
基于文本挖掘的高速铁路动车组故障多级分类研究
2020-08-03 05:47王志飞赵俊华
计算机测量与控制 2020年7期
高 凡,李 樊,张 铭,王志飞,赵俊华
(1.中国铁道科学研究院 研究生部,北京 100081;2.中国铁道科学研究院集团有限公司,北京 100081; 3.北京经纬信息技术有限公司,北京 100081)
0 引言
高速铁路信号设备是保障高速铁路行车安全的重要基础设施[1],随着高速铁路运营里程的积累,产生了海量的信号设备故障数据,这些故障数据大多以非结构化文本的形式存储,该数据蕴含了高速铁路安全的重要信息,长期由业务人员根据经验对数据进行故障设备诊断与分类,由于高速铁路中存在众多不同类型的信号设备,设备故障类型多,且设备与故障原因的隶属关系严谨,为深入开展高速铁路故障数据分析工作,需要对故障数据进行多级分类,而人工进行多级分类工作容易造成分类的不准确性,在智慧铁路和铁路大数据的建设下,亟需研究基于文本挖掘的机器学习算法,实现高速铁路信号故障设备的多级分类。
多级别分类方法包括自上而下分类、全局分类和收缩分类方法[2-3],高速铁路信号设备故障多级分类,采用自上而下分类方法中分而治之的策略,将设备故障多级分类问题分解为单层分类问题,通过设计单级分类模型得出每一级别的分类结果,最后通过多任务协作决策树投票策略,将各级的分类结果进行汇集与隶属关系矫正,实现信号设备故障的多级分类。
采用铁路安全文本特征提取和单层分类模型的研究方法,设计高速铁路信号设备故障多级分类模型[4]。首先针对高速铁路信号设备故障数据特点,提出基于词频-逆向文件频率(term frequency-inverse document frequency,TF-IDF)改良的特征提取方法[5]。针对故障类别样例数量差异较大,为避免防止单一分类器造成过拟合的问题,采用K折交叉验证+ Stacking分类模型实现单层分类模型[6],Stacking模型中提出将相似网路结构的变体双向门控循环单元(bidirection gated recurrent unit,BiGRU)与双向长短时记忆网络(bidirection long short term memory,BiLSTM)初级学习器[7],设计整体与类别权重相结合的权重分配机制作为次学习器,提升单层分类模型的分类性能。通过Staking模型对各级别任务进行分类[8],设计多任务协作投票决策树,实现多个级别分类结果的隶属关系矫正,同时提升整个多级分类模型的分类性能。最后应用高速铁路2009年到2018年信号设备故障数据进行实验,验证多级分类模型的有效性与正确性。
1 高速铁路信号故障文本特征提取
高速铁路信号设备故障数据来源于铁路牵引供电管理信息系统(EMIS),故障数据以结构化的形式记载了故障的详细信息,如表1所示,记录故障发生的原因信息以自然语言文本的形式存储。本文基于高速铁路故障原因分析文本数据,对故障的信息进行故障原因和部位二级分类。
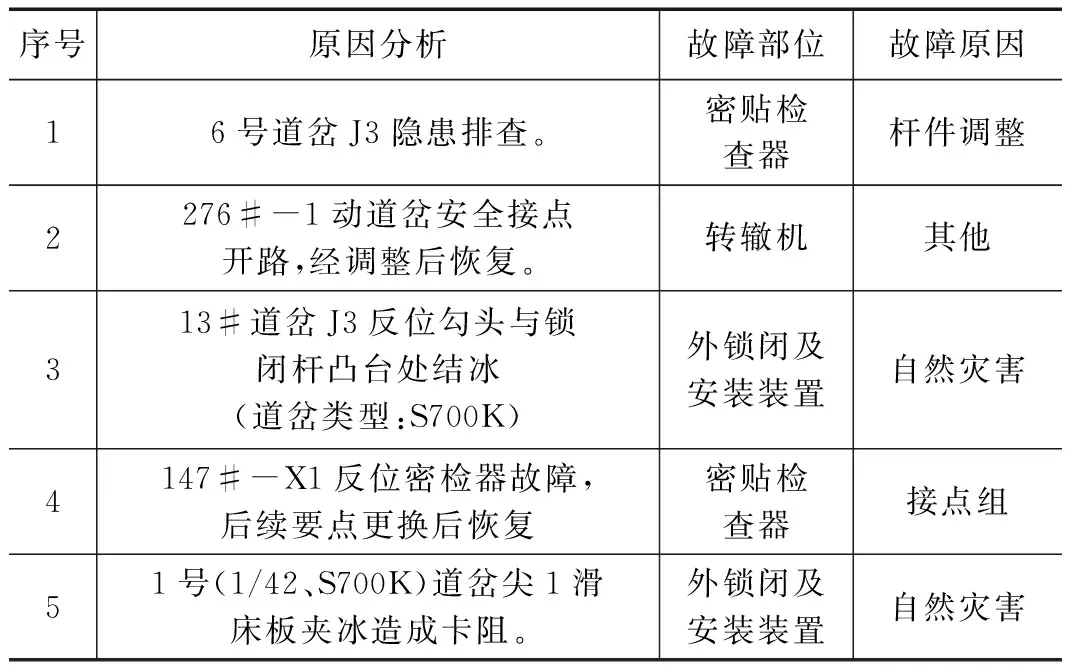
表1 高铁信号道岔故障部分样例数据
高速铁路信号设备故障原因分析文本数据中包含道岔、红光带、密贴器等具有特征的关键词,采用TF-IDF对故障文本数据进行特征提取[9],TF-IDF方法的原理是若某个词在样本中出现的频率越高,而有该词的样本在全文档中越少,说明该词对这个样本有着越高的辨识度,具有很好的区分能力。由于高速铁路信号设备故障文档数量较大,但是每个故障文档都是短文本,直接采用TF-IDF方法抽取特征,易造成特征向量冗余性和稀疏性,缺失了数据的特异性,所以本文针对高速铁路信号设备故障数据特征提取方法在TF-IDF方法基础上进行了改良。
改良的TF-IDF高速铁路信号设备故障文本数据特征抽取方法:首先要将中文文本内容进行分词,本文采用基于专业语料库和常用语料库的Jieba分词工具对信号故障文本分词[10],并对助词如“的”,“了”等不能表示文档特征的词语进行清理,然后将分词后的词汇集合进行TF-IDF权重计算形成词汇权重矩阵,以及对每个词汇的数量统计形成词汇字典。TF-IDF权重矩阵中m为文档数,n为所有文档的词汇,所以n的维度很大,TF-IDF权重矩阵具有严重的稀疏性。根据TF-IDF值为每个样本中的词进行排序,允许词汇重复,选取前100个最具有样本特征的词语,降低特征向量维度,并将词频替换为对应的词汇ID,形成特征字典矩阵,将文本特征向量以及经过one-hot编码后的各级别的标签输入到文本分类模型中。
2 基于Stacking的信号设备故障单层文本分类模型计
高速铁路信号设备故障文本特征数据集分为训练集、验证集以及测试集输入到Stacking单层分类模型中。基于Stacking的高速铁路信号设备故障单层文本分类,通过将循环神经网络BiGRU与BiLSTM作为Stacking的初次学习器,将两个神经网络预测的结果作为特征来训练组合加权次级学习器,通过次级学习器整合初级学习器的预测结果。为了避免训练集训练出来的模型反过来预测训练集造成过拟合问题,以及训练多个单层分类模型,达到相同测试集产生多个预测结果的目的,采用了K折交叉验证方法,如图1所示。
2.1 软件设计思路和编程方法BiLSTM与BiGRU初级学习器原理
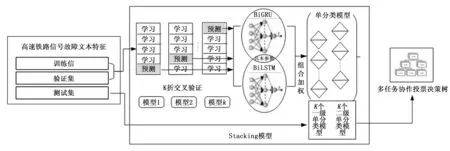
图1 Stacking信号设备故障文本分类模型
循环神经网络(RNN)是一种处理序列信息的神经网络,由于在结构上存在前后依赖关系,在自然语言应用上得到了广泛的应用。RNN特殊性在于其在t时刻的输出st,不仅取决于输入层的xt,而且还取决于上一节点的输出st-1,其学习过程是一个预测下一个词的过程,例如,xt-1,xt,xt+1是一个输入“道岔定位无”,那么ot-1和ot对应的是“定位”和“无“这两项”,预测下一个次最有可能是什么,通过信号故障语料训练,ot+1最有可能的是“表示”。ht表示t时刻隐藏层的状态,xt表示t时刻的输入,ot表示t时刻的输出,st表示t时刻的记忆单元,U,W模型的线性参数矩阵。双向RNN同时考虑预测词的上文信息和下文信息,由前向后、由后向前均保留该词的重要信息,能够更加有效的进行预测。
(1)
(2)
st=f(U*xt+W*st-1)
(3)
ot=softmax(Vst)
(4)
(5)
RNN的变体神经网络LSTM和GRU是通过设计门的结构来选择通过神经元的信息,由于sigmoid的输出是在0到1之间的取值,有助于信息的选择与忘记,0表示全部舍弃,1表示全部保留,通常选择sigmoid函数作为激活函数,tanh函数作为输出函数。
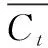
ft=σ(Wf·[ht-1,xt]+bf)
(6)
it=σ(Wi·[ht-1,xt]+bi)
(7)
(8)
(9)
ot=σ(Wo·[ht-1,xt]+bo)
(10)
ht=ot*tanh(Ct)
(11)
GRU是将LSTM的遗忘门、输入门和输出门变为更新门zt与重置门rt,并将单元状态与输出合并为一个状态ht。
zt=σ(Wz·[ht-1,xt])
(12)
rt=σ(Wr·[ht-1,xt])
(13)
(14)
(15)
2.2 组合加权次级学习器原理
组合加权次级学习器不仅考虑神经网络的整体学习能力,同时也考虑神经网络在不同类别上的表现。根据单个神经网络对相同输入的学习结果,给单个神经网络分配权重,准确度越高的神经网络权重越大,这种方法可以有效抑制神经网络学习过程中少数值,极端值的影响。神经网络在各类别上的权重根据公式(16)、(17)计算,通过计算分类神经网络在某个类别上的错误比例对数计算在该类别上的权重,表现好的,错误比例小的权重越大,当错误比例超过0.5时,权重计为0。最后按公式(18)将神经网络的整体权重与类别权重相加,重新计算模型对标签的预测值。
(16)
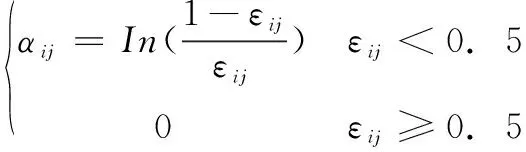
(17)
(18)

2.3 Stacking单层分类模型
Stacking模型采用两个神经网络作为初级学习器,在数据预处理层将字符特征向量进行降维,转换为神经网络嵌入层(Embedding),分别输入到两个双向神经网络BiGRU和BiLSTM中,两个神经网络经过学习后分别在Softmax层输出对各分类标签的预测概率,经过组合权重分类器对两个初级学习器的预测结果整合计算,最后输出Stacking模型对输入数据的分类情况,如图2所示。
3 实验结果与分析
本文以高速铁路信号基础设备中的道岔转辙设备2009~2018年10年数据进行验证,其中,70%作为训练集样本,20%作为验证集样本,10%作为测试集样本。数据包括7类一级分类标签,64类二级分类标签,采用准确度(Precision)和召回率(Recall)构建F1值综合评价模型。
其中,Precision计算公式为:
(19)
Recall计算公式为:
(20)

图2 Stacking单层分类模型网络结构
F-score计算公式为:
(21)
C为所有样本的总数,c为所有类别总数,TPi为被正确分到此类的样本个数,TNi为被正确识别不在此类的样本个数,FPi表示被误分到此类的样本个数,FNi表示属于此类但被误分到其它类的样本个数。
3.1 BiGRU和BiLSTM整体权重分配
BiGRU和BiLSTM整体权重大小根据单个神经网络对相同特征向量的学习结果。本文设计BiGRU和BiLSTM具有相同的网络参数,设定K折交叉验证K=5,神经网络的迭代轮数为50,网络输入批处理大小为256,嵌入层维度为100,隐藏层维度为512。BiGRU和BiLSTM一级和二级训练过程的loss函数值如图3所示,从图中可以看出,迭代轮数为30~50之间,损失函数loss值接近最小,并且基本稳定,BiGRU相比于BiLSTM损失函数小,分类性能较优,二级分类较一级分类loss函数变化幅度较小,随着K值的增加,每一次迭代过程中,loss值逐渐变小且趋于平稳。
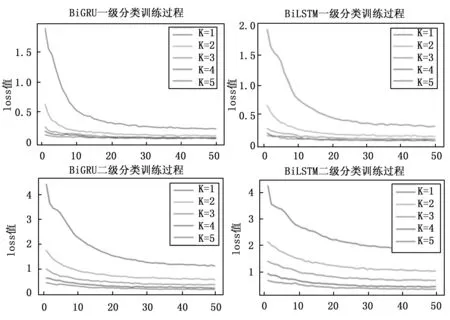
图3 BiGRU和BiLSTM网络K交叉loss函数
经过K=5次训练,将每次的训练结果求和平均,得到两个神经网络各自的训练结果,如表2所示。
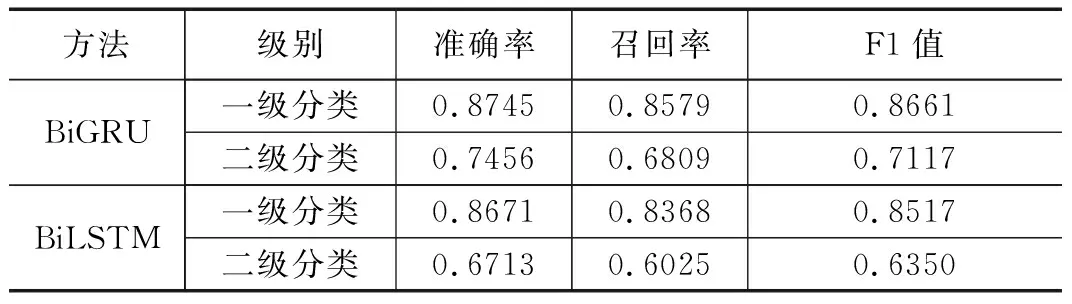
表2 BiGRU和BiLSTM神经网络训练结果
由表2可以看出,两个神经网络在相同参数下,BiGRU较BiLSTM各评价指标都较高,经实验,给BiGRU分配权重为0.7,BiLSTM权重为0.3。
3.2 BiGRU和BiLSTM类别权重计算
高速铁路信号设备故障一级类别中各类别数量以及类别权重如表3所示,由于二级类别数量较大,考虑文章篇幅的原因,只列出一级类别的类别权重分析结果。从表3中可以看出密贴检查器、外锁闭及安装装置和转辙机的故障数据较少,在数据量基数小,错误数量稍大时类别权重就小,相反,在配套器材和原因不明故障数量基础较大时,网络学习效果好,类别权重也较大。
3.3 Stacking模型分类
通过组合加权对两个网络的输出重新计算,得出共同的分类预测结果,最终分类结果如表4所示,可以看出,各分类评价指标值都有所提升,实验证明,Stacking单层分类模型是一种能够有效提升高速铁路信号设备故障文本分类指标的模型。

表3 信号故障一级分类类别权重计算结果

表4 Satcking模型单层文本分类结果
3.4 实现总结
根据以上实验分析,各模型的分类指标按各级相应评价指标的平均值计算,BiGRU模型、BiLSTM模型、Stacking模型,以及最后通过多任务协作投票的多级分类模型,各模型的分类性能如图4所示。
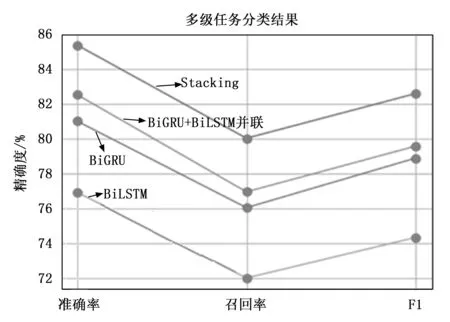
图4 各模型分类性能对比
转辙机、外锁闭及安装装置、密贴检查器、道岔控制电路器材、工务设备等设备的一级、二级故障按相应评价指标的平均值计算精准度,BiGRU模型为81%、BiLSTM模型为75%、BiGRU+BiLSTM并联模型为82.3%,Stacking模型为85.5%,从图4中可以看出,针对高速铁路信号设备故障文本数据进行信号设备故障多级分类,本文设计的Stacking模型有效提高了各级别的分类指标,基于多任务协作投票的机制有效解决分类结果的从属关系,并提升了Stacking模型的整体分类性能,实验证明,本文提出的基于文本挖掘技术的Stacking模型在解决高速信号设备多级分类问题具有优势。
4 结束语
高速铁路设备故障文本数据是挖掘高速铁路运营安全状况与安全规律的重要数据,基于文本挖掘技术实现高速铁路设备故障多级分类是深入分析高速铁路设备故障数据的必要手段。本文就高速铁路信号设备故障文本数据设计多级分类模型,解决各级分类之间的隶属关系,并有效提升了分类评价指标。本文基于Stacking思想设计的K折交叉验证单层分类模型,保证了初级学习器的算法差异和多样性,有效降低分类过拟合的风险,并且分类指标相比单神经网络分类器有所提升,多任务协作投票机制保证了分类结果的隶属关系。本文中的Stacking单层分类模型和多级分类模型在铁路文本分类中都具有借鉴价值。本系统在试点工程中根据实际设备及用户的关注度需要进一步调整模型参数,使系统达到最优效果。
猜你喜欢
分子催化(2022年1期)2022-11-02
南京航空航天大学学报(2022年4期)2022-08-30
心理学报(2022年5期)2022-05-16
中国新通信(2022年4期)2022-04-23
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
中国建筑金属结构(2018年4期)2018-05-23
证券市场红周刊(2018年3期)2018-05-14
艺术科技(2016年9期)2016-11-18
科学与财富(2016年28期)2016-10-14
