
小型断路器柔性装配中视觉识别系统的设计与应用
2020-08-03 01:50闫俊涛吴自然陈宪帅吴桂初
计算机测量与控制 2020年7期
闫俊涛,吴自然,陈宪帅,吴桂初,舒 亮
(温州大学,浙江 温州 325000)
0 引言
随着制造行业不断发展,众多企业已经实现了“机器换人”的自动化改造,正在向智能化迈进。传统的自动化装配都是通过振动盘来上料保证零件姿态和位置的一致性,然后通过示教或离线编程的方式使工业机器人从固定的位置夹取零件至固定的安装位置,之后重复固定的轨迹、执行固定的任务[1]。这种传统的自动化装配虽然在一定程度上提高了产品的质量和生产效率,但是也存在一些问题:1)某些零部件无法通过振动盘机构调整姿态和位置,需要通过特定复杂机构完成调整;2)按照传统的方案一台工业机器人通常只执行一项固定的安装任务,为了完成所有的安装步骤就需要配置大量的工业机器人,这样会增加设备的投入,也造成了工业机器人资源的浪费;3)最重要的是,这种传统装配方案是根据装配零件的形状特征来设计振动盘、导轨、工业机器人夹爪等配套设备,在产线的灵活度方面存在很大的缺陷,一旦产品升级或者其中某一个零件有轻微改动,则整个配套设施都需要重新设计和改造。
随着机器视觉技术迅速发展,将机器视觉引入自动装配中可以根据视觉识别结果来调整抓取点坐标及姿态对零件进行抓取,然后将夹起的零件进行相应的平移、旋转操作以达到标准的安装位置和姿态[2]。一些基于机器视觉的自动化装配的方案也相继被提出。郭瑞,刘振国等人[3]提出了通过视觉系统对机器人精确定位的智能引导方法,相机采用移动式安装,固定在机器人手爪上跟随手爪移动使机器人可以根据工件的实际位置动态调整抓取点,实现装配机器人精确定位和智能抓取。刘泉晶,沈俊杰[4]提出了利用机器视觉技术结合CV-X100 Series Ver3.4图像处理软件进行边缘位置和边缘宽度检测,得到零件的外形尺寸,提高产品的装配质量的方法,并且在汽车发电机部件自动装配上得到应用。张明建,曾伟明[5]提出了以德国MVTec Software GmbH公司开发的MERLIC图像处理软件为支撑的机器人视觉控制平台,构建了小型电机目标装配零件与装配位置自动识别的单目视觉机器人智能抓取系统。徐远,宋爱国等人[6]针对工业生产中自动装配技术装配精度不高的问题,提出了一种基于机器视觉和六维力传感器的自动装配控制方法,该方法采用两个摄像头对装配物体和装配孔两次定位,通过六维力传感器实现装配过程中的力位控制,完成精密装配作业。由以上可知机器视觉技术在自动装配领域具有很好的应用前景。然而现有的方案只是针对单一的对象进行识别和抓取,如果在待识别区域有多种零件,并且每一种零件都需要进行类别、坐标、姿态的识别,同时需要根据识别的结果来切换工业机器人末端的气缸及夹爪,现有的方案无法满足上述需求。
针对上述问题,本文提出了一种基于机器视觉的柔性装配方案,该方案是通过深度学习在相机视野中先进行多种零件种类的识别,再结合图像处理算法程序完成多个零件的种类、坐标以及姿态的识别,可根据不同产品的特征进行灵活优化,达到最佳的识别效果,通过该视觉识别模块可以对零件种类以及实际的位置坐标和姿态进行识别,然后将识别结果发送给工业机器人,指导工业机器人进行夹爪的切换和抓取点的位置调整,最后将夹起的零件进行旋转和平移达到标准的安装位置和姿态,从而实现了一机多用的柔性装配。该系统已经在小型断路器装配生产线上得到了应用。
1 需求分析及系统总体方案设计
1.1 零件装配需求分析
如图1所示是标准托盘及零件安装姿态图,其中零件0、1、2、3、4、5是在相机视野中小型断路器的装配零件通过视觉识别和工业机器人系统进行分类和姿态调整后的标准状态。
实际工程应用中为了使系统具有一定的容错能力,在设计标准零件托盘的时候采用倒角及滑轨的形式,使零件在一定的角度和坐标偏差的情况下依然可以放置到正确的位置,根据多次实验证明,旋转角度的容错偏差范围为±0.8°,坐标的容错偏差范围为±0.3 mm。

图1 标准托盘及零件安装姿态图
如图2所示是级联分类器的零件分类图,其中包含了小型断路器中可采用自动装配的内部零件图以及所有可能的放置状态,其中包含6大类零件,零件名称分别为0、1、2、3、4、5,另外,由图2中可知其中有些放置状态无论旋转多少角度都无法达到如图1所示的标准的安装姿态,还需要借助翻转才能达到标准姿态,因此,对于同一零件的不同放置状态进一步细分,采用二级命名的形式“(零件种类)-(放置状态)”,如“0-0”表示如图2所示中第一个零件的第一种状态,其它零件的命名以此类推。这种命名方式可以根据第二级名称——放置状态来确定零件是否需要在旋转平移的基础上再进行翻转操作才能达到标准姿态,其中翻转的方式也会根据二级分类器识别出的结果调出提前设定的翻转程序。由此,任意零件的任意姿态和位置都能通过视觉系统的识别结果指导工业机器人进行夹取、旋转、平移、翻转操作后以标准的姿态放入标准托盘中,之后进入组装程序进行最后的组装操作。
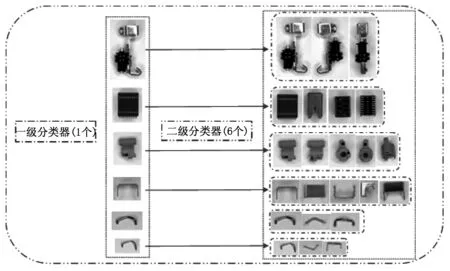
图2 级联分类器
1.2 系统总体方案设计
如图3所示是基于机器视觉的小型断路器柔性装配系统的整体架构框图,该系统主要由视觉识别和运动控制两个子系统构成,其中视觉识别子系统是核心的组成部分,它包括图像采集、图像处理、相机标定以及通信模块,该子系统可以获取相机视野中每个待装配零件的种类、夹取点坐标以及姿态信息,其中夹取点坐标再经过相机标定转换到工业机器人坐标系下,然后将上述信息通过Socket通信[7]发送给机器人控制器。此时运动控制子系统中的工业机器人就能够通过这些信息切换夹爪来夹取和调整零件的位置和姿态,以达到标准的安装状态。
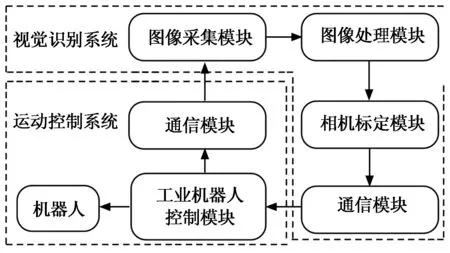
图3 系统整体架构框图
基于机器视觉的柔性装配系统硬件部分由视觉识别部分和机器人运动控制部分构成。如图4所示为系统硬件实物图,其中视觉识别包含相机支架、工业相机及镜头、光源、底座、待识别零件,机器人运动控制部分包含工业机器人、伸缩气缸、夹爪、中间过渡组件、标准托盘,另外有些特殊的零件姿态不能直接通过旋转平移得到,因此需要中间过渡组件进行中转调整,得到零件标准的安装姿态后放入到标准托盘中,标准托盘中的零件传送到下一工序直接进行装配。

图4 系统硬件实物图
2 视觉识别系统方案设计
视觉识别部分包含3个重要的内容:一个是单个零件种类的识别,包括零件的不同种类以及同一零件的不同放置状态;另一个是零件的姿态(角度)识别,再有一个是零件位置坐标的确定。如图5所示为视觉识别系统程序设计流程图,该流程图展示了从接收工业机器人的图片采集信号到最终将获取到的信息发送给工业机器人的过程为一个处理周期。其中包括用Python + OpenCV[8]调用相机获取图片,然后将图片经过预处理分割成多个独立的零件图,这些零件图一方面经过深度学习模型来进行类别预测,进而根据预测类别找到对应的零件模板,通过与模板进行特征提取与匹配得到单应性矩阵,通过单应性矩阵分解可以得到旋转矩阵,通过旋转矩阵就可以得到当前零件相对于该零件模板的旋转角度,另一方面,也可以通过模板中定义的夹取点坐标来找到当前零件图片对应点的坐标,然后再根据之前该零件图片切割点的位置坐标求出夹取点在图片像素坐标系中的位置,该像素坐标点再经过相机标定和坐标转换就可以得到夹取点相对于机器人坐标系的位置坐标。结合零件类别、旋转角度、夹取点坐标就可以确定出该零件需要的夹爪类型,零件夹取点位置坐标,以及将零件进行旋转平移特定角度之后放置到对应的安装托盘上,以供后续的装配机器人进行装配。
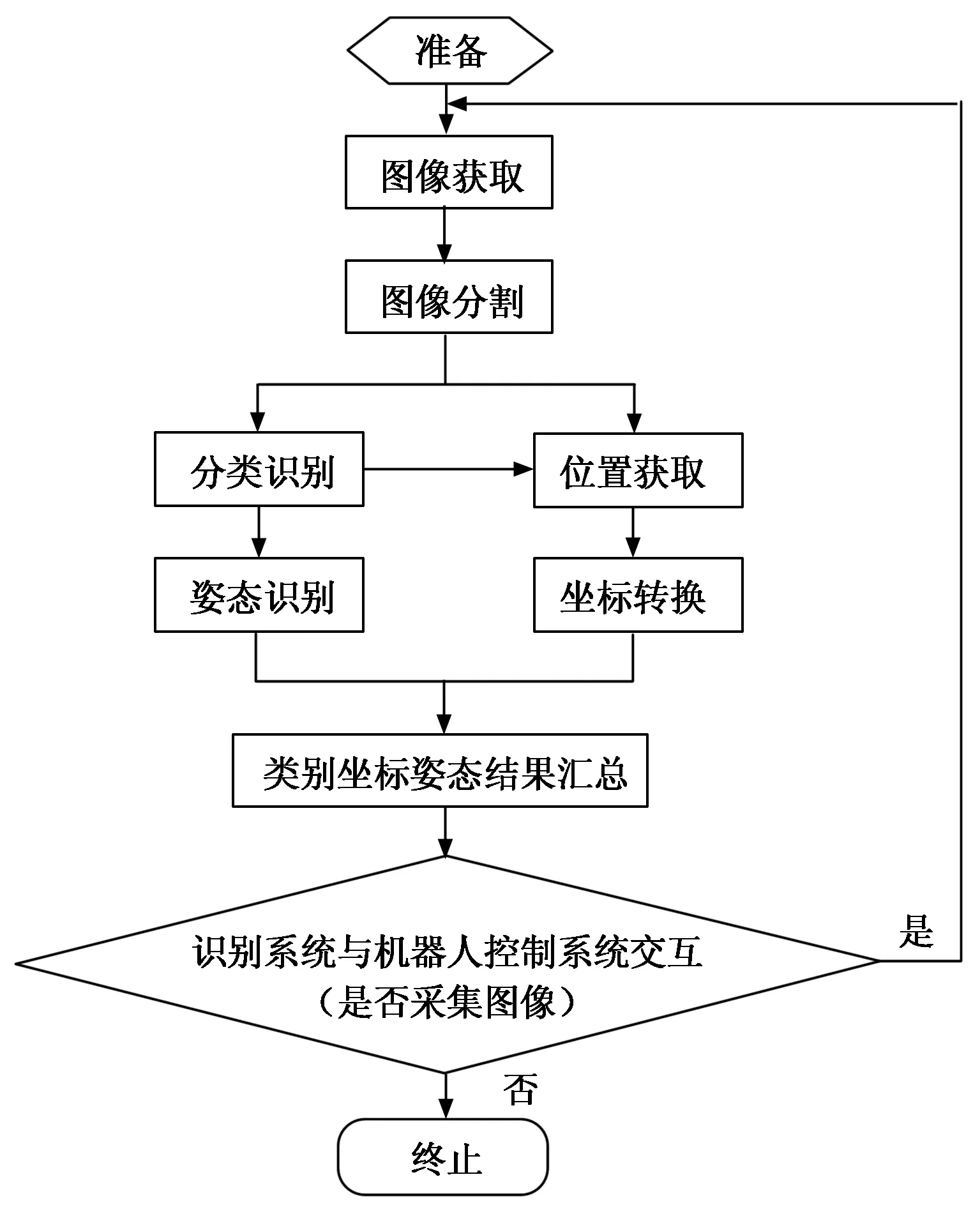
图5 视觉识别系统程序设计流程图
3 方案实现
3.1 图像获取及分割
如图6所示为图像预处理过程框图,其中包括Sobel算子[9]提取零件的边缘信息,高频滤波及二值化以及形态学腐蚀与膨胀,完成上述预处理后对图像中的零件进行分割。

图6 图像预处理过程框图
由工业相机获取相机视野中如图7所示的图片,之后进行如图8所示Sobel算子计算x、y方向的梯度然后梯度做差,如图9所示低通滤波器平滑图像高频噪声然后模糊二值化,如图10所示图像形态学腐蚀与膨胀,一系列图像预处理操作后得到如图11所示的零件的最小矩形框,然后按照最小矩形框的4个角的坐标计算出零件的垂直切割点,从而得到如图12所示的单个零件的切分图。

图7 图片获取 图8 Sobel算子

图9 滤波及二值化 图10 形态学腐蚀与膨胀

图11 画最小矩形框

图12 零件切分
3.2 零件种类识别
零件种类识别是基于深度学习搭建的分类器模型经过大量训练样本训练,最终得到专注于对这部分零件进行分类的特定分类器。另外,由于在实际的识别任务中不仅要识别零件种类还要识别该零件的放置状态,因为同一零件的不同放置状态在后期机器人抓取的情况处理的方法也有所不同,因此也归属于不同的类别。对于这种特殊的分类情况,本文采用了级联分类器来做分类,如图2所示,其原理是第一级分类器做零件的种类识别,本文为6大类,第二级分类器是接在每一个一级分类器之后的,作用是在确定了该零件类别的情况下再做这个零件不同放置状态的识别,即识别哪一面朝上,其中零件0有3种放置状态、零件1有4种、零件2有5种、零件3有5种、零件4有3种、零件5有3种,一共有23类;采用两级分类器来识别的目的是为了提高识别的准确率,如果用常规的分类器一次做23种分类,则分类错误率会较高,而这种级联的方式第一级只做6分类,第二级最多做5分类,这样错误的概率就会得到有效的降低。整个分类器需要根据训练样本得到7个模型参数,以实现7个分类器的功能,其中1个一级分类器,6个二级分类器。
在图像分类识别领域,卷积神经网络以其模型简单且识别准确率高而普遍应用,其中以LeNet5经典网络模型为开端,LeNet5模型简单但是识别精度不够高,而在LeNet5上发展而来的VGG-Net架构[10]采用了更深的网络架构、更小的卷积核以及用ReLU作为激活函数,在一定程度上提高了识别的准确率。虽然到目前为止已经有更深更复杂的模型在大型的识别任务比赛中比VGG-Net表现更好,但是针对本文的分类任务(一级分类器6类、二级分类器最多5类),VGG-Net在保证模型和参数简单的情况下足以达到预期的识别准确率。本文在实现分类器模型设计时,从卷积神经网络模型的识别准确率和模型的复杂程度来综合考虑,参考的是经典的CNN(卷积神经网络)结构模型VGG-Net架构,在该架构的基础上根据实际零件的特征和分类需求进行了深度和卷积核参数以及输出参数的调整,得到如图13所示的基于卷积神经网络的分类器模型,根据本文的两级分类需求,一级分类器是识别零件的大类,各个零件的特征区别较大,因此采用5*5的卷积核以及较大的步幅就能达到分类效果,同时,一级分类器是6分类,因此最后输出的Softmax参数设置为6。而二级分类器是对同一零件的不同放置状态分类,特征相似度较高,因此采用3*3的卷积核以及较小的步幅,以获取更多的细节特征,由于二级分类器是对不同放置状态进行分类,而每种零件可能的放置状态不一样,因此每一个二级分类器的最后输出的Softmax参数都是取决于该零件有几种放置状态。

图13 基于卷积神经网络的分类器模型
3.3 夹取点坐标及姿态获取
对于零件姿态的识别,根据零件特征点是否明显采用了两种处理方案。方案一:特征匹配法,其原理是找出模板与实际零件图片的对应特征点对,然后根据这些特征点对求出单应性矩阵,根据单应性矩阵可以求出旋转矩阵,再根据旋转矩阵求出对应的旋转角度。单应性矩阵H与模板中的夹取点坐标相乘可以得到实际的夹取点坐标。
假设两张图像中的对应点对齐次坐标为(x′,y′,1)和(x,y,1),单应矩阵H定义为:
(1)
则有如下对应关系式:
(2)
上式经过矩阵运算可得到如下对应的表达式:
(3)
(4)

(5)
理论上一组对应点坐标可以带入表达式(3) (4)中可以得到2个求解方程式,则四组对应点坐标就可以得到8个求解方程式,另外再结合H的约束条件(5)就可以得到个数为9的方程组,因此可以解出单应性矩阵H中的9个未知量,最终得到单应性矩阵H[11]。
在真实的应用场景中,计算的点对中都会包含噪声。比如点的位置偏差几个像素,甚至出现特征点对误匹配的现象,如果仅仅使用4个点对来计算单应矩阵,会出现较大的误差[11]。因此,为了使得计算更精确,一般都会使用远大于4个点对来计算单应矩阵。另外直接采用线性解法通常很难得到最优解,所以实际使用中一般会用其它优化方法,如奇异值分解。由单应性矩阵H分解可以得到旋转矩阵H和平移矩阵t, 旋转矩阵RH定义如式(6)所示:
(6)
由式(6)旋转矩阵R可以分别得到绕x,y,z轴旋转的如式(7) (8) (9)所示的欧拉角θx,θy,θz:
θx= atan2(r32,r33)
(7)
(8)
θz= atan(r21,r11)
(9)
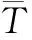
(10)
这种方案的优点是对零件图片特征的明显程度要求不高,能够应用于众多零件,而且准确率有保证;但是其缺点就是计算量会随着识别精度提高而增大;对于这个缺点本文采用了如下方法来提高效率:1)提前将模板按照一定间隔旋转一周,保存下来,这样做可以避免在程序运行过程中进行旋转,用内存换效率;2)先以较大间隔旋转一周找到相关系数较高的旋转角度范围,即可以将第一次得到的相关系数进行排序,找出最大的几个值,然后在这个范围中进行小间隔旋转,最终确定出最大相关系数对应的旋转角度;3)在程序设计上由于C++的运行效率远远高于python,因此为了程序的高效运行,这一部分程序采用C++来实现,然后生成dll动态链接库文件,用python来扩展调用该动态链接库文件。
3.4 相机标定及坐标转换
前面对于图片的处理都是基于图片的像素坐标系,与机器人坐标系不一致,因此还需要进行坐标系转化,将像素坐标通过相机标定和坐标转换转变成机器人的坐标系,视觉系统的处理结果经过坐标转换之后才能指导机器人控制系统进行相应的操作。
坐标转换是指将获取的像素坐标转换为机器人坐标。过程中涉及如图14所示5个坐标系的转换,分别为像素坐标系、图像坐标系、相机坐标系、世界坐标系及机器人坐标系[13-14]。

图14 坐标系示意图
设像素坐标系中一点P(u,v),对应机器人坐标系下的点为P(x,y,z),其变换经如图15所示的流程实现。

图15 坐标系转换流程图
其中,M1、M2分别为相机的内外参矩阵,由相机标定获得,方法选用张正友教授的棋盘标定法[15]。将棋盘格第一个内角点作为世界坐标系原点,(x0,y0,z0)为世界坐标系与机器人坐标系原点坐标的偏移值,把机器人末端移动到世界坐标原点位置,记录此时机器人的坐标即为两者间的偏移量[16]。经上述变换,得到机器人坐标与像素坐标的转换关系如公式(11)所示:
(11)
其中:由于实际中世界坐标系与机器人坐标系的x轴正方向相反,而图14所示坐标系示意图为便于公式描述,取世界坐标系的x轴正方向与机器人坐标系方向一致。因此,实际计算时,需将计算出的世界坐标的x值取负。
3.5 视觉识别系统与工业机器人通信
视觉识别系统在完成识别任务之后需要通过Socket通信与机器人控制系统建立通信连接,机器人控制系统发送指令给视觉系统开始采集图像,之后视觉系统将识别的零件种类、位置坐标和旋转角度发送给机器人控制系统,机器人控制系统根据接收到的识别结果切换并控制机械手来抓取对应零件同时对零件进行旋转和平移达到指定位置和姿态。
4 实验结果
在分类器模型选择方面,选择500个测试样本,分别用训练好的LeNet网络和VGG-Net网络进行测试,识别的准确率及测试样本所用时间如表1所示,结构简单的LeNet5的识别率与VGG-Net相比明显偏低,不能满足要求;VGG-Net模型,识别精度可以满足要求,且测试500个样本所用的时间只比LeNet5模型多0.4秒,对整个识别效率的影响不是很大;因此,从识别准确率和识别效率上综合考虑,选择VGG-Net作为分类器的模型结构。

表1 LeNet5与VGG-Net对比
在夹取点坐标和姿态获取方面,如表2是特征匹配法与归一化互相关法在识别精度和识别效率上的性能对比,归一化互相关法对每个零件的坐标和姿态的识别精度都可以满足系统设计的容错范围0.3 mm,但是识别单个零件用时平均为0.96秒,用时与特征匹配法相比较长,识别效率偏低;特征匹配法识别单个零件的坐标和姿态用时平均为0.1秒,识别效率较高,但是在识别特征相似度较高的零件1时,识别误差为1.86 mm超过了系统设计的容错范围0.3 mm。因此,从识别效率和准确度两方面综合考虑,零件0、零件2、零件3、零件4、零件5采用特征匹配法获取零件的坐标和姿态,表2中用灰色标记的零件1采用归一化互相关法获取零件的坐标和姿态。

表2 特征匹配与归一化互相关性能对比
如表3所示是采用最优方案后的零件类别、旋转角度、夹取点x,y坐标数据的标准值与实际值,其中零件类别的标准值是通过对照图2来获取,旋转角度和夹取点坐标的标准值是通过手动操作工业机器人将零件放置在待识别区域,记录下此时控制系统中夹爪的坐标和旋转角度,重复上述步骤得到多个零件的坐标和角度的标准值后将机器人复位,移出相机视野,此时启动视觉识别系统进行类别、角度以及坐标的测试值的获取,通过测试值和标准值可得到偏差值。根据表中的结果可以得出本次待识别的6个零件中,类别的识别准确率为100%,旋转角度偏差的最大值为0.62°,夹取点坐标x的偏差最大值为-0.23 mm,y的偏差最大值为-0.26 mm,偏差结果满足需求分析中标准托盘旋转角度的容错偏差范围±0.8°以及坐标的容错偏差范围±0.3 mm。

图16 零件夹取 图17 零件放置
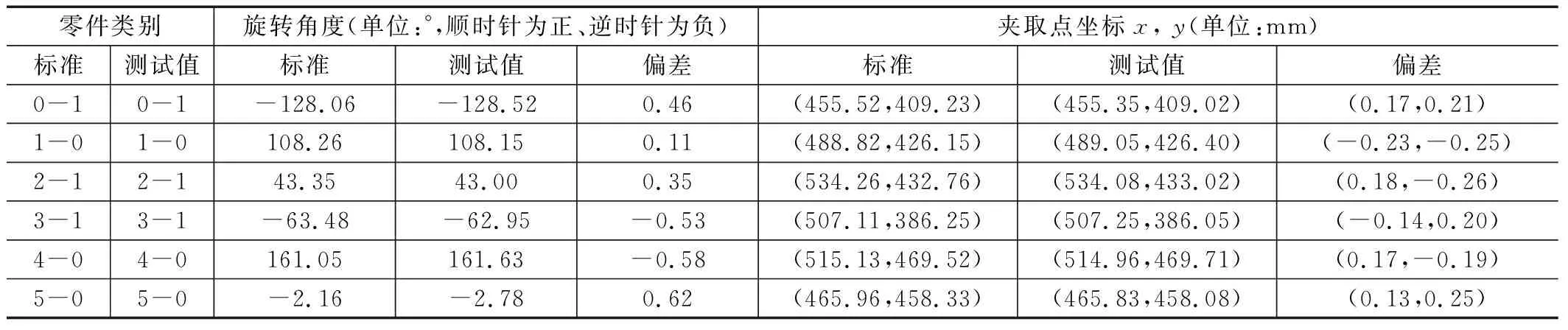
表3 零件识别信息表
通过视觉识别系统与工业机器人通信将上述表1中的测试数据发送给工业机器人控制器,如图16所示工业机器人根据接收到的夹取点坐标和姿态夹取底座上的零件,经过旋转和平移后如图17所示放置到标准的零件托盘中供后续装配使用。
5 结束语
本文设计并实现的基于机器视觉的小型断路器柔性装配方案不仅解决了人工装配效率低和一致性差的问题,同时也解决了基于振动盘自动装配噪音大和灵活差的问题。从而实现了一条生产线就能高效率、高质量、高灵活性地完成多种型号的小型断路器的生产任务,满足了市场对产品小批量、个性化的需求。另外,由于该方案采用的是模块化设计,因此只需进行部分模块的修改就可以将该系统应用到其它的柔性装配领域, 降低了企业的设备投入,也降低了后期设备升级的难度。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
导航定位学报(2022年2期)2022-04-11
计算机系统应用(2021年2期)2021-02-23
语数外学习·高中版中旬(2021年11期)2021-02-14
学生天地(2020年3期)2020-08-25
考试周刊(2018年15期)2018-01-21
中学生数理化·七年级数学人教版(2017年4期)2017-07-08
软件导刊(2017年4期)2017-06-20
诗选刊(2015年4期)2015-10-26
