胞和3个控制门,分别为输入门、输出门和遗忘门[13]。网络结构如图1所示。图1中的3个方框代表细胞在不同时序的状态,中间方框中带有的小框是激活函数为Sigmoid的前馈网络层[14],具有tanh的小方框是具有激活函数tanh的前馈网络层,Xt代表t时刻的输入,ht代表t时刻细胞的状态值。LSTM各个门的工作原理如下。
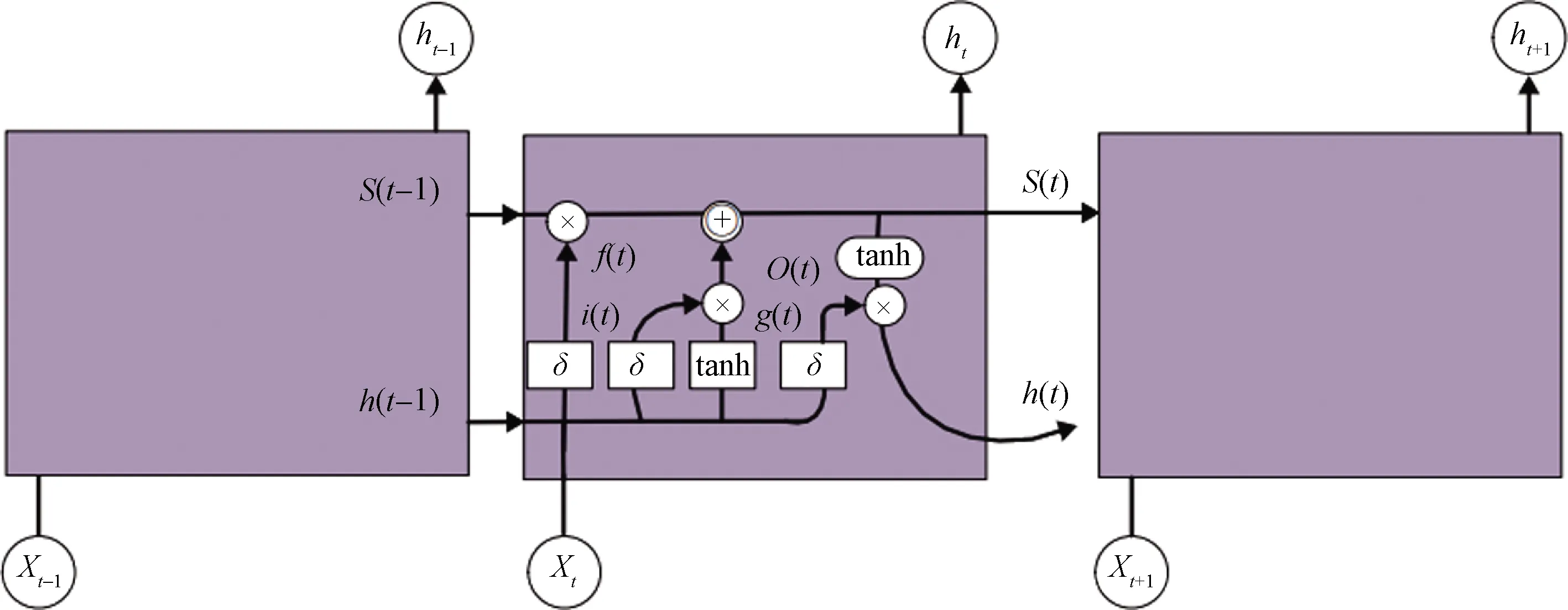
图1 LSTM网络结构Fig.1 LSTM network structure
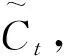
it=δ[Wi(Xt,ht-1)+bi]
(1)
(2)
其次,计算遗忘门在时间t的激活值ft,公式为
ft=δ[Wf(Xt,ht-1)+bf]
(3)
通过上述两个步骤,就能够计算出来细胞在时间t的状态更新值Ct,公式为
(4)
计算输出门的值,公式为
Ot=δ[Wo(Xt,ht-1)+bo]
(5)
ht=OttanhCt
(6)
经过上面的4个计算步骤,LSTM就可以有效地利用输入来使其具有长时期的记忆功能。
2 LSTM网络模型的搭建
首先,在Windows操作环境下构建CPU版本的Tensorflow框架。Tensorflow不但能实现深度学习算法,还能实现例如回归预测、聚类分析等算法。LSTM模型使用Tensorflow提供的LSTMCell模块进行搭建,该模块将LSTM的隐藏层封装在Tensorflow内,并包含3个门结构,分别是遗忘门、输入门和输出门结构,隐藏层的数目要根据实际情况来定,所设置的隐藏层的数目为10。为了避免出现过拟合现象,采用Dropout机制来增强模型的泛化能力。
以往的搭建网络的过程是以网络节点为单位来进行网络布局,而使用Tensorflow搭建LSTM框架的过程是以网络层数为单位来进行模型的构建,Tensorflow中的LSTMCell包含多个网络节点的输入和输出层,它们都由向量表示,向量的长度就是该层节点的个数。
在搭建模型和训练模型的过程中,最重要的一点是参数的初始化,不同类型的特征参数需要进行不同类型的初始化,这对模型的训练效果具有十分重大的影响。对连续性参数变量初始化的方式为:dummies=pd.get_dummies(rides[each],prefix=each, drop_first=False),初始化离散参数变量的方法是:mean, std =data[each].mean(), data[each].std()。用批量随机梯度下降法对模型进行训练。
3 实验过程及结果分析
3.1 实验环境
在Windows7系统中使Anaconda Navigator3(Jupyter notebook),Python3.6为实验平台进行仿真实验,将Tensorflow所提供的LSTM等神经网络模型用于仿真实验。
3.2 实验数据获取
采用网络爬虫的方法,从美国国家海洋和大气管理局官方网站气象服务中心提供的纽约市历史天气数据集中爬取纽约市的历史气象数据,所爬取的数据范围从2015年1月—2018年12月的小时数据,共计48个月,共35 064条数据。其中某些数据存在缺失现象,其数据字段如表1所示。
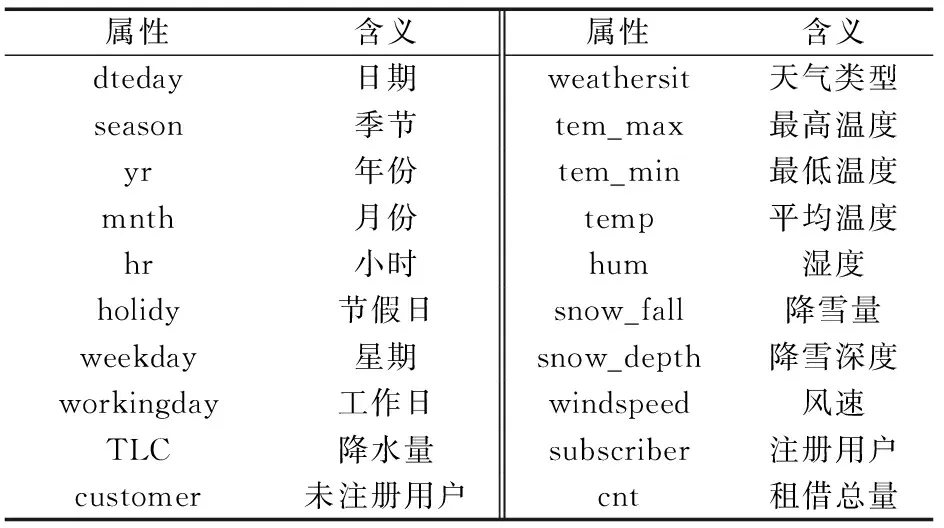
表1 实验中使用的数据集Table 1 Data set used in the experiment
3.3 影响因子分析
3.3.1 气象因子的影响
共享单车是一种受气象影响显著的交通工具,图2所示为2015—2018年纽约地区共享单车租借总量与4种气象因子的相关性热力分布图。
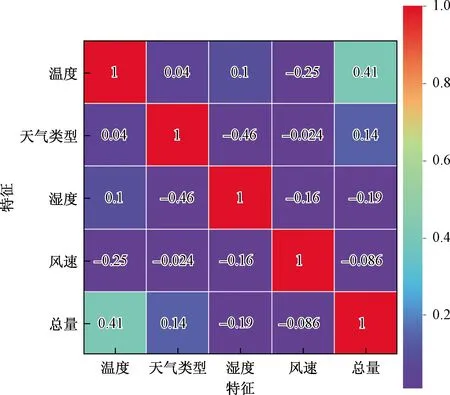
图2 气象因子与单车使用量的相关性热力图Fig.2 Correlation between meteorological factors and bicycle usage
由图2可得,共享单车需求量与4种气象因子之间都存在相关性。温度与租车人数正相关,寒冷抑制租车需求;湿度与租车人数负相关,雨雪天气抑制了单车租借需求;单车需求量与温度和湿度的相关性最高,分别为0.41和-0.19。
3.3.2 时间因子的影响
(1)共享单车使用量受时间影响,利用2015—2018年美国纽约地区共享单车项目数据进行时序变化规律分析,结果如图3所示。
共享单车使用在2015年1月—2018年12月期间,总体用量逐年上升,每一年从1月开始租车人数就迅速增加,直到6月用车人数最多,随后至10月用车人数缓慢减少,在10月之后大幅减少,这显然与季节有关。在1月、2月和12月这样的比较冷的季节,用车的人数工作日高于非工作日;在温暖和凉爽的季节(5—11月),用车的人数非工作日数高于工作日。可以得出结论,时间因素如年和月份也会对租借数量产生重大影响,因为月份和季节对租借数量的影响是一致的,月份更详细,因此要留下月份特征,删除季节特征。
(2)图4和图5进一步考察了2015—2018年平均每小时和每星期对共享单车的使用量的影响,并绘制折线图和箱线图。
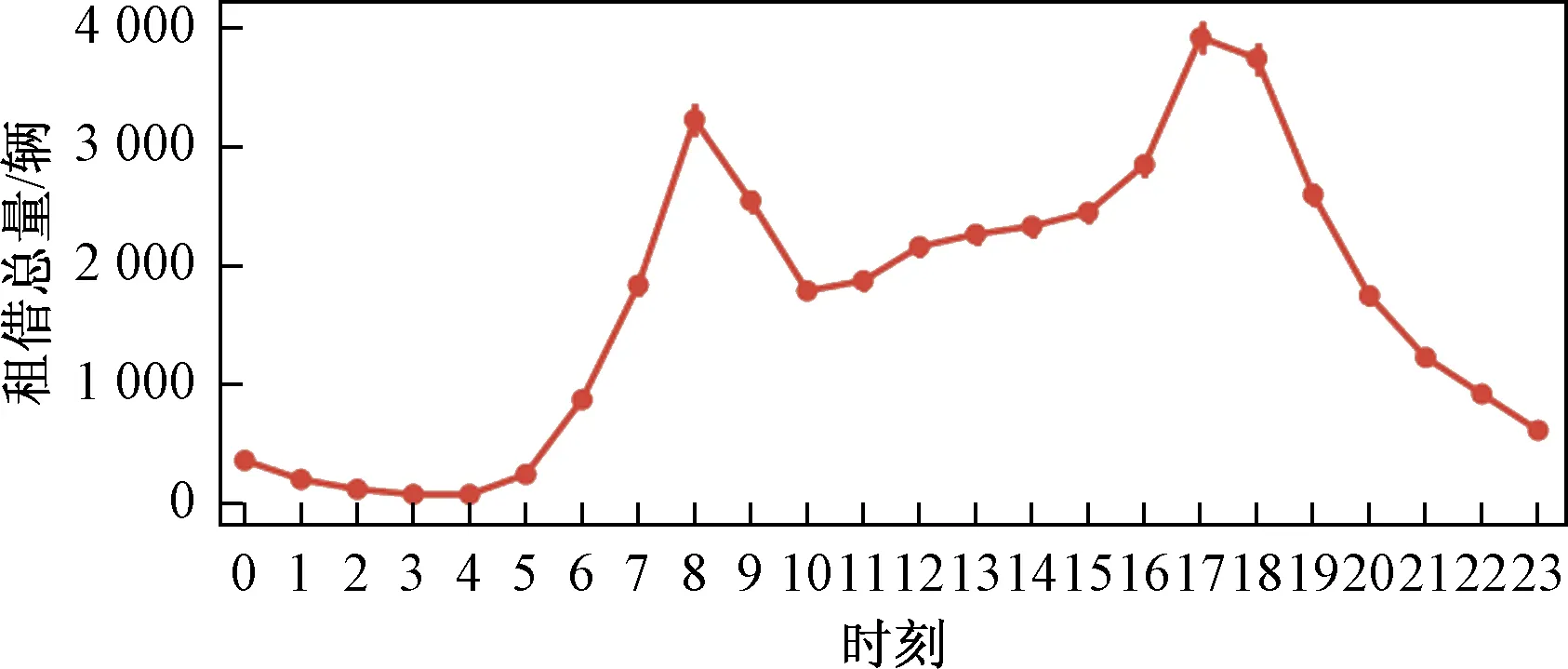
图4 2015—2018年平均每小时共享单车使用量Fig.4 Average bicycle usage per hour for 2015—2018
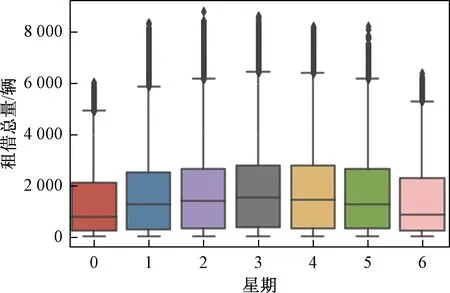
图5 2015—2018年平均每星期共享单车使用量Fig.5 Average bicycle usage per week in 2015—2018
从图5中可以看出,周一到周五租车人数相对较多,每天有两个高峰期,分别是7:00—8:00点左右和17:00—18:00点左右,正好是工作日的上下班高峰期;此外,从12:00—16:00点的使用量较高,这进一步反映了时间段,特别是高峰时段,是影响自行车需求的重要因素。
3.4 实验数据预处理
(1)填写缺失数据:通过上述方法获得的数据为不完整数据,需要填写缺失数据以便于在接下来的预测工作中使用。
(2)虚拟变量:通过Pandas库中的get_dummies()函数对季节、月份和天气等离散变量创建二进制虚拟变量。
(3)调整目标变量:为了更轻松地训练模型,需要将温度、湿度和风速等连续变量标准化,使它们的均值为0,标准差为1;同时保存换算因子,在后续进行预测时可以还原数据,其公式为
(7)
式(7)中:max表示所选取的数据中特征的最大值;min表示数据特征的最小值;xij为原始数据;Xij为标准化后的数据。
3.5 LSTM网络结构的设定
3.5.1 评价指标
为了评估LSTM预测模型的预测性能,选择均方根误差(root mean square error,RMSE)指数来评估模型的预测精度,RMSE是用来衡量模型预测值与真实值之间的偏差的物理量,值越小,预测出来的效果越好,公式为
(8)
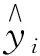
3.5.2 网络模型的拟定
研究使用单层的LSTM模型对纽约市共享单车需求量进行预测。利用深度学习库中Tensorflow 中所提供的LSTMCell模型来预测出每小时的单车需求量。通过add函数将多个网络层进行线性堆叠。通过不断的调试和搜索,最终确定的网络结构参数的过程如下。
(1)层数设置:构建了单层LSTM模型结构,输入的共享单车数据的总维数为60,所设定的的隐含层的数目为10层,输入层是12,输出层是1。
(2)参数设置:采用的激活函数为ReLU激活函数,每批次训练样本数batch_size设置为10,时间步长time_steps设置为10,学习率learning_rate设置为0.000 5,训练数据的截断长度num_steps为50,向量的维度lstm_size为256。为了在训练的过程中防止过拟合现象发生,将每一层网络节点的舍弃率Dropout设置为0.75。
(3)维度转换:输入特征时,需要将张量tensor转换为二维计算,计算结果作为隐藏层的输入。,最后再将 tensor 转成三维作为 lstm cell 的输入。通过get_batches批量处理数据。
3.6 对比实验与结果分析
3.6.1 网络训练
基于纽约市2015—2018年每小时的共享单车使用量数据35 064条,其中训练数据35 033条,剩下的数据用于测试。每次训练的样本数batch_size=10,训练轮次数为epoch = 100,每轮指定模型的相应测试数据,并输出每次训练记录。训练模型时可以更改迭代次数,迭代的次数越多预测越准确,但缺点是需要的时间也长,本次实验的迭代次数为6 600,使用的损失函数为均方误差RMSE,选择自适应矩估计Adam为优化器。图6所示为模型在训练的过程中损失函数下降的过程,从图6中可以看到,模型在训练集上的损失函数不断下降并趋近于0。图7所示为模型在验证集上的预测精度变化过程,从图7中可以看到,验证集的精度逐渐上升并趋近于0.9,说明了所选择的参数为该模型在该数据集下的最优参数组合。
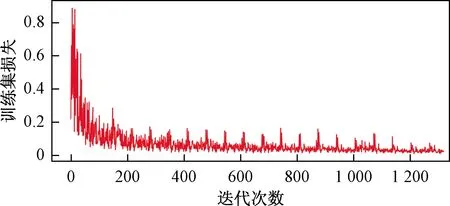
图6 训练集损失变化曲线Fig.6 Training set loss curve
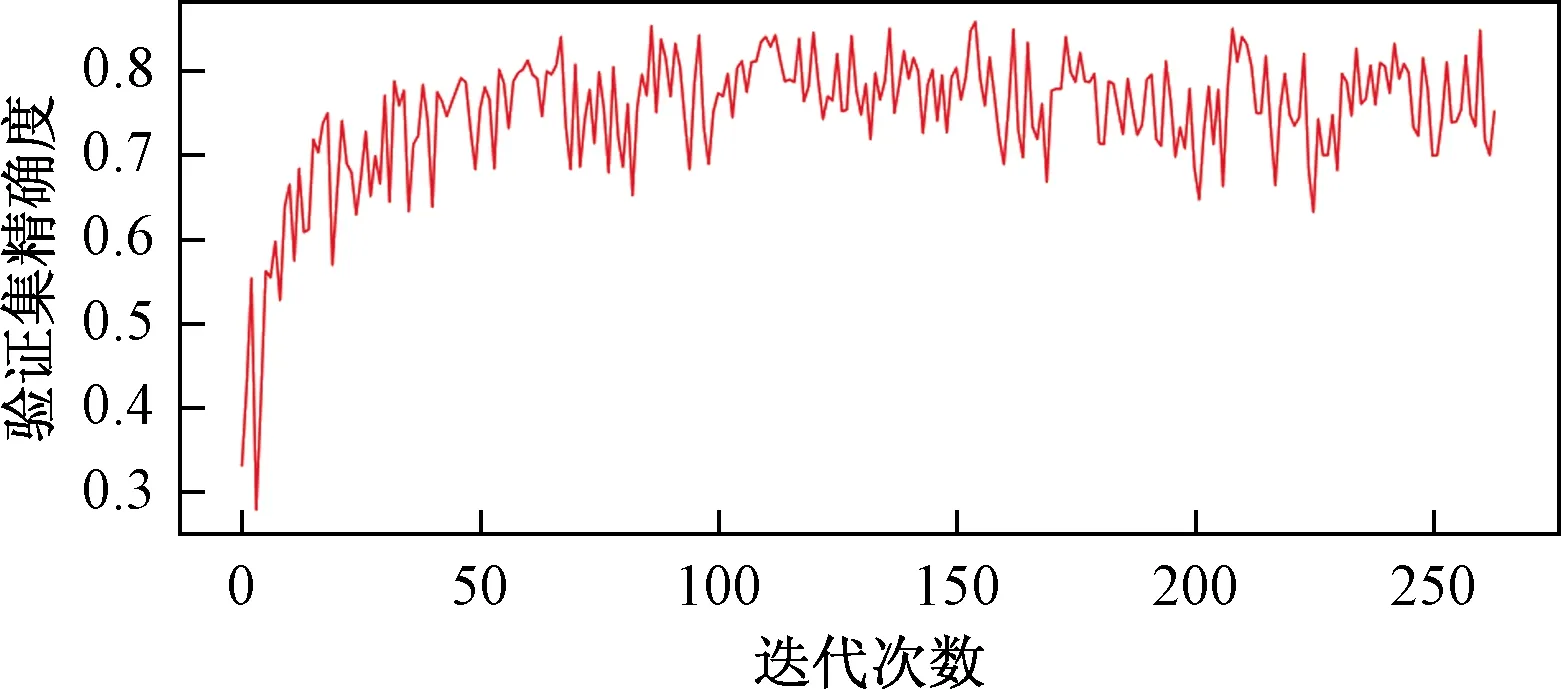
图7 验证集精度变化曲线Fig.7 Verification set accuracy curve
3.6.2 模型预测结果
经过训练后的模型为最优的模型,用该模型对剩下31 d的数据进行测试,并将模型的预测值和实际值进行反归一化处理,预测完后的模型所得出的RMSE=0.090,并将模型的预测值和实际值进行比较,比较的结果如图8所示。从图8中可以看出,LSTM模型能够很好地预测数据,除了最后10 d,因为这10 d是节假日,自行车需求量和平时不一样。预测的每小时使用量曲线和实际车辆使用量曲线趋势相吻合,模型的拟合效果很好,满足回归预测过程中的经验误差要求。因此,LSTM预测模型在共享单车需求预测中是可行的。
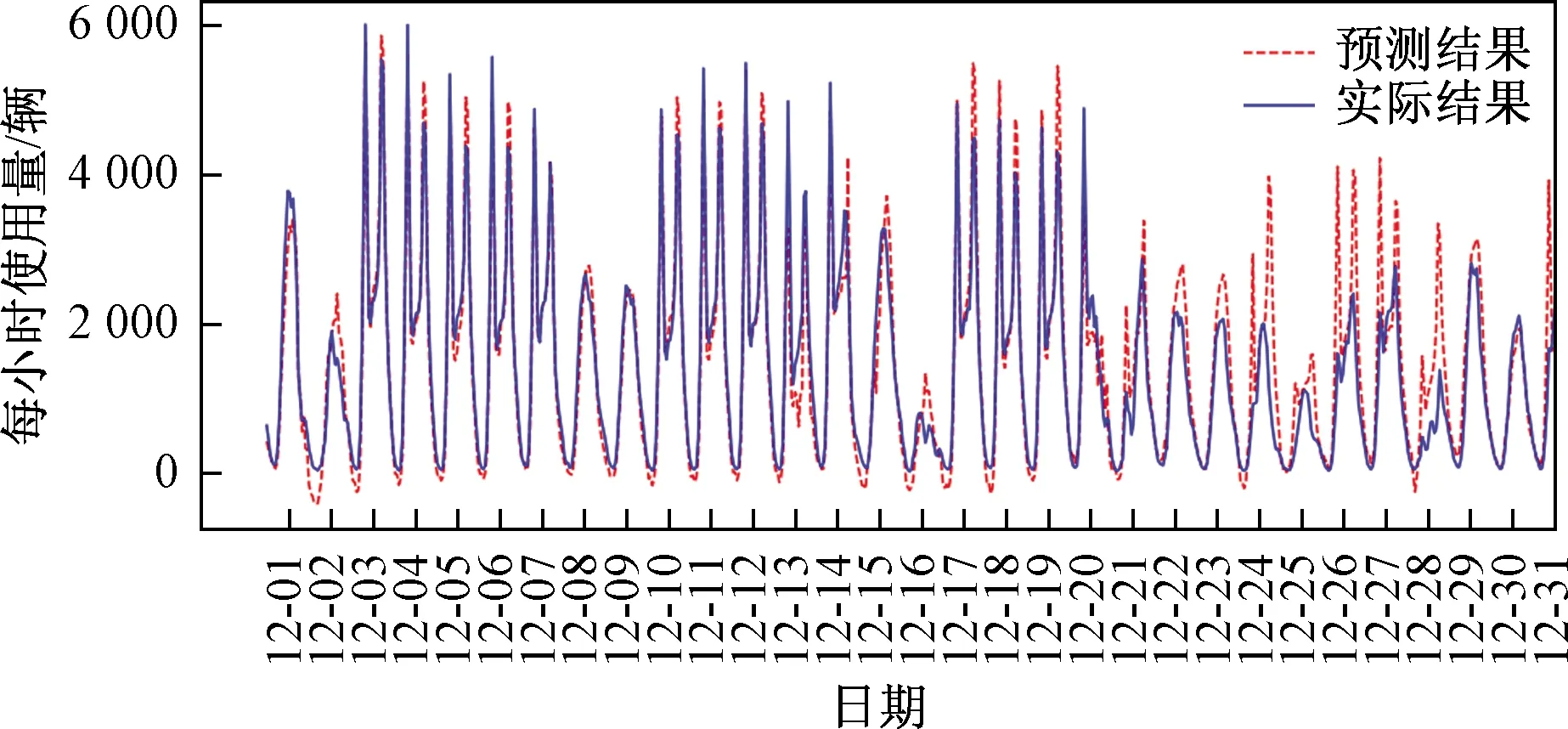
图8 LSTM神经网络预测结果曲线Fig.8 LSTM neural network prediction result graph
3.6.3 预测模型对比
(1)预测误差对比。利用BP神经网络模型和RNN循环神经网络对同样的共享单车数据集进行模型搭建并预测,并将预测结果和真实结果进行反归一化处理,并计算出预测结果值和实际需求量结果值的差值即预测误差,其预测误差曲线如图9所示。由图9可得,LSTM神经网络模型在共享单车数据集上的预测效果最好,不仅能够很好地预测数据的变化趋势,而且预测误差最小。而RNN循环神经网络和BP神经网络对共享单车数据的预测结果和预测误差都稍差于LSTM模型。所以在共享单车需求量预测方面,LSTM模型更加合理。
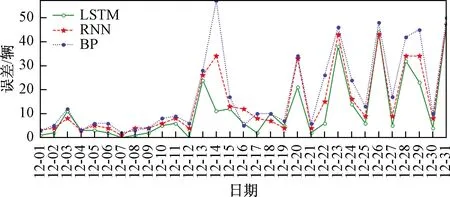
图9 3种网络模型预测误差对比Fig.9 Three network model prediction error comparison chart
(2)评价指标对比。上述3个模型拟合完所有数据后所得到的RMSE和预测精确度如表2所示。根据表2中每个模型的性能指标结果,LSTM模型的RMSE最小值为0.090,预测精度高达0.860,模型的拟合效果最好,变量对预测值的解释能力最强;RNN相比LSTM较弱,这是由于RNN在模型训练过程中存在梯度爆炸和梯度弥散的现象,而LSTM正好解决了这个问题;BP神经网络的性能最差,预测精度最低,RMSE最大,综合来看LSTM的性能最好。

表2 不同模型的评价指标对比Table 2 Comparison of evaluation indicators of different models
4 结论
针对如何精确地预测一个区域小时级别的共享单车需求量的问题,通过爬取纽约共享单车数据集并分析各个特征变量对单车租借总量的影响,最后采用LSTM神经网络对纽约市共享单车每小时时需求量进行预测。经过实验得到以下结论。
(1)影响单车需求量的主要因素包括温度、节假日、季节以及早晚高峰时间段等因素,最主要的是温度的影响和早晚上班高峰时间段(7:00—8:00点和17:00—18:00点)的影响比较大。
(2)与传统BP神经网络算法和循环神经网络RNN算法相比,LSTM模型预测精度最高,值为0.860,预测误差较小,且预测结果曲线与真实结果曲线相吻合,可以用来对共享单车短时需求量进行预测。
猜你喜欢
电子乐园·下旬刊(2022年5期)2022-05-13
意林彩版(2022年1期)2022-05-03
今日农业(2021年6期)2021-11-27
数学大王·中高年级(2021年6期)2021-09-27
读友·少年文学(清雅版)(2020年1期)2020-05-20
中国计算机报(2020年10期)2020-04-07
当代水产(2020年2期)2020-03-17
领导决策信息(2017年9期)2017-05-04
岷峨诗稿(2017年4期)2017-04-20
